 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Unified Benchmark for Arabic Pronunciation Assessment: Quranic Recitation as Case Study
Jun 09, 2025



We present a unified benchmark for mispronunciation detection in Modern Standard Arabic (MSA) using Qur'anic recitation as a case study. Our approach lays the groundwork for advancing Arabic pronunciation assessment by providing a comprehensive pipeline that spans data processing, the development of a specialized phoneme set tailored to the nuances of MSA pronunciation, and the creation of the first publicly available test set for this task, which we term as the Qur'anic Mispronunciation Benchmark (QuranMB.v1). Furthermore, we evaluate several baseline models to provide initial performance insights, thereby highlighting both the promise and the challenges inherent in assessing MSA pronunciation. By establishing this standardized framework, we aim to foster further research and development in pronunciation assessment in Arabic language technology and related applications.
Improving Visual Question Answering Models through Robustness Analysis and In-Context Learning with a Chain of Basic Questions
Apr 06, 2023



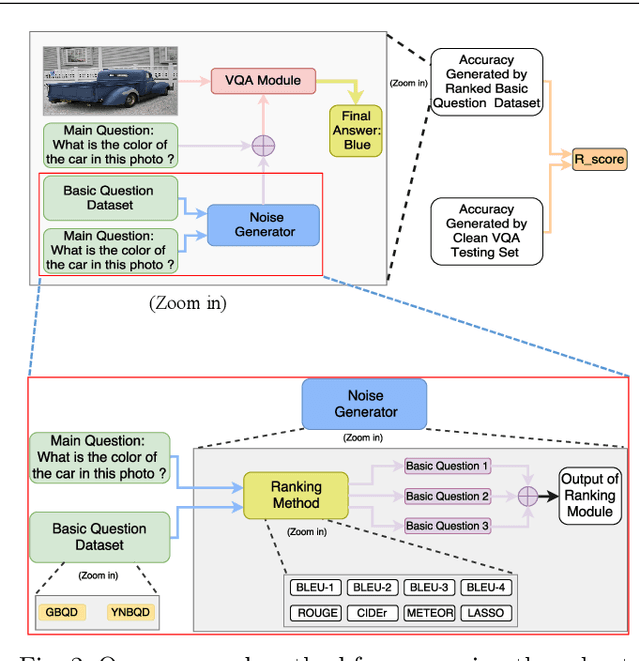
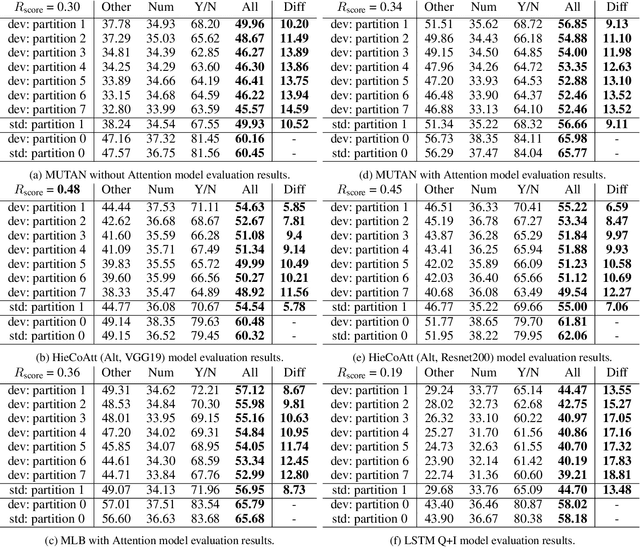
Deep neural networks have been critical in the task of Visual Question Answering (VQA), with research traditionally focused on improving model accuracy. Recently, however, there has been a trend towards evaluating the robustness of these models against adversarial attacks. This involves assessing the accuracy of VQA models under increasing levels of noise in the input, which can target either the image or the proposed query question, dubbed the main question. However, there is currently a lack of proper analysis of this aspect of VQA. This work proposes a new method that utilizes semantically related questions, referred to as basic questions, acting as noise to evaluate the robustness of VQA models. It is hypothesized that as the similarity of a basic question to the main question decreases, the level of noise increases. To generate a reasonable noise level for a given main question, a pool of basic questions is ranked based on their similarity to the main question, and this ranking problem is cast as a LASSO optimization problem. Additionally, this work proposes a novel robustness measure, R_score, and two basic question datasets to standardize the analysis of VQA model robustness. The experimental results demonstrate that the proposed evaluation method effectively analyzes the robustness of VQA models. Moreover, the experiments show that in-context learning with a chain of basic questions can enhance model accuracy.
