 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexical Semantic Recognition
Apr 30, 2020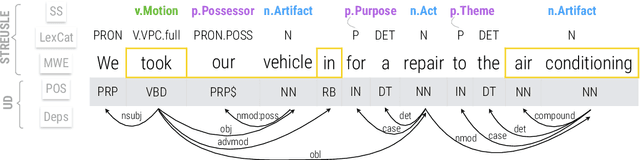
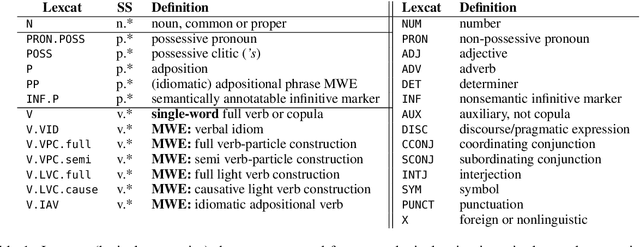
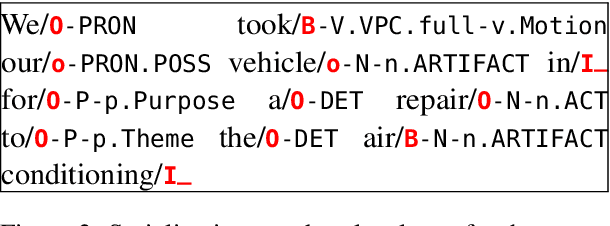
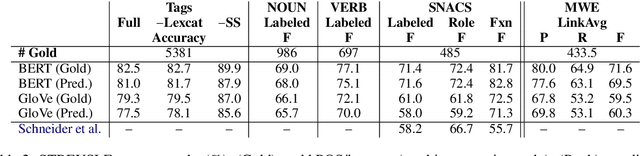
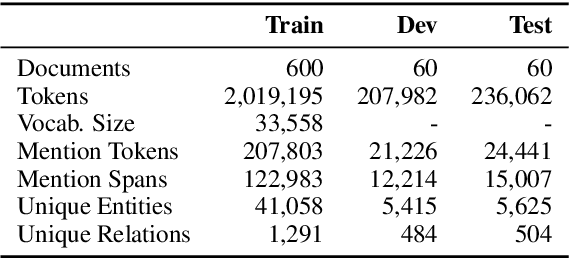
Segmentation and (segment) labeling are generally treated separately in lexical semantics, raising issues due to their close inter-dependence and necessitating joint annotation. We therefore investigate the lexical semantic recognition task of multiword expression segmentation and supersense disambiguation, unifying several previously-disparate styles of lexical semantic annotation. We evaluate a neural CRF model along all annotation axes available in version 4.3 of the STREUSLE corpus: lexical unit segmentation (multiword expressions), word-level syntactic tags, and supersense classes for noun, verb, and preposition/possessive units. As the label set generalizes that of previous tasks (DiMSUM, PARSEME), we additionally evaluate how well the model generalizes to those test sets, with encouraging results. By establishing baseline models and evaluation metrics, we pave the way for comprehensive and accurate modeling of lexical semantics.
