 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Anatomical Landmark Detection via Shape-regulated Self-training
May 28, 2021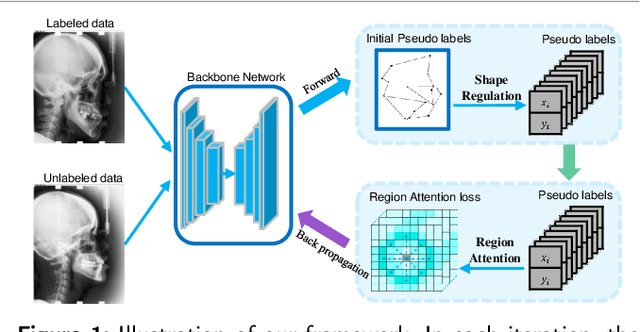
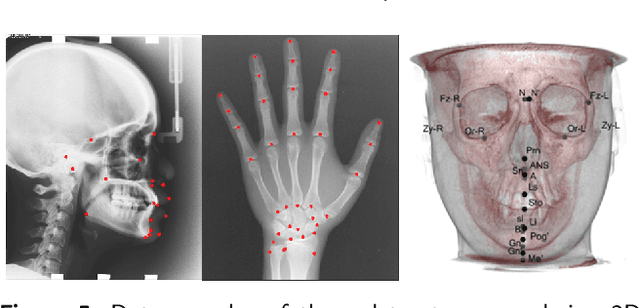
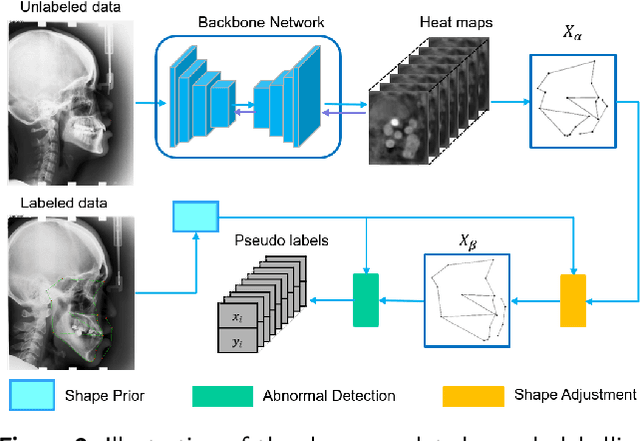

Well-annotated medical images are costly and sometimes even impossible to acquire, hindering landmark detection accuracy to some extent. Semi-supervised learning alleviates the reliance on large-scale annotated data by exploiting the unlabeled data to understand the population structure of anatomical landmarks. The global shape constraint is the inherent property of anatomical landmarks that provides valuable guidance for more consistent pseudo labelling of the unlabeled data, which is ignored in the previously semi-supervised methods. In this paper, we propose a model-agnostic shape-regulated self-training framework for semi-supervised landmark detection by fully considering the global shape constraint. Specifically, to ensure pseudo labels are reliable and consistent, a PCA-based shape model adjusts pseudo labels and eliminate abnormal ones. A novel Region Attention loss to make the network automatically focus on the structure consistent regions around pseudo labels. Extensive experiments show that our approach outperforms other semi-supervised methods and achieves notable improvement on three medical image datasets. Moreover, our framework is flexible and can be used as a plug-and-play module integrated into most supervised methods to improve performance further.
