 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRange-Based Equal Error Rate for Spoof Localization
May 28, 2023



Spoof localization, also called segment-level detection, is a crucial task that aims to locate spoofs in partially spoofed audio. The equal error rate (EER) is widely used to measure performance for such biometric scenarios. Although EER is the only threshold-free metric, it is usually calculated in a point-based way that uses scores and references with a pre-defined temporal resolution and counts the number of misclassified segments. Such point-based measurement overly relies on this resolution and may not accurately measure misclassified ranges. To properly measure misclassified ranges and better evaluate spoof localization performance, we upgrade point-based EER to range-based EER. Then, we adapt the binary search algorithm for calculating range-based EER and compare it with the classical point-based EER. Our analyses suggest utilizing either range-based EER, or point-based EER with a proper temporal resolution can fairly and properly evaluate the performance of spoof localization.
Can spoofing countermeasure and speaker verification systems be jointly optimised?
Mar 31, 2023Spoofing countermeasure (CM) and automatic speaker verification (ASV) sub-systems can be used in tandem with a backend classifier as a solution to the spoofing aware speaker verification (SASV) task. The two sub-systems are typically trained independently to solve different tasks. While our previous work demonstrated the potential of joint optimisation, it also showed a tendency to over-fit to speakers and a lack of sub-system complementarity. Using only a modest quantity of auxiliary data collected from new speakers, we show that joint optimisation degrades the performance of separate CM and ASV sub-systems, but that it nonetheless improves complementarity, thereby delivering superior SASV performance. Using standard SASV evaluation data and protocols, joint optimisation reduces the equal error rate by 27\% relative to performance obtained using fixed, independently-optimised sub-systems under like-for-like training conditions.
ASVspoof 2021: Towards Spoofed and Deepfake Speech Detection in the Wild
Oct 05, 2022
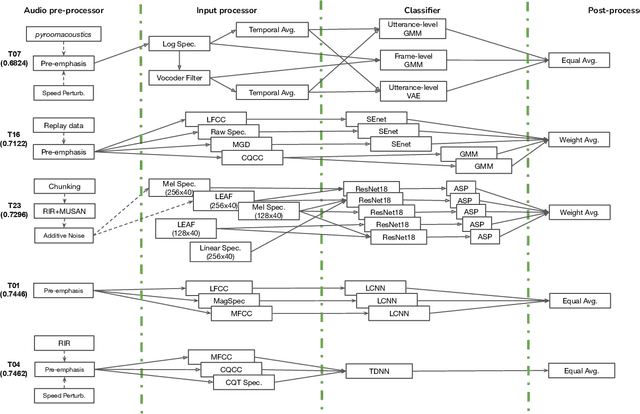
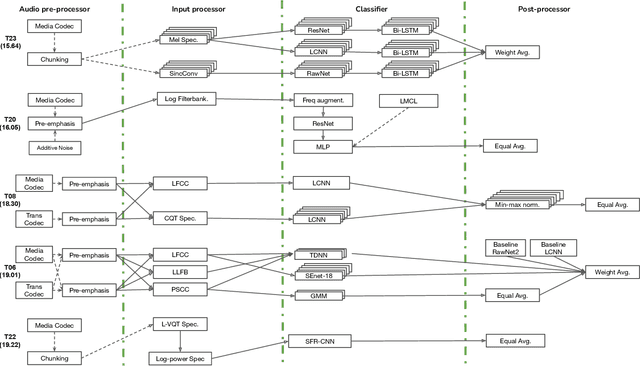
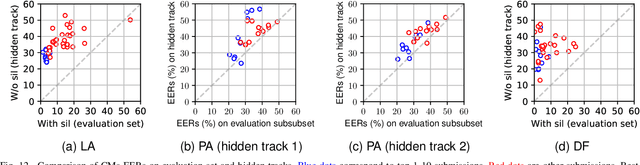
