 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Oct 22, 2020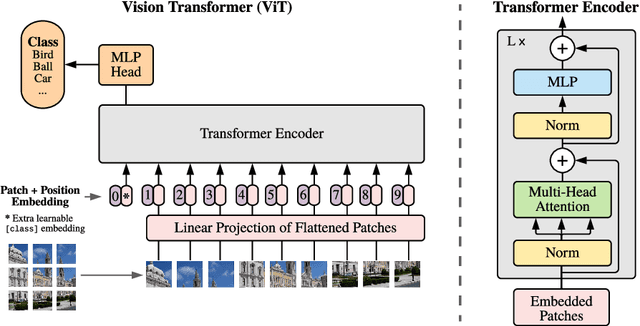

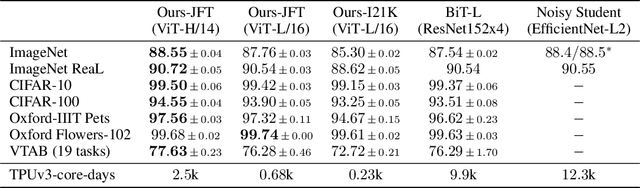
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
Deep Ensembles for Low-Data Transfer Learning
Oct 19, 2020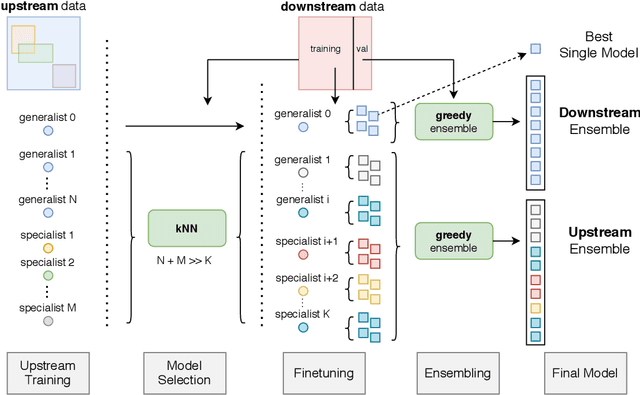
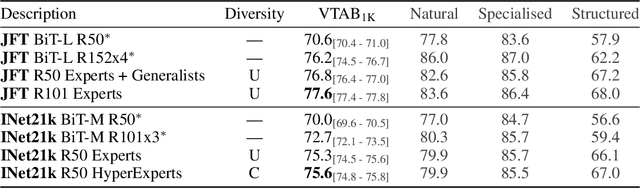
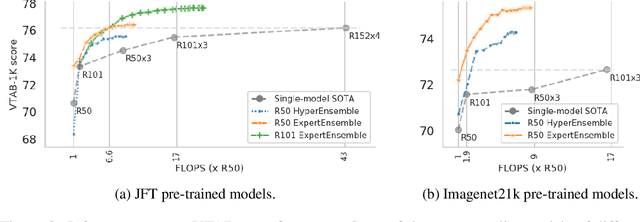
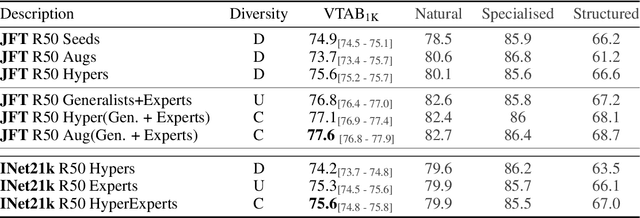
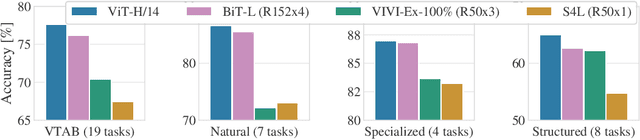
In the low-data regime, it is difficult to train good supervised models from scratch. Instead practitioners turn to pre-trained models, leveraging transfer learning. Ensembling is an empirically and theoretically appealing way to construct powerful predictive models, but the predominant approach of training multiple deep networks with different random initialisations collides with the need for transfer via pre-trained weights. In this work, we study different ways of creating ensembles from pre-trained models. We show that the nature of pre-training itself is a performant source of diversity, and propose a practical algorithm that efficiently identifies a subset of pre-trained models for any downstream dataset. The approach is simple: Use nearest-neighbour accuracy to rank pre-trained models, fine-tune the best ones with a small hyperparameter sweep, and greedily construct an ensemble to minimise validation cross-entropy. When evaluated together with strong baselines on 19 different downstream tasks (the Visual Task Adaptation Benchmark), this achieves state-of-the-art performance at a much lower inference budget, even when selecting from over 2,000 pre-trained models. We also assess our ensembles on ImageNet variants and show improved robustness to distribution shift.
