 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe StarCraft Multi-Agent Challenge
Feb 26, 2019
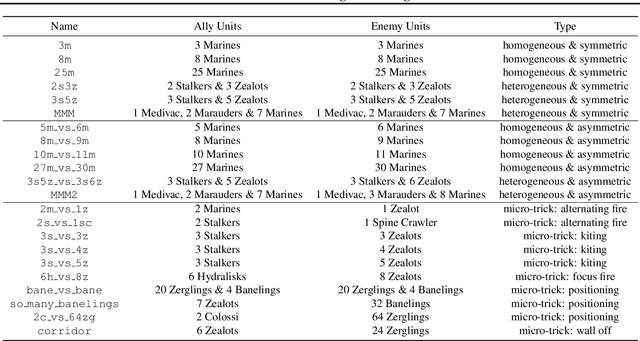

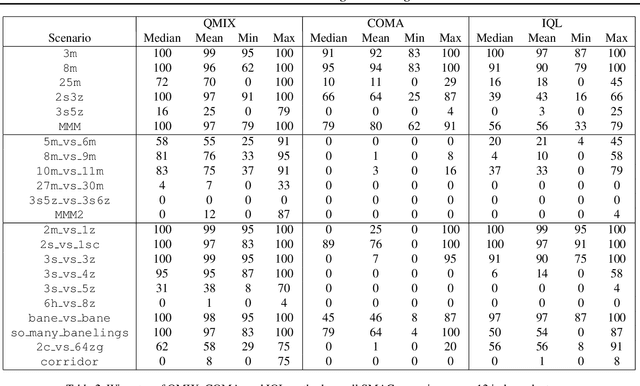
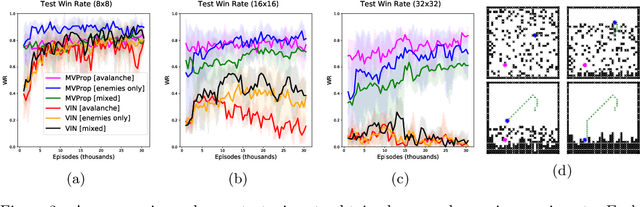
In the last few years, deep multi-agent reinforcement learning (RL) has become a highly active area of research. A particularly challenging class of problems in this area is partially observable, cooperative, multi-agent learning, in which teams of agents must learn to coordinate their behaviour while conditioning only on their private observations. This is an attractive research area since such problems are relevant to a large number of real-world systems and are also more amenable to evaluation than general-sum problems. Standardised environments such as the ALE and MuJoCo have allowed single-agent RL to move beyond toy domains, such as grid worlds. However, there is no comparable benchmark for cooperative multi-agent RL. As a result, most papers in this field use one-off toy problems, making it difficult to measure real progress. In this paper, we propose the StarCraft Multi-Agent Challenge (SMAC) as a benchmark problem to fill this gap. SMAC is based on the popular real-time strategy game StarCraft II and focuses on micromanagement challenges where each unit is controlled by an independent agent that must act based on local observations. We offer a diverse set of challenge maps and recommendations for best practices in benchmarking and evaluations. We also open-source a deep multi-agent RL learning framework including state-of-the-art algorithms. We believe that SMAC can provide a standard benchmark environment for years to come. Videos of our best agents for several SMAC scenarios are available at: https://youtu.be/VZ7zmQ_obZ0.
Value Propagation Networks
May 28, 2018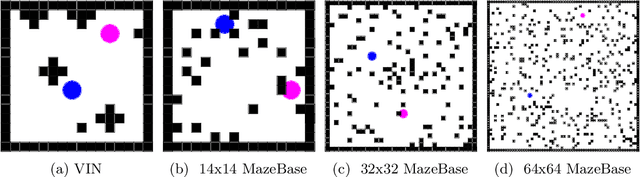

