 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForward Modeling for Partial Observation Strategy Games - A StarCraft Defogger
Nov 30, 2018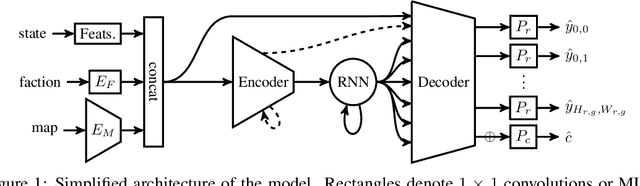
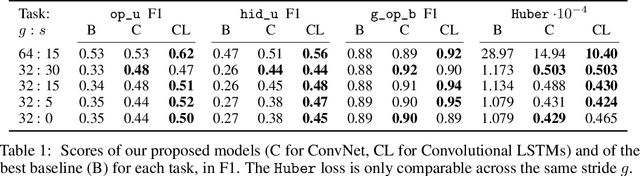
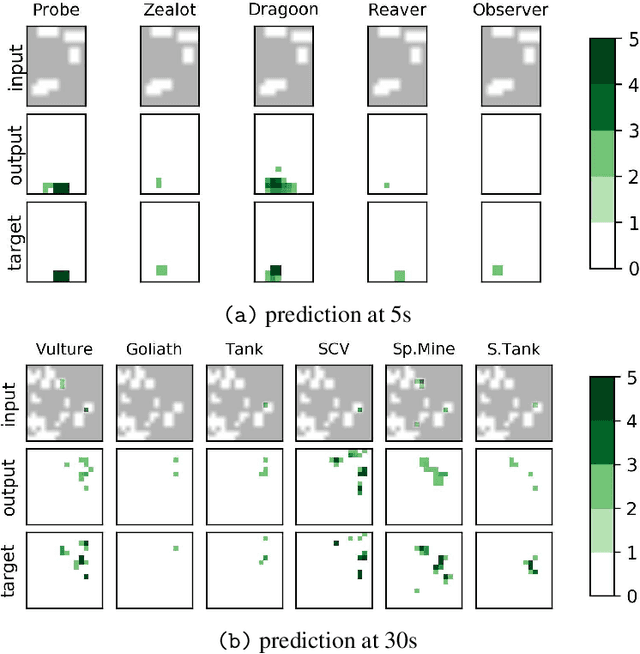
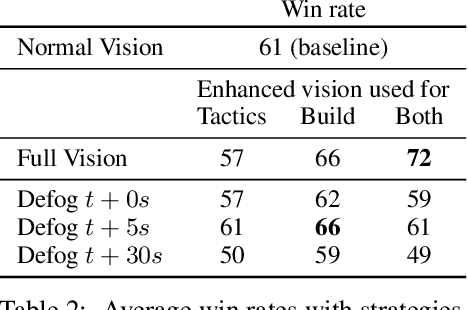
We formulate the problem of defogging as state estimation and future state prediction from previous, partial observations in the context of real-time strategy games. We propose to employ encoder-decoder neural networks for this task, and introduce proxy tasks and baselines for evaluation to assess their ability of capturing basic game rules and high-level dynamics. By combining convolutional neural networks and recurrent networks, we exploit spatial and sequential correlations and train well-performing models on a large dataset of human games of StarCraft: Brood War. Finally, we demonstrate the relevance of our models to downstream tasks by applying them for enemy unit prediction in a state-of-the-art, rule-based StarCraft bot. We observe improvements in win rates against several strong community bots.
