 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Lexical Replacements for Arabic-English Code-Switched Data Augmentation
May 25, 2022
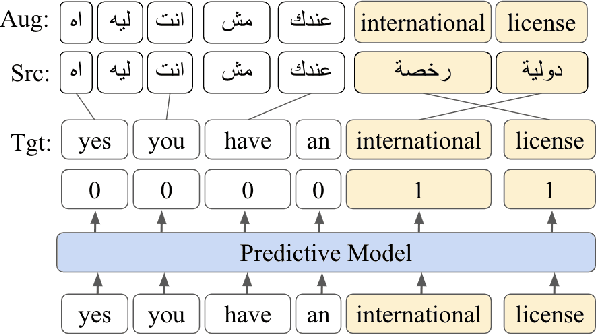

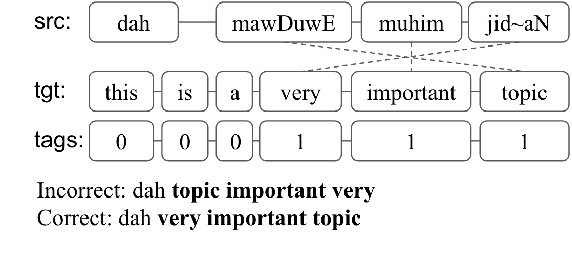
Code-switching (CS) poses several challenges to NLP tasks, where data sparsity is a main problem hindering the development of CS NLP systems. In this paper, we investigate data augmentation techniques for synthesizing Dialectal Arabic-English CS text. We perform lexical replacements using parallel corpora and alignments where CS points are either randomly chosen or learnt using a sequence-to-sequence model. We evaluate the effectiveness of data augmentation on language modeling (LM), machine translation (MT), and automatic speech recognition (ASR) tasks. Results show that in the case of using 1-1 alignments, using trained predictive models produces more natural CS sentences, as reflected in perplexity. By relying on grow-diag-final alignments, we then identify aligning segments and perform replacements accordingly. By replacing segments instead of words, the quality of synthesized data is greatly improved. With this improvement, random-based approach outperforms using trained predictive models on all extrinsic tasks. Our best models achieve 33.6% improvement in perplexity, +3.2-5.6 BLEU points on MT task, and 7% relative improvement on WER for ASR task. We also contribute in filling the gap in resources by collecting and publishing the first Arabic English CS-English parallel corpus.
Meta Learning for Natural Language Processing: A Survey
May 03, 2022
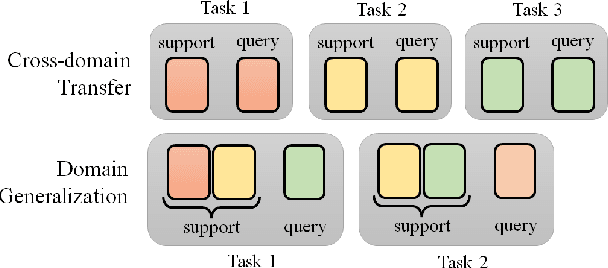

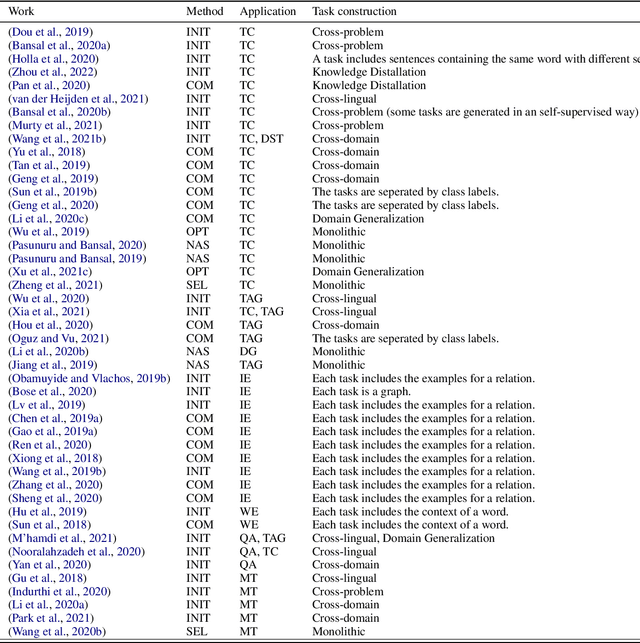
Deep learning has been the mainstream technique in natural language processing (NLP) area. However, the techniques require many labeled data and are less generalizable across domains. Meta-learning is an arising field in machine learning studying approaches to learn better learning algorithms. Approaches aim at improving algorithms in various aspects, including data efficiency and generalizability. Efficacy of approaches has been shown in many NLP tasks, but there is no systematic survey of these approaches in NLP, which hinders more researchers from joining the field. Our goal with this survey paper is to offer researchers pointers to relevant meta-learning works in NLP and attract more attention from the NLP community to drive future innovation. This paper first introduces the general concepts of meta-learning and the common approaches. Then we summarize task construction settings and application of meta-learning for various NLP problems and review the development of meta-learning in NLP community.
