 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe JHU submission to VoxSRC-21: Track 3
Sep 28, 2021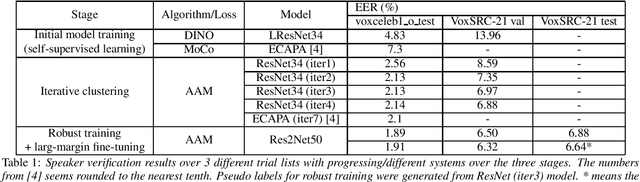
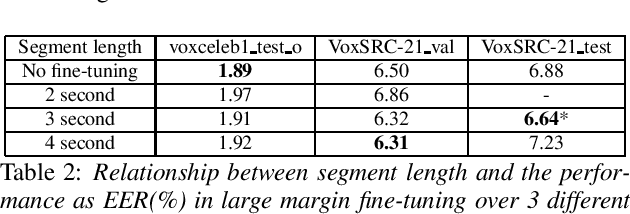
This technical report describes Johns Hopkins University speaker recognition system submitted to Voxceleb Speaker Recognition Challenge 2021 Track 3: Self-supervised speaker verification (closed). Our overall training process is similar to the proposed one from the first place team in the last year's VoxSRC2020 challenge. The main difference is a recently proposed non-contrastive self-supervised method in computer vision (CV), distillation with no labels (DINO), is used to train our initial model, which outperformed the last year's contrastive learning based on momentum contrast (MoCo). Also, this requires only a few iterations in the iterative clustering stage, where pseudo labels for supervised embedding learning are updated based on the clusters of the embeddings generated from a model that is continually fine-tuned over iterations. In the final stage, Res2Net50 is trained on the final pseudo labels from the iterative clustering stage. This is our best submitted model to the challenge, showing 1.89, 6.50, and 6.89 in EER(%) in voxceleb1 test o, VoxSRC-21 validation, and test trials, respectively.
Beyond Isolated Utterances: Conversational Emotion Recognition
Sep 13, 2021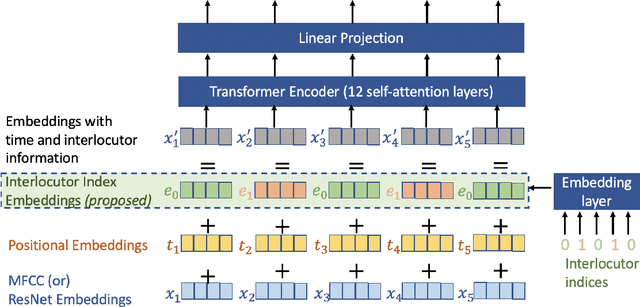

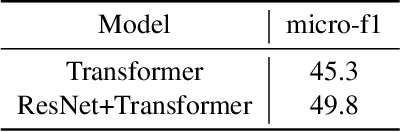
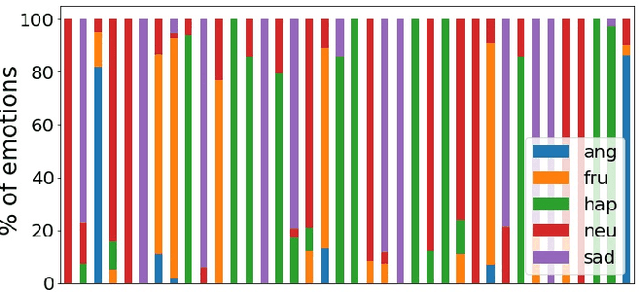
Speech emotion recognition is the task of recognizing the speaker's emotional state given a recording of their utterance. While most of the current approaches focus on inferring emotion from isolated utterances, we argue that this is not sufficient to achieve conversational emotion recognition (CER) which deals with recognizing emotions in conversations. In this work, we propose several approaches for CER by treating it as a sequence labeling task. We investigated transformer architecture for CER and, compared it with ResNet-34 and BiLSTM architectures in both contextual and context-less scenarios using IEMOCAP corpus. Based on the inner workings of the self-attention mechanism, we proposed DiverseCatAugment (DCA), an augmentation scheme, which improved the transformer model performance by an absolute 3.3% micro-f1 on conversations and 3.6% on isolated utterances. We further enhanced the performance by introducing an interlocutor-aware transformer model where we learn a dictionary of interlocutor index embeddings to exploit diarized conversations.
