 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Recurrent Models Don't Need To Be Recurrent
May 29, 2018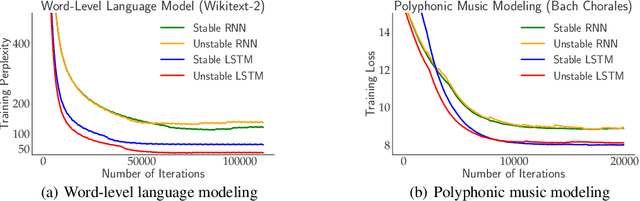
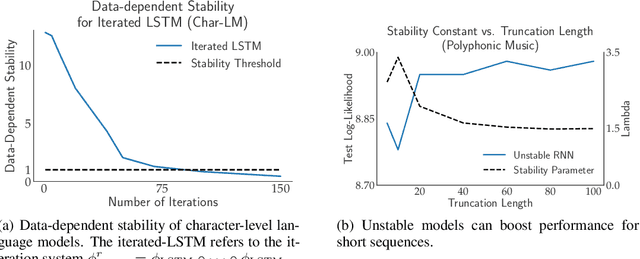
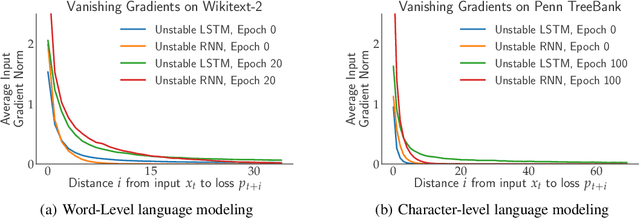
We prove stable recurrent neural networks are well approximated by feed-forward networks for the purpose of both inference and training by gradient descent. Our result applies to a broad range of non-linear recurrent neural networks under a natural stability condition, which we observe is also necessary. Complementing our theoretical findings, we verify the conclusions of our theory on both real and synthetic tasks. Furthermore, we demonstrate recurrent models satisfying the stability assumption of our theory can have excellent performance on real sequence learning tasks.
Delayed Impact of Fair Machine Learning
Apr 07, 2018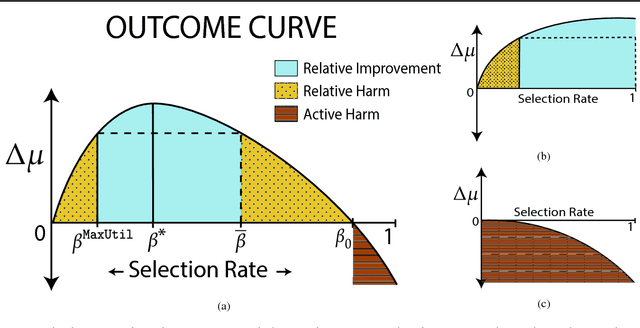
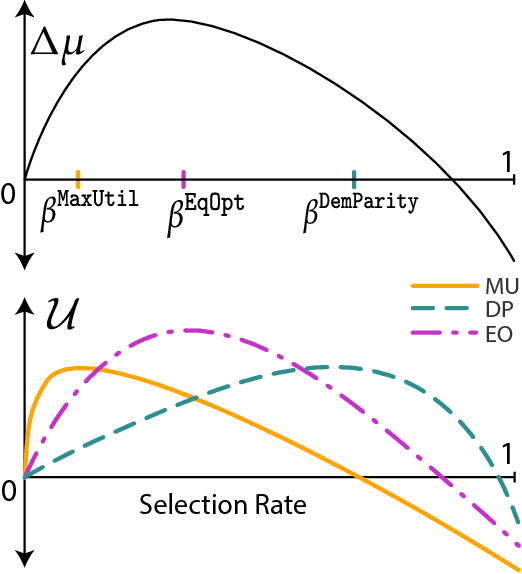
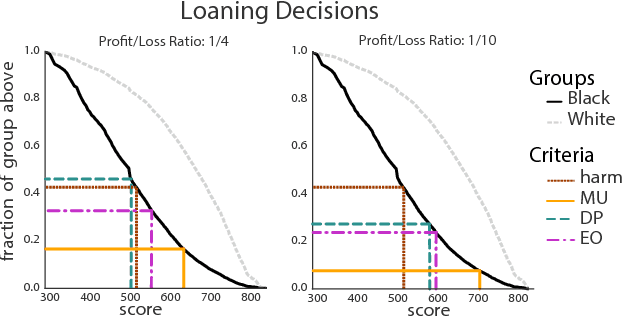
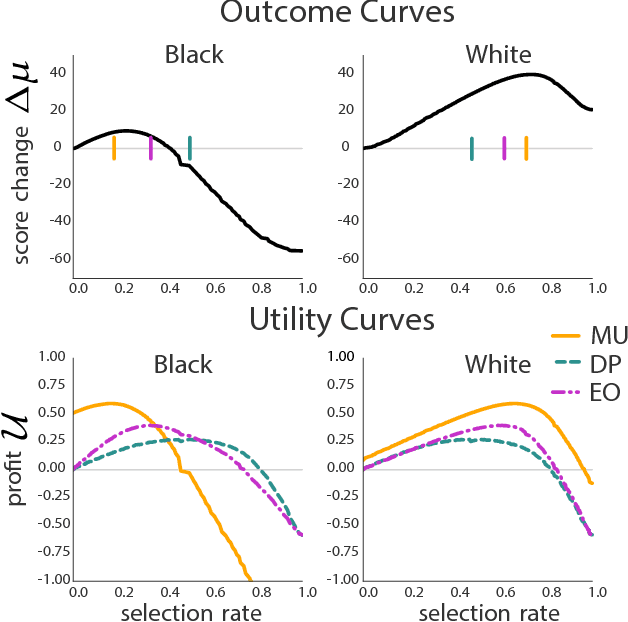
Fairness in machine learning has predominantly been studied in static classification settings without concern for how decisions change the underlying population over time. Conventional wisdom suggests that fairness criteria promote the long-term well-being of those groups they aim to protect. We study how static fairness criteria interact with temporal indicators of well-being, such as long-term improvement, stagnation, and decline in a variable of interest. We demonstrate that even in a one-step feedback model, common fairness criteria in general do not promote improvement over time, and may in fact cause harm in cases where an unconstrained objective would not. We completely characterize the delayed impact of three standard criteria, contrasting