 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylized Adversarial Defense
Jul 29, 2020
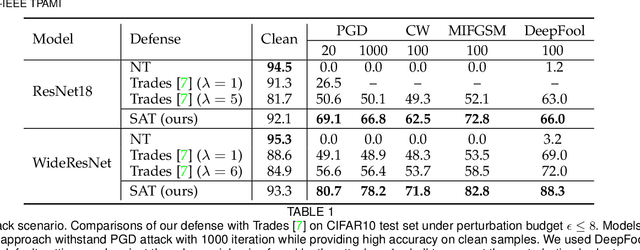
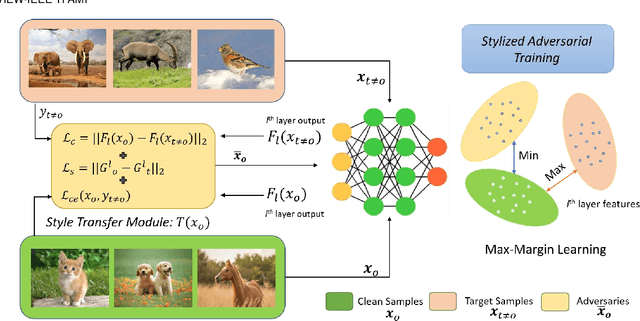
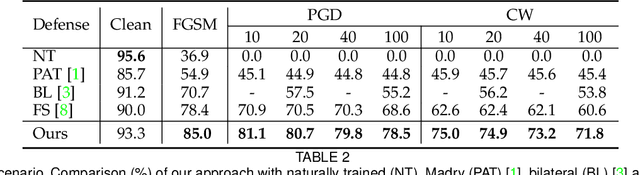
Deep Convolution Neural Networks (CNNs) can easily be fooled by subtle, imperceptible changes to the input images. To address this vulnerability, adversarial training creates perturbation patterns and includes them in the training set to robustify the model. In contrast to existing adversarial training methods that only use class-boundary information (e.g., using a cross entropy loss), we propose to exploit additional information from the feature space to craft stronger adversaries that are in turn used to learn a robust model. Specifically, we use the style and content information of the target sample from another class, alongside its class boundary information to create adversarial perturbations. We apply our proposed multi-task objective in a deeply supervised manner, extracting multi-scale feature knowledge to create maximally separating adversaries. Subsequently, we propose a max-margin adversarial training approach that minimizes the distance between source image and its adversary and maximizes the distance between the adversary and the target image. Our adversarial training approach demonstrates strong robustness compared to state of the art defenses, generalizes well to naturally occurring corruptions and data distributional shifts, and retains the model accuracy on clean examples.
