 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFORML: Learning to Reweight Data for Fairness
Feb 03, 2022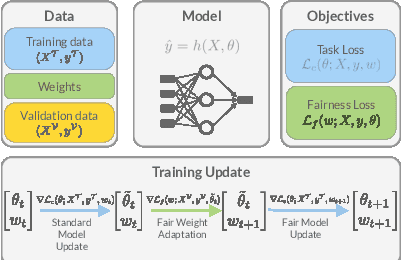

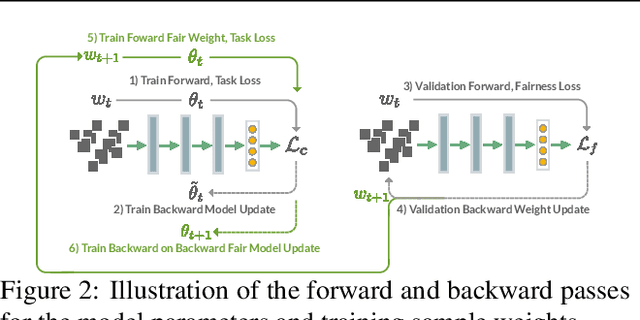
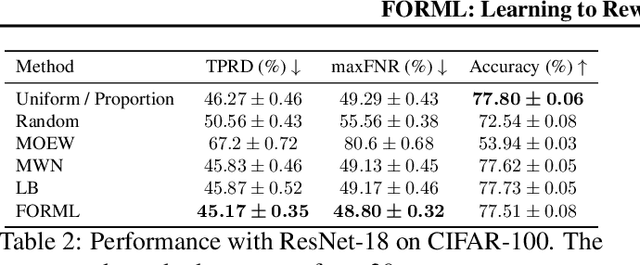
Deployed machine learning models are evaluated by multiple metrics beyond accuracy, such as fairness and robustness. However, such models are typically trained to minimize the average loss for a single metric, which is typically a proxy for accuracy. Training to optimize a single metric leaves these models prone to fairness violations, especially when the population of sub-groups in the training data are imbalanced. This work addresses the challenge of jointly optimizing fairness and predictive performance in the multi-class classification setting by introducing Fairness Optimized Reweighting via Meta-Learning (FORML), a training algorithm that balances fairness constraints and accuracy by jointly optimizing training sample weights and a neural network's parameters. The approach increases fairness by learning to weight each training datum's contribution to the loss according to its impact on reducing fairness violations, balancing the contributions from both over- and under-represented sub-groups. We empirically validate FORML on a range of benchmark and real-world classification datasets and show that our approach improves equality of opportunity fairness criteria over existing state-of-the-art reweighting methods by approximately 1% on image classification tasks and by approximately 5% on a face attribute prediction task. This improvement is achieved without pre-processing data or post-processing model outputs, without learning an additional weighting function, and while maintaining accuracy on the original predictive metric.
Challenges of Adversarial Image Augmentations
Dec 03, 2021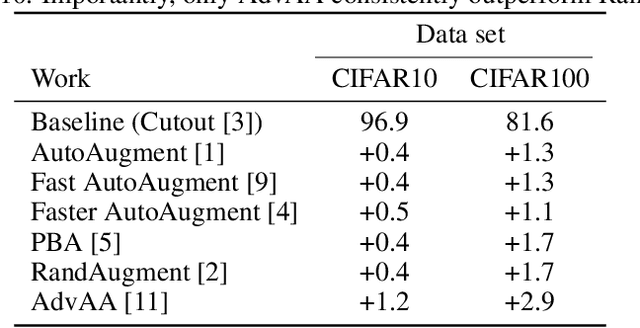
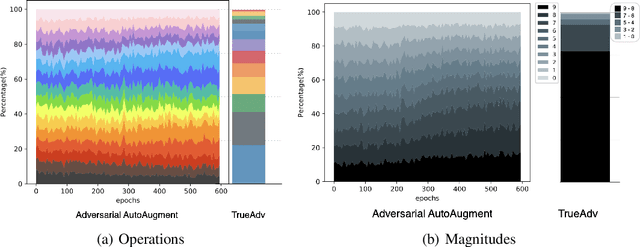


Image augmentations applied during training are crucial for the generalization performance of image classifiers. Therefore, a large body of research has focused on finding the optimal augmentation policy for a given task. Yet, RandAugment [2], a simple random augmentation policy, has recently been shown to outperform existing sophisticated policies. Only Adversarial AutoAugment (AdvAA) [11], an approach based on the idea of adversarial training, has shown to be better than RandAugment. In this paper, we show that random augmentations are still competitive compared to an optimal adversarial approach, as well as to simple curricula, and conjecture that the success of AdvAA is due to the stochasticity of the policy controller network, which introduces a mild form of curriculum.