Network Moments: Extensions and Sparse-Smooth Attacks
Jun 21, 2020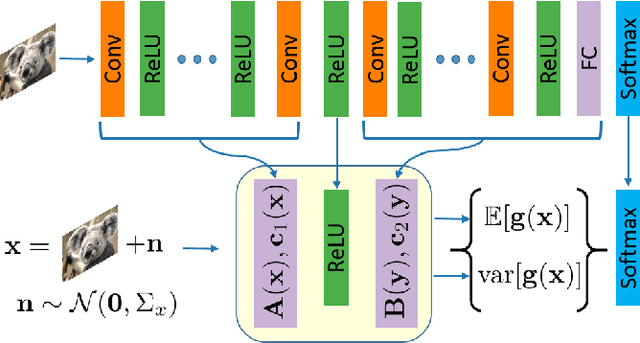
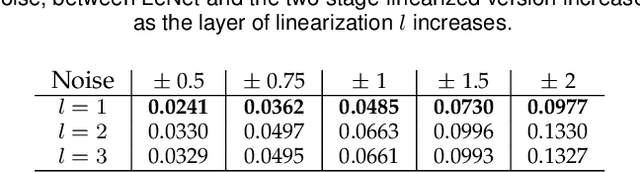
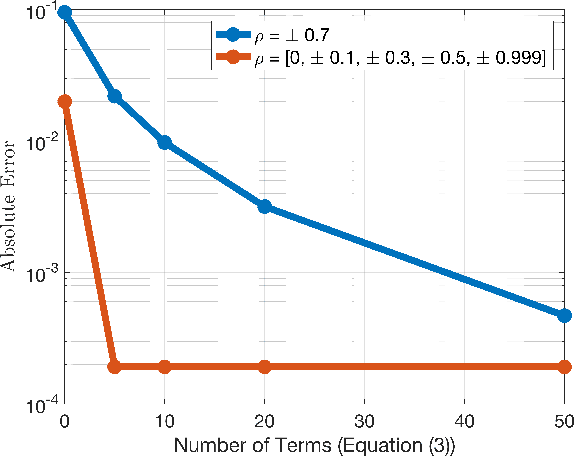
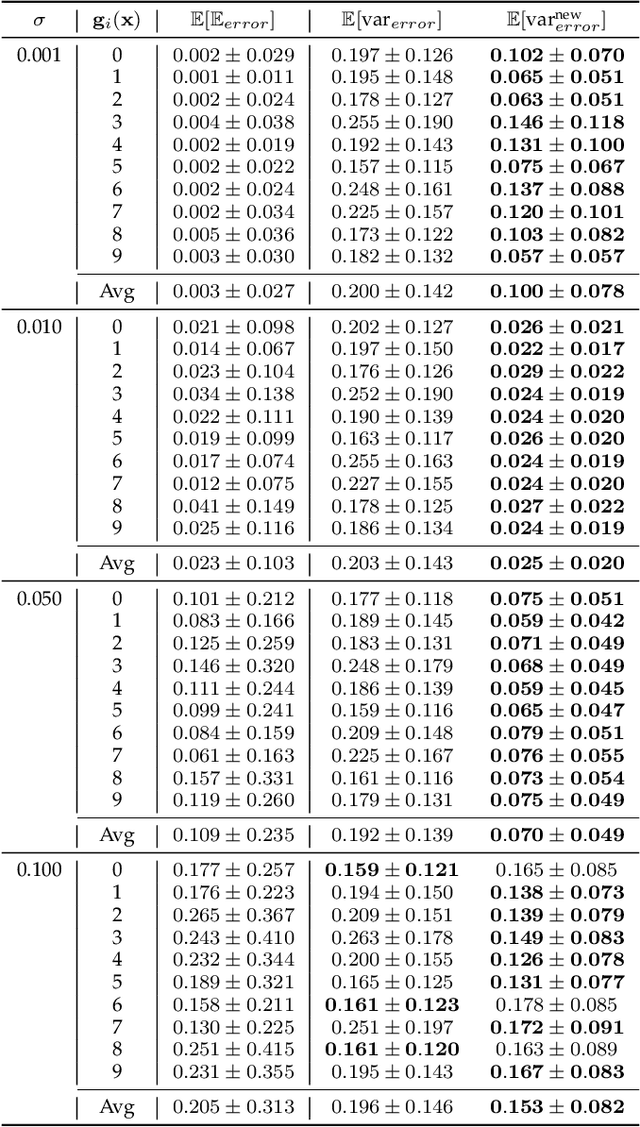
The impressive performance of deep neural networks (DNNs) has immensely strengthened the line of research that aims at theoretically analyzing their effectiveness. This has incited research on the reaction of DNNs to noisy input, namely developing adversarial input attacks and strategies that lead to robust DNNs to these attacks. To that end, in this paper, we derive exact analytic expressions for the first and second moments (mean and variance) of a small piecewise linear (PL) network (Affine, ReLU, Affine) subject to Gaussian input. In particular, we generalize the second-moment expression of Bibi et al. to arbitrary input Gaussian distributions, dropping the zero-mean assumption. We show that the new variance expression can be efficiently approximated leading to much tighter variance estimates as compared to the preliminary results of Bibi et al. Moreover, we experimentally show that these expressions are tight under simple linearizations of deeper PL-DNNs, where we investigate the effect of the linearization sensitivity on the accuracy of the moment estimates. Lastly, we show that the derived expressions can be used to construct sparse and smooth Gaussian adversarial attacks (targeted and non-targeted) that tend to lead to perceptually feasible input attacks.
