 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeeperCut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model
Nov 30, 2016
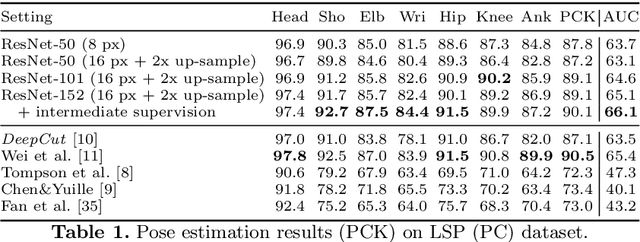
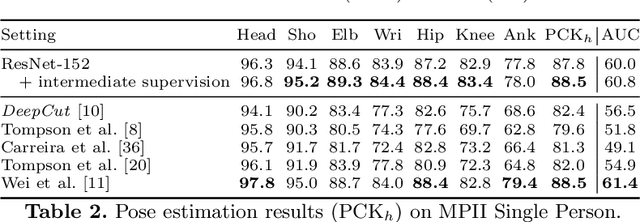

The goal of this paper is to advance the state-of-the-art of articulated pose estimation in scenes with multiple people. To that end we contribute on three fronts. We propose (1) improved body part detectors that generate effective bottom-up proposals for body parts; (2) novel image-conditioned pairwise terms that allow to assemble the proposals into a variable number of consistent body part configurations; and (3) an incremental optimization strategy that explores the search space more efficiently thus leading both to better performance and significant speed-up factors. Evaluation is done on two single-person and two multi-person pose estimation benchmarks. The proposed approach significantly outperforms best known multi-person pose estimation results while demonstrating competitive performance on the task of single person pose estimation. Models and code available at http://pose.mpi-inf.mpg.de
Multi-Person Tracking by Multicut and Deep Matching
Aug 17, 2016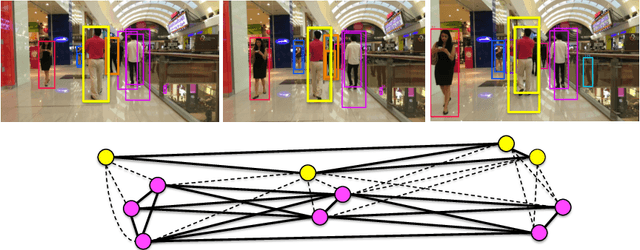
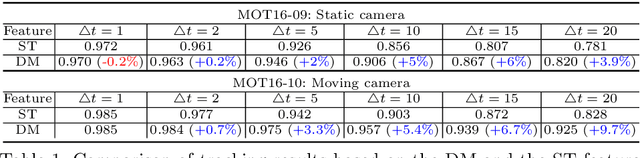

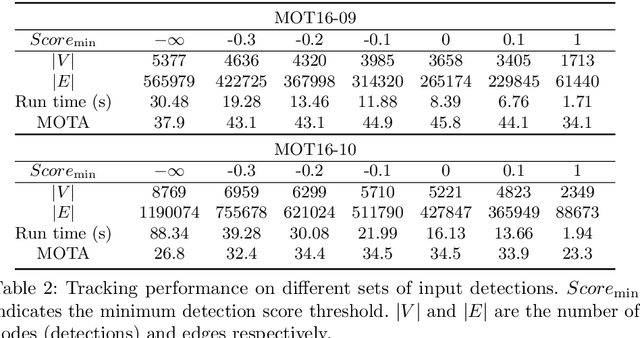
In [1], we proposed a graph-based formulation that links and clusters person hypotheses over time by solving a minimum cost subgraph multicut problem. In this paper, we modify and extend [1] in three ways: 1) We introduce a novel local pairwise feature based on local appearance matching that is robust to partial occlusion and camera motion. 2) We perform extensive experiments to compare different pairwise potentials and to analyze the robustness of the tracking formulation. 3) We consider a plain multicut problem and remove outlying clusters from its solution. This allows us to employ an efficient primal feasible optimization algorithm that is not applicable to the subgraph multicut problem of [1]. Unlike the branch-and-cut algorithm used there, this efficient algorithm used here is applicable to long videos and many detections. Together with the novel feature, it eliminates the need for the intermediate tracklet representation of [1]. We demonstrate the effectiveness of our overall approach on the MOT16 benchmark [2], achieving state-of-art performance.
DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation
Apr 26, 2016
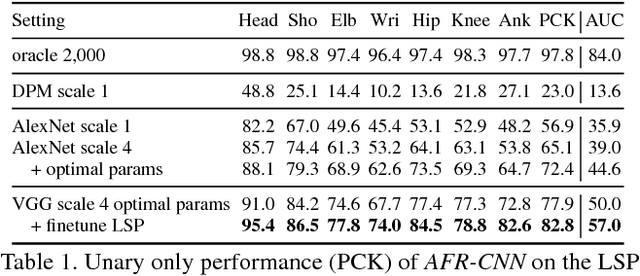
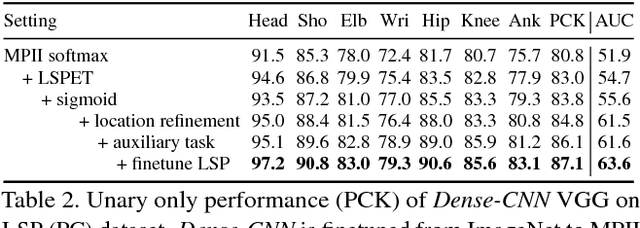
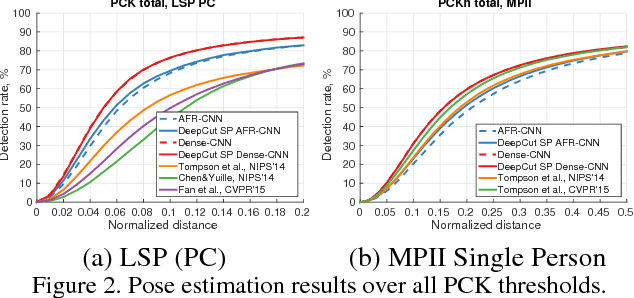
This paper considers the task of articulated human pose estimation of multiple people in real world images. We propose an approach that jointly solves the tasks of detection and pose estimation: it infers the number of persons in a scene, identifies occluded body parts, and disambiguates body parts between people in close proximity of each other. This joint formulation is in contrast to previous strategies, that address the problem by first detecting people and subsequently estimating their body pose. We propose a partitioning and labeling formulation of a set of body-part hypotheses generated with CNN-based part detectors. Our formulation, an instance of an integer linear program, implicitly performs non-maximum suppression on the set of part candidates and groups them to form configurations of body parts respecting geometric and appearance constraints. Experiments on four different datasets demonstrate state-of-the-art results for both single person and multi person pose estimation. Models and code available at http://pose.mpi-inf.mpg.de.
Recognizing Fine-Grained and Composite Activities using Hand-Centric Features and Script Data
Oct 15, 2015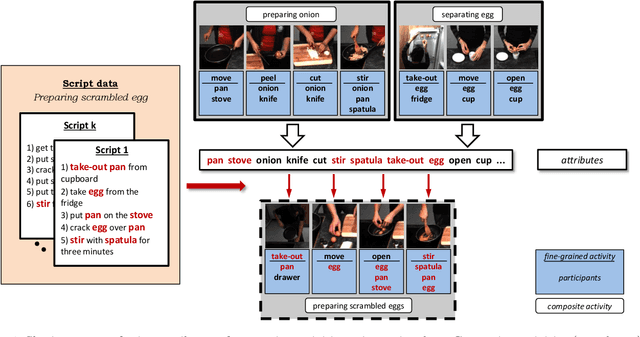
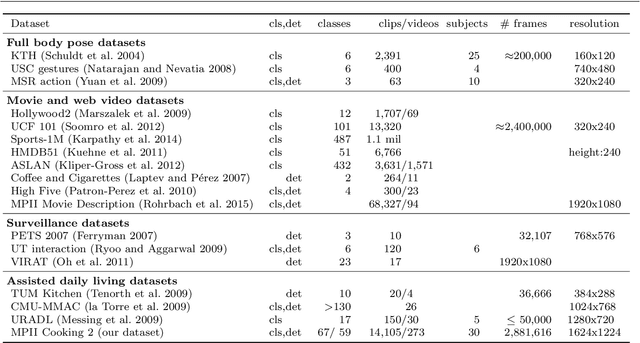

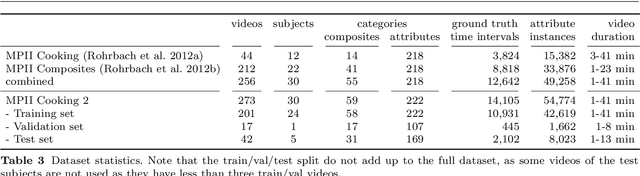
Activity recognition has shown impressive progress in recent years. However, the challenges of detecting fine-grained activities and understanding how they are combined into composite activities have been largely overlooked. In this work we approach both tasks and present a dataset which provides detailed annotations to address them. The first challenge is to detect fine-grained activities, which are defined by low inter-class variability and are typically characterized by fine-grained body motions. We explore how human pose and hands can help to approach this challenge by comparing two pose-based and two hand-centric features with state-of-the-art holistic features. To attack the second challenge, recognizing composite activities, we leverage the fact that these activities are compositional and that the essential components of the activities can be obtained from textual descriptions or scripts. We show the benefits of our hand-centric approach for fine-grained activity classification and detection. For composite activity recognition we find that decomposition into attributes allows sharing information across composites and is essential to attack this hard task. Using script data we can recognize novel composites without having training data for them.