Self-conditioning pre-trained language models
Sep 30, 2021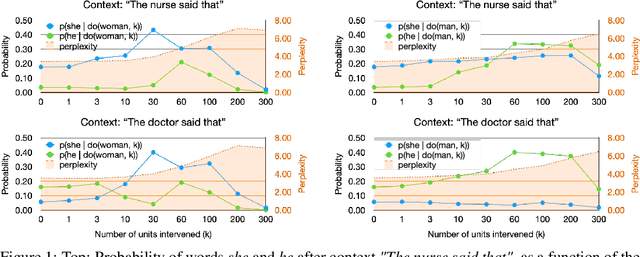
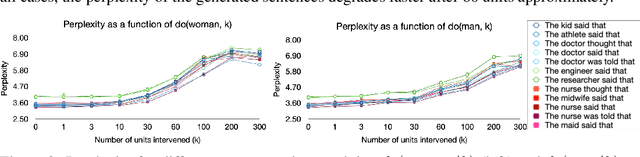
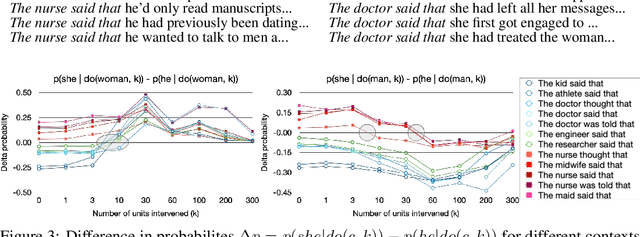
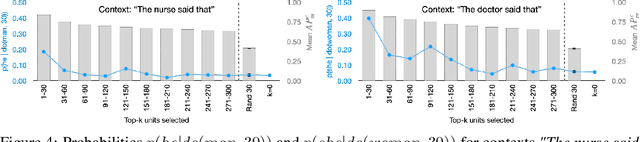
We study the presence of expert units in pre-trained Transformer-based Language Models (TLMs), and how they can be used to condition text generation to contain specific concepts. We define expert units to be neurons that are able to detect a concept in the input with a given average precision. A concept is represented with a set of sentences that either do or do not contain the concept. Leveraging the OneSec dataset, we compile a dataset of 1344 concepts that allows diverse expert units in TLMs to be discovered. Our experiments demonstrate that off-the-shelf pre-trained TLMs can be conditioned on their own knowledge (self-conditioning) to generate text that contains a given concept. To this end, we intervene on the top expert units by fixing their output during inference, and we show experimentally that this is an effective method to condition TLMs. Our method does not require fine-tuning the model or using additional parameters, which allows conditioning large TLM with minimal compute resources. Furthermore, by intervening on a small number of experts in GPT2, we can achieve parity with respect to two concepts at generation time. The specific case of gender bias is explored, and we show that, for given contexts, gender parity is achieved while maintaining the model's perplexity.