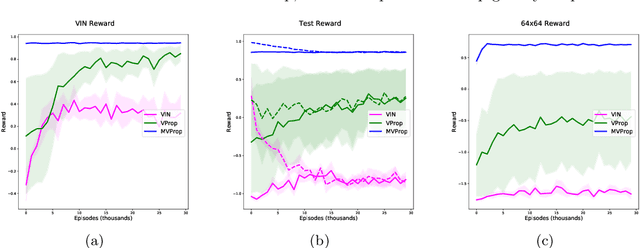
We present Value Propagation (VProp), a parameter-efficient differentiable planning module built on Value Iteration which can successfully be trained using reinforcement learning to solve unseen tasks, has the capability to generalize to larger map sizes, and can learn to navigate in dynamic environments. Furthermore, we show that the module enables learning to plan when the environment also includes stochastic elements, providing a cost-efficient learning system to build low-level size-invariant planners for a variety of interactive navigation problems. We evaluate on static and dynamic configurations of MazeBase grid-worlds, with randomly generated environments of several different sizes, and on a StarCraft navigation scenario, with more complex dynamics, and pixels as input.
Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learning
May 21, 2018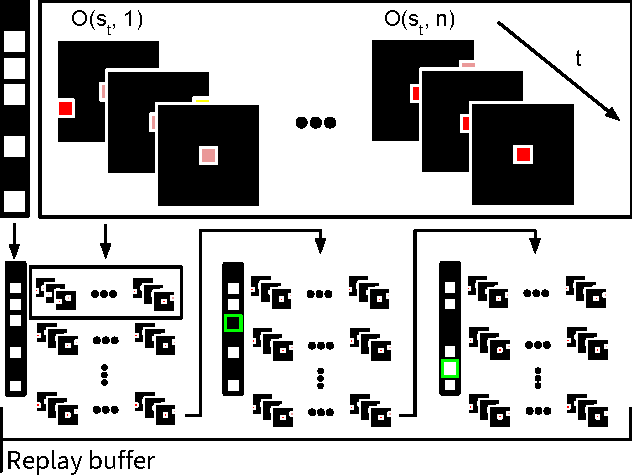

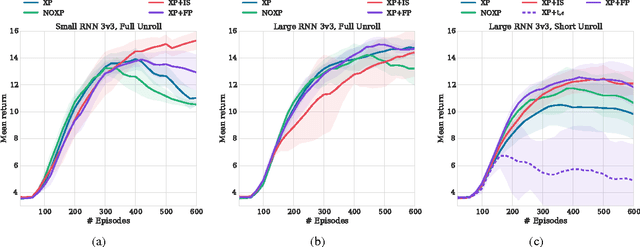
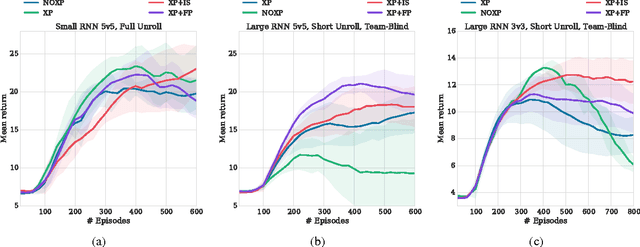
Many real-world problems, such as network packet routing and urban traffic control, are naturally modeled as multi-agent reinforcement learning (RL) problems. However, existing multi-agent RL methods typically scale poorly in the problem size. Therefore, a key challenge is to translate the success of deep learning on single-agent RL to the multi-agent setting. A major stumbling block is that independent Q-learning, the most popular multi-agent RL method, introduces nonstationarity that makes it incompatible with the experience replay memory on which deep Q-learning relies. This paper proposes two methods that address this problem: 1) using a multi-agent variant of importance sampling to naturally decay obsolete data and 2) conditioning each agent's value function on a fingerprint that disambiguates the age of the data sampled from the replay memory. Results on a challenging decentralised variant of StarCraft unit micromanagement confirm that these methods enable the successful combination of experience replay with multi-agent RL.
Counterfactual Multi-Agent Policy Gradients
Dec 14, 2017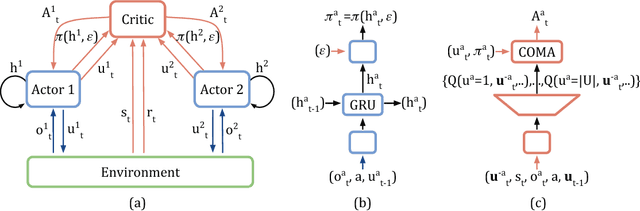