Representation learning from videos in-the-wild: An object-centric approach
Oct 06, 2020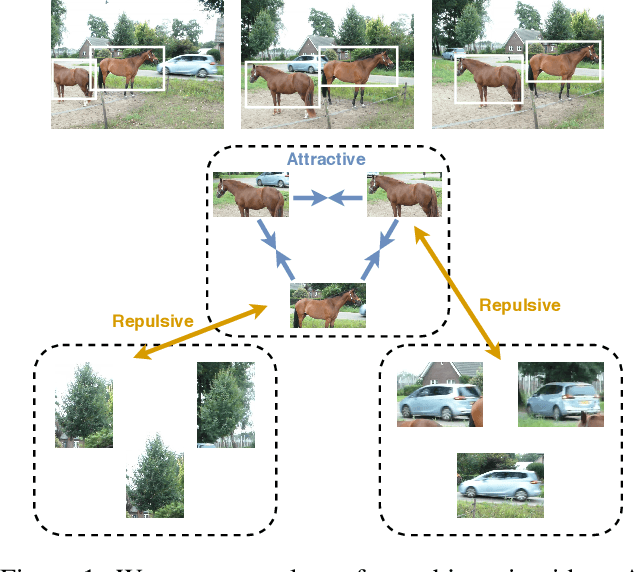
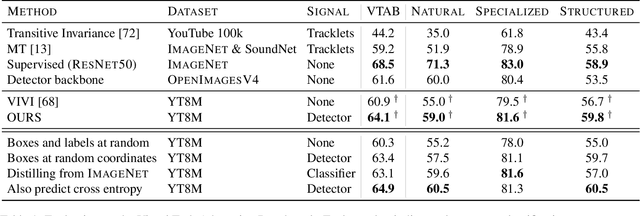

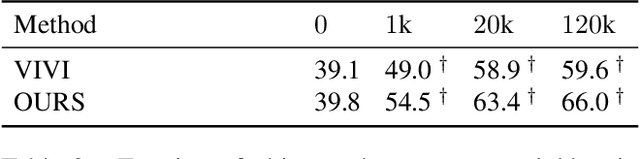
We propose a method to learn image representations from uncurated videos. We combine a supervised loss from off-the-shelf object detectors and self-supervised losses which naturally arise from the video-shot-frame-object hierarchy present in each video. We report competitive results on 19 transfer learning tasks of the Visual Task Adaptation Benchmark (VTAB), and on 8 out-of-distribution-generalization tasks, and discuss the benefits and shortcomings of the proposed approach. In particular, it improves over the baseline on all 18/19 few-shot learning tasks and 8/8 out-of-distribution generalization tasks. Finally, we perform several ablation studies and analyze the impact of the pretrained object detector on the performance across this suite of tasks.
Training general representations for remote sensing using in-domain knowledge
Sep 30, 2020
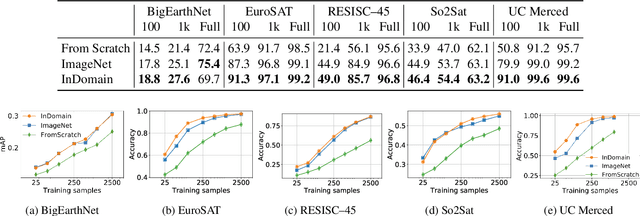
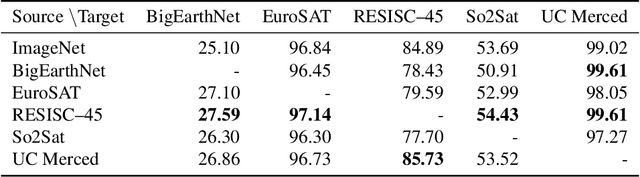
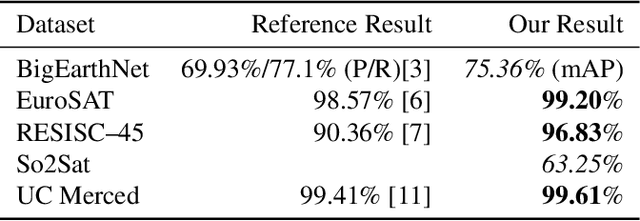
Automatically finding good and general remote sensing representations allows to perform transfer learning on a wide range of applications - improving the accuracy and reducing the required number of training samples. This paper investigates development of generic remote sensing representations, and explores which characteristics are important for a dataset to be a good source for representation learning. For this analysis, five diverse remote sensing datasets are selected and used for both, disjoint upstream representation learning and downstream model training and evaluation. A common evaluation protocol is used to establish baselines for these datasets that achieve state-of-the-art performance. As the results indicate, especially with a low number of available training samples a significant performance enhancement can be observed when including additionally in-domain data in comparison to training models from scratch or fine-tuning only on ImageNet (up to 11% and 40%, respectively, at 100 training samples). All datasets and pretrained representation models are published online.