Benchmarking initiatives support the meaningful comparison of competing solutions to prominent problems in speech and language processing. Successive benchmarking evaluations typically reflect a progressive evolution from ideal lab conditions towards to those encountered in the wild. ASVspoof, the spoofing and deepfake detection initiative and challenge series, has followed the same trend. This article provides a summary of the ASVspoof 2021 challenge and the results of 37 participating teams. For the logical access task, results indicate that countermeasures solutions are robust to newly introduced encoding and transmission effects. Results for the physical access task indicate the potential to detect replay attacks in real, as opposed to simulated physical spaces, but a lack of robustness to variations between simulated and real acoustic environments. The DF task, new to the 2021 edition, targets solutions to the detection of manipulated, compressed speech data posted online. While detection solutions offer some resilience to compression effects, they lack generalization across different source datasets. In addition to a summary of the top-performing systems for each task, new analyses of influential data factors and results for hidden data subsets, the article includes a review of post-challenge results, an outline of the principal challenge limitations and a road-map for the future of ASVspoof. Link to the ASVspoof challenge and related resources: https://www.asvspoof.org/index2021.html
The VoicePrivacy 2020 Challenge Evaluation Plan
May 14, 2022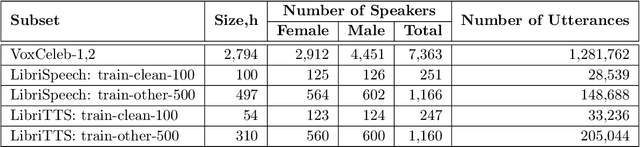
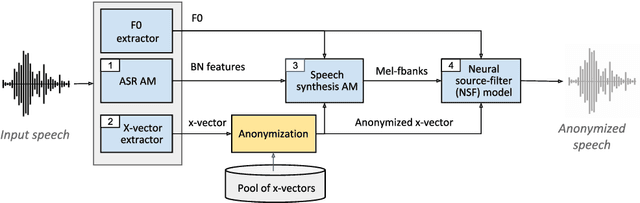
The VoicePrivacy Challenge aims to promote the development of privacy preservation tools for speech technology by gathering a new community to define the tasks of interest and the evaluation methodology, and benchmarking solutions through a series of challenges. In this document, we formulate the voice anonymization task selected for the VoicePrivacy 2020 Challenge and describe the datasets used for system development and evaluation. We also present the attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and report objective evaluation results.
The PartialSpoof Database and Countermeasures for the Detection of Short Generated Audio Segments Embedded in a Speech Utterance
Apr 28, 2022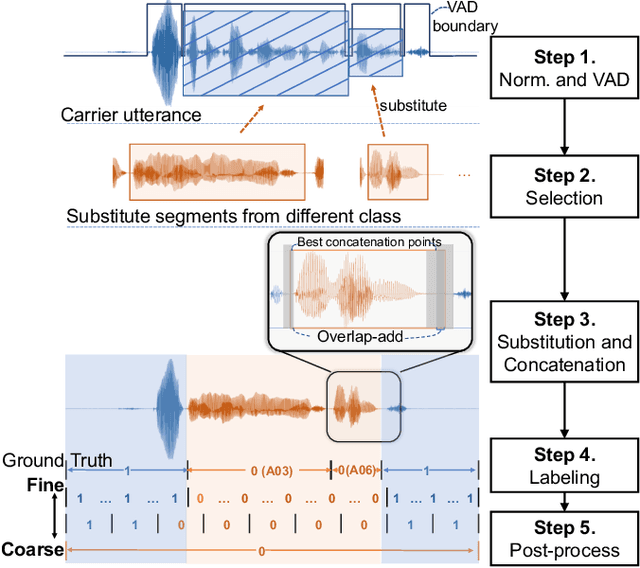
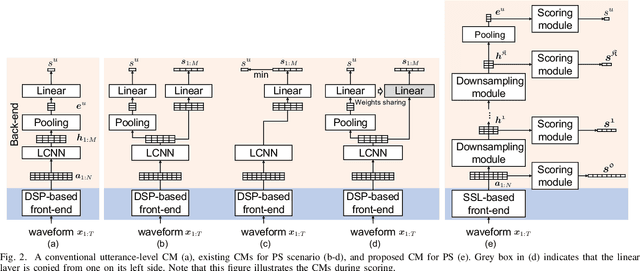
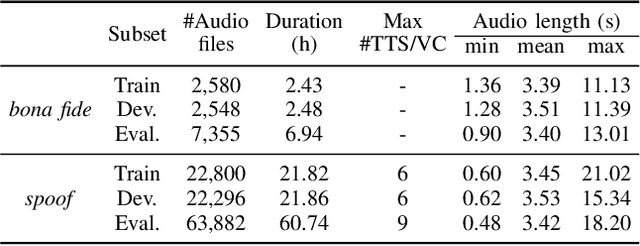
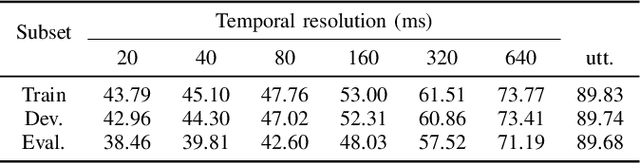
Automatic speaker verification is susceptible to various manipulations and spoofing, such as text-to-speech (TTS) synthesis, voice conversion (VC), replay, tampering, and so on. In this paper, we consider a new spoofing scenario called "Partial Spoof" (PS) in which synthesized or transformed audio segments are embedded into a bona fide speech utterance. While existing countermeasures (CMs) can detect fully spoofed utterances, there is a need for their adaptation or extension to the PS scenario to detect utterances in which