Assessing the Robustness of Visual Question Answering
Nov 30, 2019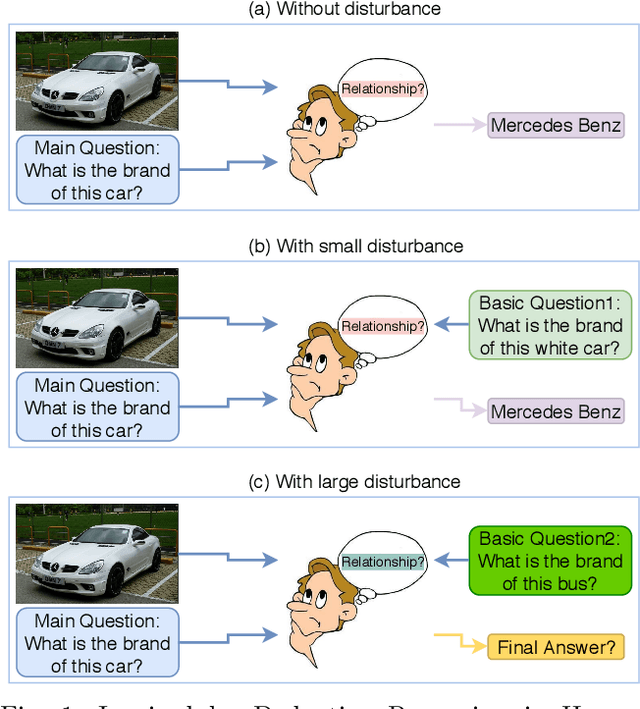
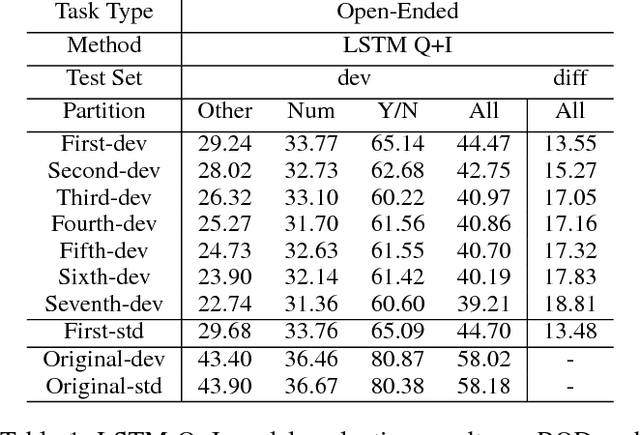
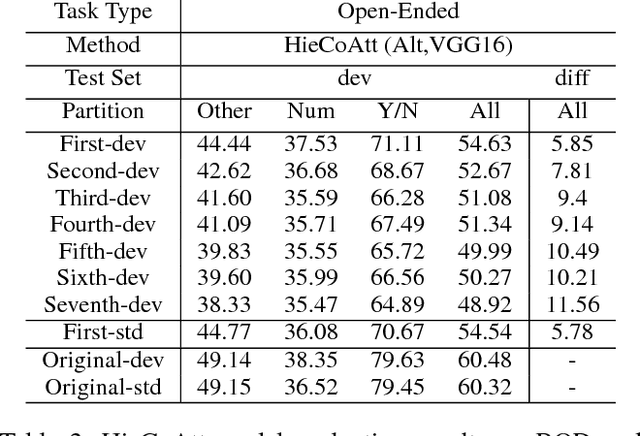
Deep neural networks have been playing an essential role in the task of Visual Question Answering (VQA). Until recently, their accuracy has been the main focus of research. Now there is a trend toward assessing the robustness of these models against adversarial attacks by evaluating the accuracy of these models under increasing levels of noisiness in the inputs of VQA models. In VQA, the attack can target the image and/or the proposed query question, dubbed main question, and yet there is a lack of proper analysis of this aspect of VQA. In this work, we propose a new method that uses semantically related questions, dubbed basic questions, acting as noise to evaluate the robustness of VQA models. We hypothesize that as the similarity of a basic question to the main question decreases, the level of noise increases. To generate a reasonable noise level for a given main question, we rank a pool of basic questions based on their similarity with this main question. We cast this ranking problem as a LASSO optimization problem. We also propose a novel robustness measure Rscore and two large-scale basic question datasets in order to standardize robustness analysis of VQA models. The experimental results demonstrate that the proposed evaluation method is able to effectively analyze the robustness of VQA models. To foster the VQA research, we will publish our proposed datasets.