the regimes in which these exhibit qualitatively different behavior. In addition, we find that a natural form of measurement error broadens the regime in which fairness criteria perform favorably. Our results highlight the importance of measurement and temporal modeling in the evaluation of fairness criteria, suggesting a range of new challenges and trade-offs.
* 37 pages, 6 figures
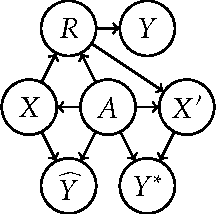
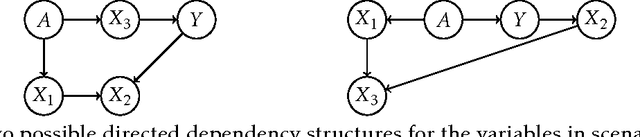
Avoiding Discrimination through Causal Reasoning
Jan 21, 2018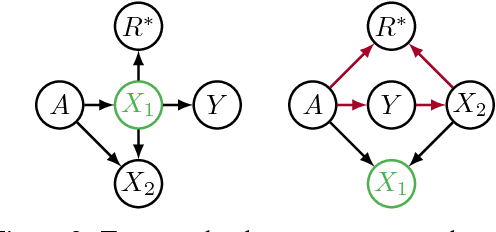
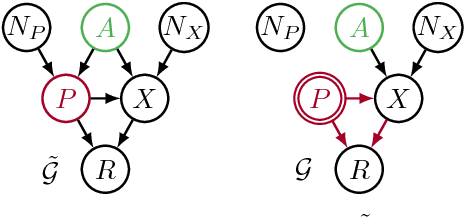
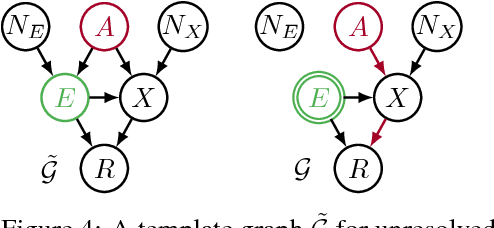

Recent work on fairness in machine learning has focused on various statistical discrimination criteria and how they trade off. Most of these criteria are observational: They depend only on the joint distribution of predictor, protected attribute, features, and outcome. While convenient to work with, observational criteria have severe inherent limitations that prevent them from resolving matters of fairness conclusively. Going beyond observational criteria, we frame the problem of discrimination based on protected attributes in the language of causal reasoning. This viewpoint shifts attention from "What is the right fairness criterion?" to "What do we want to assume about the causal data generating process?" Through the lens of causality, we make several contributions. First, we crisply articulate why and when observational criteria fail, thus formalizing what was before a matter of opinion. Second, our approach exposes previously ignored subtleties and why they are fundamental to the problem. Finally, we put forward natural causal non-discrimination criteria and develop algorithms that satisfy them.