High-Level Strategy Selection under Partial Observability in StarCraft: Brood War
Nov 21, 2018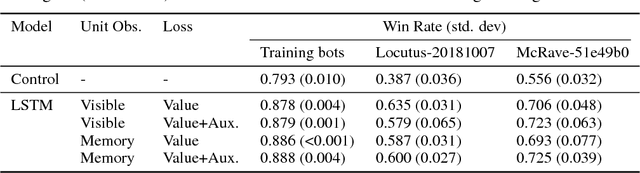
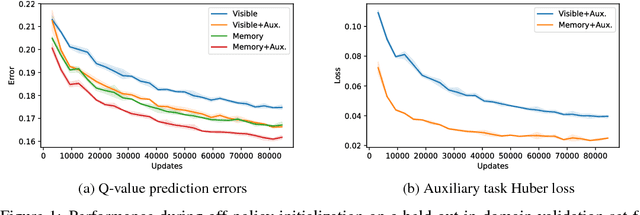
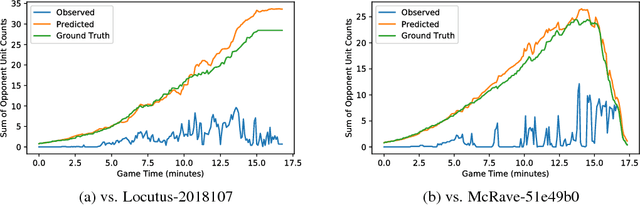
We consider the problem of high-level strategy selection in the adversarial setting of real-time strategy games from a reinforcement learning perspective, where taking an action corresponds to switching to the respective strategy. Here, a good strategy successfully counters the opponent's current and possible future strategies which can only be estimated using partial observations. We investigate whether we can utilize the full game state information during training time (in the form of an auxiliary prediction task) to increase performance. Experiments carried out within a StarCraft: Brood War bot against strong community bots show substantial win rate improvements over a fixed-strategy baseline and encouraging results when learning with the auxiliary task.
SING: Symbol-to-Instrument Neural Generator
Oct 23, 2018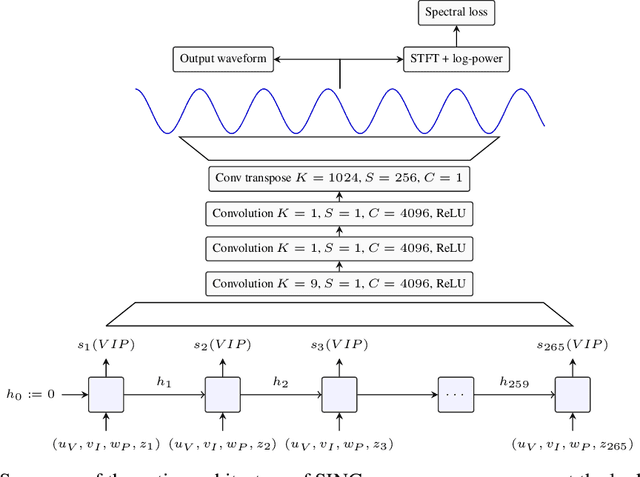
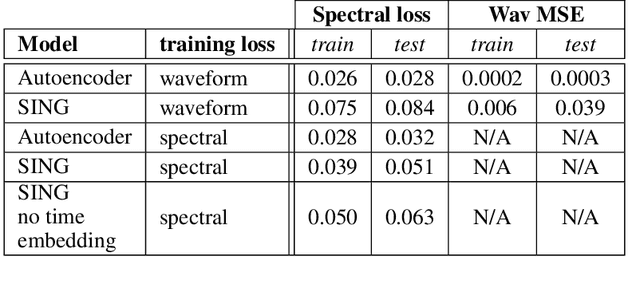


Recent progress in deep learning for audio synthesis opens the way to models that directly produce the waveform, shifting away from the traditional paradigm of relying on vocoders or MIDI synthesizers for speech or music generation. Despite their successes, current state-of-the-art neural audio synthesizers such as WaveNet and SampleRNN suffer from prohibitive training and inference times because they are based on autoregressive models that generate audio samples one at a time at a rate of 16kHz. In this work, we study the more computationally efficient alternative of generating the waveform frame-by-frame with large strides. We present SING, a lightweight neural audio synthesizer for the original task of generating musical notes given desired instrument, pitch and velocity. Our model is trained end-to-end to generate notes from nearly 1000 instruments with a single decoder, thanks to a new loss function that minimizes the distances between the log spectrograms of the generated and target waveforms. On the generalization task of synthesizing notes for pairs of pitch and instrument not seen during training, SING produces audio with significantly improved perceptual quality compared to a state-of-the-art autoencoder based on WaveNet as measured by a Mean Opinion Score (MOS), and is about 32 times faster for training and 2, 500 times faster for inference.