Probabilistically True and Tight Bounds for Robust Deep Neural Network Training
May 28, 2019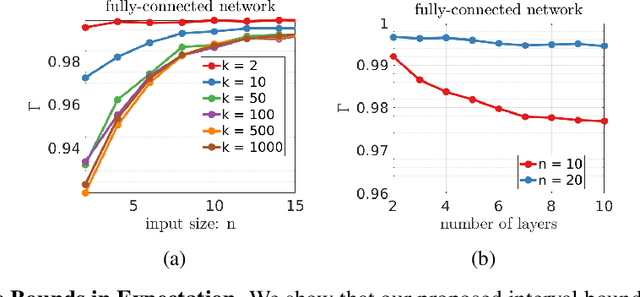
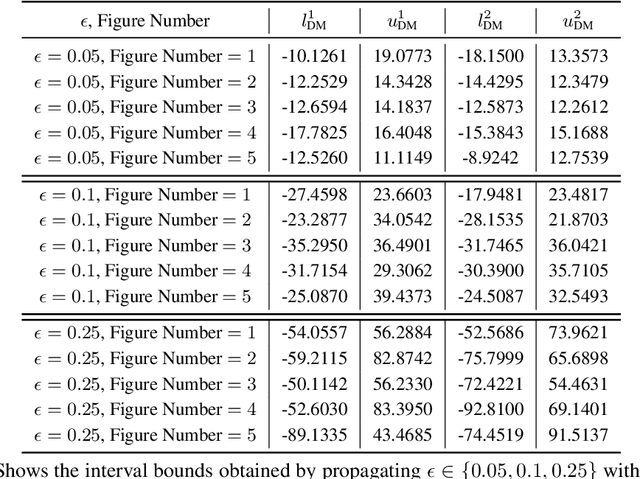
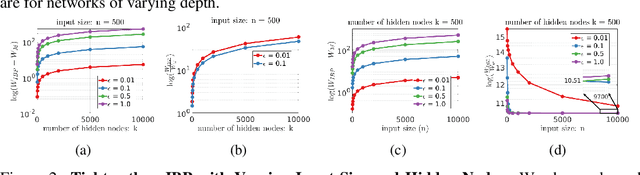
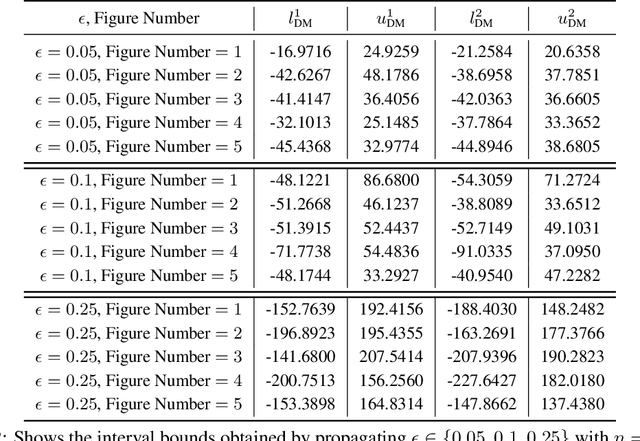
Training Deep Neural Networks (DNNs) that are robust to norm bounded adversarial attacks remains an elusive problem. While verification based methods are generally too expensive to robustly train large networks, it was demonstrated in Gowal et al. that bounded input intervals can be inexpensively propagated per layer through large networks. This interval bound propagation (IBP) approach lead to high robustness and was the first to be employed on large networks. However, due to the very loose nature of the IBP bounds, particularly for large networks, the required training procedure is complex and involved. In this paper, we closely examine the bounds of a block of layers composed of an affine layer followed by a ReLU nonlinearity followed by another affine layer. In doing so, we propose probabilistic bounds, true bounds with overwhelming probability, that are provably tighter than IBP bounds in expectation. We then extend this result to deeper networks through blockwise propagation and show that we can achieve orders of magnitudes