Evaluating NLP Models via Contrast Sets
Apr 06, 2020
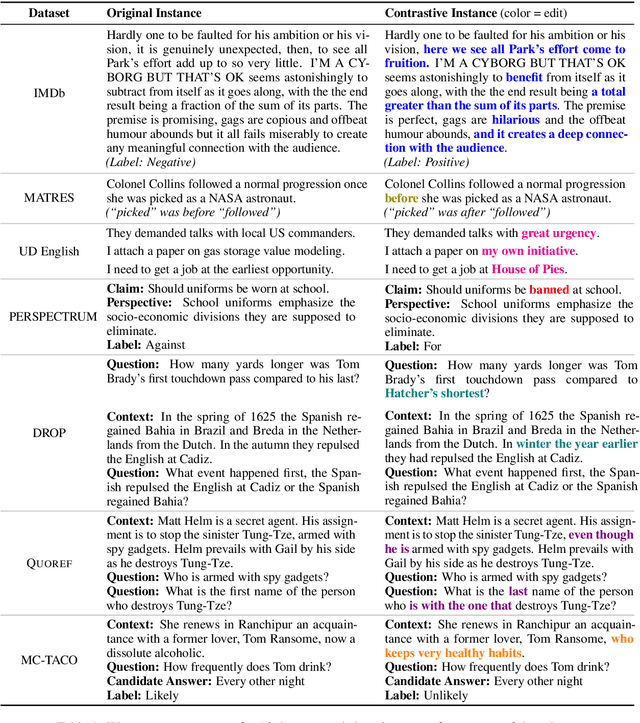
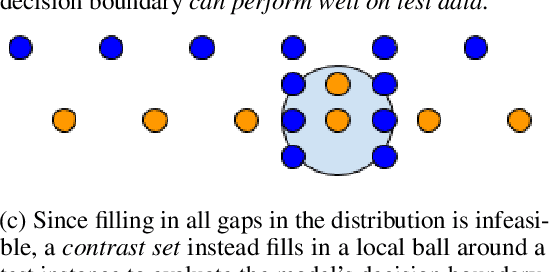
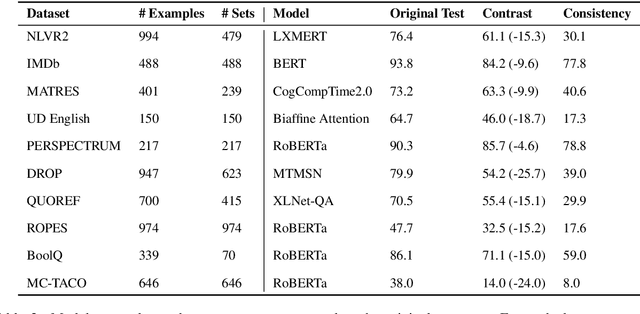
Standard test sets for supervised learning evaluate in-distribution generalization. Unfortunately, when a dataset has systematic gaps (e.g., annotation artifacts), these evaluations are misleading: a model can learn simple decision rules that perform well on the test set but do not capture a dataset's intended capabilities. We propose a new annotation paradigm for NLP that helps to close systematic gaps in the test data. In particular, after a dataset is constructed, we recommend that the dataset authors manually perturb the test instances in small but meaningful ways that (typically) change the gold label, creating contrast sets. Contrast sets provide a local view of a model's decision boundary, which can be used to more accurately evaluate a model's true linguistic capabilities. We demonstrate the efficacy of contrast sets by creating them for 10 diverse NLP datasets (e.g., DROP reading comprehension, UD parsing, IMDb sentiment analysis). Although our contrast sets are not explicitly adversarial, model performance is significantly lower on them than on the original test sets---up to 25\% in some cases. We release our contrast sets as new evaluation benchmarks and encourage future dataset construction efforts to follow similar annotation processes.
Quoref: A Reading Comprehension Dataset with Questions Requiring Coreferential Reasoning
Sep 05, 2019
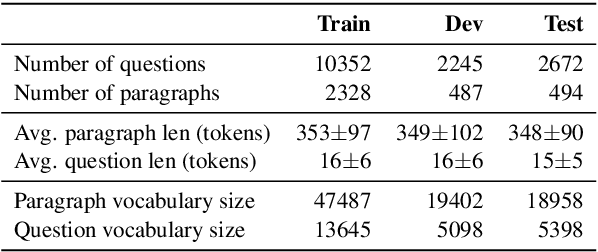

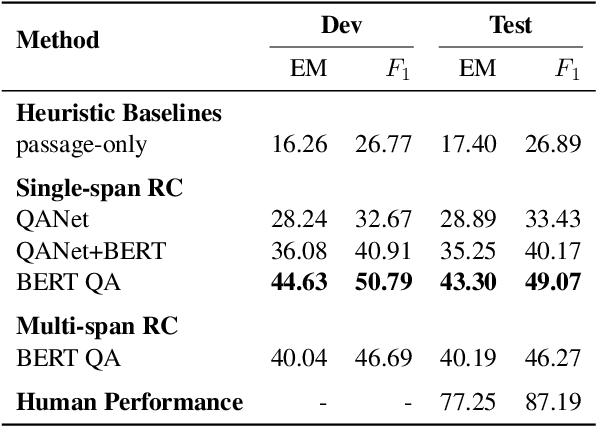
Machine comprehension of texts longer than a single sentence often requires coreference resolution. However, most current reading comprehension benchmarks do not contain complex coreferential phenomena and hence fail to evaluate the ability of models to resolve coreference. We present a new crowdsourced dataset containing more than 24K span-selection questions that require resolving coreference among entities in over 4.7K English paragraphs from Wikipedia. Obtaining questions focused on such phenomena is challenging, because it is hard to avoid lexical cues that shortcut complex reasoning. We deal with this issue by using a strong baseline model as an adversary in the crowdsourcing loop, which helps crowdworkers avoid writing questions with exploitable surface cues. We show that state-of-the-art reading comprehension models perform significantly worse than humans on this benchmark---the best model performance is 70.5 F1, while the estimated human performance is 93.4 F1.