Multimodal Punctuation Prediction with Contextual Dropout
Feb 12, 2021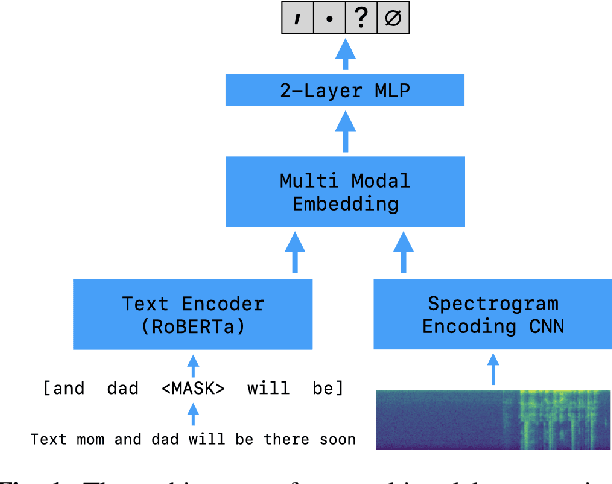

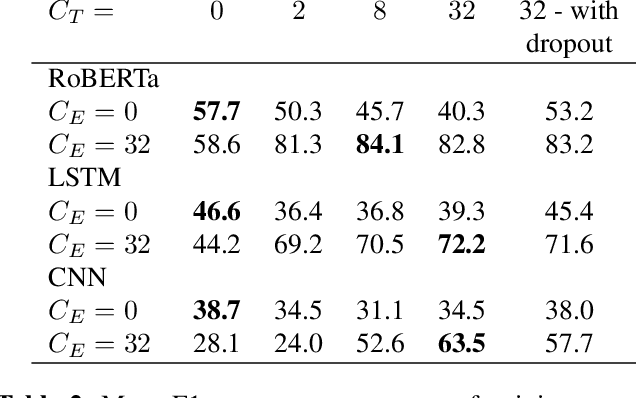
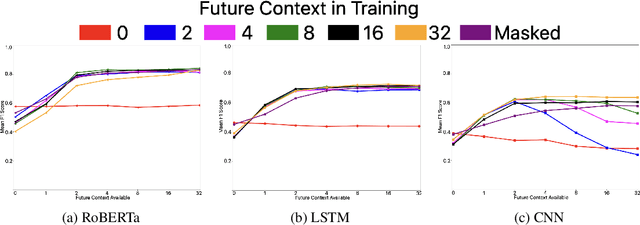
Automatic speech recognition (ASR) is widely used in consumer electronics. ASR greatly improves the utility and accessibility of technology, but usually the output is only word sequences without punctuation. This can result in ambiguity in inferring user-intent. We first present a transformer-based approach for punctuation prediction that achieves 8% improvement on the IWSLT 2012 TED Task, beating the previous state of the art [1]. We next describe our multimodal model that learns from both text and audio, which achieves 8% improvement over the text-only algorithm on an internal dataset for which we have both the audio and transcriptions. Finally, we present an approach to learning a model using contextual dropout that allows us to handle variable amounts of future context at test time.
MorphGAN: One-Shot Face Synthesis GAN for Detecting Recognition Bias
Dec 10, 2020
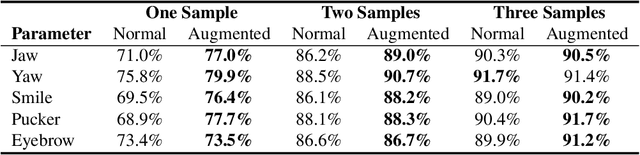
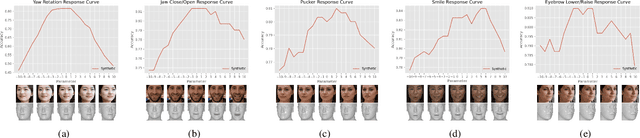

To detect bias in face recognition networks, it can be useful to probe a network under test using samples in which only specific attributes vary in some controlled way. However, capturing a sufficiently large dataset with specific control over the attributes of interest is difficult. In this work, we describe a simulator that applies specific head pose and facial expression adjustments to images of previously unseen people. The simulator first fits a 3D morphable model to a provided image, applies the desired head pose and facial expression controls, then renders the model into an image. Next, a conditional Generative Adversarial Network (GAN) conditioned on the original image and the rendered morphable model is used to produce the image of the original person with the new facial expression and head pose. We call this conditional GAN -- MorphGAN. Images generated using MorphGAN conserve the identity of the person in the original image, and the provided control over head pose and facial expression allows test sets to be created to identify robustness issues of a facial recognition deep network with respect to pose and expression. Images generated by MorphGAN can also serve as data augmentation when training data are scarce. We show that by augmenting small datasets of faces with new poses and expressions improves the recognition performance by up to 9% depending on the augmentation and data scarcity.