tighter bounds compared to IBP. With such tight bounds, we demonstrate that a simple standard training procedure can achieve the best robustness-accuracy trade-off across several architectures on both MNIST and CIFAR10.
Analytical Moment Regularizer for Gaussian Robust Networks
Apr 24, 2019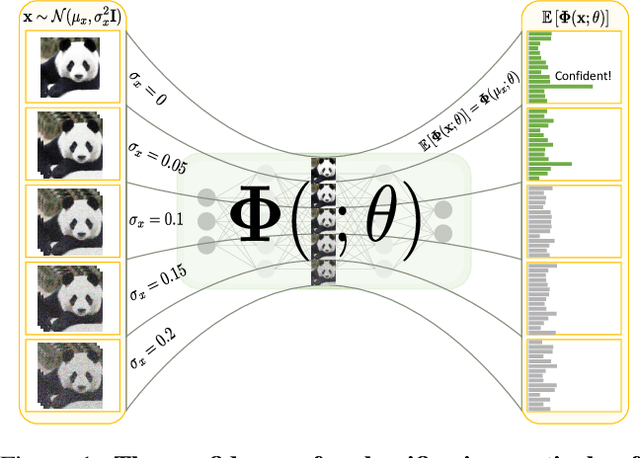
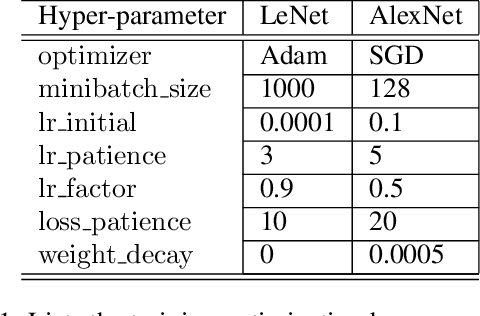
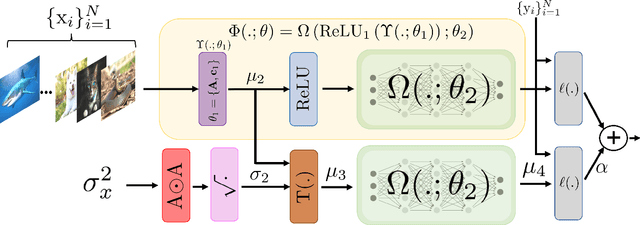
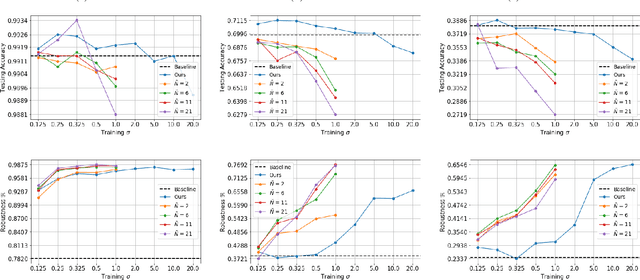
Despite the impressive performance of deep neural networks (DNNs) on numerous vision tasks, they still exhibit yet-to-understand uncouth behaviours. One puzzling behaviour is the subtle sensitive reaction of DNNs to various noise attacks. Such a nuisance has strengthened the line of research around developing and training noise-robust networks. In this work, we propose a new training regularizer that aims to minimize the probabilistic expected training loss of a DNN subject to a generic Gaussian input. We provide an efficient and simple approach to approximate such a regularizer for arbitrary deep networks. This is done by leveraging the analytic expression of the output mean of a shallow neural network; avoiding the need for the memory and computationally expensive data augmentation. We conduct extensive experiments on LeNet and AlexNet on various datasets including MNIST, CIFAR10, and CIFAR100 demonstrating the effectiveness of our proposed regularizer. In particular, we show that networks that are trained with the proposed regularizer benefit from a boost in robustness equivalent to performing 3-21 folds of data augmentation.