Barack's Wife Hillary: Using Knowledge-Graphs for Fact-Aware Language Modeling
Jun 20, 2019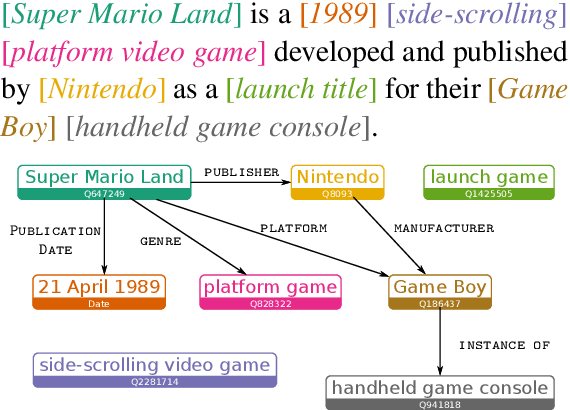
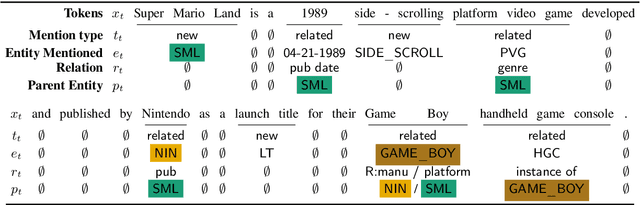
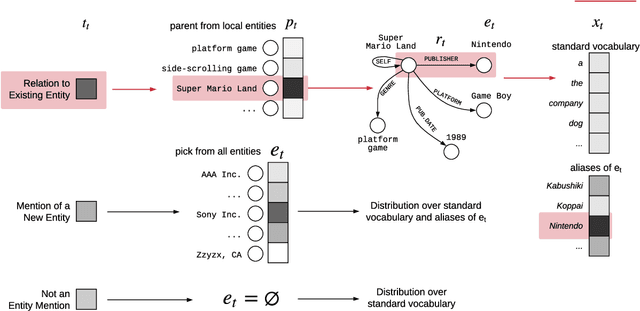
Modeling human language requires the ability to not only generate fluent text but also encode factual knowledge. However, traditional language models are only capable of remembering facts seen at training time, and often have difficulty recalling them. To address this, we introduce the knowledge graph language model (KGLM), a neural language model with mechanisms for selecting and copying facts from a knowledge graph that are relevant to the context. These mechanisms enable the model to render information it has never seen before, as well as generate out-of-vocabulary tokens. We also introduce the Linked WikiText-2 dataset, a corpus of annotated text aligned to the Wikidata knowledge graph whose contents (roughly) match the popular WikiText-2 benchmark. In experiments, we demonstrate that the KGLM achieves significantly better performance than a strong baseline language model. We additionally compare different language model's ability to complete sentences requiring factual knowledge, showing that the KGLM outperforms even very large language models in generating facts.