Scalable Transfer Learning with Expert Models
Sep 28, 2020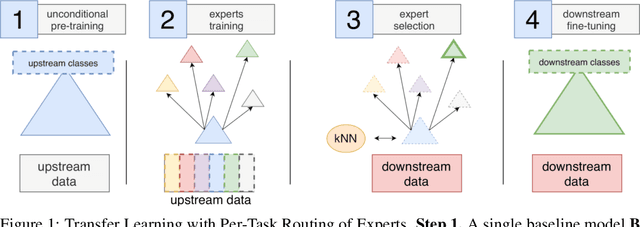
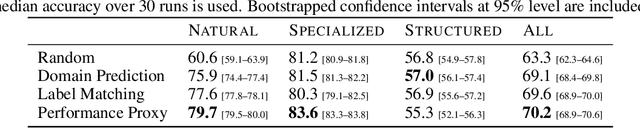
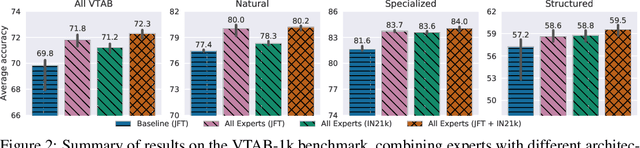
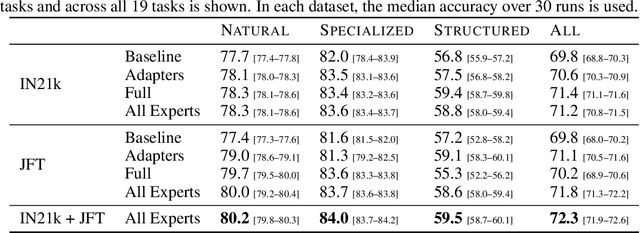
Transfer of pre-trained representations can improve sample efficiency and reduce computational requirements for new tasks. However, representations used for transfer are usually generic, and are not tailored to a particular distribution of downstream tasks. We explore the use of expert representations for transfer with a simple, yet effective, strategy. We train a diverse set of experts by exploiting existing label structures, and use cheap-to-compute performance proxies to select the relevant expert for each target task. This strategy scales the process of transferring to new tasks, since it does not revisit the pre-training data during transfer. Accordingly, it requires little extra compute per target task, and results in a speed-up of 2-3 orders of magnitude compared to competing approaches. Further, we provide an adapter-based architecture able to compress many experts into a single model. We evaluate our approach on two different data sources and demonstrate that it outperforms baselines on over 20 diverse vision tasks in both cases.
