 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Abstraction for Knowledge-based Semantic Communication: A Generative Causality Invariant Approach
Jul 23, 2025In this study, we design a low-complexity and generalized AI model that can capture common knowledge to improve data reconstruction of the channel decoder for semantic communication. Specifically, we propose a generative adversarial network that leverages causality-invariant learning to extract causal and non-causal representations from the data. Causal representations are invariant and encompass crucial information to identify the data's label. They can encapsulate semantic knowledge and facilitate effective data reconstruction at the receiver. Moreover, the causal mechanism ensures that learned representations remain consistent across different domains, making the system reliable even with users collecting data from diverse domains. As user-collected data evolves over time causing knowledge divergence among users, we design sparse update protocols to improve the invariant properties of the knowledge while minimizing communication overheads. Three key observations were drawn from our empirical evaluations. Firstly, causality-invariant knowledge ensures consistency across different devices despite the diverse training data. Secondly, invariant knowledge has promising performance in classification tasks, which is pivotal for goal-oriented semantic communications. Thirdly, our knowledge-based data reconstruction highlights the robustness of our decoder, which surpasses other state-of-the-art data reconstruction and semantic compression methods in terms of Peak Signal-to-Noise Ratio (PSNR).
Federated Koopman-Reservoir Learning for Large-Scale Multivariate Time-Series Anomaly Detection
Mar 14, 2025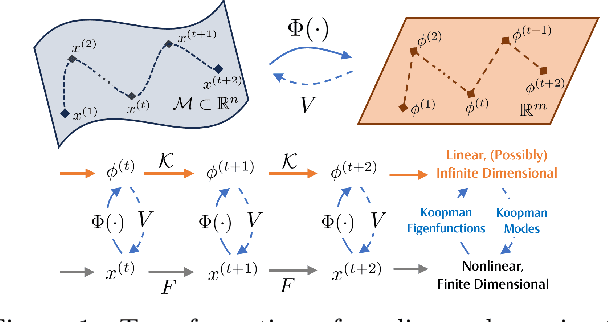
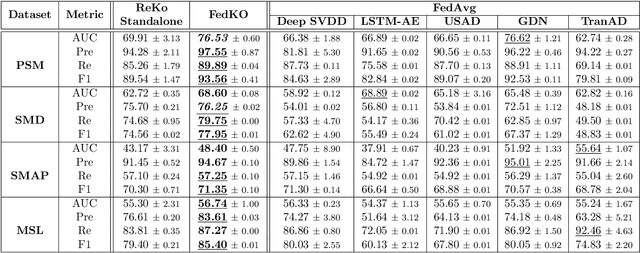
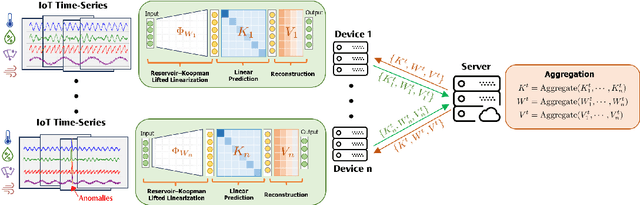
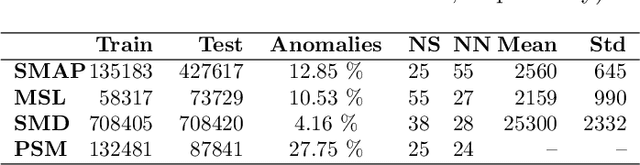
The proliferation of edge devices has dramatically increased the generation of multivariate time-series (MVTS) data, essential for applications from healthcare to smart cities. Such data streams, however, are vulnerable to anomalies that signal crucial problems like system failures or security incidents. Traditional MVTS anomaly detection methods, encompassing statistical and centralized machine learning approaches, struggle with the heterogeneity, variability, and privacy concerns of large-scale, distributed environments. In response, we introduce FedKO, a novel unsupervised Federated Learning framework that leverages the linear predictive capabilities of Koopman operator theory along with the dynamic adaptability of Reservoir Computing. This enables effective spatiotemporal processing and privacy preservation for MVTS data. FedKO is formulated as a bi-level optimization problem, utilizing a specific federated algorithm to explore a shared Reservoir-Koopman model across diverse datasets. Such a model is then deployable on edge devices for efficient detection of anomalies in local MVTS streams. Experimental results across various datasets showcase FedKO's superior performance against state-of-the-art methods in MVTS anomaly detection. Moreover, FedKO reduces up to 8x communication size and 2x memory usage, making it highly suitable for large-scale systems.