Inoculation by Fine-Tuning: A Method for Analyzing Challenge Datasets
Apr 26, 2019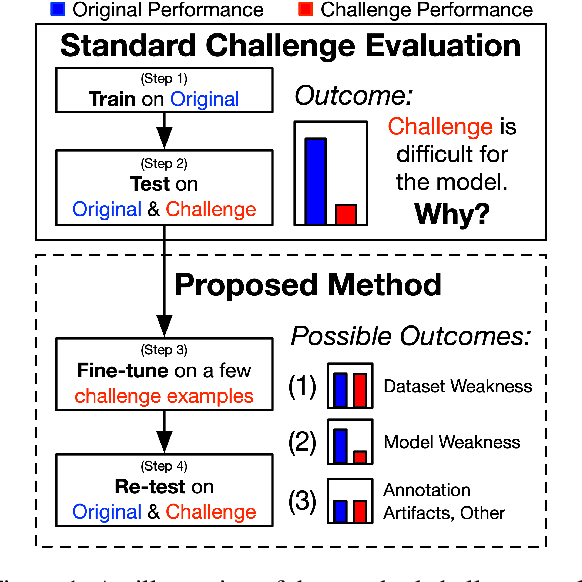

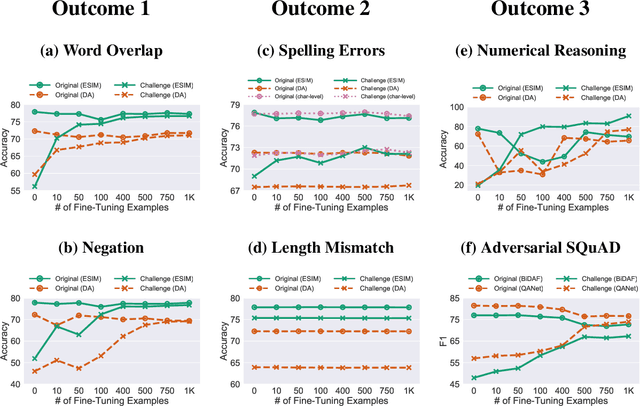
Several datasets have recently been constructed to expose brittleness in models trained on existing benchmarks. While model performance on these challenge datasets is significantly lower compared to the original benchmark, it is unclear what particular weaknesses they reveal. For example, a challenge dataset may be difficult because it targets phenomena that current models cannot capture, or because it simply exploits blind spots in a model's specific training set. We introduce inoculation by fine-tuning, a new analysis method for studying challenge datasets by exposing models (the metaphorical patient) to a small amount of data from the challenge dataset (a metaphorical pathogen) and assessing how well they can adapt. We apply our method to analyze the NLI "stress tests" (Naik et al., 2018) and the Adversarial SQuAD dataset (Jia and Liang, 2017). We show that after slight exposure, some of these datasets are no longer challenging, while others remain difficult. Our results indicate that failures on challenge datasets may lead to very different conclusions about models, training datasets, and the challenge datasets themselves.
Linguistic Knowledge and Transferability of Contextual Representations
Apr 11, 2019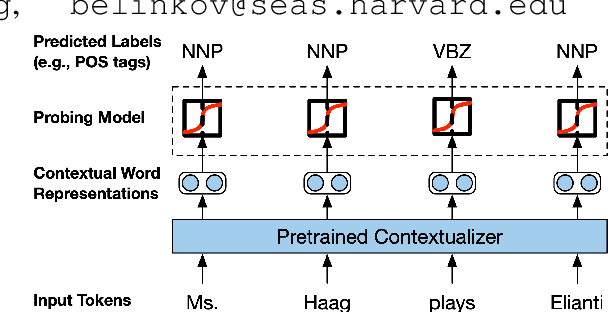
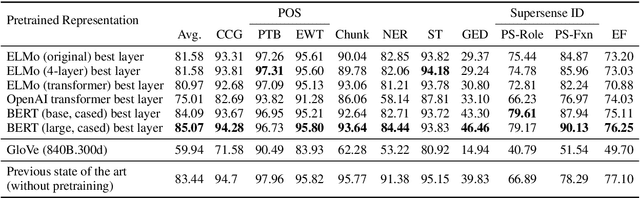
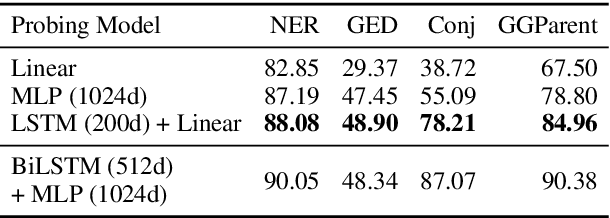
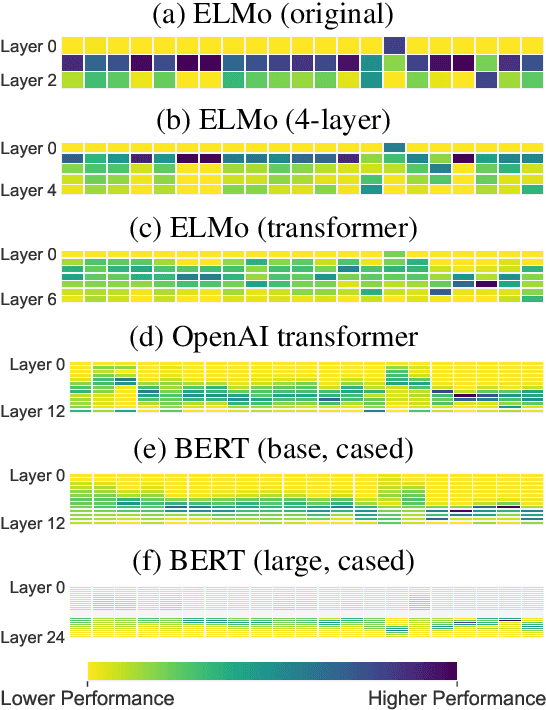