only a part of the audio signal is generated and hence only a fraction of an utterance is spoofed. For improved explainability, such new CMs should ideally also be able to detect such short spoofed segments. Our previous study introduced the first version of a speech database suitable for training CMs for the PS scenario and showed that, although it is possible to train CMs to execute the two types of detection described above, there is much room for improvement. In this paper we propose various improvements to construct a significantly more accurate CM that can detect short generated spoofed audio segments at finer temporal resolutions. First, we introduce newly proposed self-supervised pre-trained models as enhanced feature extractors. Second, we extend the PartialSpoof database by adding segment labels for various temporal resolutions, ranging from 20 ms to 640 ms. Third, we propose a new CM and training strategies that enable the simultaneous use of the utterance-level and segment-level labels at different temporal resolutions. We also show that the proposed CM is capable of detecting spoofing at the utterance level with low error rates, not only in the PS scenario but also in a related logical access (LA) scenario. The equal error rates of utterance-level detection on the PartialSpoof and the ASVspoof 2019 LA database were 0.47% and 0.59%, respectively.
Baseline Systems for the First Spoofing-Aware Speaker Verification Challenge: Score and Embedding Fusion
Apr 21, 2022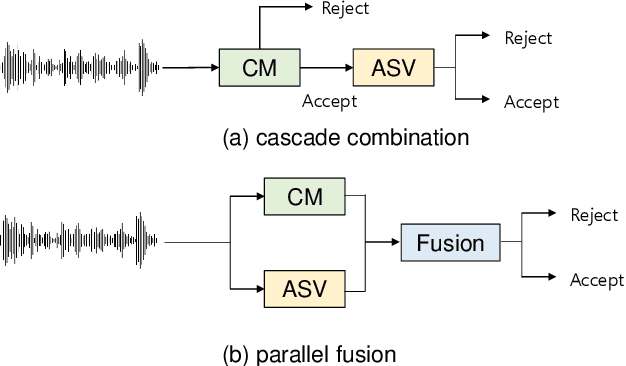

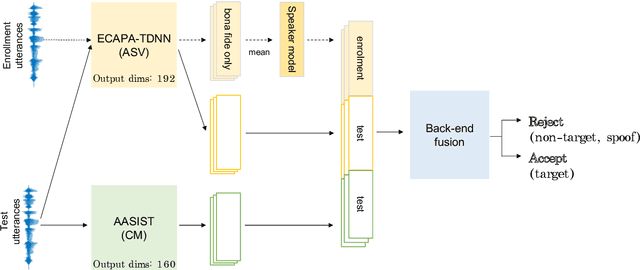
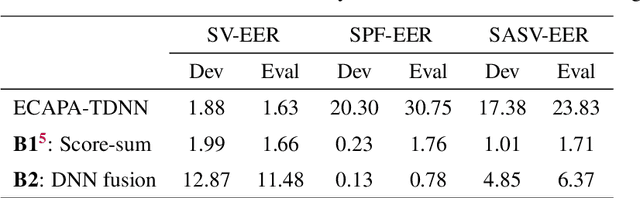
Deep learning has brought impressive progress in the study of both automatic speaker verification (ASV) and spoofing countermeasures (CM). Although solutions are mutually dependent, they have typically evolved as standalone sub-systems whereby CM solutions are usually designed for a fixed ASV system. The work reported in this paper aims to gauge the improvements in reliability that can be gained from their closer integration. Results derived using the popular ASVspoof2019 dataset indicate that the equal error rate (EER) of a state-of-the-art ASV system degrades from 1.63% to 23.83% when the evaluation protocol is extended with spoofed trials.%subjected to spoofing attacks. However, even the straightforward integration of ASV and CM systems in the form of score-sum and deep neural network-based fusion strategies reduce the EER to 1.71% and 6.37%, respectively. The new Spoofing-Aware Speaker Verification (SASV) challenge has been formed to encourage greater attention to the integration of ASV and CM systems as well as to provide a means to benchmark different solutions.