End-to-End Speech Recognition From the Raw Waveform
Jun 21, 2018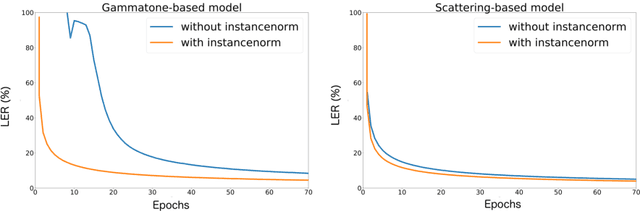
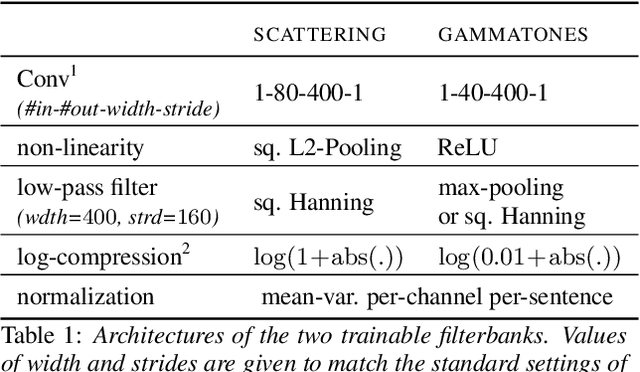
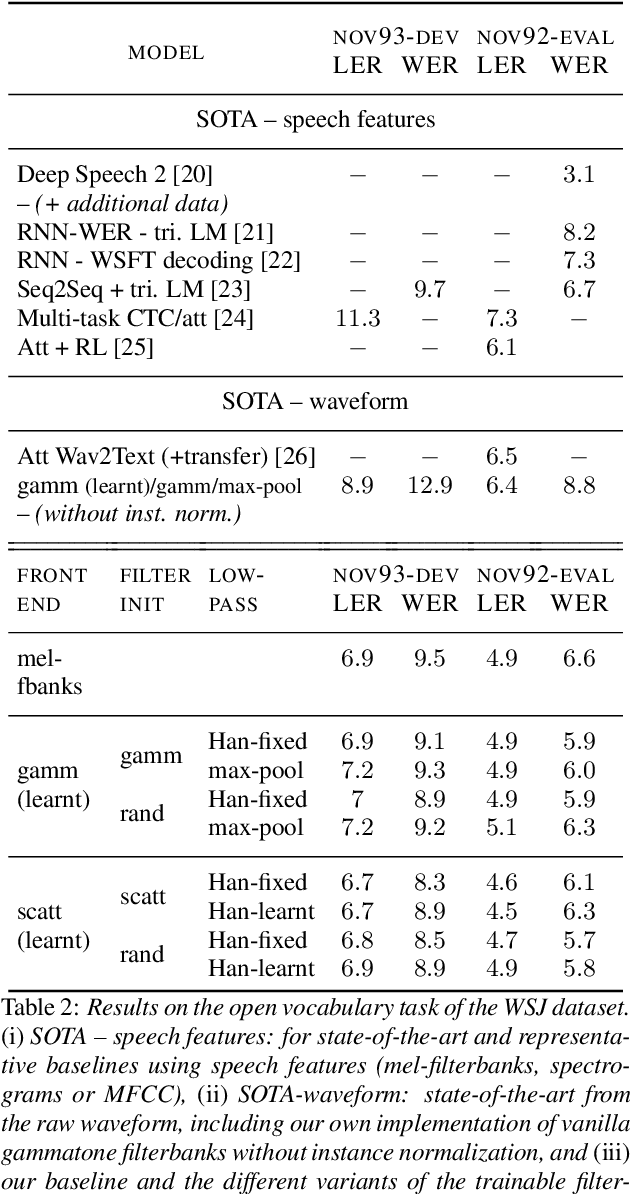
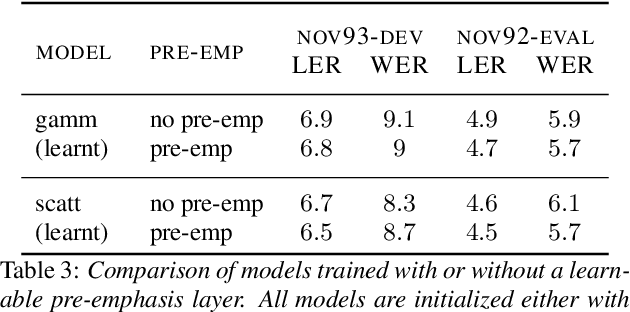
State-of-the-art speech recognition systems rely on fixed, hand-crafted features such as mel-filterbanks to preprocess the waveform before the training pipeline. In this paper, we study end-to-end systems trained directly from the raw waveform, building on two alternatives for trainable replacements of mel-filterbanks that use a convolutional architecture. The first one is inspired by gammatone filterbanks (Hoshen et al., 2015; Sainath et al, 2015), and the second one by the scattering transform (Zeghidour et al., 2017). We propose two modifications to these architectures and systematically compare them to mel-filterbanks, on the Wall Street Journal dataset. The first modification is the addition of an instance normalization layer, which greatly improves on the gammatone-based trainable filterbanks and speeds up the training of the scattering-based filterbanks. The second one relates to the low-pass filter used in these approaches. These modifications consistently improve performances for both approaches, and remove the need for a careful initialization in scattering-based trainable filterbanks. In particular, we show a consistent improvement in word error rate of the trainable filterbanks relatively to comparable mel-filterbanks. It is the first time end-to-end models trained from the raw signal significantly outperform mel-filterbanks on a large vocabulary task under clean recording conditions.