Joint prediction of truecasing and punctuation for conversational speech in low-resource scenarios
Sep 13, 2021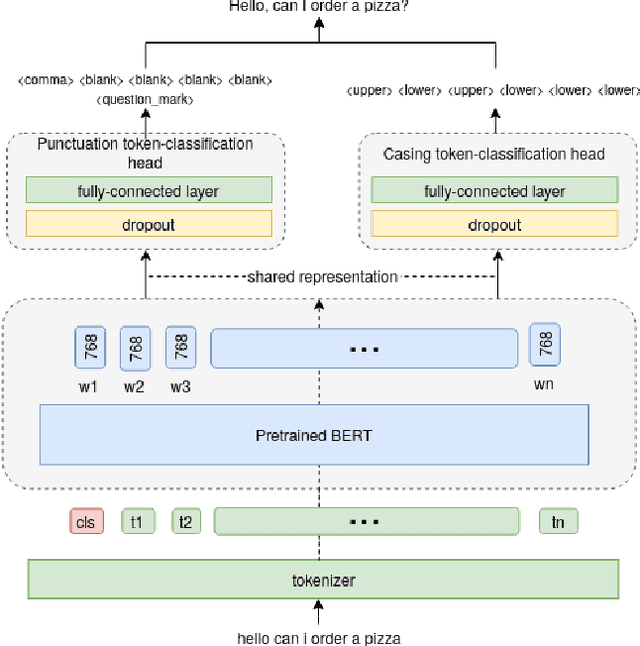
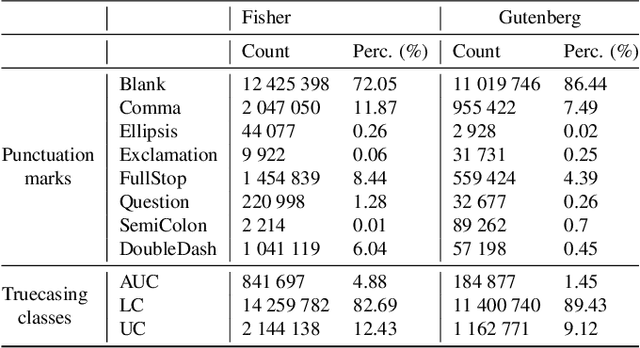
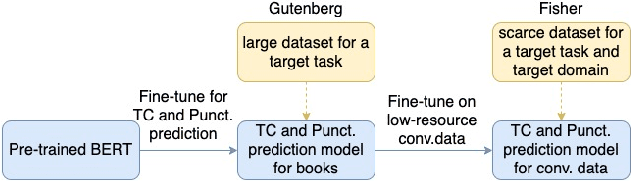
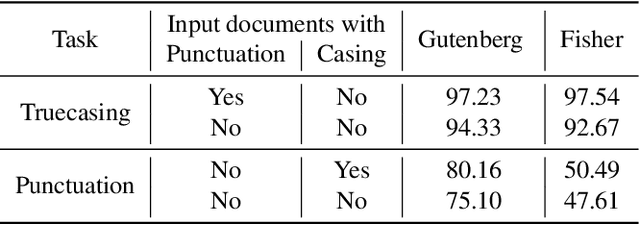
Capitalization and punctuation are important cues for comprehending written texts and conversational transcripts. Yet, many ASR systems do not produce punctuated and case-formatted speech transcripts. We propose to use a multi-task system that can exploit the relations between casing and punctuation to improve their prediction performance. Whereas text data for predicting punctuation and truecasing is seemingly abundant, we argue that written text resources are inadequate as training data for conversational models. We quantify the mismatch between written and conversational text domains by comparing the joint distributions of punctuation and word cases, and by testing our model cross-domain. Further, we show that by training the model in the written text domain and then transfer learning to conversations, we can achieve reasonable performance with less data.