End-to-end people detection in crowded scenes
Jul 08, 2015
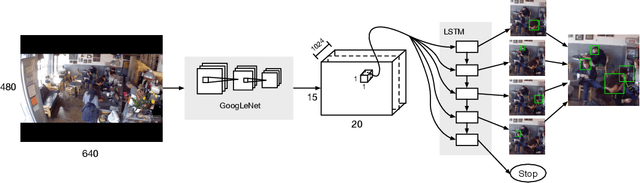

Current people detectors operate either by scanning an image in a sliding window fashion or by classifying a discrete set of proposals. We propose a model that is based on decoding an image into a set of people detections. Our system takes an image as input and directly outputs a set of distinct detection hypotheses. Because we generate predictions jointly, common post-processing steps such as non-maximum suppression are unnecessary. We use a recurrent LSTM layer for sequence generation and train our model end-to-end with a new loss function that operates on sets of detections. We demonstrate the effectiveness of our approach on the challenging task of detecting people in crowded scenes.
An Empirical Evaluation of Deep Learning on Highway Driving
Apr 17, 2015
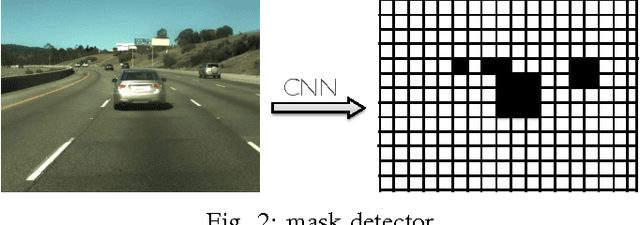
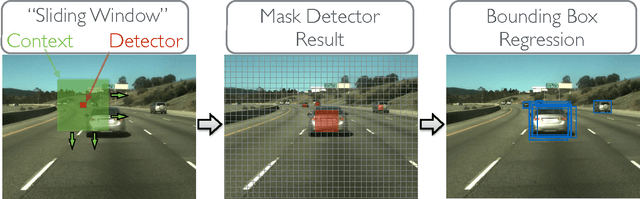
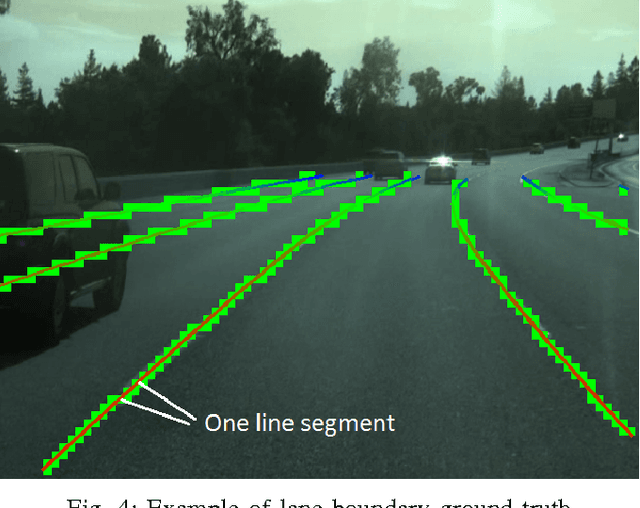
Numerous groups have applied a variety of deep learning techniques to computer vision problems in highway perception scenarios. In this paper, we presented a number of empirical evaluations of recent deep learning advances. Computer vision, combined with deep learning, has the potential to bring about a relatively inexpensive, robust solution to autonomous driving. To prepare deep learning for industry uptake and practical applications, neural networks will require large data sets that represent all possible driving environments and scenarios. We collect a large data set of highway data and apply deep learning and computer vision algorithms to problems such as car and lane detection. We show how existing convolutional neural networks (CNNs) can be used to perform lane and vehicle detection while running at frame rates required for a real-time system. Our results lend credence to the hypothesis that deep learning holds promise for autonomous driving.