Self-supervised Knowledge Distillation for Few-shot Learning
Jun 17, 2020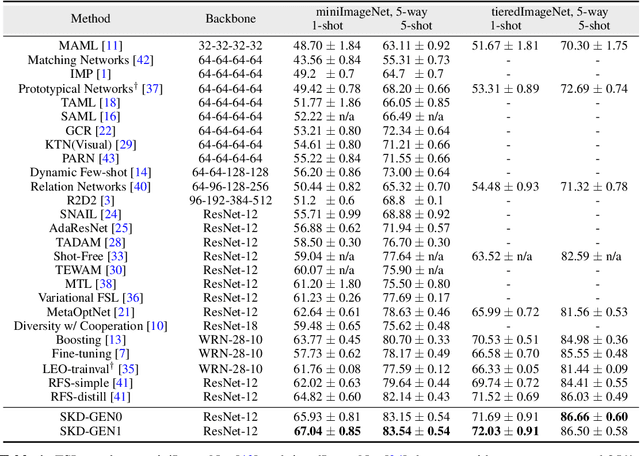
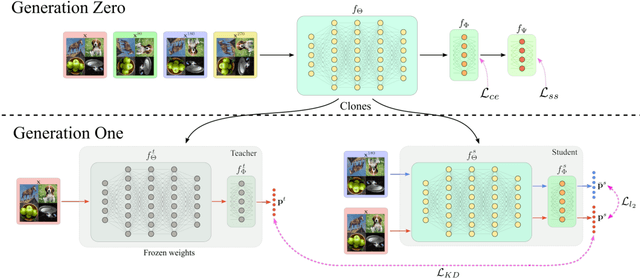
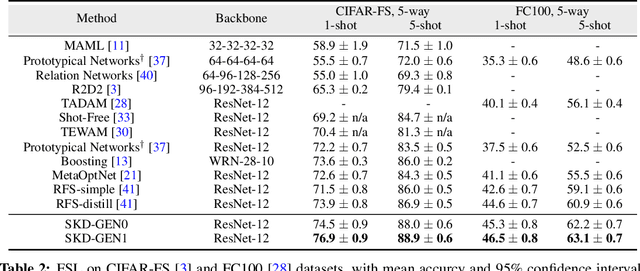
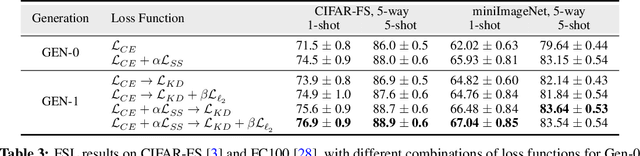
Real-world contains an overwhelmingly large number of object classes, learning all of which at once is infeasible. Few shot learning is a promising learning paradigm due to its ability to learn out of order distributions quickly with only a few samples. Recent works [7, 41] show that simply learning a good feature embedding can outperform more sophisticated meta-learning and metric learning algorithms for few-shot learning. In this paper, we propose a simple approach to improve the representation capacity of deep neural networks for few-shot learning tasks. We follow a two-stage learning process: First, we train a neural network to maximize the entropy of the feature embedding, thus creating an optimal output manifold using a self-supervised auxiliary loss. In the second stage, we minimize the entropy on feature embedding by bringing self-supervised twins together, while constraining the manifold with student-teacher distillation. Our experiments show that, even in the first stage, self-supervision can outperform current state-of-the-art methods, with further gains achieved by our second stage distillation process. Our codes are available at: https://github.com/brjathu/SKD.
A Self-supervised Approach for Adversarial Robustness