Representation Learning to Classify and Detect Adversarial Attacks against Speaker and Speech Recognition Systems
Jul 09, 2021
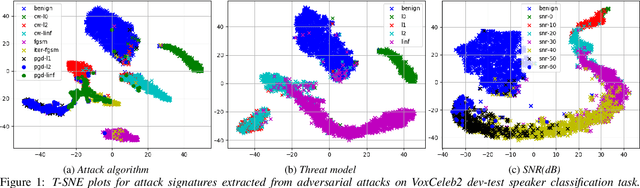
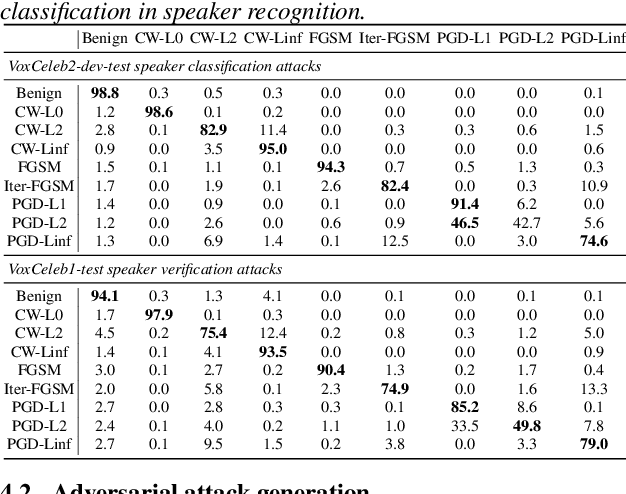
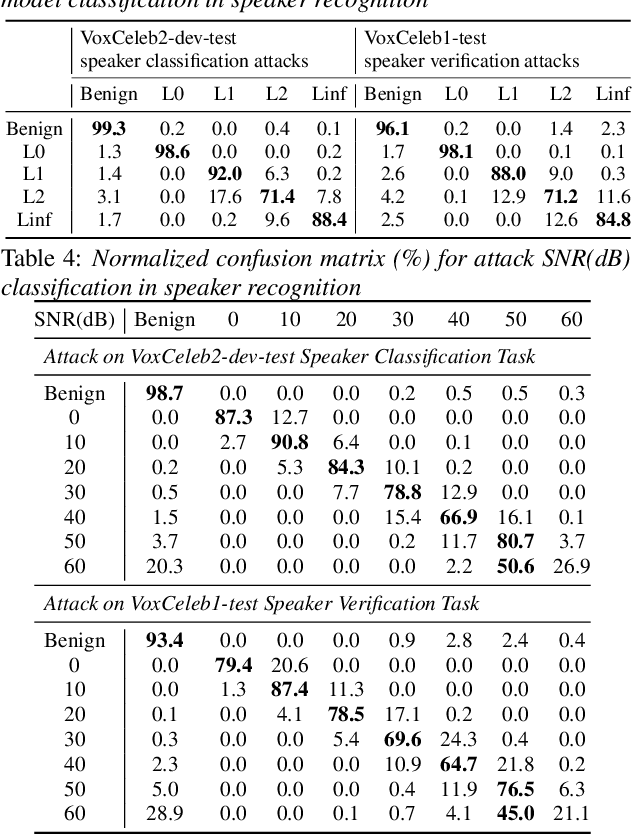
Adversarial attacks have become a major threat for machine learning applications. There is a growing interest in studying these attacks in the audio domain, e.g, speech and speaker recognition; and find defenses against them. In this work, we focus on using representation learning to classify/detect attacks w.r.t. the attack algorithm, threat model or signal-to-adversarial-noise ratio. We found that common attacks in the literature can be classified with accuracies as high as 90%. Also, representations trained to classify attacks against speaker identification can be used also to classify attacks against speaker verification and speech recognition. We also tested an attack verification task, where we need to decide whether two speech utterances contain the same attack. We observed that our models did not generalize well to attack algorithms not included in the attack representation model training. Motivated by this, we evaluated an unknown attack detection task. We were able to detect unknown attacks with equal error rates of about 19%, which is promising.