Fine-grained Activity Recognition with Holistic and Pose based Features
Jul 28, 2014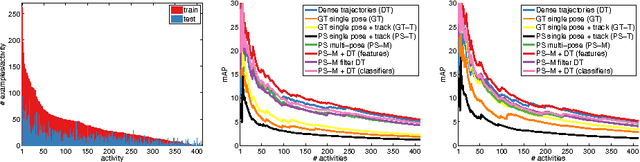
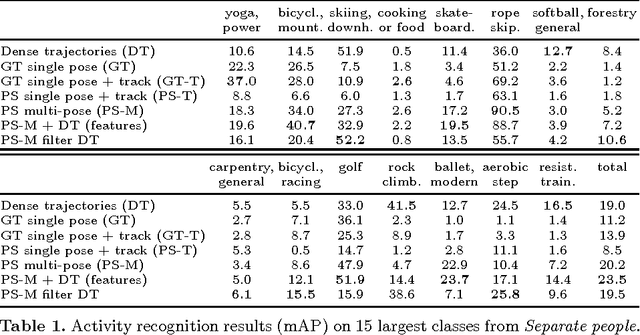
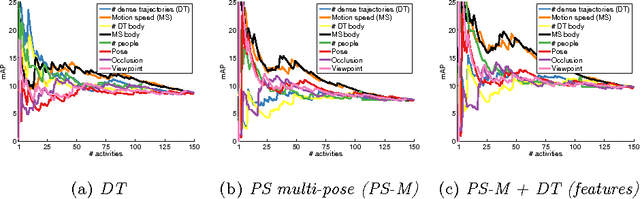

Holistic methods based on dense trajectories are currently the de facto standard for recognition of human activities in video. Whether holistic representations will sustain or will be superseded by higher level video encoding in terms of body pose and motion is the subject of an ongoing debate. In this paper we aim to clarify the underlying factors responsible for good performance of holistic and pose-based representations. To that end we build on our recent dataset leveraging the existing taxonomy of human activities. This dataset includes 24,920 video snippets covering 410 human activities in total. Our analysis reveals that holistic and pose-based methods are highly complementary, and their performance varies significantly depending on the activity. We find that holistic methods are mostly affected by the number and speed of trajectories, whereas pose-based methods are mostly influenced by viewpoint of the person. We observe striking performance differences across activities: for certain activities results with pose-based features are more than twice as accurate compared to holistic features, and vice versa. The best performing approach in our comparison is based on the combination of holistic and pose-based approaches, which again underlines their complementarity.