SASV 2022: The First Spoofing-Aware Speaker Verification Challenge
Mar 28, 2022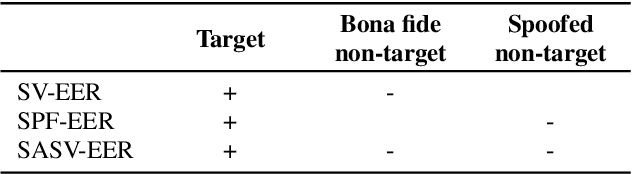
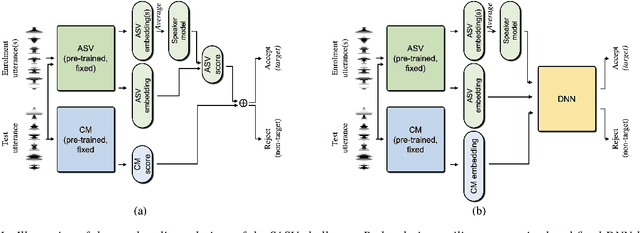
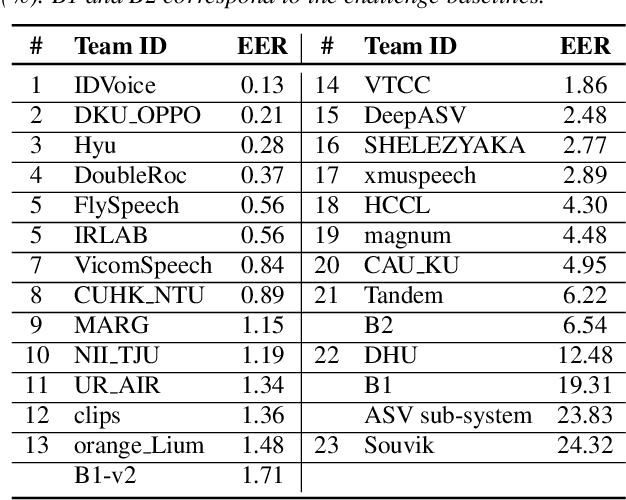
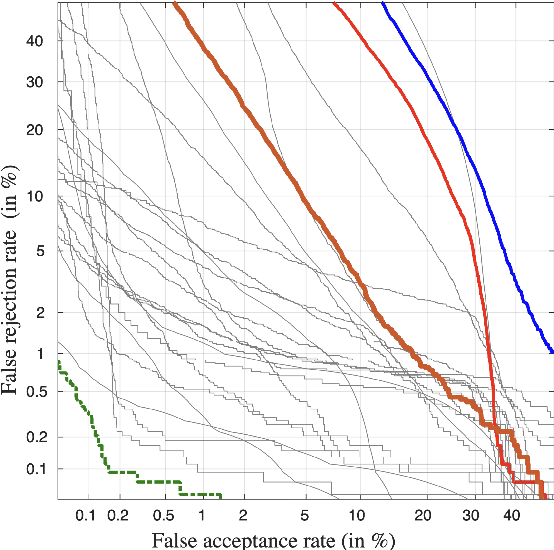
The first spoofing-aware speaker verification (SASV) challenge aims to integrate research efforts in speaker verification and anti-spoofing. We extend the speaker verification scenario by introducing spoofed trials to the usual set of target and impostor trials. In contrast to the established ASVspoof challenge where the focus is upon separate, independently optimised spoofing detection and speaker verification sub-systems, SASV targets the development of integrated and jointly optimised solutions. Pre-trained spoofing detection and speaker verification models are provided as open source and are used in two baseline SASV solutions. Both models and baselines are freely available to participants and can be used to develop back-end fusion approaches or end-to-end solutions. Using the provided common evaluation protocol, 23 teams submitted SASV solutions. When assessed with target, bona fide non-target and spoofed non-target trials, the top-performing system reduces the equal error rate of a conventional speaker verification system from 23.83% to 0.13%. SASV challenge results are a testament to the reliability of today's state-of-the-art approaches to spoofing detection and speaker verification.