Modality Dropout for Improved Performance-driven Talking Faces
May 27, 2020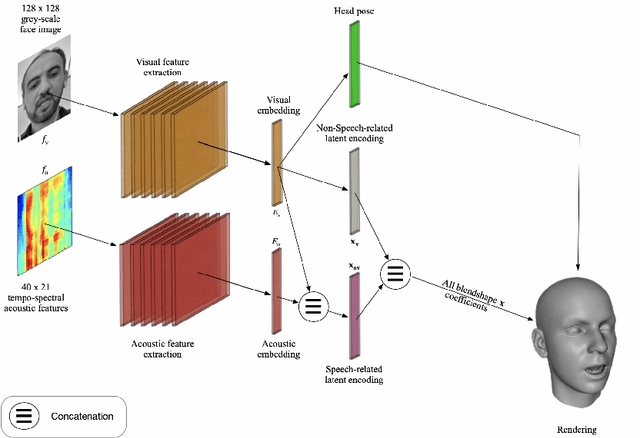
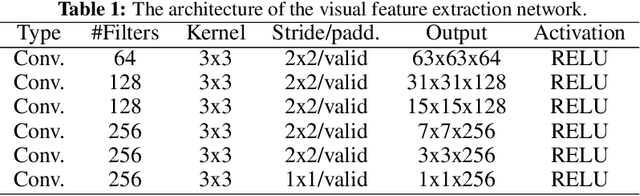
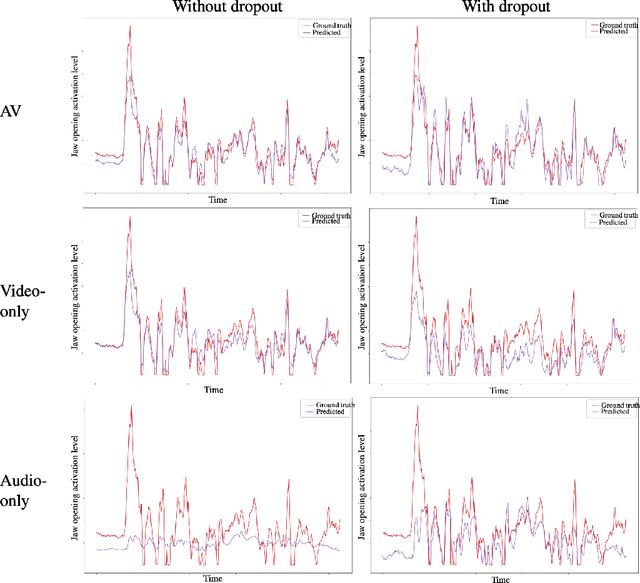

We describe our novel deep learning approach for driving animated faces using both acoustic and visual information. In particular, speech-related facial movements are generated using audiovisual information, and non-speech facial movements are generated using only visual information. To ensure that our model exploits both modalities during training, batches are generated that contain audio-only, video-only, and audiovisual input features. The probability of dropping a modality allows control over the degree to which the model exploits audio and visual information during training. Our trained model runs in real-time on resource limited hardware (e.g.\ a smart phone), it is user agnostic, and it is not dependent on a potentially error-prone transcription of the speech. We use subjective testing to demonstrate: 1) the improvement of audiovisual-driven animation over the equivalent video-only approach, and 2) the improvement in the animation of speech-related facial movements after introducing modality dropout. Before introducing dropout, viewers prefer audiovisual-driven animation in 51% of the test sequences compared with only 18% for video-driven. After introducing dropout viewer preference for audiovisual-driven animation increases to 74%, but decreases to 8% for video-only.