BPE vs. Morphological Segmentation: A Case Study on Machine Translation of Four Polysynthetic Languages
Mar 16, 2022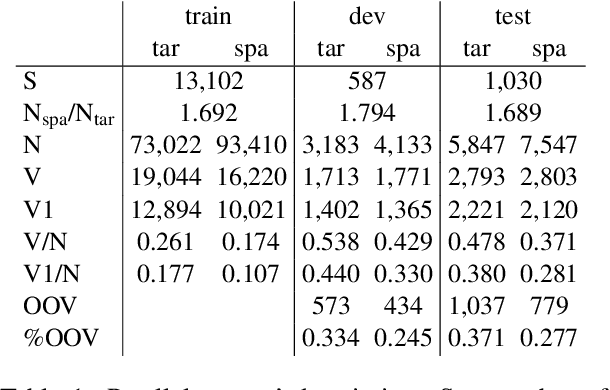
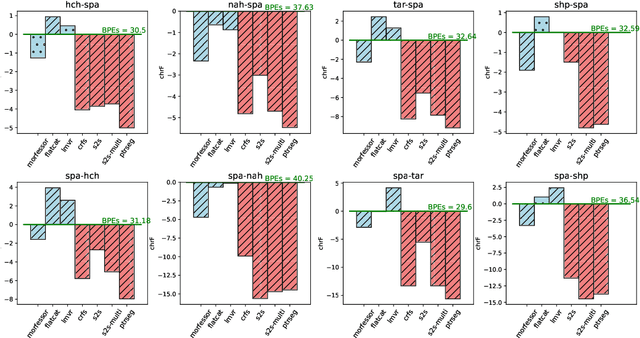
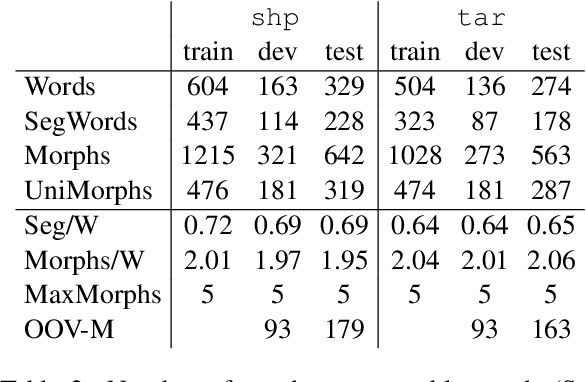
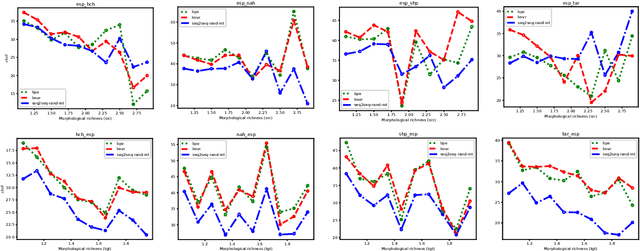
Morphologically-rich polysynthetic languages present a challenge for NLP systems due to data sparsity, and a common strategy to handle this issue is to apply subword segmentation. We investigate a wide variety of supervised and unsupervised morphological segmentation methods for four polysynthetic languages: Nahuatl, Raramuri, Shipibo-Konibo, and Wixarika. Then, we compare the morphologically inspired segmentation methods against Byte-Pair Encodings (BPEs) as inputs for machine translation (MT) when translating to and from Spanish. We show that for all language pairs except for Nahuatl, an unsupervised morphological segmentation algorithm outperforms BPEs consistently and that, although supervised methods achieve better segmentation scores, they under-perform in MT challenges. Finally, we contribute two new morphological segmentation datasets for Raramuri and Shipibo-Konibo, and a parallel corpus for Raramuri--Spanish.