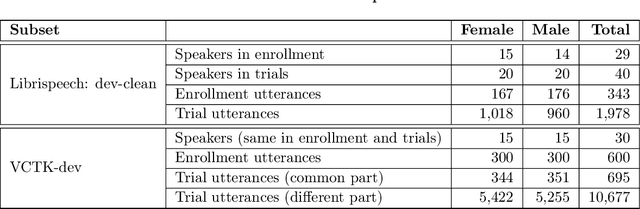
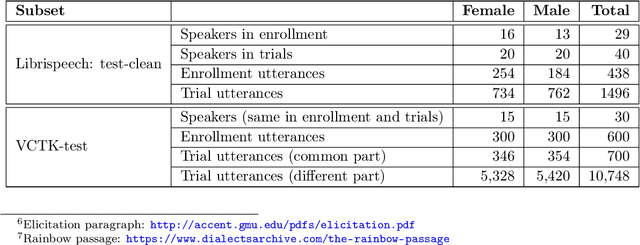
The VoicePrivacy 2022 Challenge Evaluation Plan
Mar 27, 2022For new participants - Executive summary: (1) The task is to develop a voice anonymization system for speech data which conceals the speaker's voice identity while protecting linguistic content, paralinguistic attributes, intelligibility and naturalness. (2) Training, development and evaluation datasets are provided in addition to 3 different baseline anonymization systems, evaluation scripts, and metrics. Participants apply their developed anonymization systems, run evaluation scripts and submit objective evaluation results and anonymized speech data to the organizers. (3) Results will be presented at a workshop held in conjunction with INTERSPEECH 2022 to which all participants are invited to present their challenge systems and to submit additional workshop papers. For readers familiar with the VoicePrivacy Challenge - Changes w.r.t. 2020: (1) A stronger, semi-informed attack model in the form of an automatic speaker verification (ASV) system trained on anonymized (per-utterance) speech data. (2) Complementary metrics comprising the equal error rate (EER) as a privacy metric, the word error rate (WER) as a primary utility metric, and the pitch correlation and gain of voice distinctiveness as secondary utility metrics. (3) A new ranking policy based upon a set of minimum target privacy requirements.