Canonical Tensor Decomposition for Knowledge Base Completion
Jun 19, 2018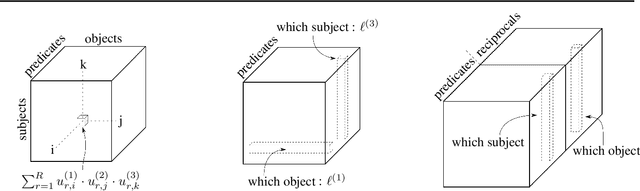
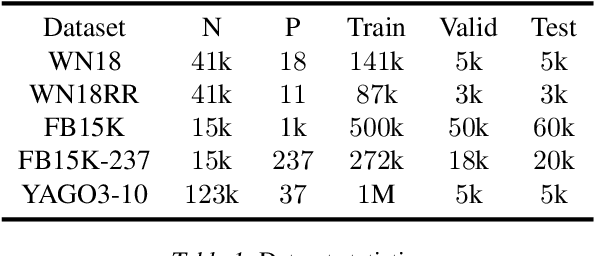
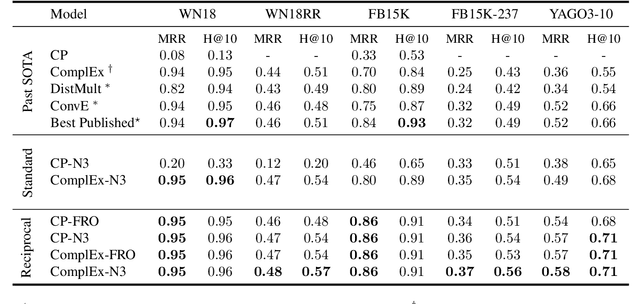
The problem of Knowledge Base Completion can be framed as a 3rd-order binary tensor completion problem. In this light, the Canonical Tensor Decomposition (CP) (Hitchcock, 1927) seems like a natural solution; however, current implementations of CP on standard Knowledge Base Completion benchmarks are lagging behind their competitors. In this work, we attempt to understand the limits of CP for knowledge base completion. First, we motivate and test a novel regularizer, based on tensor nuclear $p$-norms. Then, we present a reformulation of the problem that makes it invariant to arbitrary choices in the inclusion of predicates or their reciprocals in the dataset. These two methods combined allow us to beat the current state of the art on several datasets with a CP decomposition, and obtain even better results using the more advanced ComplEx model.