Jun 08, 2020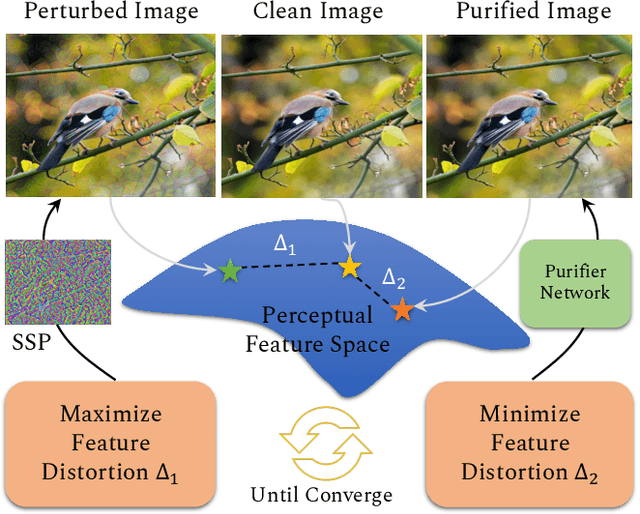
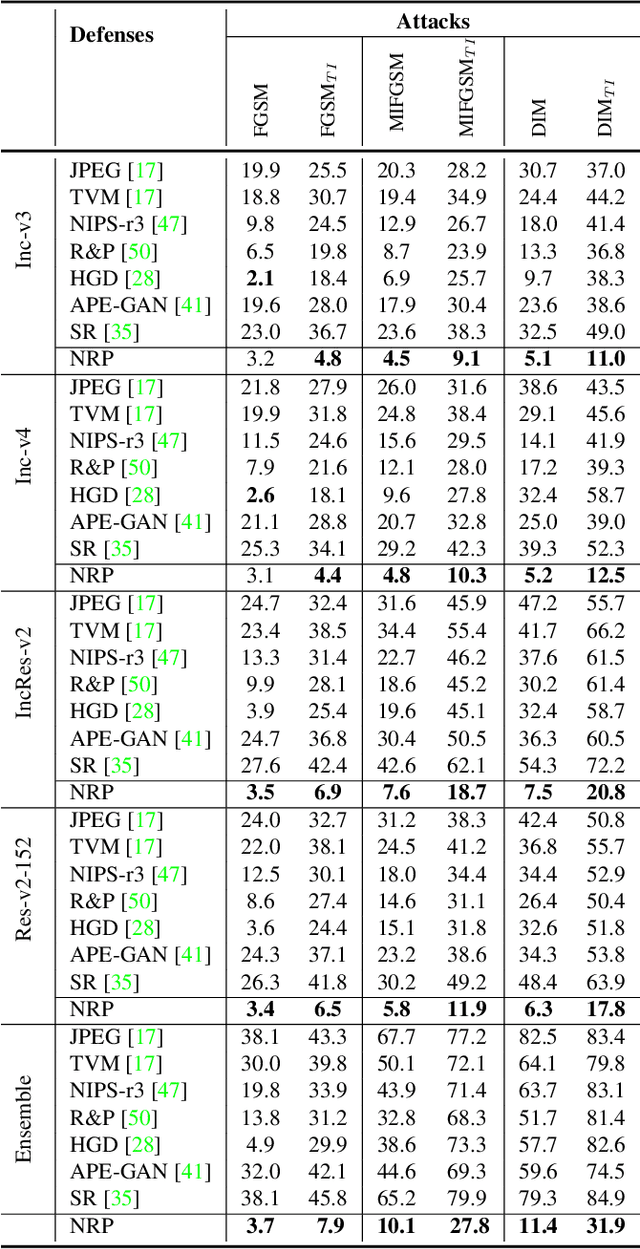
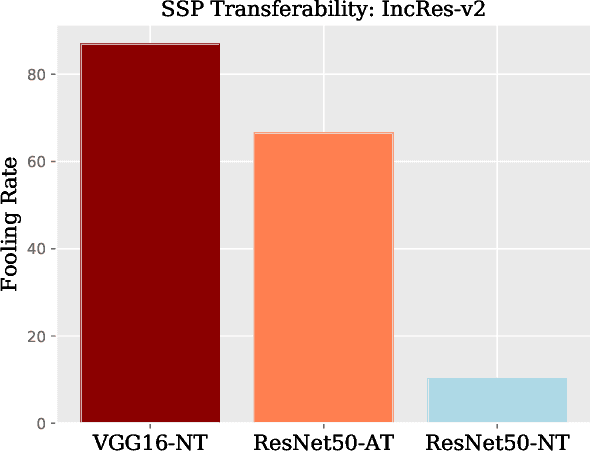
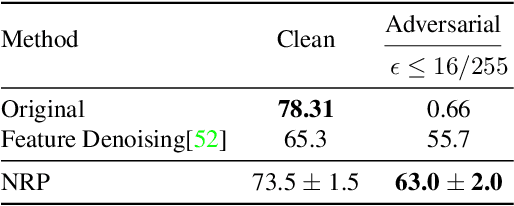
Adversarial examples can cause catastrophic mistakes in Deep Neural Network (DNNs) based vision systems e.g., for classification, segmentation and object detection. The vulnerability of DNNs against such attacks can prove a major roadblock towards their real-world deployment. Transferability of adversarial examples demand generalizable defenses that can provide cross-task protection. Adversarial training that enhances robustness by modifying target model's parameters lacks such generalizability. On the other hand, different input processing based defenses fall short in the face of continuously evolving attacks. In this paper, we take the first step to combine the benefits of both approaches and propose a self-supervised adversarial training mechanism in the input space. By design, our defense is a generalizable approach and provides significant robustness against the \textbf{unseen} adversarial attacks (\eg by reducing the success rate of translation-invariant \textbf{ensemble} attack from 82.6\% to 31.9\% in comparison to previous state-of-the-art). It can be deployed as a plug-and-play solution to protect a variety of vision systems, as we demonstrate for the case of classification, segmentation and detection. Code is available at: {\small\url{https://github.com/Muzammal-Naseer/NRP}}.