Language-Agnostic Meta-Learning for Low-Resource Text-to-Speech with Articulatory Features
Mar 07, 2022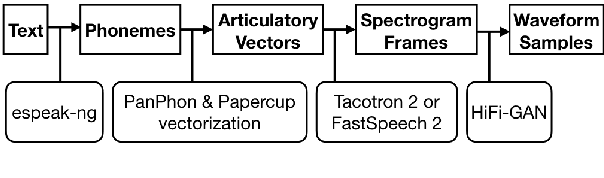
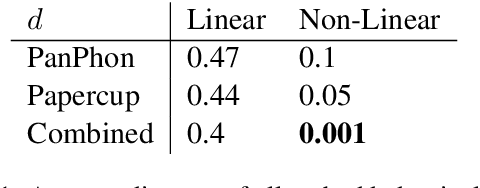
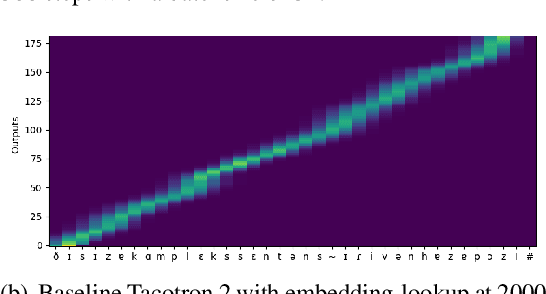

While neural text-to-speech systems perform remarkably well in high-resource scenarios, they cannot be applied to the majority of the over 6,000 spoken languages in the world due to a lack of appropriate training data. In this work, we use embeddings derived from articulatory vectors rather than embeddings derived from phoneme identities to learn phoneme representations that hold across languages. In conjunction with language agnostic meta learning, this enables us to fine-tune a high-quality text-to-speech model on just 30 minutes of data in a previously unseen language spoken by a previously unseen speaker.
Human Interpretation of Saliency-based Explanation Over Text
Jan 27, 2022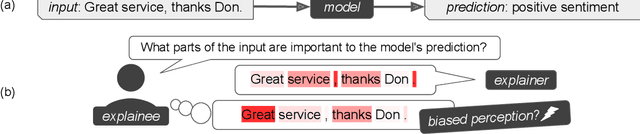

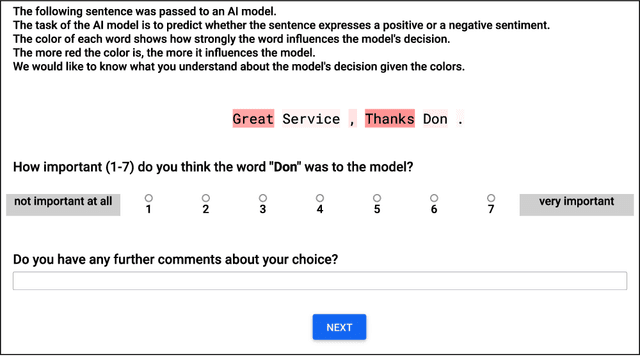
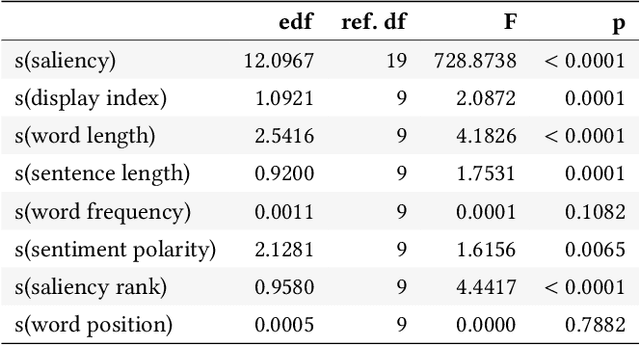
While a lot of research in explainable AI focuses on producing effective explanations, less work is devoted to the question of how people understand and interpret the explanation. In this work, we focus on this question through a study of saliency-based explanations over textual data. Feature-attribution explanations of text models aim to communicate which parts of the input text were more influential than others towards the model decision. Many current explanation methods, such as gradient-based or Shapley value-based methods, provide measures of importance which are well-understood mathematically. But how does a person receiving the explanation (the explainee) comprehend it? And does their understanding match what the explanation attempted to communicate? We empirically investigate the effect of various factors of the input, the feature-attribution explanation, and visualization procedure, on laypeople's interpretation of the explanation. We query crowdworkers for their interpretation on tasks in English and German, and fit a GAMM model to their responses considering the factors of interest. We find that people often mis-interpret the explanations: superficial and unrelated factors, such as word length, influence the explainees' importance assignment despite the explanation communicating importance directly. We then show that some of this distortion can be attenuated: we propose a method to adjust saliencies based on model estimates of over- and under-perception, and explore bar charts as an alternative to heatmap saliency visualization. We find that both approaches can attenuate the distorting effect of specific factors, leading to better-calibrated understanding of the explanation.