Value Propagation Networks
May 28, 2018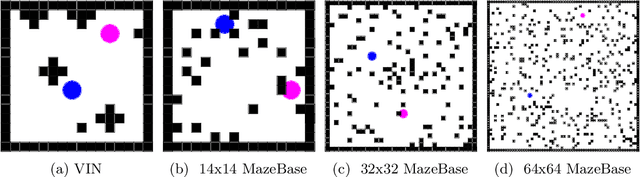

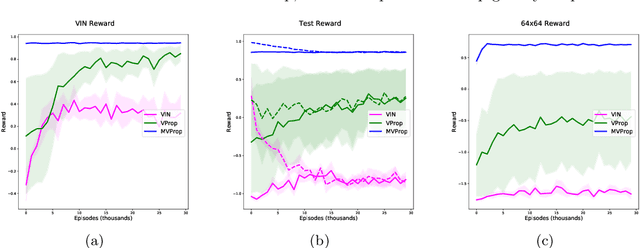
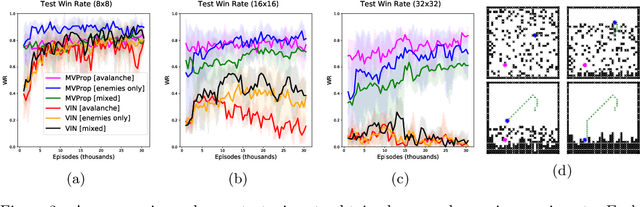
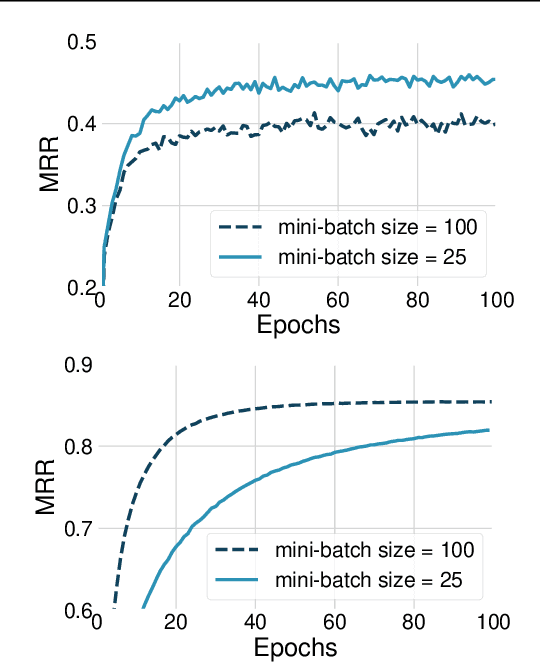
We present Value Propagation (VProp), a parameter-efficient differentiable planning module built on Value Iteration which can successfully be trained using reinforcement learning to solve unseen tasks, has the capability to generalize to larger map sizes, and can learn to navigate in dynamic environments. Furthermore, we show that the module enables learning to plan when the environment also includes stochastic elements, providing a cost-efficient learning system to build low-level size-invariant planners for a variety of interactive navigation problems. We evaluate on static and dynamic configurations of MazeBase grid-worlds, with randomly generated environments of several different sizes, and on a StarCraft navigation scenario, with more complex dynamics, and pixels as input.
Learning Filterbanks from Raw Speech for Phone Recognition
Apr 04, 2018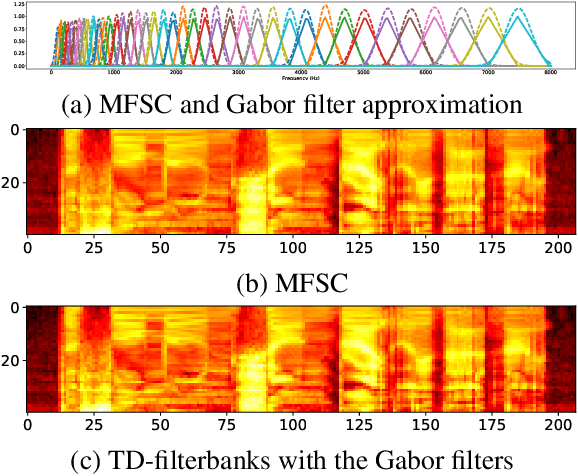

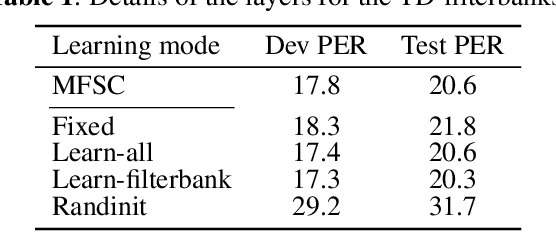
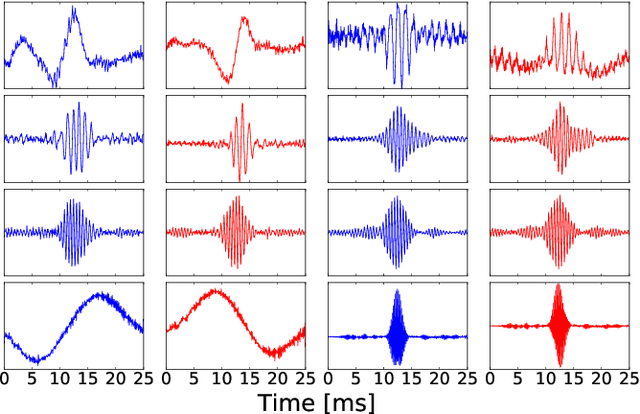
We train a bank of complex filters that operates on the raw waveform and is fed into a convolutional neural network for end-to-end phone recognition. These time-domain filterbanks (TD-filterbanks) are initialized as an approximation of mel-filterbanks, and then fine-tuned jointly with the remaining convolutional architecture. We perform phone recognition experiments on TIMIT and show that for several architectures, models trained on TD-filterbanks consistently outperform their counterparts trained on comparable mel-filterbanks. We get our best performance by learning all front-end steps, from pre-emphasis up to averaging. Finally, we observe that the filters at convergence have an asymmetric impulse response, and that some of them remain almost analytic.