What Helps Transformers Recognize Conversational Structure? Importance of Context, Punctuation, and Labels in Dialog Act Recognition
Jul 05, 2021
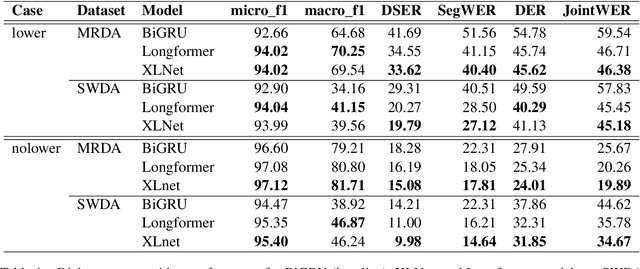
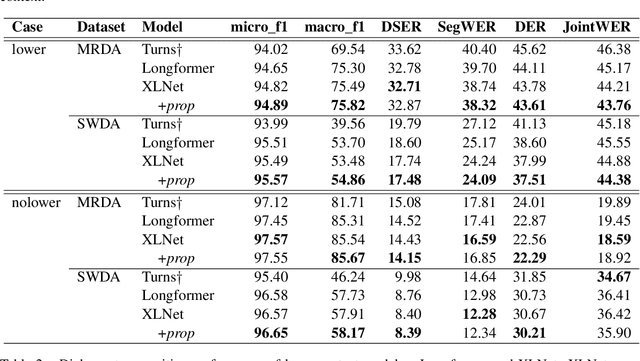
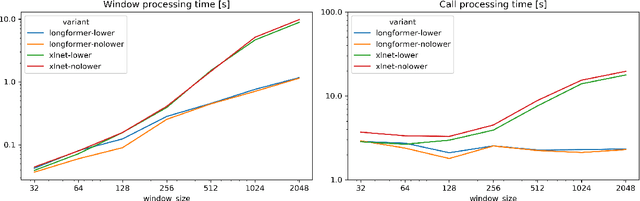
Dialog acts can be interpreted as the atomic units of a conversation, more fine-grained than utterances, characterized by a specific communicative function. The ability to structure a conversational transcript as a sequence of dialog acts -- dialog act recognition, including the segmentation -- is critical for understanding dialog. We apply two pre-trained transformer models, XLNet and Longformer, to this task in English and achieve strong results on Switchboard Dialog Act and Meeting Recorder Dialog Act corpora with dialog act segmentation error rates (DSER) of 8.4% and 14.2%. To understand the key factors affecting dialog act recognition, we perform a comparative analysis of models trained under different conditions. We find that the inclusion of a broader conversational context helps disambiguate many dialog act classes, especially those infrequent in the training data. The presence of punctuation in the transcripts has a massive effect on the models' performance, and a detailed analysis reveals specific segmentation patterns observed in its absence. Finally, we find that the label set specificity does not affect dialog act segmentation performance. These findings have significant practical implications for spoken language understanding applications that depend heavily on a good-quality segmentation being available.
WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
Jun 19, 2021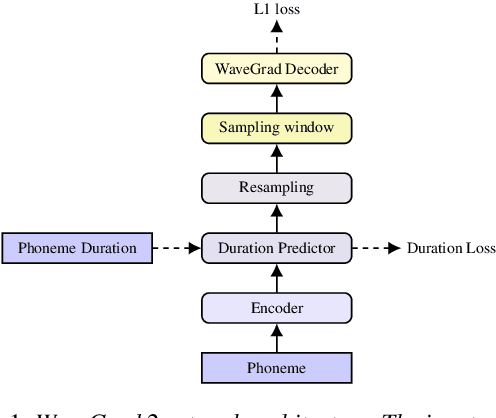
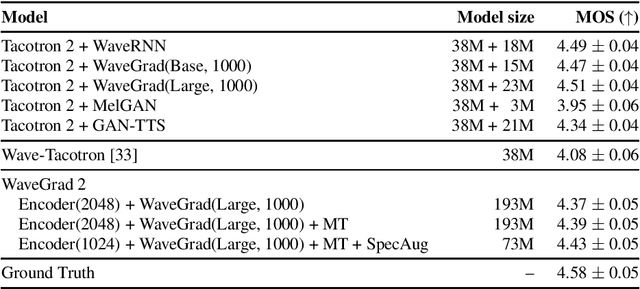
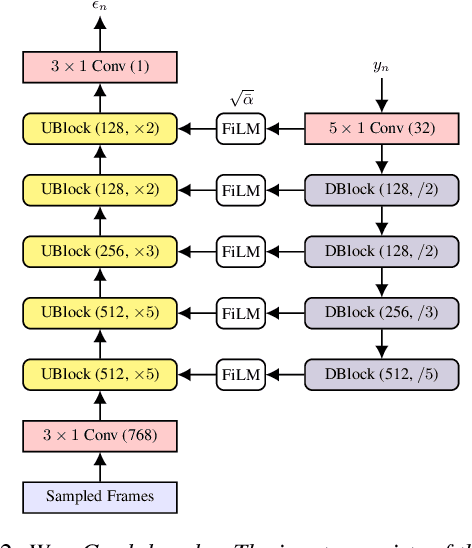

This paper introduces WaveGrad 2, a non-autoregressive generative model for text-to-speech synthesis. WaveGrad 2 is trained to estimate the gradient of the log conditional density of the waveform given a phoneme sequence. The model takes an input phoneme sequence, and through an iterative refinement process, generates an audio waveform. This contrasts to the original WaveGrad vocoder which conditions on mel-spectrogram features, generated by a separate model. The iterative refinement process starts from Gaussian noise, and through a series of refinement steps (e.g., 50 steps), progressively recovers the audio sequence. WaveGrad 2 offers a natural way to trade-off between inference speed and sample quality, through adjusting the number of refinement steps. Experiments show that the model can generate high fidelity audio, approaching the performance of a state-of-the-art neural TTS system. We also report various ablation studies over different model configurations. Audio samples are available at https://wavegrad.github.io/v2.