Learning Human Pose Estimation Features with Convolutional Networks
Apr 23, 2014
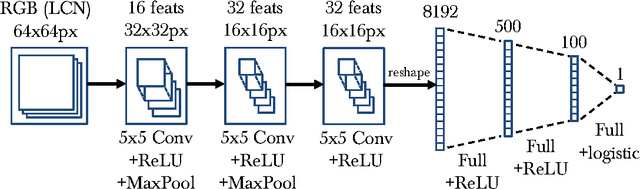
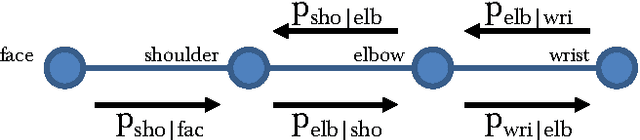
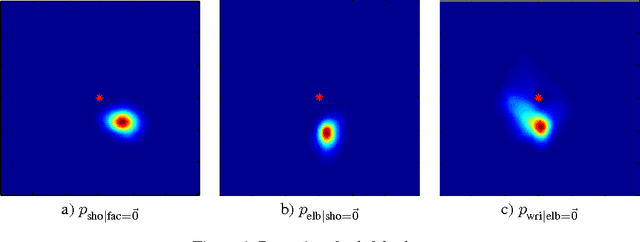
This paper introduces a new architecture for human pose estimation using a multi- layer convolutional network architecture and a modified learning technique that learns low-level features and higher-level weak spatial models. Unconstrained human pose estimation is one of the hardest problems in computer vision, and our new architecture and learning schema shows significant improvement over the current state-of-the-art results. The main contribution of this paper is showing, for the first time, that a specific variation of deep learning is able to outperform all existing traditional architectures on this task. The paper also discusses several lessons learned while researching alternatives, most notably, that it is possible to learn strong low-level feature detectors on features that might even just cover a few pixels in the image. Higher-level spatial models improve somewhat the overall result, but to a much lesser extent then expected. Many researchers previously argued that the kinematic structure and top-down information is crucial for this domain, but with our purely bottom up, and weak spatial model, we could improve other more complicated architectures that currently produce the best results. This mirrors what many other researchers, like those in the speech recognition, object recognition, and other domains have experienced.
Coherent Multi-Sentence Video Description with Variable Level of Detail
Mar 24, 2014
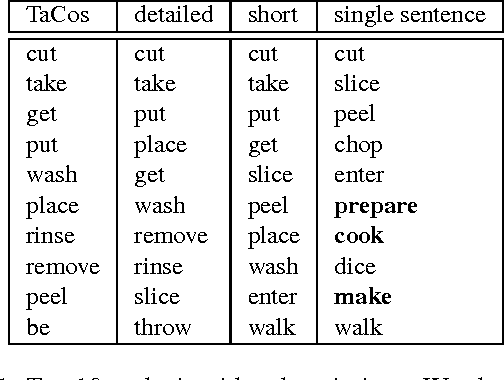
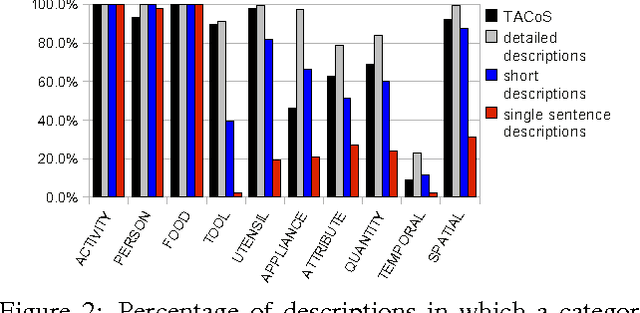
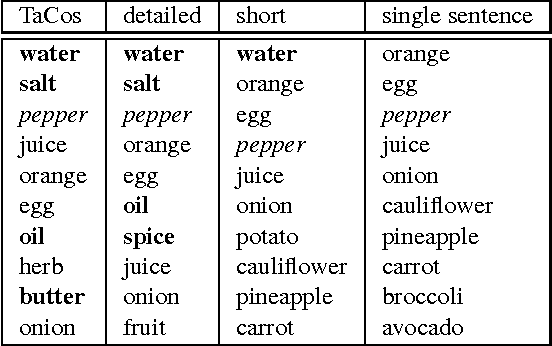
Humans can easily describe what they see in a coherent way and at varying level of detail. However, existing approaches for automatic video description are mainly focused on single sentence generation and produce descriptions at a fixed level of detail. In this paper, we address both of these limitations: for a variable level of detail we produce coherent multi-sentence descriptions of complex videos. We follow a two-step approach where we first learn to predict a semantic representation (SR) from video and then generate natural language descriptions from the SR. To produce consistent multi-sentence descriptions, we model across-sentence consistency at the level of the SR by enforcing a consistent topic. We also contribute both to the visual recognition of objects proposing a hand-centric approach as well as to the robust generation of sentences using a word lattice. Human judges rate our multi-sentence descriptions as more readable, correct, and relevant than related work. To understand the difference between more detailed and shorter descriptions, we collect and analyze a video description corpus of three levels of detail.