Contextual word representations derived from large-scale neural language models are successful across a diverse set of NLP tasks, suggesting that they encode useful and transferable features of language. To shed light on the linguistic knowledge they capture, we study the representations produced by several recent pretrained contextualizers (variants of ELMo, the OpenAI transformer language model, and BERT) with a suite of sixteen diverse probing tasks. We find that linear models trained on top of frozen contextual representations are competitive with state-of-the-art task-specific models in many cases, but fail on tasks requiring fine-grained linguistic knowledge (e.g., conjunct identification). To investigate the transferability of contextual word representations, we quantify differences in the transferability of individual layers within contextualizers, especially between recurrent neural networks (RNNs) and transformers. For instance, higher layers of RNNs are more task-specific, while transformer layers do not exhibit the same monotonic trend. In addition, to better understand what makes contextual word representations transferable, we compare language model pretraining with eleven supervised pretraining tasks. For any given task, pretraining on a closely related task yields better performance than language model pretraining (which is better on average) when the pretraining dataset is fixed. However, language model pretraining on more data gives the best results.
Augmenting Statistical Machine Translation with Subword Translation of Out-of-Vocabulary Words
Aug 16, 2018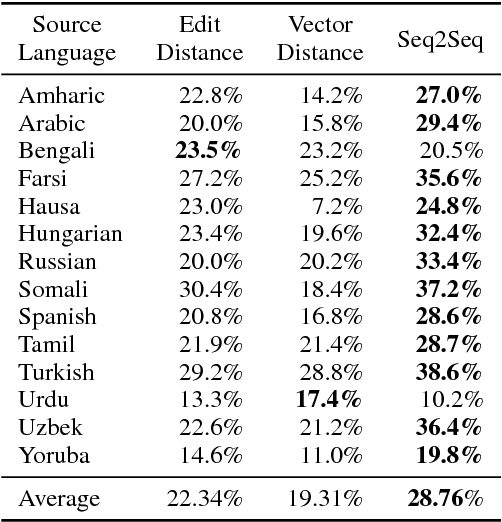

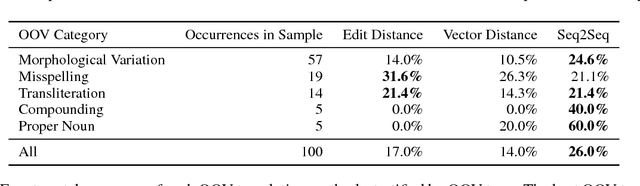
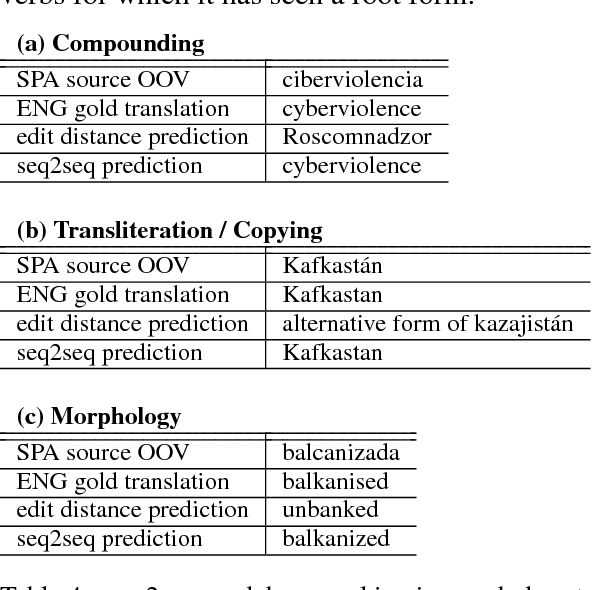