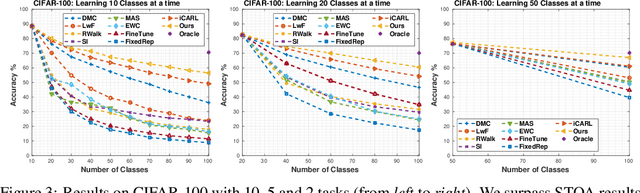
iTAML: An Incremental Task-Agnostic Meta-learning Approach
Mar 25, 2020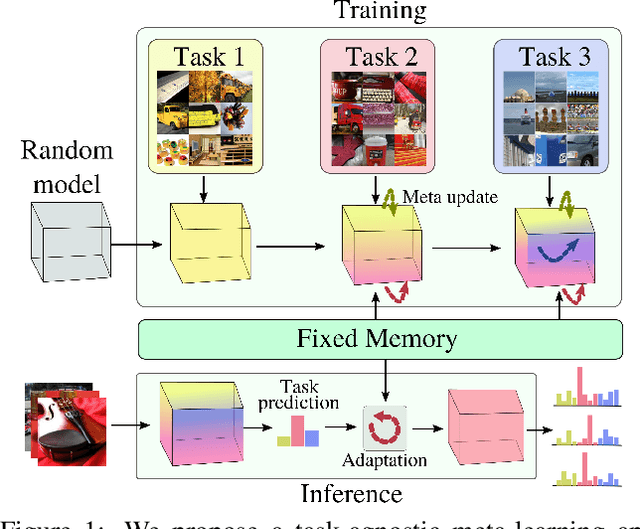
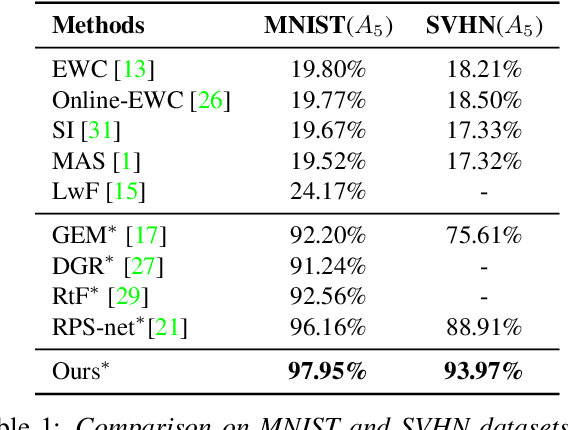
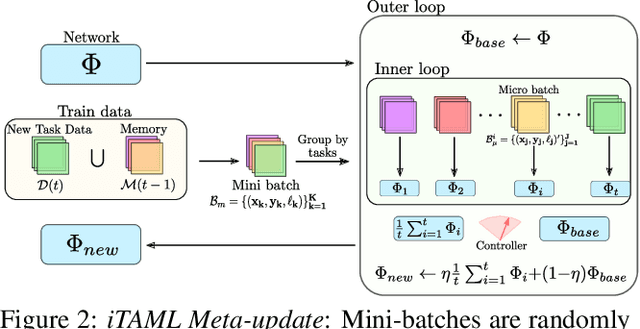
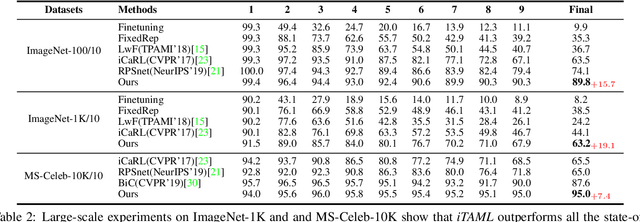
Humans can continuously learn new knowledge as their experience grows. In contrast, previous learning in deep neural networks can quickly fade out when they are trained on a new task. In this paper, we hypothesize this problem can be avoided by learning a set of generalized parameters, that are neither specific to old nor new tasks. In this pursuit, we introduce a novel meta-learning approach that seeks to maintain an equilibrium between all the encountered tasks. This is ensured by a new meta-update rule which avoids catastrophic forgetting. In comparison to previous meta-learning techniques, our approach is task-agnostic. When presented with a continuum of data, our model automatically identifies the task and quickly adapts to it with just a single update. We perform extensive experiments on five datasets in a class-incremental setting, leading to significant improvements over the state of the art methods (e.g., a 21.3% boost on CIFAR100 with 10 incremental tasks). Specifically, on large-scale datasets that generally prove difficult cases for incremental learning, our approach delivers absolute gains as high as 19.1% and 7.4% on ImageNet and MS-Celeb datasets, respectively.