Robustness Analysis of Visual QA Models by Basic Questions
May 26, 2018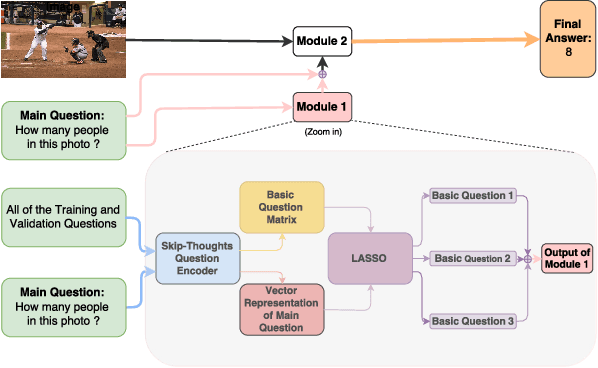
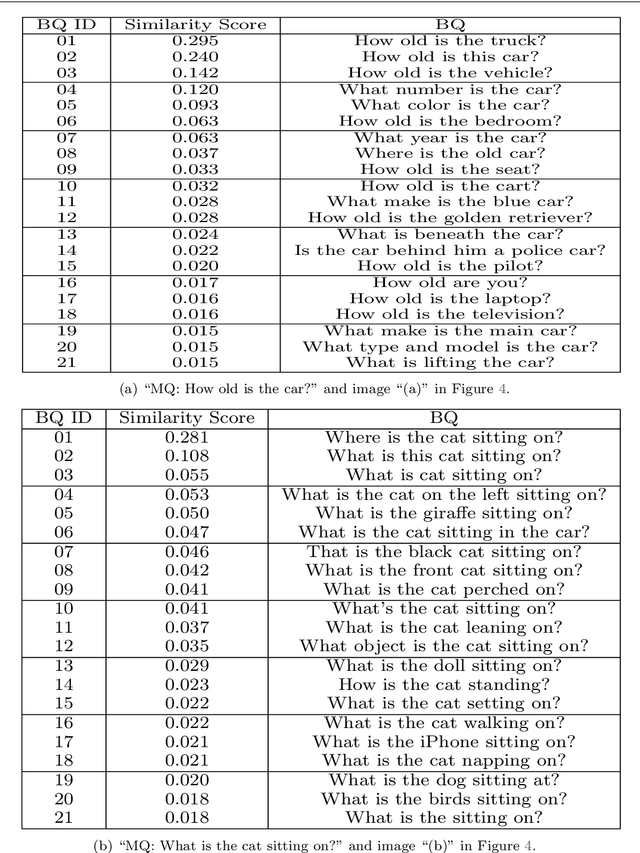
Visual Question Answering (VQA) models should have both high robustness and accuracy. Unfortunately, most of the current VQA research only focuses on accuracy because there is a lack of proper methods to measure the robustness of VQA models. There are two main modules in our algorithm. Given a natural language question about an image, the first module takes the question as input and then outputs the ranked basic questions, with similarity scores, of the main given question. The second module takes the main question, image and these basic questions as input and then outputs the text-based answer of the main question about the given image. We claim that a robust VQA model is one, whose performance is not changed much when related basic questions as also made available to it as input. We formulate the basic questions generation problem as a LASSO optimization, and also propose a large scale Basic Question Dataset (BQD) and Rscore (novel robustness measure), for analyzing the robustness of VQA models. We hope our BQD will be used as a benchmark for to evaluate the robustness of VQA models, so as to help the community build more robust and accurate VQA models.