Fader Networks: Manipulating Images by Sliding Attributes
Jan 28, 2018
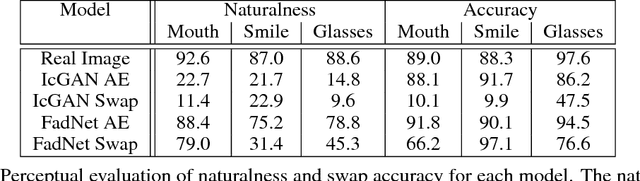
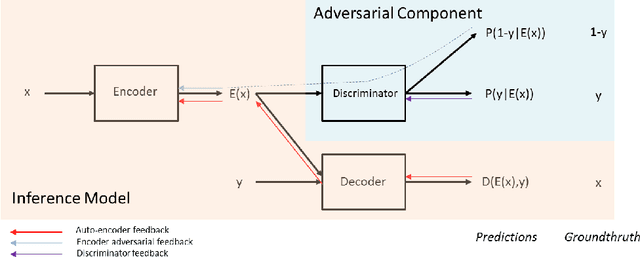

This paper introduces a new encoder-decoder architecture that is trained to reconstruct images by disentangling the salient information of the image and the values of attributes directly in the latent space. As a result, after training, our model can generate different realistic versions of an input image by varying the attribute values. By using continuous attribute values, we can choose how much a specific attribute is perceivable in the generated image. This property could allow for applications where users can modify an image using sliding knobs, like faders on a mixing console, to change the facial expression of a portrait, or to update the color of some objects. Compared to the state-of-the-art which mostly relies on training adversarial networks in pixel space by altering attribute values at train time, our approach results in much simpler training schemes and nicely scales to multiple attributes. We present evidence that our model can significantly change the perceived value of the attributes while preserving the naturalness of images.
Theory of Optimizing Pseudolinear Performance Measures: Application to F-measure
Jan 01, 2018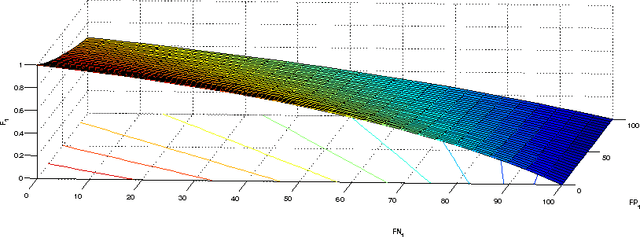
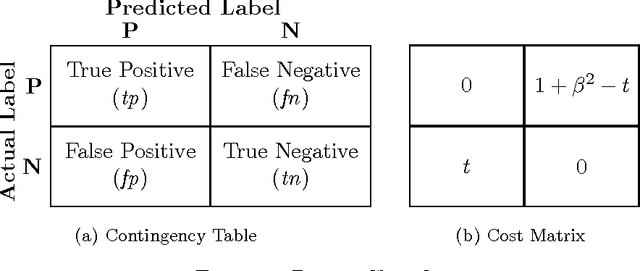

Non-linear performance measures are widely used for the evaluation of learning algorithms. For example, $F$-measure is a commonly used performance measure for classification problems in machine learning and information retrieval community. We study the theoretical properties of a subset of non-linear performance measures called pseudo-linear performance measures which includes $F$-measure, \emph{Jaccard Index}, among many others. We establish that many notions of $F$-measures and \emph{Jaccard Index} are pseudo-linear functions of the per-class false negatives and false positives for binary, multiclass and multilabel classification. Based on this observation, we present a general reduction of such performance measure optimization problem to cost-sensitive classification problem with unknown costs. We then propose an algorithm with provable guarantees to obtain an approximately optimal classifier for the $F$-measure by solving a series of cost-sensitive classification problems. The strength of our analysis is to be valid on any dataset and any class of classifiers, extending the existing theoretical results on pseudo-linear measures, which are asymptotic in nature. We also establish the multi-objective nature of the $F$-score maximization problem by linking the algorithm with the weighted-sum approach used in multi-objective optimization. We present numerical experiments to illustrate the relative importance of cost asymmetry and thresholding when learning linear classifiers on various $F$-measure optimization tasks.