Most statistical machine translation systems cannot translate words that are unseen in the training data. However, humans can translate many classes of out-of-vocabulary (OOV) words (e.g., novel morphological variants, misspellings, and compounds) without context by using orthographic clues. Following this observation, we describe and evaluate several general methods for OOV translation that use only subword information. We pose the OOV translation problem as a standalone task and intrinsically evaluate our approaches on fourteen typologically diverse languages across varying resource levels. Adding OOV translators to a statistical machine translation system yields consistent BLEU gains (0.5 points on average, and up to 2.0) for all fourteen languages, especially in low-resource scenarios.
LSTMs Exploit Linguistic Attributes of Data
May 29, 2018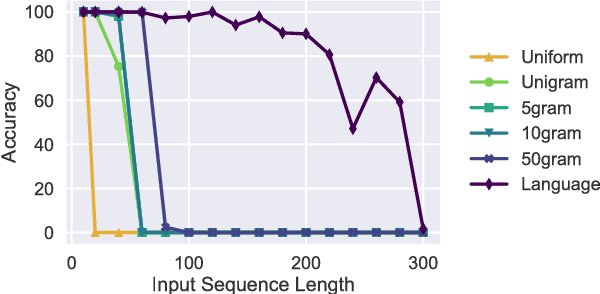
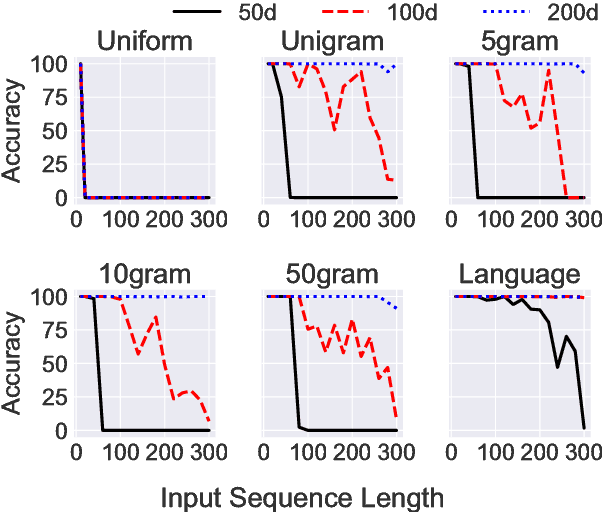
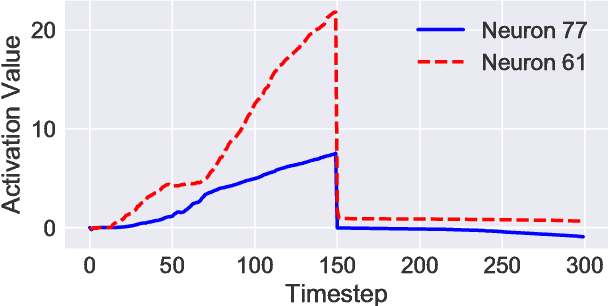
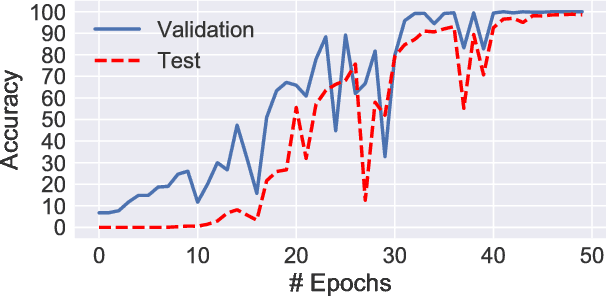
While recurrent neural networks have found success in a variety of natural language processing applications, they are general models of sequential data. We investigate how the properties of natural language data affect an LSTM's ability to learn a nonlinguistic task: recalling elements from its input. We find that models trained on natural language data are able to recall tokens from much longer sequences than models trained on non-language sequential data. Furthermore, we show that the LSTM learns to solve the memorization task by explicitly using a subset of its neurons to count timesteps in the input. We hypothesize that the patterns and structure in natural language data enable LSTMs to learn by providing approximate ways of reducing loss, but understanding the effect of different training data on the learnability of LSTMs remains an open question.