A Novel Framework for Robustness Analysis of Visual QA Models
Nov 19, 2017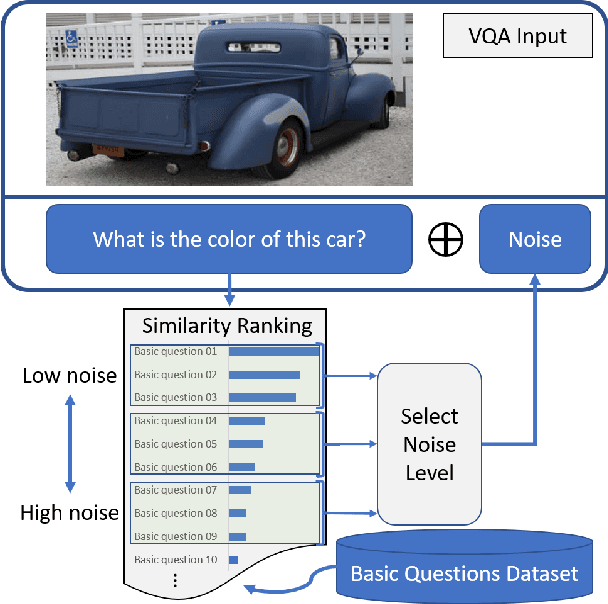
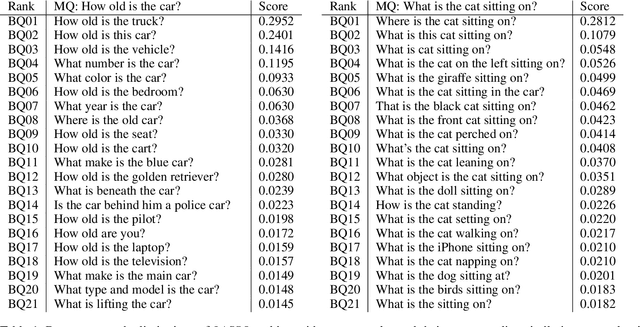
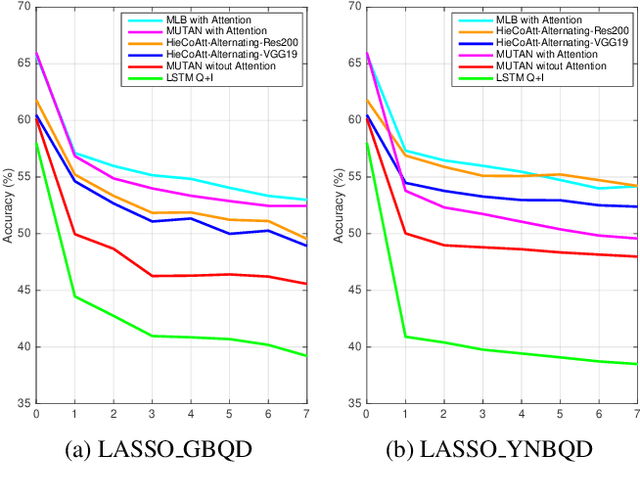
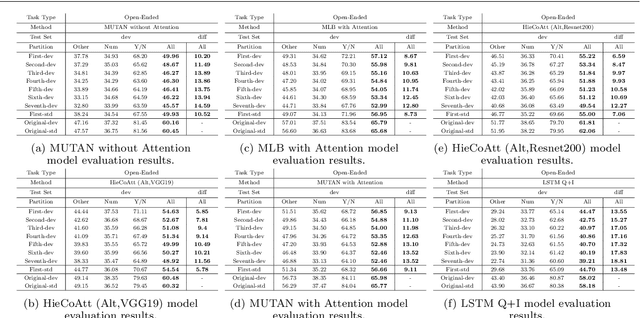
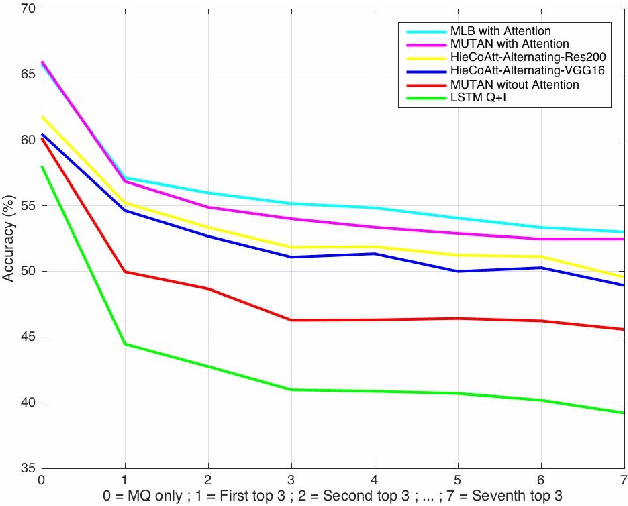
Deep neural networks have been playing an essential role in many computer vision tasks including Visual Question Answering (VQA). Until recently, the study of their accuracy has been the main focus of research and now there is a huge trend toward assessing the robustness of these models against adversarial attacks by evaluating the accuracy of these models under increasing levels of noisiness. In VQA, the attack can target the image and/or the proposed main question and yet there is a lack of proper analysis of this aspect of VQA. In this work, we propose a new framework that uses semantically relevant questions, dubbed basic questions, acting as noise to evaluate the robustness of VQA models. We hypothesize that as the similarity of a basic question to the main question decreases, the level of noise increases. So, to generate a reasonable noise level for a given main question, we rank a pool of basic questions based on their similarity with this main question. We cast this ranking problem as a LASSO optimization problem. We also propose a novel robustness measure R_score and two large-scale question