 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQRA 2026: Interspeech Challenge on Automatic Assessment Pronunciation for Modern Standard Arabic (MSA)
Mar 31, 2026We present the findings of the second edition of the IQRA Interspeech Challenge, a challenge on automatic Mispronunciation Detection and Diagnosis (MDD) for Modern Standard Arabic (MSA). Building on the previous edition, this iteration introduces \textbf{Iqra\_Extra\_IS26}, a new dataset of authentic human mispronounced speech, complementing the existing training and evaluation resources. Submitted systems employed a diverse range of approaches, spanning CTC-based self-supervised learning models, two-stage fine-tuning strategies, and using large audio-language models. Compared to the first edition, we observe a substantial jump of \textbf{0.28 in F1-score}, attributable both to novel architectures and modeling strategies proposed by participants and to the additional authentic mispronunciation data made available. These results demonstrate the growing maturity of Arabic MDD research and establish a stronger foundation for future work in Arabic pronunciation assessment.
Creating a Large Multi-Layered Representational Repository of Linguistic Code Switched Arabic Data
Sep 28, 2019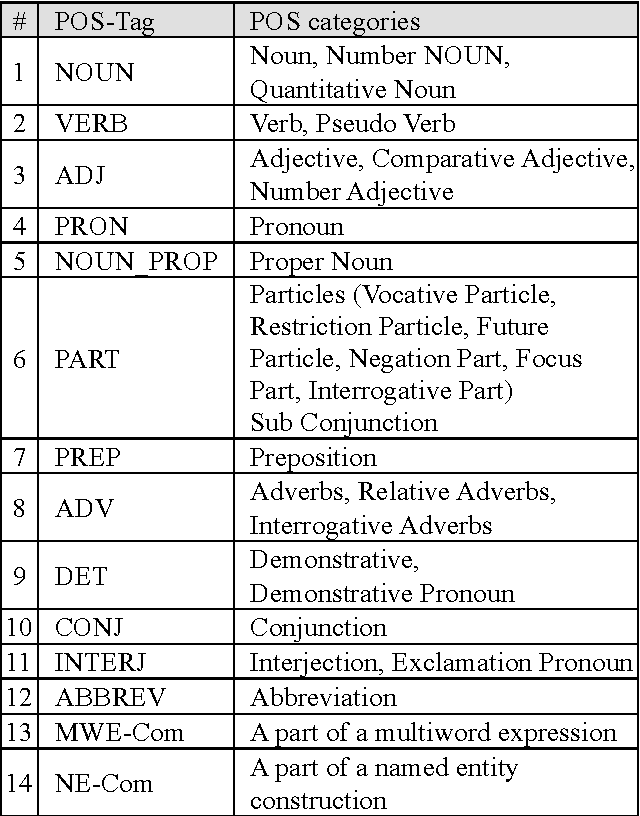
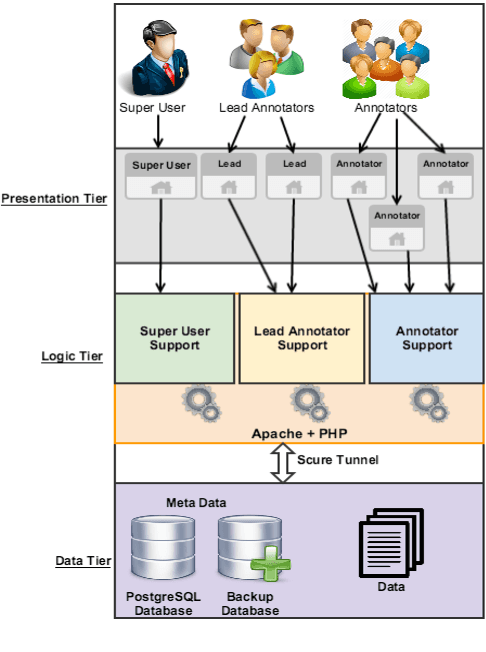
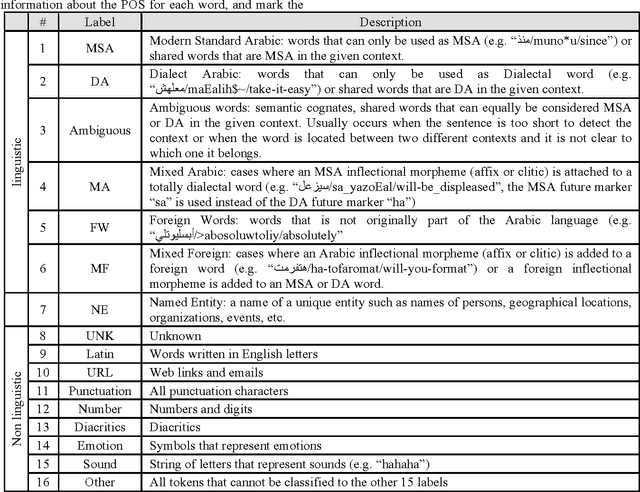
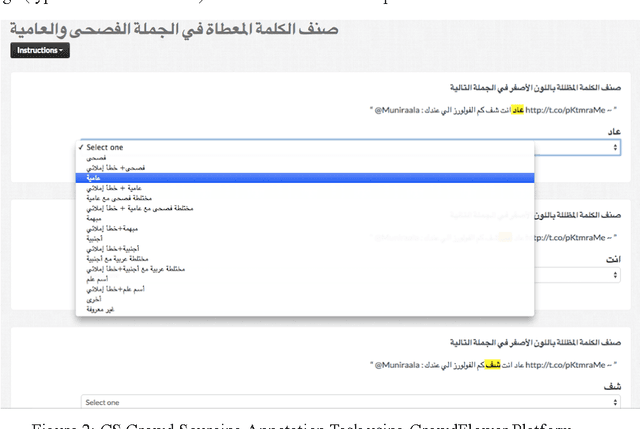
We present our effort to create a large Multi-Layered representational repository of Linguistic Code-Switched Arabic data. The process involves developing clear annotation standards and Guidelines, streamlining the annotation process, and implementing quality control measures. We used two main protocols for annotation: in-lab gold annotations and crowd sourcing annotations. We developed a web-based annotation tool to facilitate the management of the annotation process. The current version of the repository contains a total of 886,252 tokens that are tagged into one of sixteen code-switching tags. The data exhibits code switching between Modern Standard Arabic and Egyptian Dialectal Arabic representing three data genres: Tweets, commentaries, and discussion fora. The overall Inter-Annotator Agreement is 93.1%.