Integrating Knowledge in End-to-End Automatic Speech Recognition for Mandarin-English Code-Switching
Dec 19, 2021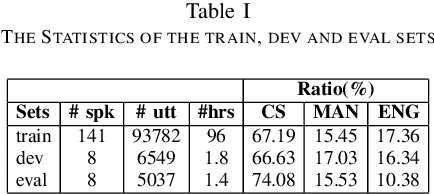
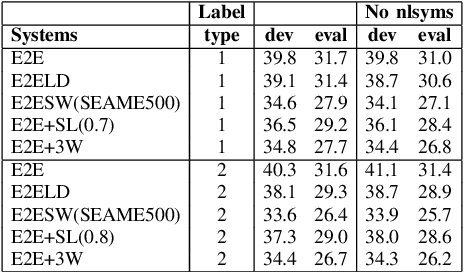

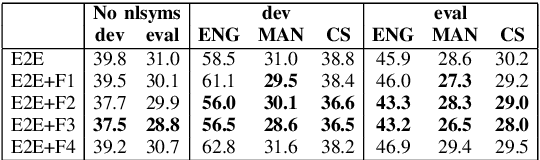
Code-Switching (CS) is a common linguistic phenomenon in multilingual communities that consists of switching between languages while speaking. This paper presents our investigations on end-to-end speech recognition for Mandarin-English CS speech. We analyse different CS specific issues such as the properties mismatches between languages in a CS language pair, the unpredictable nature of switching points, and the data scarcity problem. We exploit and improve the state-of-the-art end-to-end system by merging nonlinguistic symbols, by integrating language identification using hierarchical softmax, by modeling sub-word units, by artificially lowering the speaking rate, and by augmenting data using speed perturbed technique and several monolingual datasets to improve the final performance not only on CS speech but also on monolingual benchmarks in order to make the system more applicable on real life settings. Finally, we explore the effect of different language model integration methods on the performance of the proposed model. Our experimental results reveal that all the proposed techniques improve the recognition performance. The best combined system improves the baseline system by up to 35% relatively in terms of mixed error rate and delivers acceptable performance on monolingual benchmarks.
Investigation of Densely Connected Convolutional Networks with Domain Adversarial Learning for Noise Robust Speech Recognition
Dec 19, 2021
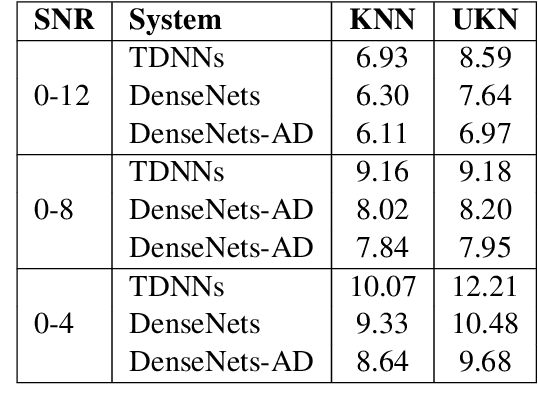

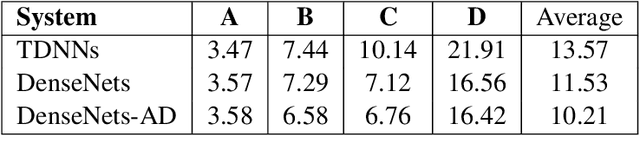
We investigate densely connected convolutional networks (DenseNets) and their extension with domain adversarial training for noise robust speech recognition. DenseNets are very deep, compact convolutional neural networks which have demonstrated incredible improvements over the state-of-the-art results in computer vision. Our experimental results reveal that DenseNets are more robust against noise than other neural network based models such as deep feed forward neural networks and convolutional neural networks. Moreover, domain adversarial learning can further improve the robustness of DenseNets against both, known and unknown noise conditions.