Segmental Contrastive Predictive Coding for Unsupervised Word Segmentation
Jun 03, 2021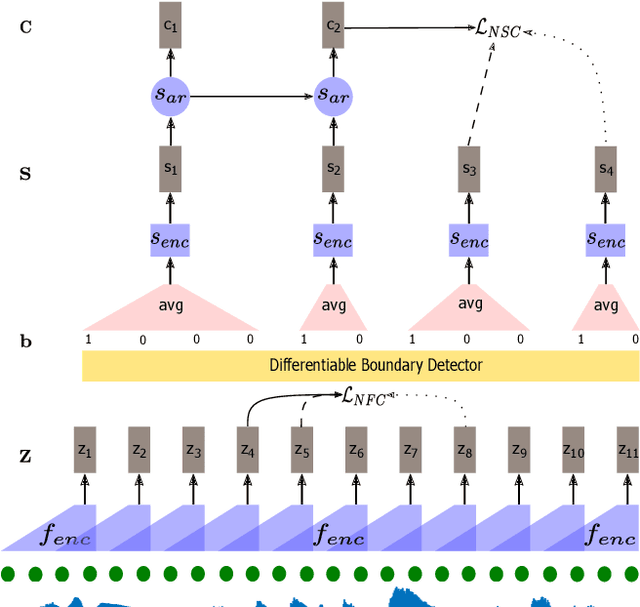
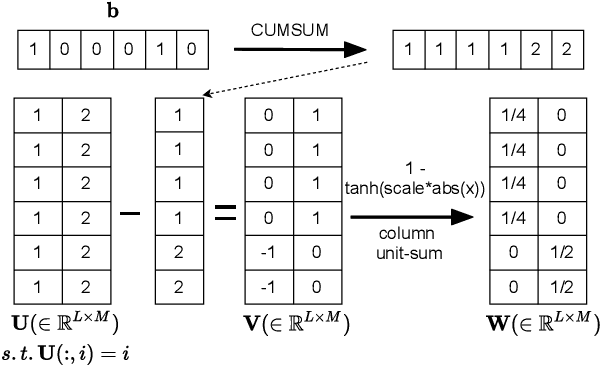
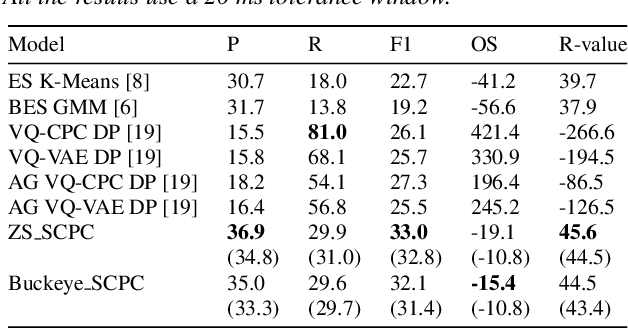
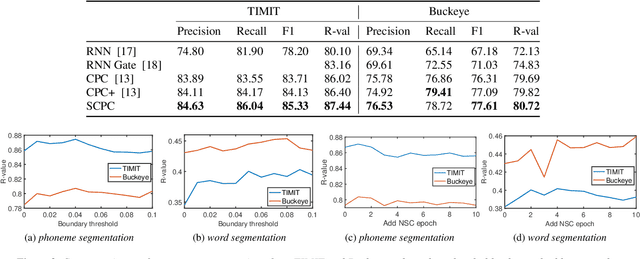
Automatic detection of phoneme or word-like units is one of the core objectives in zero-resource speech processing. Recent attempts employ self-supervised training methods, such as contrastive predictive coding (CPC), where the next frame is predicted given past context. However, CPC only looks at the audio signal's frame-level structure. We overcome this limitation with a segmental contrastive predictive coding (SCPC) framework that can model the signal structure at a higher level e.g. at the phoneme level. In this framework, a convolutional neural network learns frame-level representation from the raw waveform via noise-contrastive estimation (NCE). A differentiable boundary detector finds variable-length segments, which are then used to optimize a segment encoder via NCE to learn segment representations. The differentiable boundary detector allows us to train frame-level and segment-level encoders jointly. Typically, phoneme and word segmentation are treated as separate tasks. We unify them and experimentally show that our single model outperforms existing phoneme and word segmentation methods on TIMIT and Buckeye datasets. We analyze the impact of boundary threshold and when is the right time to include the segmental loss in the learning process.