CycleISP: Real Image Restoration via Improved Data Synthesis
Mar 17, 2020
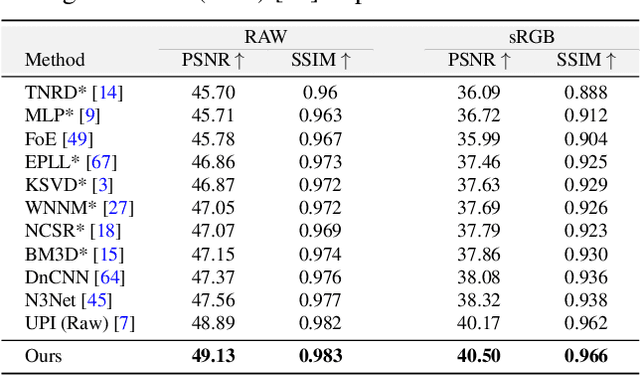
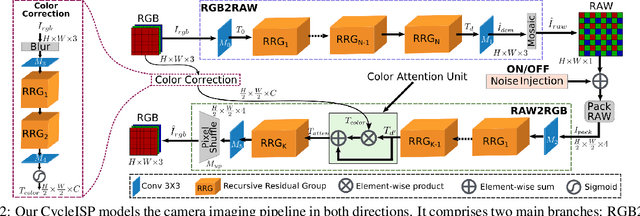
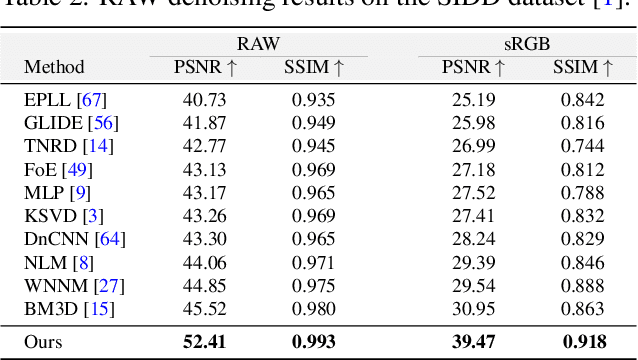
The availability of large-scale datasets has helped unleash the true potential of deep convolutional neural networks (CNNs). However, for the single-image denoising problem, capturing a real dataset is an unacceptably expensive and cumbersome procedure. Consequently, image denoising algorithms are mostly developed and evaluated on synthetic data that is usually generated with a widespread assumption of additive white Gaussian noise (AWGN). While the CNNs achieve impressive results on these synthetic datasets, they do not perform well when applied on real camera images, as reported in recent benchmark datasets. This is mainly because the AWGN is not adequate for modeling the real camera noise which is signal-dependent and heavily transformed by the camera imaging pipeline. In this paper, we present a framework that models camera imaging pipeline in forward and reverse directions. It allows us to produce any number of realistic image pairs for denoising both in RAW and sRGB spaces. By training a new image denoising network on realistic synthetic data, we achieve the state-of-the-art performance on real camera benchmark datasets. The parameters in our model are ~5 times lesser than the previous best method for RAW denoising. Furthermore, we demonstrate that the proposed framework generalizes beyond image denoising problem e.g., for color matching in stereoscopic cinema. The source code and pre-trained models are available at https://github.com/swz30/CycleISP.
Learning Enriched Features for Real Image Restoration and Enhancement
Mar 15, 2020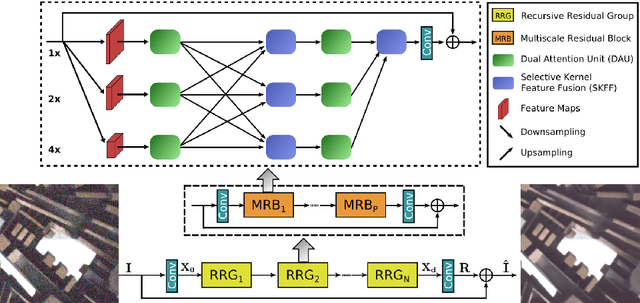

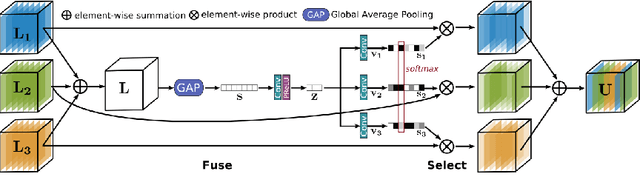
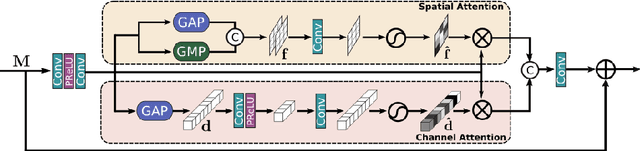
With the goal of recovering high-quality image content from its degraded version, image restoration enjoys numerous applications, such as in surveillance, computational photography, medical imaging, and remote sensing. Recently, convolutional neural networks (CNNs) have achieved dramatic improvements over conventional approaches for image restoration task. Existing CNN-based methods typically operate either on full-resolution or on progressively low-resolution representations. In the former case, spatially precise but contextually less robust results are achieved, while in the latter case, semantically reliable but spatially less accurate outputs are generated. In this paper, we present a novel architecture with the collective goals of maintaining spatially-precise high-resolution representations through the entire network, and receiving strong contextual information from the low-resolution representations. The core of our approach is a multi-scale residual block containing several key elements: (a) parallel multi-resolution convolution streams for extracting multi-scale features, (b) information exchange across the multi-resolution streams, (c) spatial and channel attention mechanisms for capturing contextual information, and (d) attention based multi-scale feature aggregation. In the nutshell, our approach learns an enriched set of features that combines contextual information from multiple scales, while simultaneously preserving the high-resolution spatial details. Extensive experiments on five real image benchmark datasets demonstrate that our method, named as MIRNet, achieves state-of-the-art results for a variety of image processing tasks, including image denoising, super-resolution and image enhancement.