Predicting User Code-Switching Level from Sociological and Psychological Profiles
Dec 13, 2021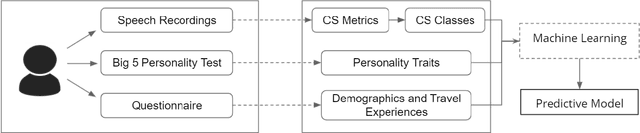
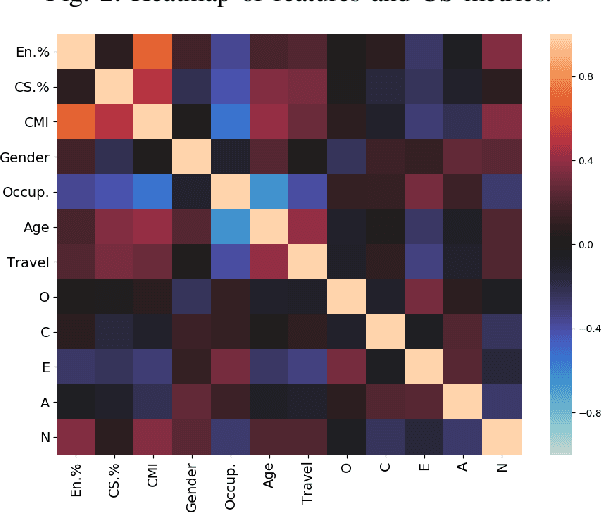
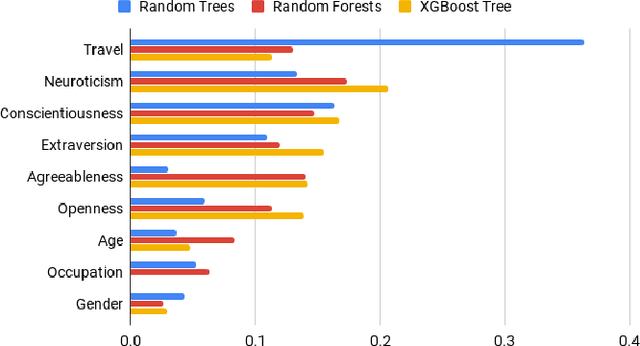
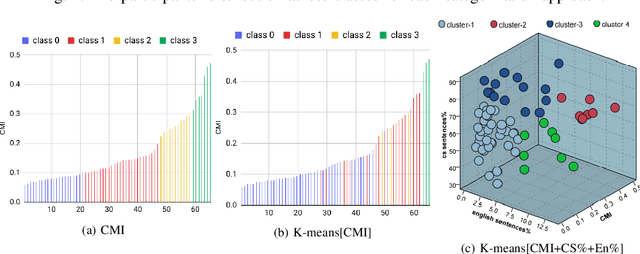
Multilingual speakers tend to alternate between languages within a conversation, a phenomenon referred to as "code-switching" (CS). CS is a complex phenomenon that not only encompasses linguistic challenges, but also contains a great deal of complexity in terms of its dynamic behaviour across speakers. This dynamic behaviour has been studied by sociologists and psychologists, identifying factors affecting CS. In this paper, we provide an empirical user study on Arabic-English CS, where we show the correlation between users' CS frequency and character traits. We use machine learning (ML) to validate the findings, informing and confirming existing theories. The predictive models were able to predict users' CS frequency with an accuracy higher than 55%, where travel experiences and personality traits played the biggest role in the modeling process.