Towards Layer-Wise Personalized Federated Learning: Adaptive Layer Disentanglement via Conflicting Gradients
Oct 03, 2024



In personalized Federated Learning (pFL), high data heterogeneity can cause significant gradient divergence across devices, adversely affecting the learning process. This divergence, especially when gradients from different users form an obtuse angle during aggregation, can negate progress, leading to severe weight and gradient update degradation. To address this issue, we introduce a new approach to pFL design, namely Federated Learning with Layer-wise Aggregation via Gradient Analysis (FedLAG), utilizing the concept of gradient conflict at the layer level. Specifically, when layer-wise gradients of different clients form acute angles, those gradients align in the same direction, enabling updates across different clients toward identifying client-invariant features. Conversely, when layer-wise gradient pairs make create obtuse angles, the layers tend to focus on client-specific tasks. In hindsights, FedLAG assigns layers for personalization based on the extent of layer-wise gradient conflicts. Specifically, layers with gradient conflicts are excluded from the global aggregation process. The theoretical evaluation demonstrates that when integrated into other pFL baselines, FedLAG enhances pFL performance by a certain margin. Therefore, our proposed method achieves superior convergence behavior compared with other baselines. Extensive experiments show that our FedLAG outperforms several state-of-the-art methods and can be easily incorporated with many existing methods to further enhance performance.
Federated PCA on Grassmann Manifold for IoT Anomaly Detection
Jul 10, 2024



With the proliferation of the Internet of Things (IoT) and the rising interconnectedness of devices, network security faces significant challenges, especially from anomalous activities. While traditional machine learning-based intrusion detection systems (ML-IDS) effectively employ supervised learning methods, they possess limitations such as the requirement for labeled data and challenges with high dimensionality. Recent unsupervised ML-IDS approaches such as AutoEncoders and Generative Adversarial Networks (GAN) offer alternative solutions but pose challenges in deployment onto resource-constrained IoT devices and in interpretability. To address these concerns, this paper proposes a novel federated unsupervised anomaly detection framework, FedPCA, that leverages Principal Component Analysis (PCA) and the Alternating Directions Method Multipliers (ADMM) to learn common representations of distributed non-i.i.d. datasets. Building on the FedPCA framework, we propose two algorithms, FEDPE in Euclidean space and FEDPG on Grassmann manifolds. Our approach enables real-time threat detection and mitigation at the device level, enhancing network resilience while ensuring privacy. Moreover, the proposed algorithms are accompanied by theoretical convergence rates even under a subsampling scheme, a novel result. Experimental results on the UNSW-NB15 and TON-IoT datasets show that our proposed methods offer performance in anomaly detection comparable to nonlinear baselines, while providing significant improvements in communication and memory efficiency, underscoring their potential for securing IoT networks.
* Accepted for publication at IEEE/ACM Transactions on Networking
$i$REPO: $i$mplicit Reward Pairwise Difference based Empirical Preference Optimization
May 24, 2024



While astonishingly capable, large Language Models (LLM) can sometimes produce outputs that deviate from human expectations. Such deviations necessitate an alignment phase to prevent disseminating untruthful, toxic, or biased information. Traditional alignment methods based on reinforcement learning often struggle with the identified instability, whereas preference optimization methods are limited by their overfitting to pre-collected hard-label datasets. In this paper, we propose a novel LLM alignment framework named $i$REPO, which utilizes implicit Reward pairwise difference regression for Empirical Preference Optimization. Particularly, $i$REPO employs self-generated datasets labelled by empirical human (or AI annotator) preference to iteratively refine the aligned policy through a novel regression-based loss function. Furthermore, we introduce an innovative algorithm backed by theoretical guarantees for achieving optimal results under ideal assumptions and providing a practical performance-gap result without such assumptions. Experimental results with Phi-2 and Mistral-7B demonstrate that $i$REPO effectively achieves self-alignment using soft-label, self-generated responses and the logit of empirical AI annotators. Furthermore, our approach surpasses preference optimization baselines in evaluations using the Language Model Evaluation Harness and Multi-turn benchmarks.