Finding Experts in Transformer Models
May 15, 2020
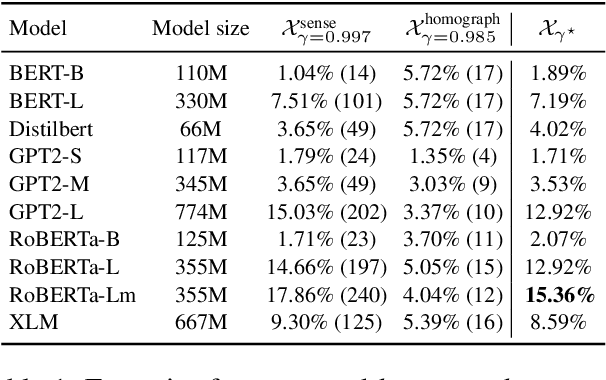
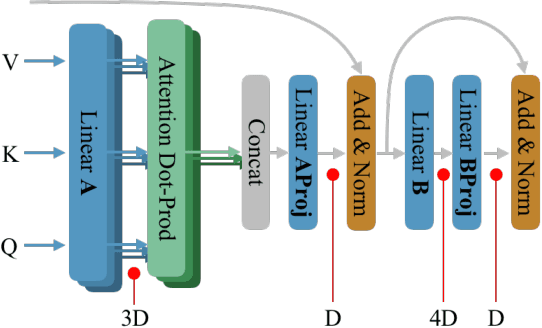
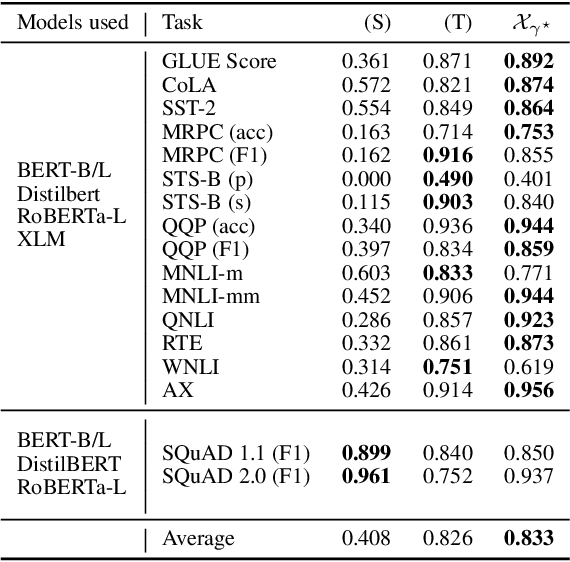
In this work we study the presence of expert units in pre-trained Transformer Models (TM), and how they impact a model's performance. We define expert units to be neurons that are able to classify a concept with a given average precision, where a concept is represented by a binary set of sentences containing the concept (or not). Leveraging the OneSec dataset (Scarlini et al., 2019), we compile a dataset of 1641 concepts that allows diverse expert units in TM to be discovered. We show that expert units are important in several ways: (1) The presence of expert units is correlated ($r^2=0.833$) with the generalization power of TM, which allows ranking TM without requiring fine-tuning on suites of downstream tasks. We further propose an empirical method to decide how accurate such experts should be to evaluate generalization. (2) The overlap of top experts between concepts provides a sensible way to quantify concept co-learning, which can be used for explainability of unknown concepts. (3) We show how to self-condition off-the-shelf pre-trained language models to generate text with a given concept by forcing the top experts to be active, without requiring re-training the model or using additional parameters.
Speaker-Independent Speech-Driven Visual Speech Synthesis using Domain-Adapted Acoustic Models
May 15, 2019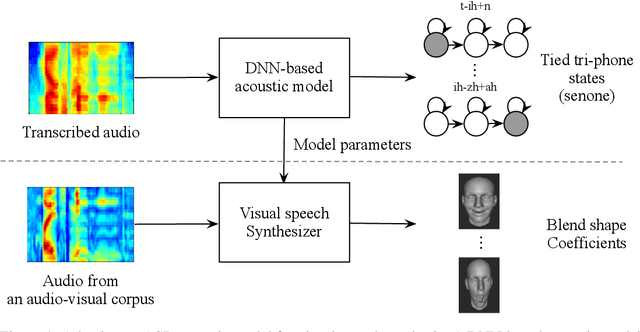

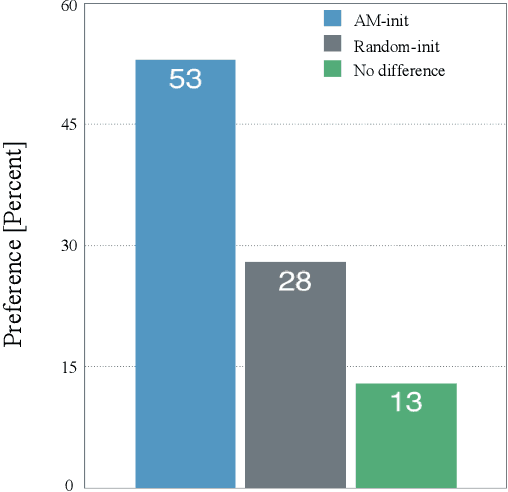
Speech-driven visual speech synthesis involves mapping features extracted from acoustic speech to the corresponding lip animation controls for a face model. This mapping can take many forms, but a powerful approach is to use deep neural networks (DNNs). However, a limitation is the lack of synchronized audio, video, and depth data required to reliably train the DNNs, especially for speaker-independent models. In this paper, we investigate adapting an automatic speech recognition (ASR) acoustic model (AM) for the visual speech synthesis problem. We train the AM on ten thousand hours of audio-only data. The AM is then adapted to the visual speech synthesis domain using ninety hours of synchronized audio-visual speech. Using a subjective assessment test, we compared the performance of the AM-initialized DNN to one with a random initialization. The results show that viewers significantly prefer animations generated from the AM-initialized DNN than the ones generated using the randomly initialized model. We conclude that visual speech synthesis can significantly benefit from the powerful representation of speech in the ASR acoustic models.