How should we evaluate supervised hashing?
Aug 10, 2017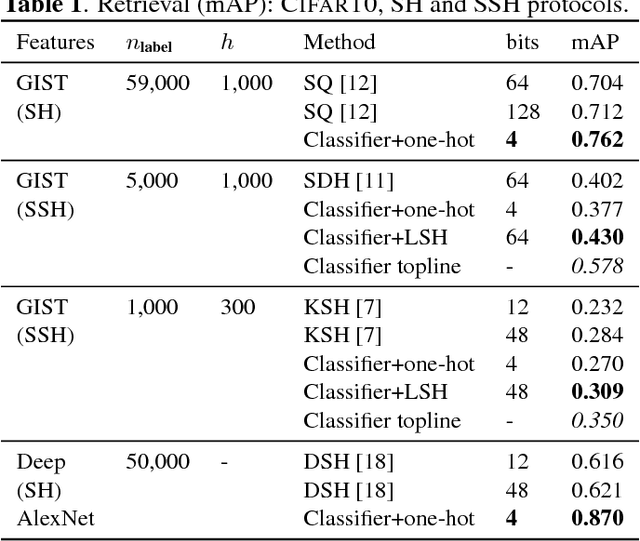
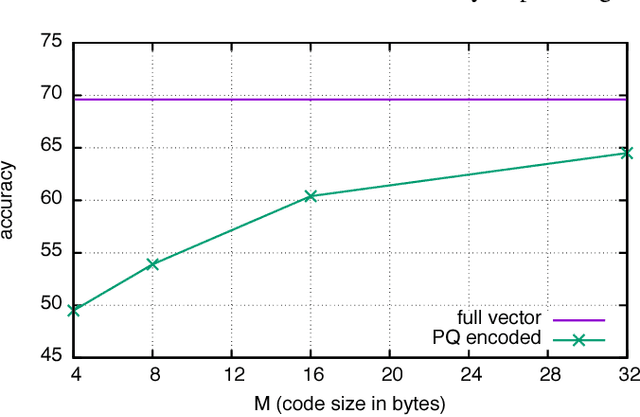

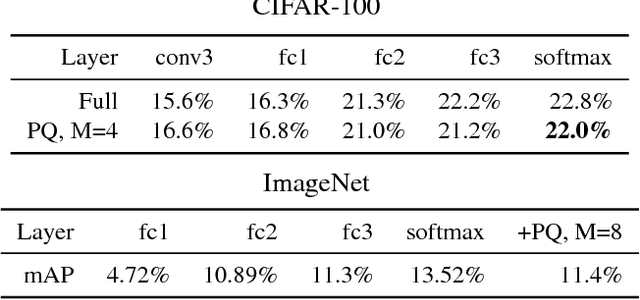
Hashing produces compact representations for documents, to perform tasks like classification or retrieval based on these short codes. When hashing is supervised, the codes are trained using labels on the training data. This paper first shows that the evaluation protocols used in the literature for supervised hashing are not satisfactory: we show that a trivial solution that encodes the output of a classifier significantly outperforms existing supervised or semi-supervised methods, while using much shorter codes. We then propose two alternative protocols for supervised hashing: one based on retrieval on a disjoint set of classes, and another based on transfer learning to new classes. We provide two baseline methods for image-related tasks to assess the performance of (semi-)supervised hashing: without coding and with unsupervised codes. These baselines give a lower- and upper-bound on the performance of a supervised hashing scheme.