On Robustness and Transferability of Convolutional Neural Networks
Jul 16, 2020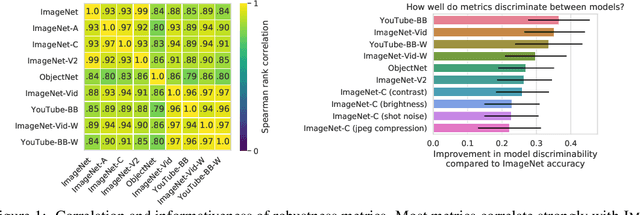

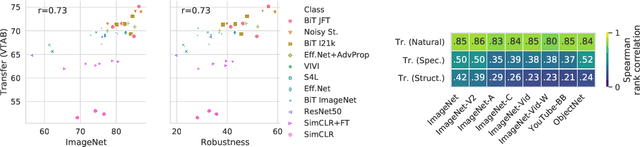
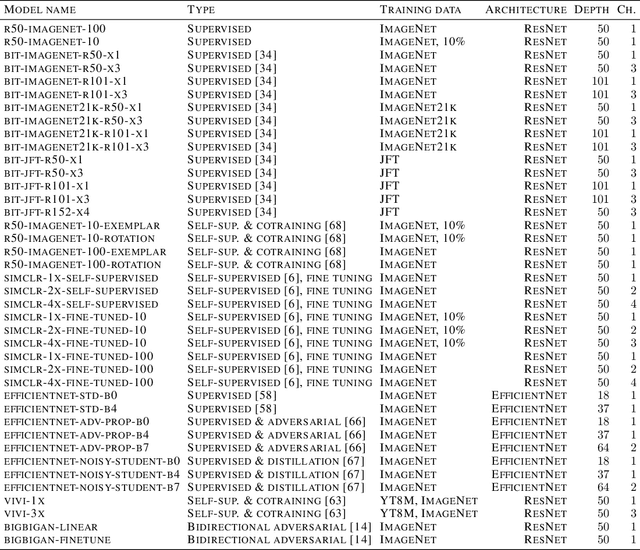
Modern deep convolutional networks (CNNs) are often criticized for not generalizing under distributional shifts. However, several recent breakthroughs in transfer learning suggest that these networks can cope with severe distribution shifts and successfully adapt to new tasks from a few training examples. In this work we revisit the out-of-distribution and transfer performance of modern image classification CNNs and investigate the impact of the pre-training data size, the model scale, and the data preprocessing pipeline. We find that increasing both the training set and model sizes significantly improve the distributional shift robustness. Furthermore, we show that, perhaps surprisingly, simple changes in the preprocessing such as modifying the image resolution can significantly mitigate robustness issues in some cases. Finally, we outline the shortcomings of existing robustness evaluation datasets and introduce a synthetic dataset we use for a systematic analysis across common factors of variation. \end{abstract}
Automatic Shortcut Removal for Self-Supervised Representation Learning
Feb 21, 2020
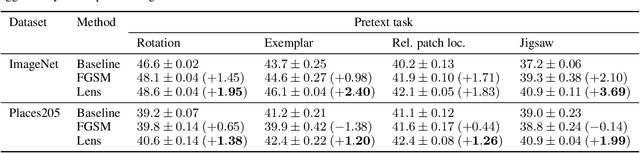
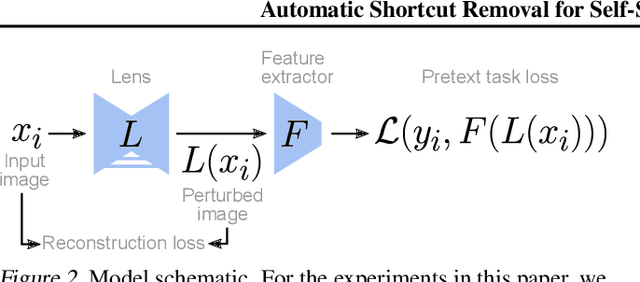
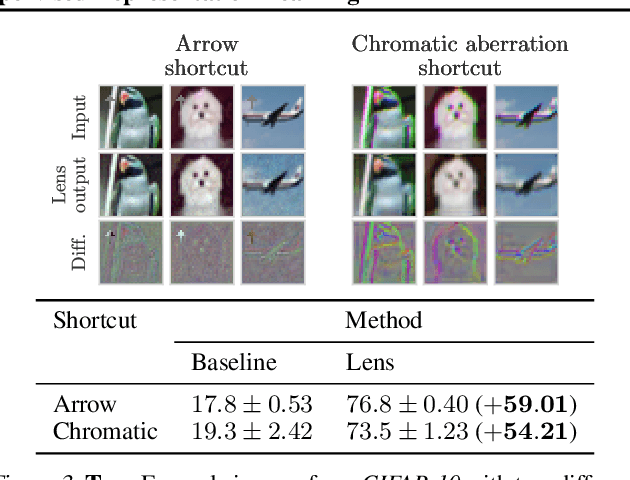
In self-supervised visual representation learning, a feature extractor is trained on a "pretext task" for which labels can be generated cheaply. A central challenge in this approach is that the feature extractor quickly learns to exploit low-level visual features such as color aberrations or watermarks and then fails to learn useful semantic representations. Much work has gone into identifying such "shortcut" features and hand-designing schemes to reduce their effect. Here, we propose a general framework for removing shortcut features automatically. Our key assumption is that those features which are the first to be exploited for solving the pretext task may also be the most vulnerable to an adversary trained to make the task harder. We show that this assumption holds across common pretext tasks and datasets by training a "lens" network to make small image changes that maximally reduce performance in the pretext task. Representations learned with the modified images outperform those learned without in all tested cases. Additionally, the modifications made by the lens reveal how the choice of pretext task and dataset affects the features learned by self-supervision.