Mirroring to Build Trust in Digital Assistants
Apr 02, 2019
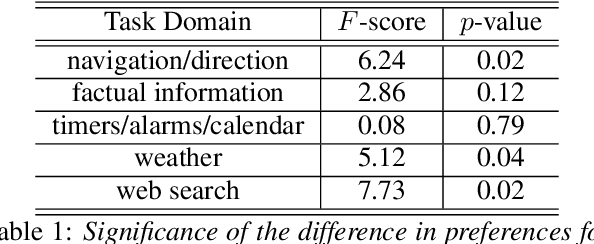
We describe experiments towards building a conversational digital assistant that considers the preferred conversational style of the user. In particular, these experiments are designed to measure whether users prefer and trust an assistant whose conversational style matches their own. To this end we conducted a user study where subjects interacted with a digital assistant that responded in a way that either matched their conversational style, or did not. Using self-reported personality attributes and subjects' feedback on the interactions, we built models that can reliably predict a user's preferred conversational style.
Learning Sharing Behaviors with Arbitrary Numbers of Agents
Dec 10, 2018

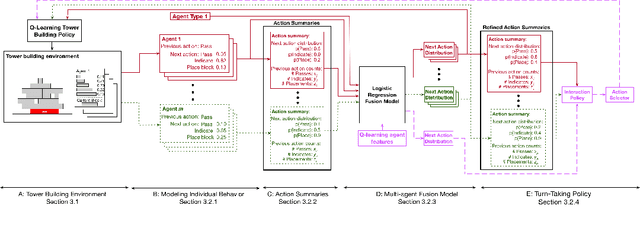
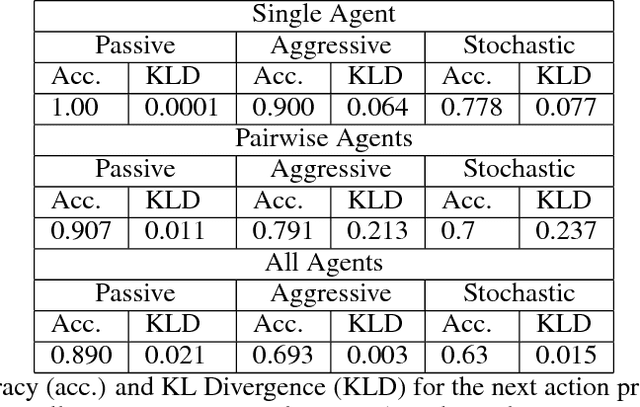
We propose a method for modeling and learning turn-taking behaviors for accessing a shared resource. We model the individual behavior for each agent in an interaction and then use a multi-agent fusion model to generate a summary over the expected actions of the group to render the model independent of the number of agents. The individual behavior models are weighted finite state transducers (WFSTs) with weights dynamically updated during interactions, and the multi-agent fusion model is a logistic regression classifier. We test our models in a multi-agent tower-building environment, where a Q-learning agent learns to interact with rule-based agents. Our approach accurately models the underlying behavior patterns of the rule-based agents with accuracy ranging between 0.63 and 1.0 depending on the stochasticity of the other agent behaviors. In addition we show using KL-divergence that the model accurately captures the distribution of next actions when interacting with both a single agent (KL-divergence < 0.1) and with multiple agents (KL-divergence < 0.37). Finally, we demonstrate that our behavior model can be used by a Q-learning agent to take turns in an interactive turn-taking environment.