PAT: Pixel-wise Adaptive Training for Long-tailed Segmentation
Apr 09, 2024



Beyond class frequency, we recognize the impact of class-wise relationships among various class-specific predictions and the imbalance in label masks on long-tailed segmentation learning. To address these challenges, we propose an innovative Pixel-wise Adaptive Training (PAT) technique tailored for long-tailed segmentation. PAT has two key features: 1) class-wise gradient magnitude homogenization, and 2) pixel-wise class-specific loss adaptation (PCLA). First, the class-wise gradient magnitude homogenization helps alleviate the imbalance among label masks by ensuring equal consideration of the class-wise impact on model updates. Second, PCLA tackles the detrimental impact of both rare classes within the long-tailed distribution and inaccurate predictions from previous training stages by encouraging learning classes with low prediction confidence and guarding against forgetting classes with high confidence. This combined approach fosters robust learning while preventing the model from forgetting previously learned knowledge. PAT exhibits significant performance improvements, surpassing the current state-of-the-art by 2.2% in the NyU dataset. Moreover, it enhances overall pixel-wise accuracy by 2.85% and intersection over union value by 2.07%, with a particularly notable declination of 0.39% in detecting rare classes compared to Balance Logits Variation, as demonstrated on the three popular datasets, i.e., OxfordPetIII, CityScape, and NYU.
Federated Deep Equilibrium Learning: A Compact Shared Representation for Edge Communication Efficiency
Sep 27, 2023Federated Learning (FL) is a prominent distributed learning paradigm facilitating collaboration among nodes within an edge network to co-train a global model without centralizing data. By shifting computation to the network edge, FL offers robust and responsive edge-AI solutions and enhance privacy-preservation. However, deploying deep FL models within edge environments is often hindered by communication bottlenecks, data heterogeneity, and memory limitations. To address these challenges jointly, we introduce FeDEQ, a pioneering FL framework that effectively employs deep equilibrium learning and consensus optimization to exploit a compact shared data representation across edge nodes, allowing the derivation of personalized models specific to each node. We delve into a unique model structure composed of an equilibrium layer followed by traditional neural network layers. Here, the equilibrium layer functions as a global feature representation that edge nodes can adapt to personalize their local layers. Capitalizing on FeDEQ's compactness and representation power, we present a novel distributed algorithm rooted in the alternating direction method of multipliers (ADMM) consensus optimization and theoretically establish its convergence for smooth objectives. Experiments across various benchmarks demonstrate that FeDEQ achieves performance comparable to state-of-the-art personalized methods while employing models of up to 4 times smaller in communication size and 1.5 times lower memory footprint during training.
Federated PCA on Grassmann Manifold for Anomaly Detection in IoT Networks
Jan 10, 2023



In the era of Internet of Things (IoT), network-wide anomaly detection is a crucial part of monitoring IoT networks due to the inherent security vulnerabilities of most IoT devices. Principal Components Analysis (PCA) has been proposed to separate network traffics into two disjoint subspaces corresponding to normal and malicious behaviors for anomaly detection. However, the privacy concerns and limitations of devices' computing resources compromise the practical effectiveness of PCA. We propose a federated PCA-based Grassmannian optimization framework that coordinates IoT devices to aggregate a joint profile of normal network behaviors for anomaly detection. First, we introduce a privacy-preserving federated PCA framework to simultaneously capture the profile of various IoT devices' traffic. Then, we investigate the alternating direction method of multipliers gradient-based learning on the Grassmann manifold to guarantee fast training and the absence of detecting latency using limited computational resources. Empirical results on the NSL-KDD dataset demonstrate that our method outperforms baseline approaches. Finally, we show that the Grassmann manifold algorithm is highly adapted for IoT anomaly detection, which permits drastically reducing the analysis time of the system. To the best of our knowledge, this is the first federated PCA algorithm for anomaly detection meeting the requirements of IoT networks.