Automatic speaker verification spoofing and deepfake detection using wav2vec 2.0 and data augmentation
Feb 28, 2022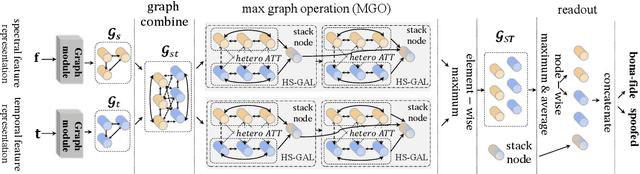
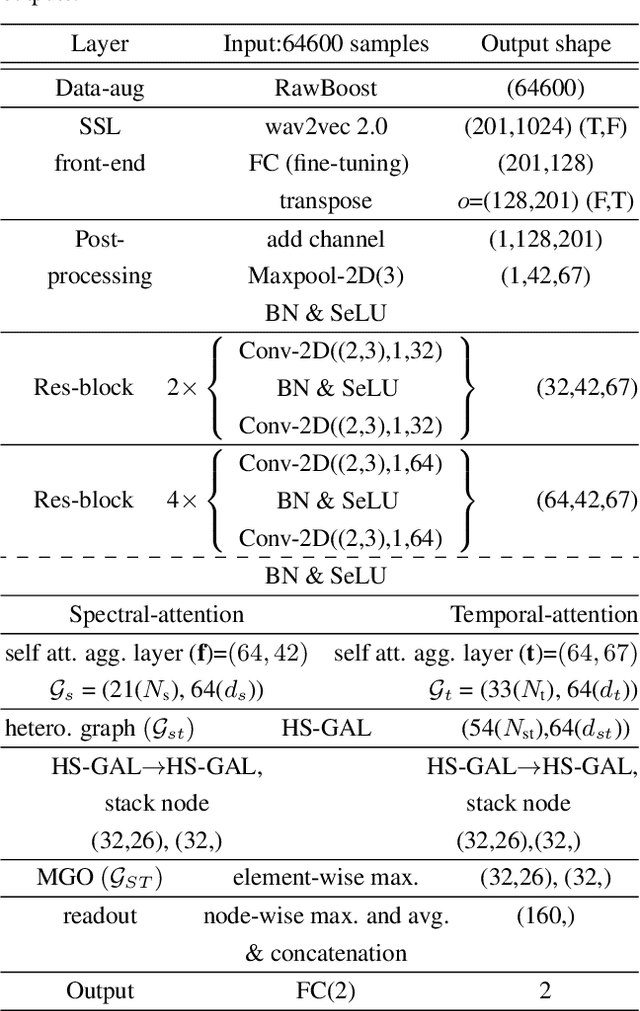
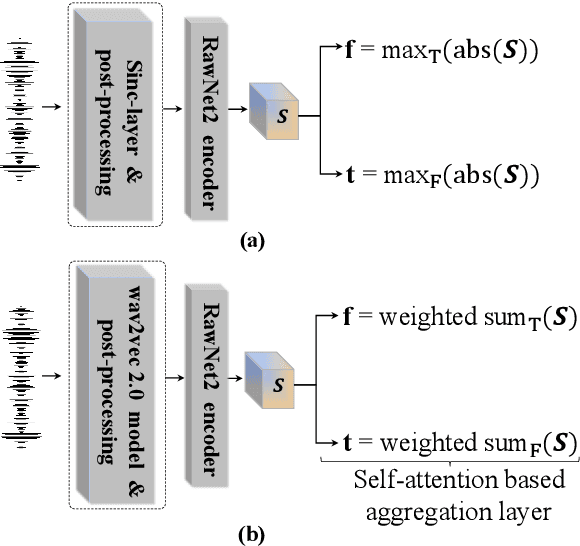
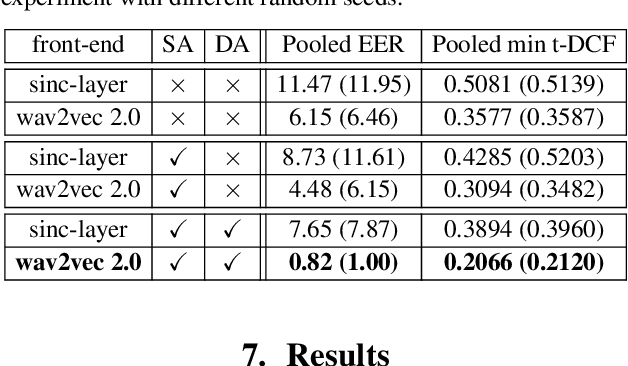
The performance of spoofing countermeasure systems depends fundamentally upon the use of sufficiently representative training data. With this usually being limited, current solutions typically lack generalisation to attacks encountered in the wild. Strategies to improve reliability in the face of uncontrolled, unpredictable attacks are hence needed. We report in this paper our efforts to use self-supervised learning in the form of a wav2vec 2.0 front-end with fine tuning. Despite initial base representations being learned using only bona fide data and no spoofed data, we obtain the lowest equal error rates reported in the literature for both the ASVspoof 2021 Logical Access and Deepfake databases. When combined with data augmentation,these results correspond to an improvement of almost 90% relative to our baseline system.