Towards Robust and Reproducible Active Learning Using Neural Networks
Feb 21, 2020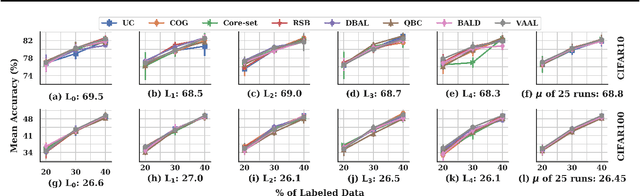
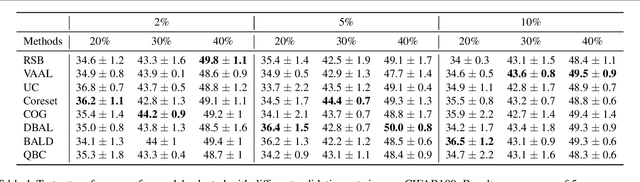
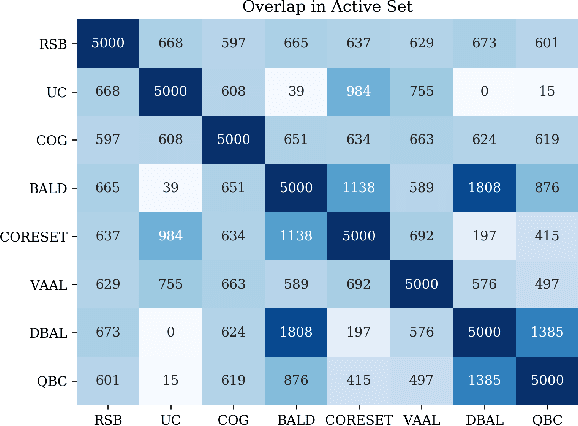
Active learning (AL) is a promising ML paradigm that has the potential to parse through large unlabeled data and help reduce annotation cost in domains where labeling entire data can be prohibitive. Recently proposed neural network based AL methods use different heuristics to accomplish this goal. In this study, we show that recent AL methods offer a gain over random baseline under a brittle combination of experimental conditions. We demonstrate that such marginal gains vanish when experimental factors are changed, leading to reproducibility issues and suggesting that AL methods lack robustness. We also observe that with a properly tuned model, which employs recently proposed regularization techniques, the performance significantly improves for all AL methods including the random sampling baseline, and performance differences among the AL methods become negligible. Based on these observations, we suggest a set of experiments that are critical to assess the true effectiveness of an AL method. To facilitate these experiments we also present an open source toolkit. We believe our findings and recommendations will help advance reproducible research in robust AL using neural networks.