Deep Feature CycleGANs: Speaker Identity Preserving Non-parallel Microphone-Telephone Domain Adaptation for Speaker Verification
Apr 03, 2021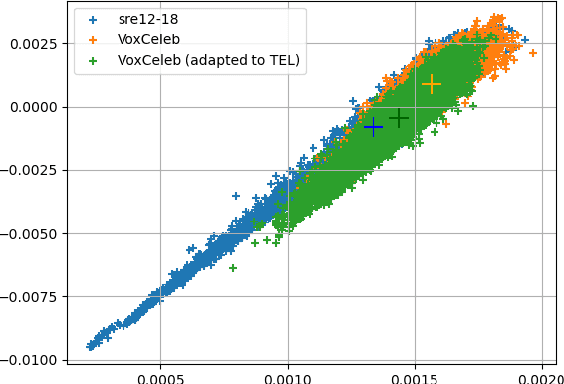
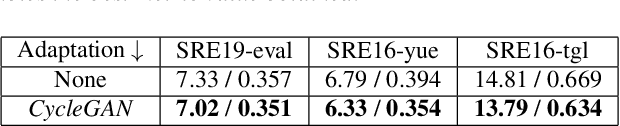
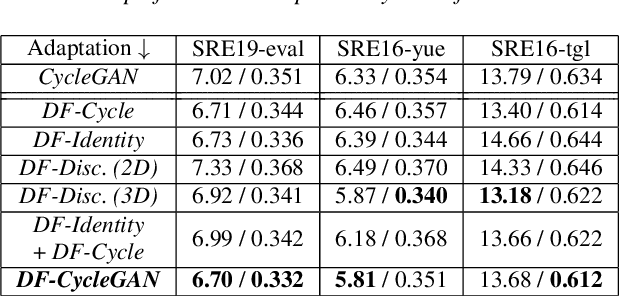
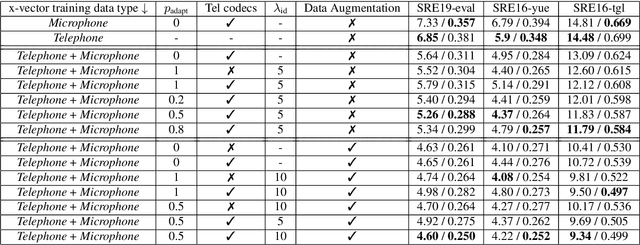
With the increase in the availability of speech from varied domains, it is imperative to use such out-of-domain data to improve existing speech systems. Domain adaptation is a prominent pre-processing approach for this. We investigate it for adapt microphone speech to the telephone domain. Specifically, we explore CycleGAN-based unpaired translation of microphone data to improve the x-vector/speaker embedding network for Telephony Speaker Verification. We first demonstrate the efficacy of this on real challenging data and then, to improve further, we modify the CycleGAN formulation to make the adaptation task-specific. We modify CycleGAN's identity loss, cycle-consistency loss, and adversarial loss to operate in the deep feature space. Deep features of a signal are extracted from an auxiliary (speaker embedding) network and, hence, preserves speaker identity. Our 3D convolution-based Deep Feature Discriminators (DFD) show relative improvements of 5-10% in terms of equal error rate. To dive deeper, we study a challenging scenario of pooling (adapted) microphone and telephone data with data augmentations and telephone codecs. Finally, we highlight the sensitivity of CycleGAN hyper-parameters and introduce a parameter called probability of adaptation.