Explainable deepfake and spoofing detection: an attack analysis using SHapley Additive exPlanations
Feb 28, 2022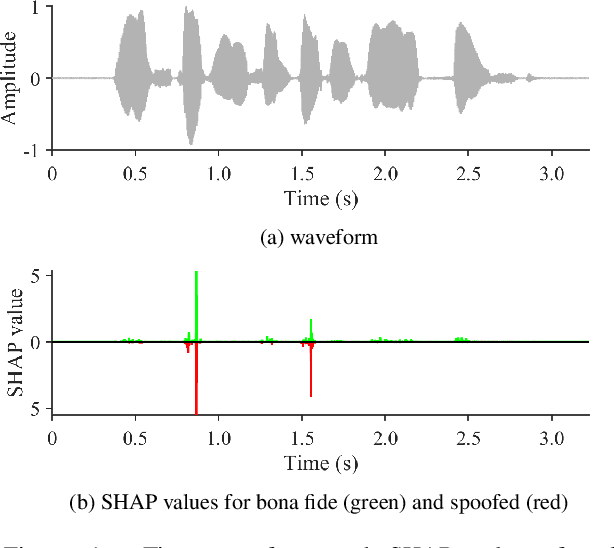
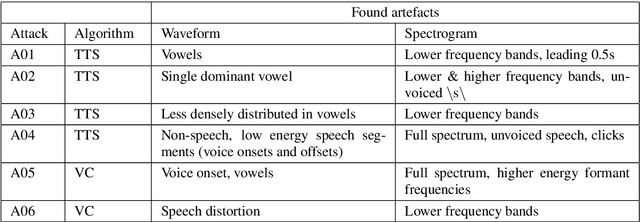
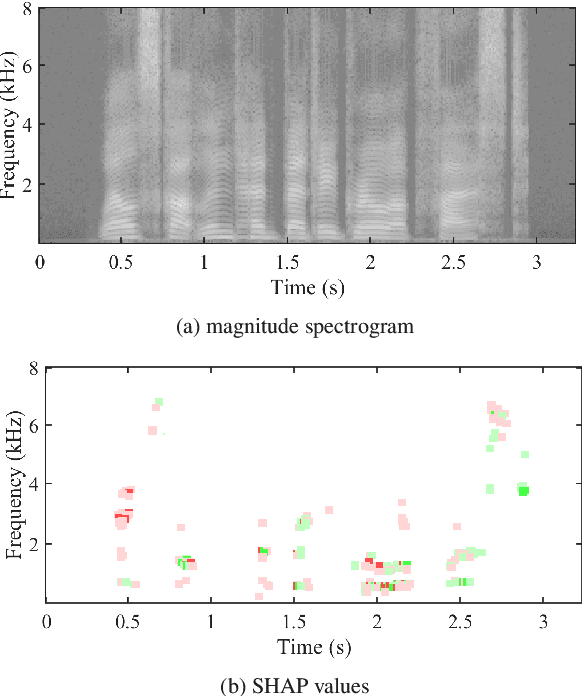
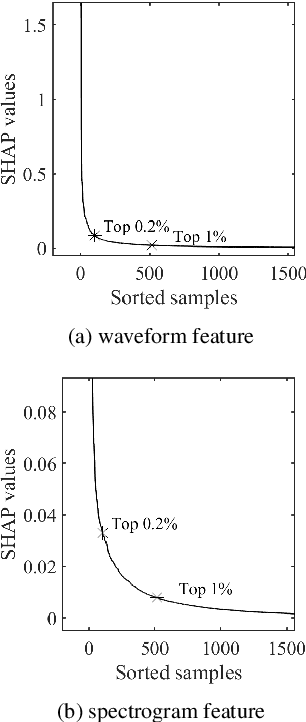
Despite several years of research in deepfake and spoofing detection for automatic speaker verification, little is known about the artefacts that classifiers use to distinguish between bona fide and spoofed utterances. An understanding of these is crucial to the design of trustworthy, explainable solutions. In this paper we report an extension of our previous work to better understand classifier behaviour to the use of SHapley Additive exPlanations (SHAP) to attack analysis. Our goal is to identify the artefacts that characterise utterances generated by different attacks algorithms. Using a pair of classifiers which operate either upon raw waveforms or magnitude spectrograms, we show that visualisations of SHAP results can be used to identify attack-specific artefacts and the differences and consistencies between synthetic speech and converted voice spoofing attacks.