On the Generalization of Wasserstein Robust Federated Learning
Jun 03, 2022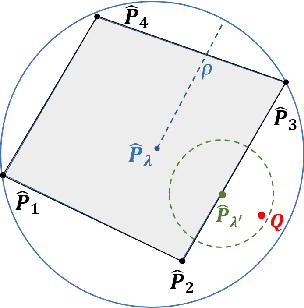
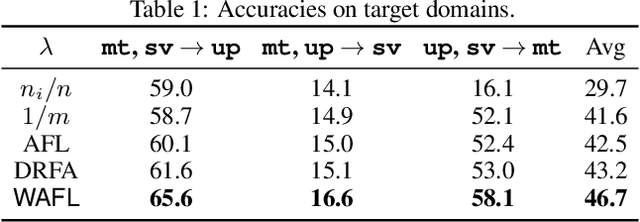
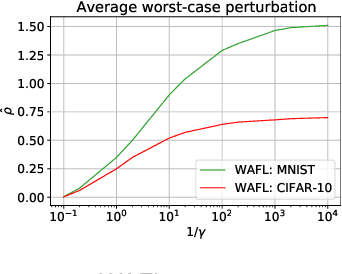
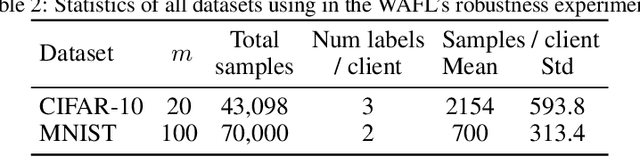
In federated learning, participating clients typically possess non-i.i.d. data, posing a significant challenge to generalization to unseen distributions. To address this, we propose a Wasserstein distributionally robust optimization scheme called WAFL. Leveraging its duality, we frame WAFL as an empirical surrogate risk minimization problem, and solve it using a local SGD-based algorithm with convergence guarantees. We show that the robustness of WAFL is more general than related approaches, and the generalization bound is robust to all adversarial distributions inside the Wasserstein ball (ambiguity set). Since the center location and radius of the Wasserstein ball can be suitably modified, WAFL shows its applicability not only in robustness but also in domain adaptation. Through empirical evaluation, we demonstrate that WAFL generalizes better than the vanilla FedAvg in non-i.i.d. settings, and is more robust than other related methods in distribution shift settings. Further, using benchmark datasets we show that WAFL is capable of generalizing to unseen target domains.