Improving Code-switching Language Modeling with Artificially Generated Texts using Cycle-consistent Adversarial Networks
Dec 12, 2021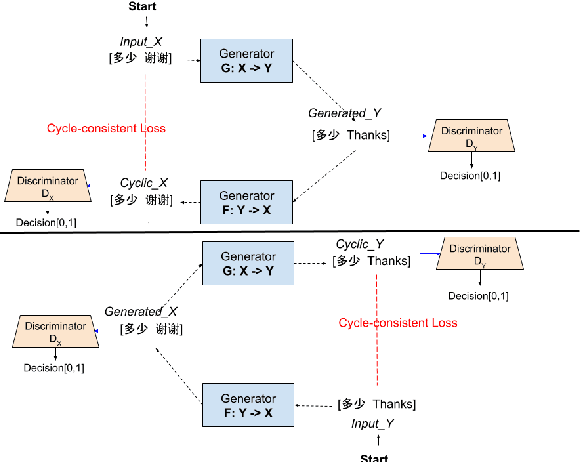
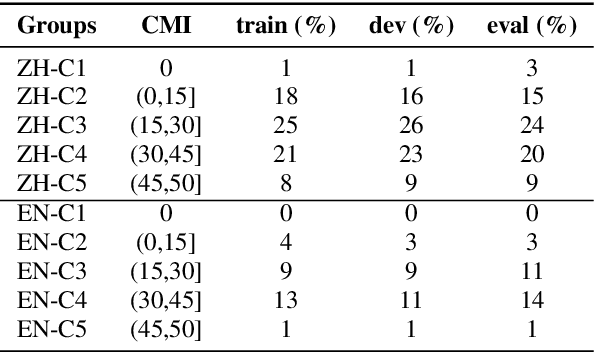
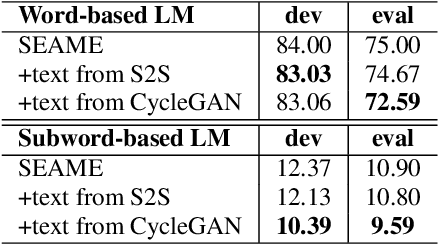

This paper presents our latest effort on improving Code-switching language models that suffer from data scarcity. We investigate methods to augment Code-switching training text data by artificially generating them. Concretely, we propose a cycle-consistent adversarial networks based framework to transfer monolingual text into Code-switching text, considering Code-switching as a speaking style. Our experimental results on the SEAME corpus show that utilising artificially generated Code-switching text data improves consistently the language model as well as the automatic speech recognition performance.
Improving Speech Recognition on Noisy Speech via Speech Enhancement with Multi-Discriminators CycleGAN
Dec 12, 2021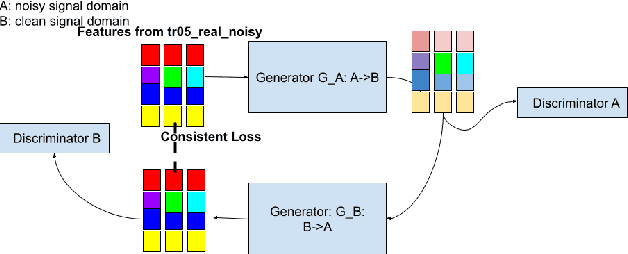
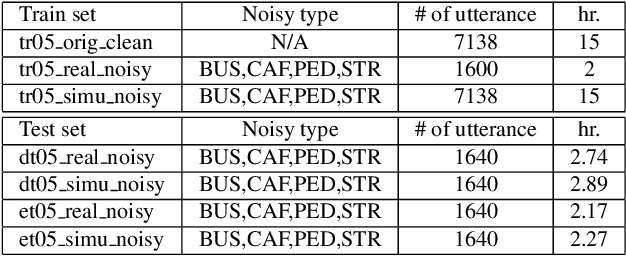
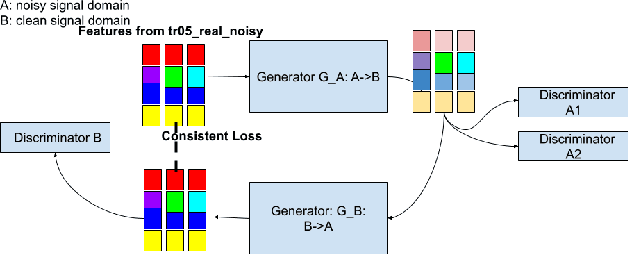
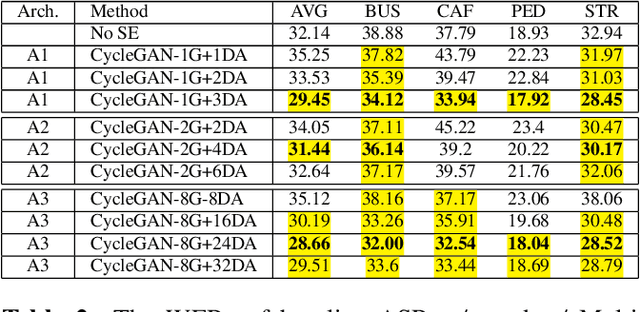
This paper presents our latest investigations on improving automatic speech recognition for noisy speech via speech enhancement. We propose a novel method named Multi-discriminators CycleGAN to reduce noise of input speech and therefore improve the automatic speech recognition performance. Our proposed method leverages the CycleGAN framework for speech enhancement without any parallel data and improve it by introducing multiple discriminators that check different frequency areas. Furthermore, we show that training multiple generators on homogeneous subset of the training data is better than training one generator on all the training data. We evaluate our method on CHiME-3 data set and observe up to 10.03% relatively WER improvement on the development set and up to 14.09% on the evaluation set.