Point2Skeleton: Learning Skeletal Representations from Point Clouds
Dec 01, 2020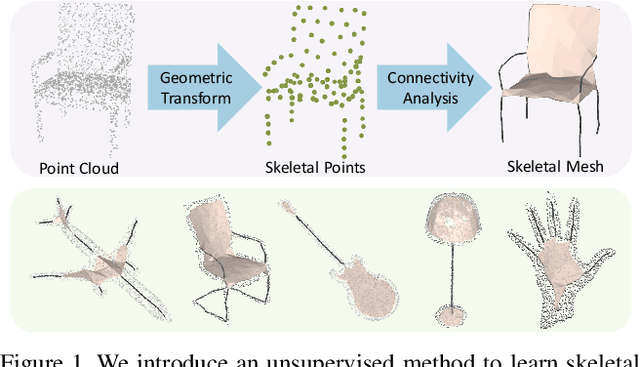
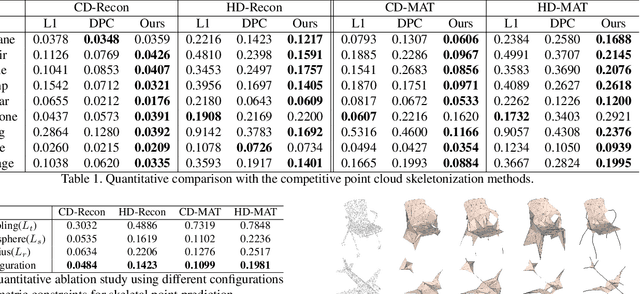
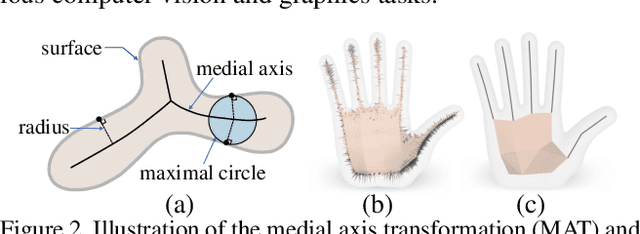
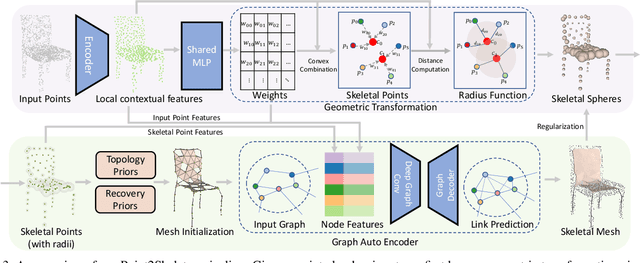
We introduce Point2Skeleton, an unsupervised method to learn skeletal representations from point clouds. Existing skeletonization methods are limited to tubular shapes and the stringent requirement of watertight input, while our method aims to produce more generalized skeletal representations for complex structures and handle point clouds. Our key idea is to use the insights of the medial axis transform (MAT) to capture the intrinsic geometric and topological natures of the original input points. We first predict a set of skeletal points by learning a geometric transformation, and then analyze the connectivity of the skeletal points to form skeletal mesh structures. Extensive evaluations and comparisons show our method has superior performance and robustness. The learned skeletal representation will benefit several unsupervised tasks for point clouds, such as surface reconstruction and segmentation.
Mapping in a cycle: Sinkhorn regularized unsupervised learning for point cloud shapes
Jul 19, 2020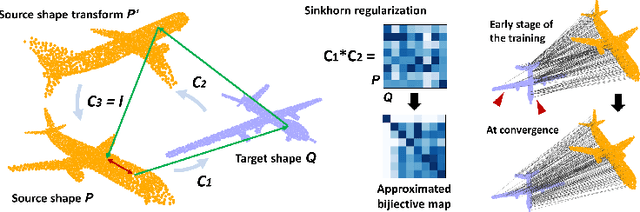
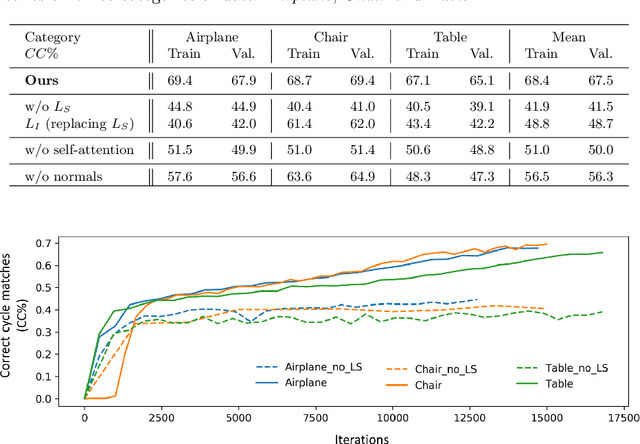
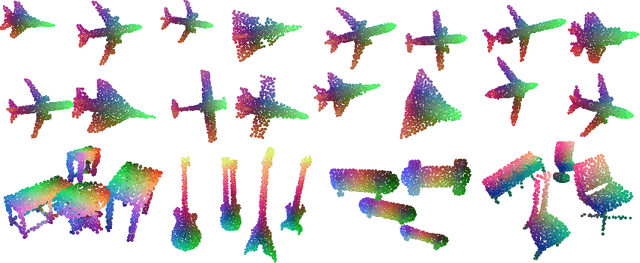
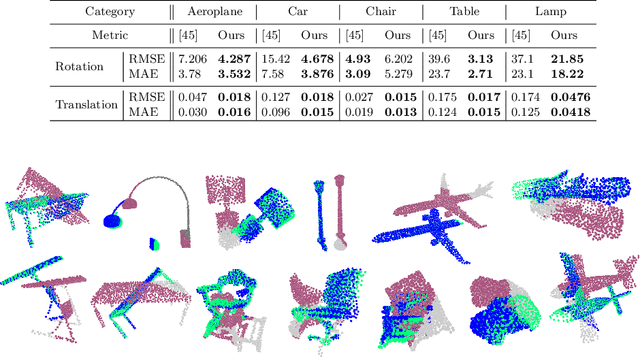
We propose an unsupervised learning framework with the pretext task of finding dense correspondences between point cloud shapes from the same category based on the cycle-consistency formulation. In order to learn discriminative pointwise features from point cloud data, we incorporate in the formulation a regularization term based on Sinkhorn normalization to enhance the learned pointwise mappings to be as bijective as possible. Besides, a random rigid transform of the source shape is introduced to form a triplet cycle to improve the model's robustness against perturbations. Comprehensive experiments demonstrate that the learned pointwise features through our framework benefits various point cloud analysis tasks, e.g. partial shape registration and keypoint transfer. We also show that the learned pointwise features can be leveraged by supervised methods to improve the part segmentation performance with either the full training dataset or just a small portion of it.