FedU: A Unified Framework for Federated Multi-Task Learning with Laplacian Regularization
Feb 14, 2021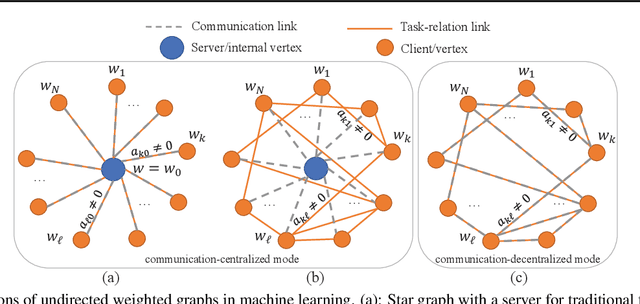
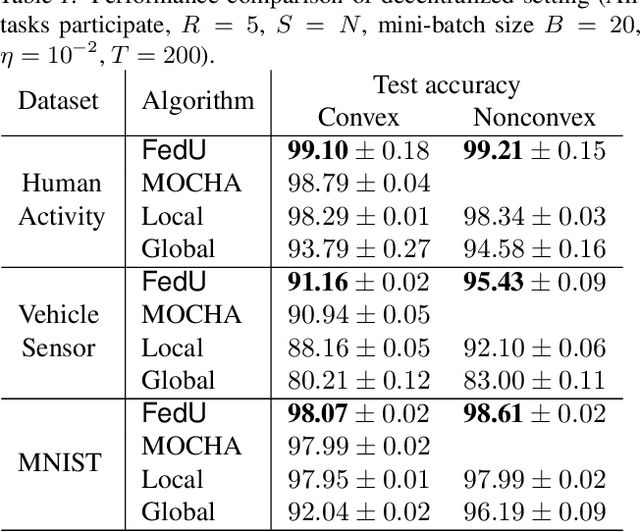
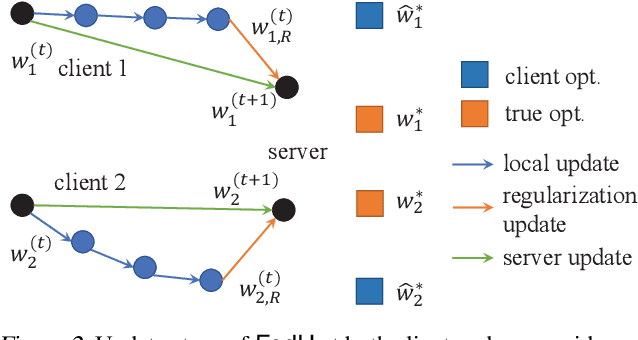
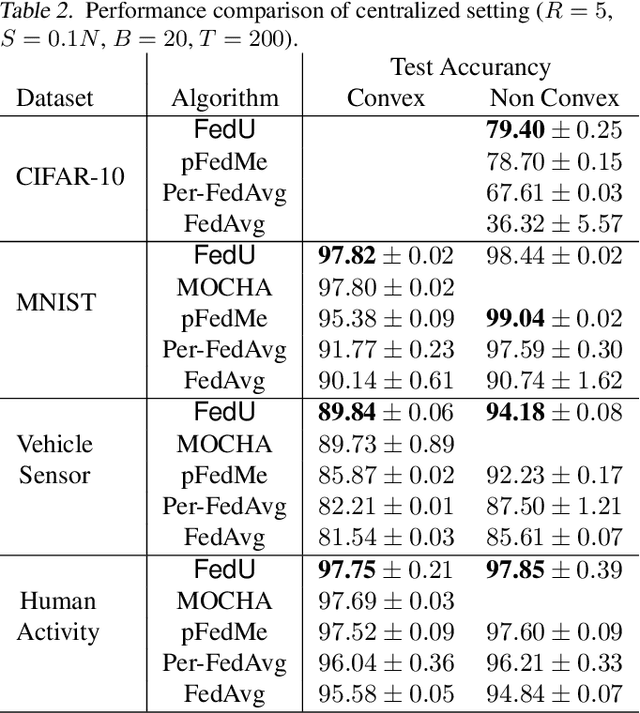
Federated multi-task learning (FMTL) has emerged as a natural choice to capture the statistical diversity among the clients in federated learning. To unleash the potential of FMTL beyond statistical diversity, we formulate a new FMTL problem FedU using Laplacian regularization, which can explicitly leverage relationships among the clients for multi-task learning. We first show that FedU provides a unified framework covering a wide range of problems such as conventional federated learning, personalized federated learning, few-shot learning, and stratified model learning. We then propose algorithms including both communication-centralized and decentralized schemes to learn optimal models of FedU. Theoretically, we show that the convergence rates of both FedU's algorithms achieve linear speedup for strongly convex and sublinear speedup of order $1/2$ for nonconvex objectives. While the analysis of FedU is applicable to both strongly convex and nonconvex loss functions, the conventional FMTL algorithm MOCHA, which is based on CoCoA framework, is only applicable to convex case. Experimentally, we verify that FedU outperforms the vanilla FedAvg, MOCHA, as well as pFedMe and Per-FedAvg in personalized federated learning.