Adversarial Attacks and Defenses for Speech Recognition Systems
Mar 31, 2021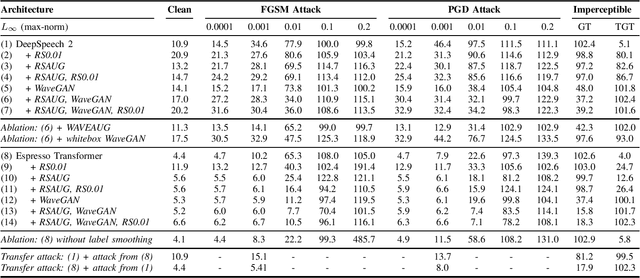
The ubiquitous presence of machine learning systems in our lives necessitates research into their vulnerabilities and appropriate countermeasures. In particular, we investigate the effectiveness of adversarial attacks and defenses against automatic speech recognition (ASR) systems. We select two ASR models - a thoroughly studied DeepSpeech model and a more recent Espresso framework Transformer encoder-decoder model. We investigate two threat models: a denial-of-service scenario where fast gradient-sign method (FGSM) or weak projected gradient descent (PGD) attacks are used to degrade the model's word error rate (WER); and a targeted scenario where a more potent imperceptible attack forces the system to recognize a specific phrase. We find that the attack transferability across the investigated ASR systems is limited. To defend the model, we use two preprocessing defenses: randomized smoothing and WaveGAN-based vocoder, and find that they significantly improve the model's adversarial robustness. We show that a WaveGAN vocoder can be a useful countermeasure to adversarial attacks on ASR systems - even when it is jointly attacked with the ASR, the target phrases' word error rate is high.
Adversarial Attacks and Defenses for Speaker Identification Systems
Jan 22, 2021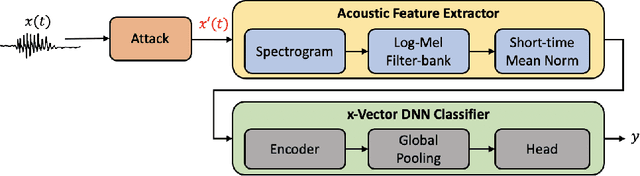
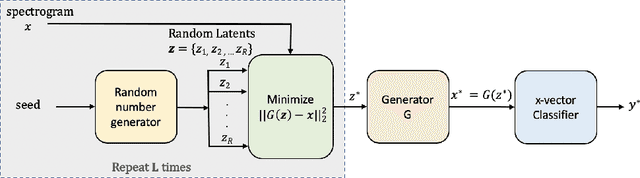

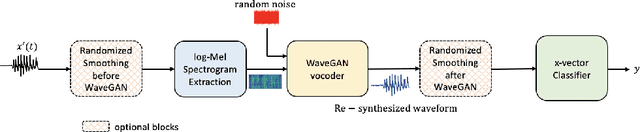
Research in automatic speaker recognition (SR) has been undertaken for several decades, reaching great performance. However, researchers discovered potential loopholes in these technologies like spoofing attacks. Quite recently, a new genre of attack, termed adversarial attacks, has been proved to be fatal in computer vision and it is vital to study their effects on SR systems. This paper examines how state-of-the-art speaker identification (SID) systems are vulnerable to adversarial attacks and how to defend against them. We investigated adversarial attacks common in the literature like fast gradient sign method (FGSM), iterative-FGSM / basic iterative method (BIM) and Carlini-Wagner (CW). Furthermore, we propose four pre-processing defenses against these attacks - randomized smoothing, DefenseGAN, variational autoencoder (VAE) and WaveGAN vocoder. We found that SID is extremely vulnerable under Iterative FGSM and CW attacks. Randomized smoothing defense robustified the system for imperceptible BIM and CW attacks recovering classification accuracies ~97%. Defenses based on generative models (DefenseGAN, VAE and WaveGAN) project adversarial examples (outside manifold) back into the clean manifold. In the case that attacker cannot adapt the attack to the defense (black-box defense), WaveGAN performed the best, being close to clean condition (Accuracy>97%). However, if the attack is adapted to the defense - assuming the attacker has access to the defense model (white-box defense), VAE and WaveGAN protection dropped significantly-50% and 37% accuracy for CW attack. To counteract this,we combined randomized smoothing with VAE or WaveGAN. We found that smoothing followed by WaveGAN vocoder was the most effective defense overall. As a black-box defense, it provides 93% average accuracy. As white-box defense, accuracy only degraded for iterative attacks with perceptible perturbations (L>=0.01).