Vid2Curve: Simultaneous Camera Motion Estimation and Thin Structure Reconstruction from an RGB Video
May 20, 2020
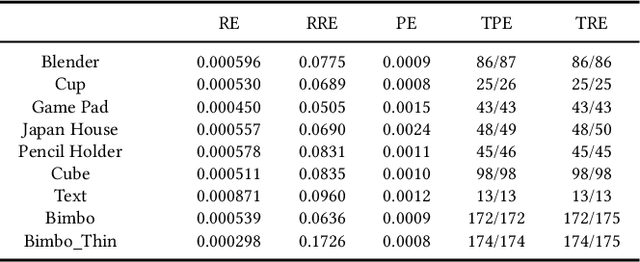
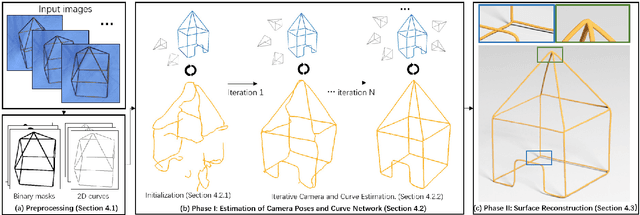
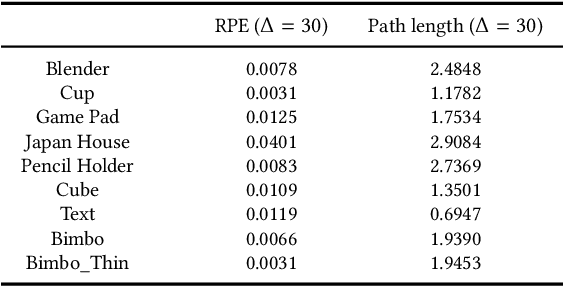
Thin structures, such as wire-frame sculptures, fences, cables, power lines, and tree branches, are common in the real world. It is extremely challenging to acquire their 3D digital models using traditional image-based or depth-based reconstruction methods because thin structures often lack distinct point features and have severe self-occlusion. We propose the first approach that simultaneously estimates camera motion and reconstructs the geometry of complex 3D thin structures in high quality from a color video captured by a handheld camera. Specifically, we present a new curve-based approach to estimate accurate camera poses by establishing correspondences between featureless thin objects in the foreground in consecutive video frames, without requiring visual texture in the background scene to lock on. Enabled by this effective curve-based camera pose estimation strategy, we develop an iterative optimization method with tailored measures on geometry, topology as well as self-occlusion handling for reconstructing 3D thin structures. Extensive validations on a variety of thin structures show that our method achieves accurate camera pose estimation and faithful reconstruction of 3D thin structures with complex shape and topology at a level that has not been attained by other existing reconstruction methods.