Unsupervised Primitive Discovery for Improved 3D Generative Modeling
Jun 09, 2019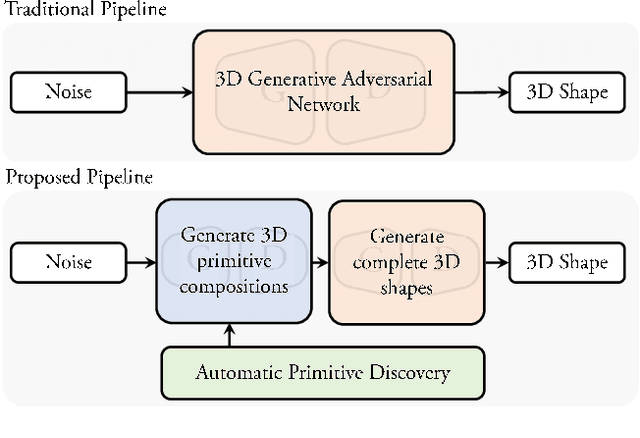
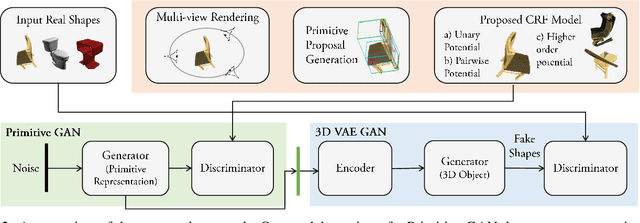
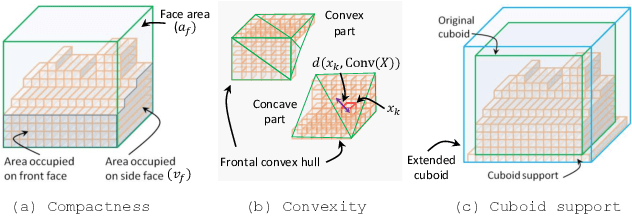
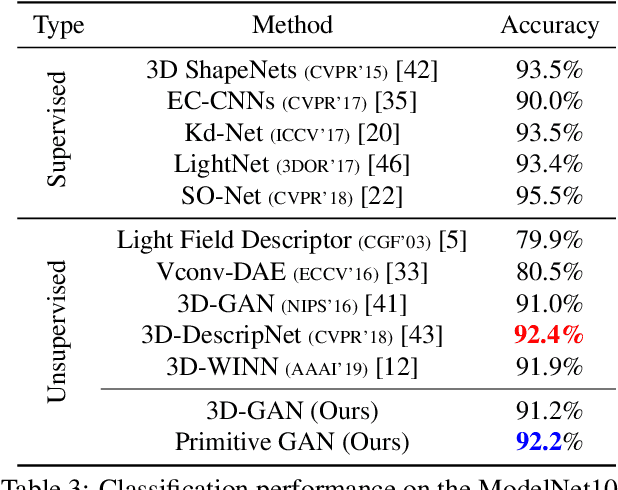
3D shape generation is a challenging problem due to the high-dimensional output space and complex part configurations of real-world objects. As a result, existing algorithms experience difficulties in accurate generative modeling of 3D shapes. Here, we propose a novel factorized generative model for 3D shape generation that sequentially transitions from coarse to fine scale shape generation. To this end, we introduce an unsupervised primitive discovery algorithm based on a higher-order conditional random field model. Using the primitive parts for shapes as attributes, a parameterized 3D representation is modeled in the first stage. This representation is further refined in the next stage by adding fine scale details to shape. Our results demonstrate improved representation ability of the generative model and better quality samples of newly generated 3D shapes. Further, our primitive generation approach can accurately parse common objects into a simplified representation.
Random Path Selection for Incremental Learning
Jun 03, 2019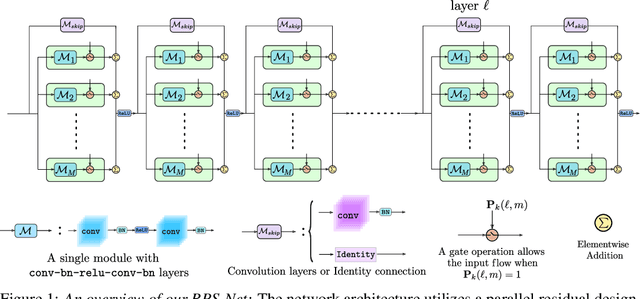
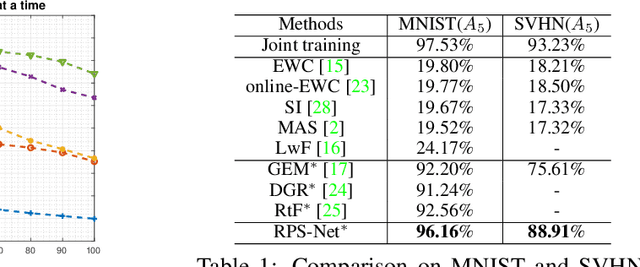
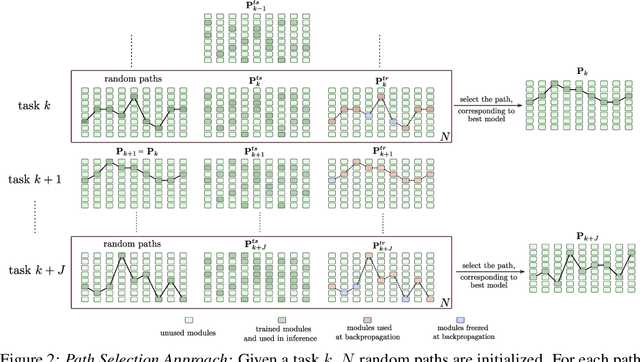
Incremental life-long learning is a main challenge towards the long-standing goal of Artificial General Intelligence. In real-life settings, learning tasks arrive in a sequence and machine learning models must continually learn to increment already acquired knowledge. Existing incremental learning approaches, fall well below the state-of-the-art cumulative models that use all training classes at once. In this paper, we propose a random path selection algorithm, called RPSnet, that progressively chooses optimal paths for the new tasks while encouraging parameter sharing and reuse. Our approach avoids the overhead introduced by computationally expensive evolutionary and reinforcement learning based