Large Scale Learning of General Visual Representations for Transfer
Dec 24, 2019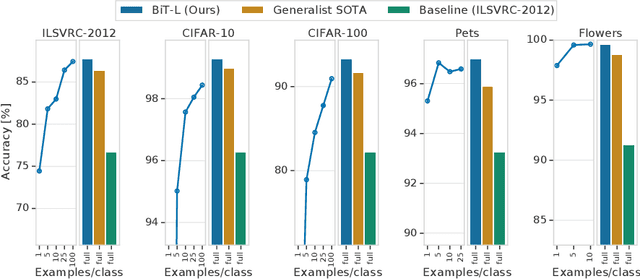

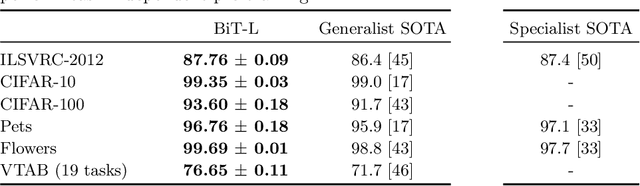
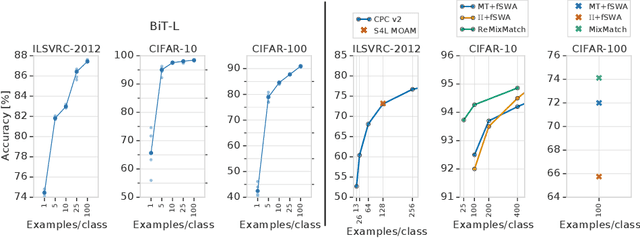
Transfer of pre-trained representations improves sample efficiency and simplifies hyperparameter tuning when training deep neural networks for vision. We revisit the paradigm of pre-training on large supervised datasets and fine-tuning the weights on the target task. We scale up pre-training, and create a simple recipe that we call Big Transfer (BiT). By combining a few carefully selected components, and transferring using a simple heuristic, we achieve strong performance on over 20 datasets. BiT performs well across a surprisingly wide range of data regimes - from 10 to 1M labeled examples. BiT achieves 87.8% top-1 accuracy on ILSVRC-2012, 99.3% on CIFAR-10, and 76.7% on the Visual Task Adaptation Benchmark (which includes 19 tasks). On small datasets, BiT attains 86.4% on ILSVRC-2012 with 25 examples per class, and 97.6% on CIFAR-10 with 10 examples per class. We conduct detailed analysis of the main components that lead to high transfer performance.
Self-Supervised Learning of Video-Induced Visual Invariances
Dec 05, 2019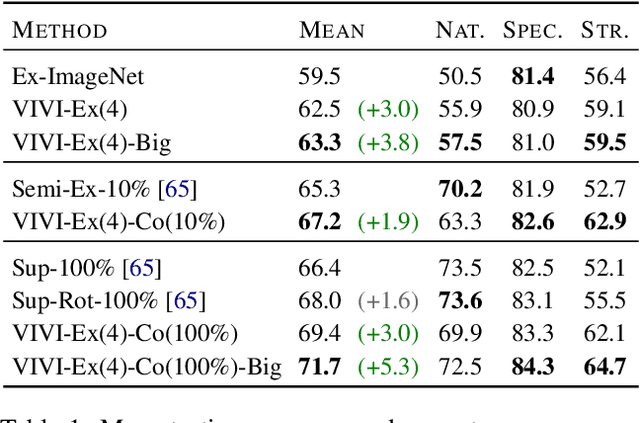
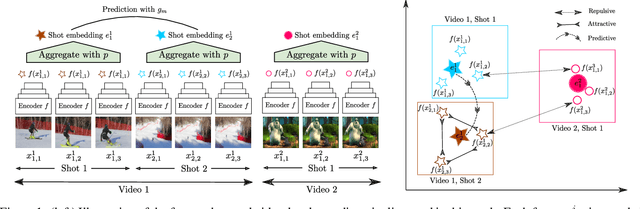
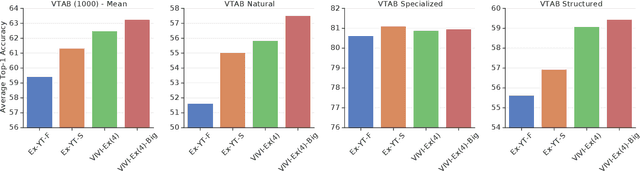
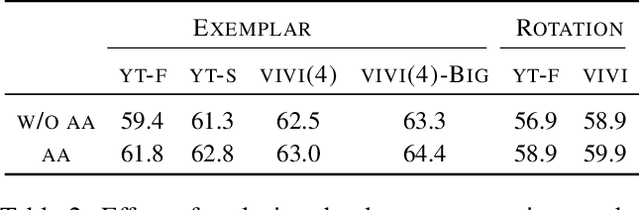
We propose a general framework for self-supervised learning of transferable visual representations based on video-induced visual invariances (VIVI). We consider the implicit hierarchy present in the videos and make use of (i) frame-level invariances (e.g. stability to color