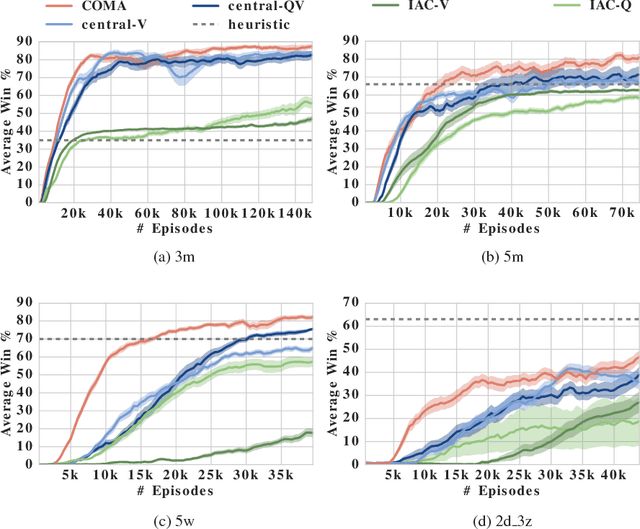
Cooperative multi-agent systems can be naturally used to model many real world problems, such as network packet routing and the coordination of autonomous vehicles. There is a great need for new reinforcement learning methods that can efficiently learn decentralised policies for such systems. To this end, we propose a new multi-agent actor-critic method called counterfactual multi-agent (COMA) policy gradients. COMA uses a centralised critic to estimate the Q-function and decentralised actors to optimise the agents' policies. In addition, to address the challenges of multi-agent credit assignment, it uses a counterfactual baseline that marginalises out a single agent's action, while keeping the other agents' actions fixed. COMA also uses a critic representation that allows the counterfactual baseline to be computed efficiently in a single forward pass. We evaluate COMA in the testbed of StarCraft unit micromanagement, using a decentralised variant with significant partial observability. COMA significantly improves average performance over other multi-agent actor-critic methods in this setting, and the best performing agents are competitive with state-of-the-art centralised controllers that get access to the full state.
Playing Doom with SLAM-Augmented Deep Reinforcement Learning
Dec 01, 2016

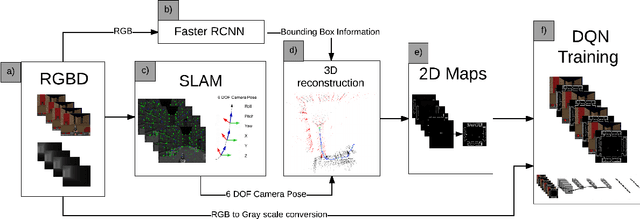
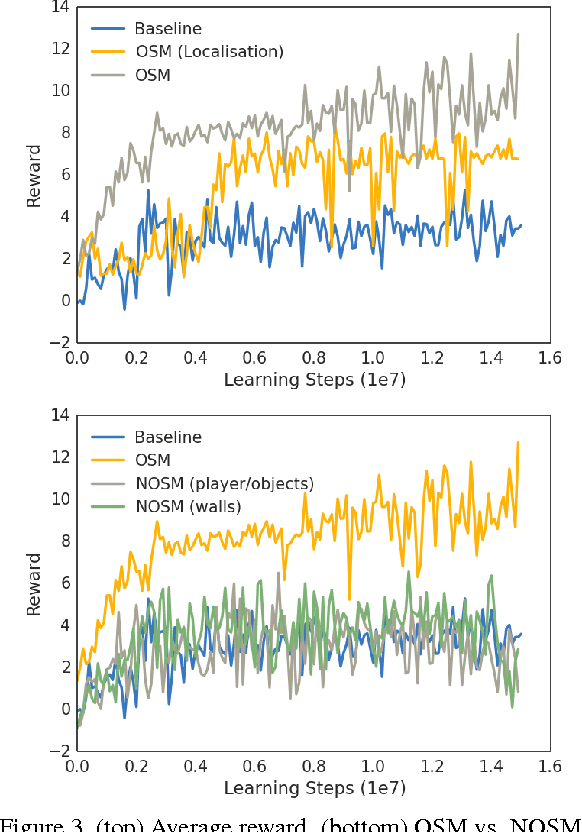
A number of recent approaches to policy learning in 2D game domains have been successful going directly from raw input images to actions. However when employed in complex 3D environments, they typically suffer from challenges related to partial observability, combinatorial exploration spaces, path planning, and a scarcity of rewarding scenarios. Inspired from prior work in human cognition that indicates how humans employ a variety of semantic concepts and abstractions (object categories, localisation, etc.) to reason about the world, we build an agent-model that incorporates such abstractions into its policy-learning framework. We augment the raw image input to a Deep Q-Learning Network (DQN), by adding details of objects and structural elements encountered, along with the agent's localisation. The different components are automatically extracted and composed into a topological representation using on-the-fly object detection and 3D-scene reconstruction.We evaluate the efficacy of our approach in Doom, a 3D first-person combat game that exhibits a number of challenges discussed, and show that our augmented framework consistently learns better, more effective policies.
TorchCraft: a Library for Machine Learning Research on Real-Time Strategy Games
Nov 03, 2016
We present TorchCraft, a library that enables deep learning research on Real-Time Strategy (RTS) games such as StarCraft: Brood War, by making it easier to control these games from a machine learning framework, here Torch. This white paper argues for using RTS games as a benchmark for AI research, and describes the design and components of TorchCraft.