path selection strategies while achieving considerable performance gains. As an added novelty, the proposed model integrates knowledge distillation and retrospection along with the path selection strategy to overcome catastrophic forgetting. In order to maintain an equilibrium between previous and newly acquired knowledge, we propose a simple controller to dynamically balance the model plasticity. Through extensive experiments, we demonstrate that the proposed method surpasses the state-of-the-art performance on incremental learning and by utilizing parallel computation this method can run in constant time with nearly the same efficiency as a conventional deep convolutional neural network.
Learned 3D Shape Representations Using Fused Geometrically Augmented Images: Application to Facial Expression and Action Unit Detection
Apr 08, 2019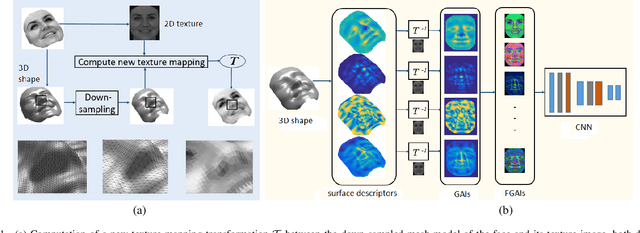

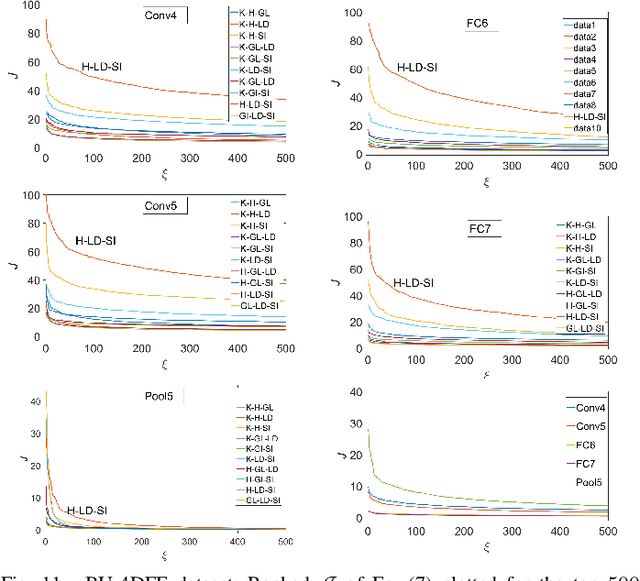
This paper proposes an approach to learn generic multi-modal mesh surface representations using a novel scheme for fusing texture and geometric data. Our approach defines an inverse mapping between different geometric descriptors computed on the mesh surface or its down-sampled version, and the corresponding 2D texture image of the mesh, allowing the construction of fused geometrically augmented images (FGAI). This new fused modality enables us to learn feature representations from 3D data in a highly efficient manner by simply employing standard convolutional neural networks in a transfer-learning mode. In contrast to existing methods, the proposed approach is both computationally and memory efficient, preserves intrinsic geometric information and learns highly discriminative feature representation by effectively fusing shape and texture information at data level. The efficacy of our approach is demonstrated for the tasks of facial action unit detection and expression classification. The extensive experiments conducted on the Bosphorus and BU-4DFE datasets, show that our method produces a significant boost in the performance when compared to state-of-the-art solutions