and contrast perturbations), (ii) shot/clip-level invariances (e.g. robustness to changes in object orientation and lighting conditions), and (iii) video-level invariances (semantic relationships of scenes across shots/clips), to define a holistic self-supervised loss. Training models using different variants of the proposed framework on videos from the YouTube-8M data set, we obtain state-of-the-art self-supervised transfer learning results on the 19 diverse downstream tasks of the Visual Task Adaptation Benchmark (VTAB), using only 1000 labels per task. We then show how to co-train our models jointly with labeled images, outperforming an ImageNet-pretrained ResNet-50 by 0.8 points with 10x fewer labeled images, as well as the previous best supervised model by 3.7 points using the full ImageNet data set.
In-domain representation learning for remote sensing
Nov 15, 2019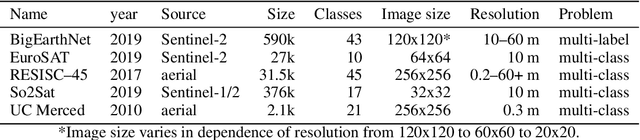
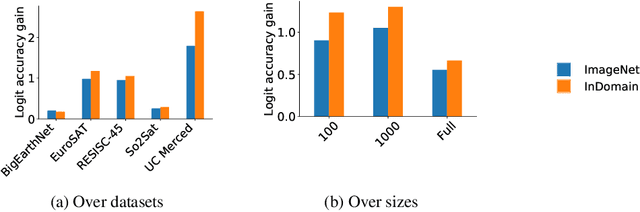
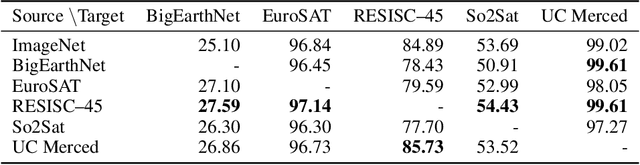
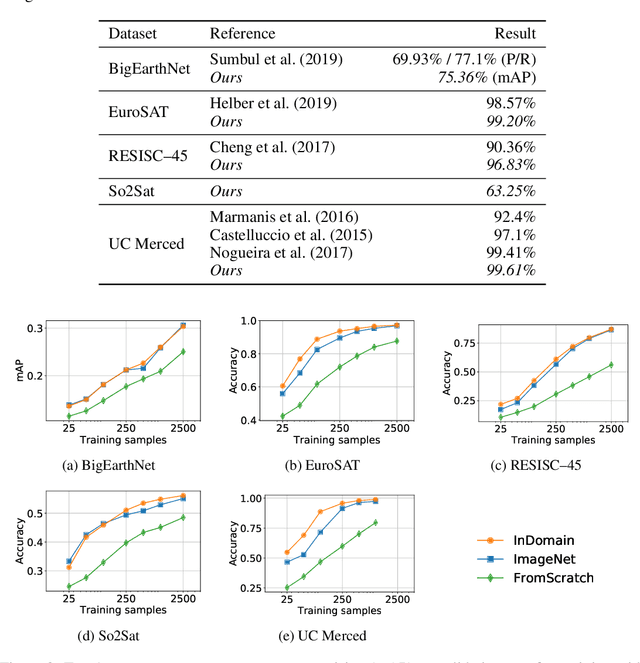
Given the importance of remote sensing, surprisingly little attention has been paid to it by the representation learning community. To address it and to establish baselines and a common evaluation protocol in this domain, we provide simplified access to 5 diverse remote sensing datasets in a standardized form. Specifically, we investigate in-domain representation learning to develop generic remote sensing representations and explore which characteristics are important for a dataset to be a good source for remote sensing representation learning. The established baselines achieve state-of-the-art performance on these datasets.