datasets, General Basic Question Dataset and Yes/No Basic Question Dataset in order to standardize robustness analysis of VQA models. We analyze the robustness of several state-of-the-art VQA models and show that attention-based VQA models are more robust than other methods in general. The main goal of this framework is to serve as a benchmark to help the community in building more accurate and robust VQA models.
VQABQ: Visual Question Answering by Basic Questions
Aug 28, 2017

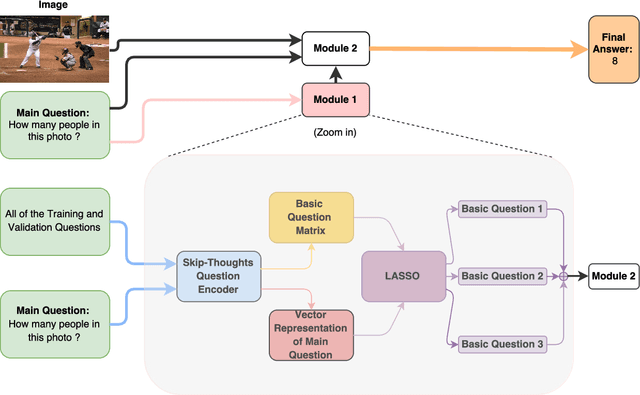
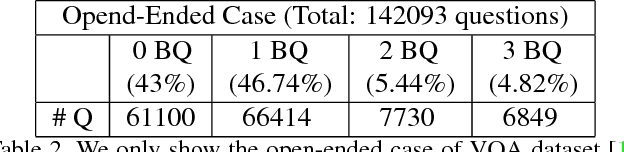
Taking an image and question as the input of our method, it can output the text-based answer of the query question about the given image, so called Visual Question Answering (VQA). There are two main modules in our algorithm. Given a natural language question about an image, the first module takes the question as input and then outputs the basic questions of the main given question. The second module takes the main question, image and these basic questions as input and then outputs the text-based answer of the main question. We formulate the basic questions generation problem as a LASSO optimization problem, and also propose a criterion about how to exploit these basic questions to help answer main question. Our method is evaluated on the challenging VQA dataset and yields state-of-the-art accuracy, 60.34% in open-ended task.