Crowdsourcing Multiple Choice Science Questions
Jul 19, 2017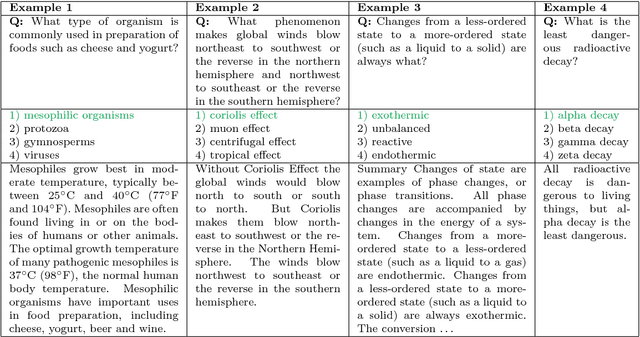
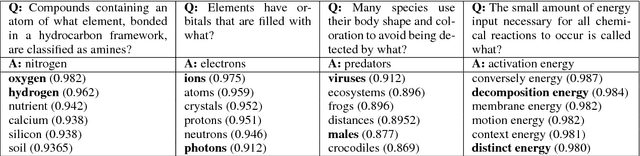
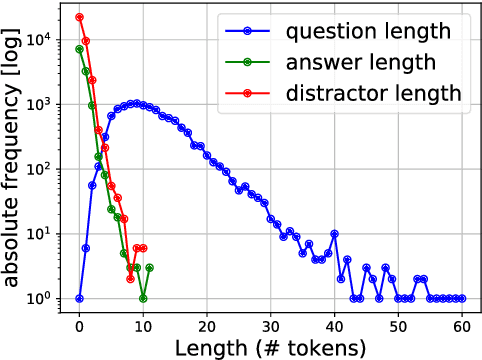
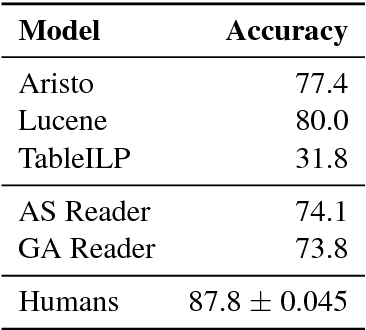
We present a novel method for obtaining high-quality, domain-targeted multiple choice questions from crowd workers. Generating these questions can be difficult without trading away originality, relevance or diversity in the answer options. Our method addresses these problems by leveraging a large corpus of domain-specific text and a small set of existing questions. It produces model suggestions for document selection and answer distractor choice which aid the human question generation process. With this method we have assembled SciQ, a dataset of 13.7K multiple choice science exam questions (Dataset available at http://allenai.org/data.html). We demonstrate that the method produces in-domain questions by providing an analysis of this new dataset and by showing that humans cannot distinguish the crowdsourced questions from original questions. When using SciQ as additional training data to existing questions, we observe accuracy improvements on real science exams.