Unsupervised Learning of Intrinsic Structural Representation Points
Mar 26, 2020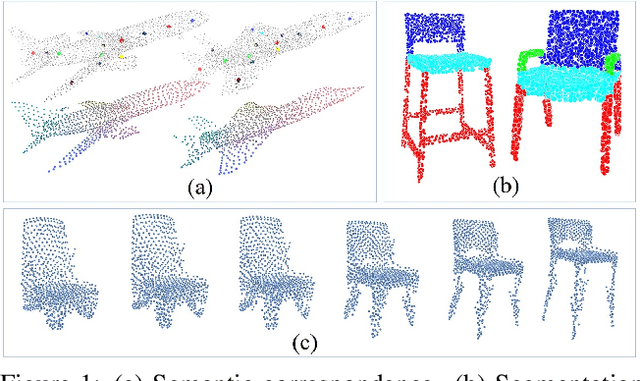

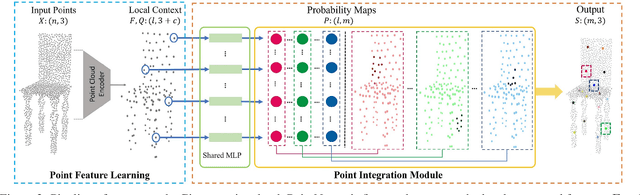
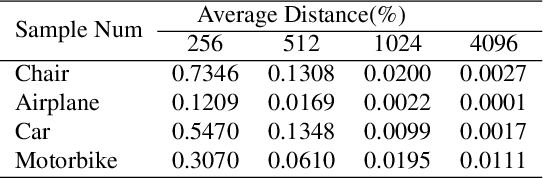
Learning structures of 3D shapes is a fundamental problem in the field of computer graphics and geometry processing. We present a simple yet interpretable unsupervised method for learning a new structural representation in the form of 3D structure points. The 3D structure points produced by our method encode the shape structure intrinsically and exhibit semantic consistency across all the shape instances with similar structures. This is a challenging goal that has not fully been achieved by other methods. Specifically, our method takes a 3D point cloud as input and encodes it as a set of local features. The local features are then passed through a novel point integration module to produce a set of 3D structure points. The chamfer distance is used as reconstruction loss to ensure the structure points lie close to the input point cloud. Extensive experiments have shown that our method outperforms the state-of-the-art on the semantic shape correspondence task and achieves comparable performance with the state-of-the-art on the segmentation label transfer task. Moreover, the PCA based shape embedding built upon consistent structure points demonstrates good performance in preserving the shape structures. Code is available at https://github.com/NolenChen/3DStructurePoints
Cephalometric Landmark Detection by AttentiveFeature Pyramid Fusion and Regression-Voting
Aug 23, 2019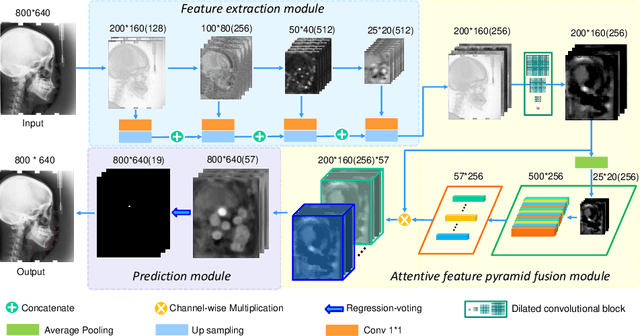
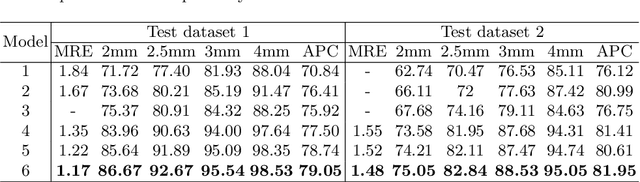
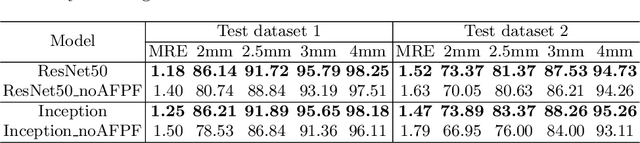
Marking anatomical landmarks in cephalometric radiography is a critical operation in cephalometric analysis. Automatically and accurately locating these landmarks is a challenging issue because different landmarks require different levels of resolution and semantics. Based on this observation, we propose a novel attentive feature pyramid fusion module (AFPF) to explicitly shape high-resolution and semantically enhanced fusion features to achieve significantly higher accuracy than existing deep learning-based methods. We also combine heat maps and offset maps to perform pixel-wise regression-voting to improve detection accuracy. By incorporating the AFPF and regression-voting, we develop an end-to-end deep learning framework that improves detection accuracy by 7%~11% for all the evaluation metrics over the state-of-the-art method. We present ablation studies to give more insights into different components of our method and demonstrate its generalization capability and stability for unseen data from diverse devices.