* Advances in Neural Information Processing Systems 30, 2017 http://papers.nips.cc/paper/6668-avoiding-discrimination-through-causal-reasoning
Climbing a shaky ladder: Better adaptive risk estimation
Jun 08, 2017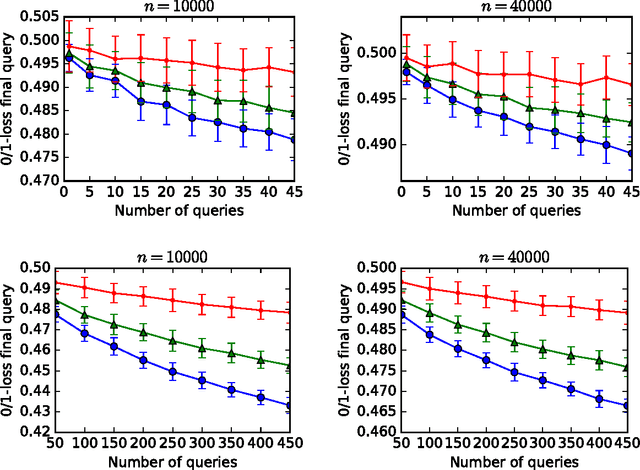
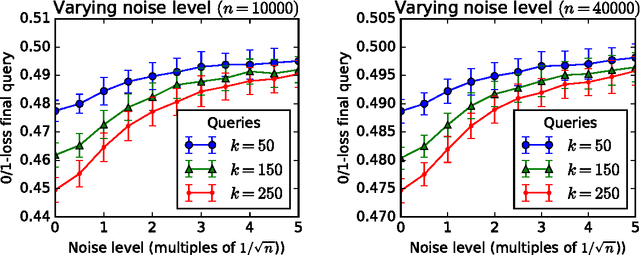
We revisit the \emph{leaderboard problem} introduced by Blum and Hardt (2015) in an effort to reduce overfitting in machine learning benchmarks. We show that a randomized version of their Ladder algorithm achieves leaderboard error O(1/n^{0.4}) compared with the previous best rate of O(1/n^{1/3}). Short of proving that our algorithm is optimal, we point out a major obstacle toward further progress. Specifically, any improvement to our upper bound would lead to asymptotic improvements in the general adaptive estimation setting as have remained elusive in recent years. This connection also directly leads to lower bounds for specific classes of algorithms. In particular, we exhibit a new attack on the leaderboard algorithm that both theoretically and empirically distinguishes between our algorithm and previous leaderboard algorithms.
Understanding deep learning requires rethinking generalization
Feb 26, 2017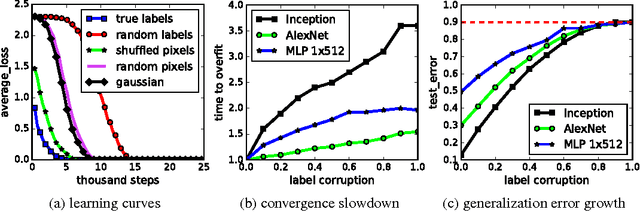
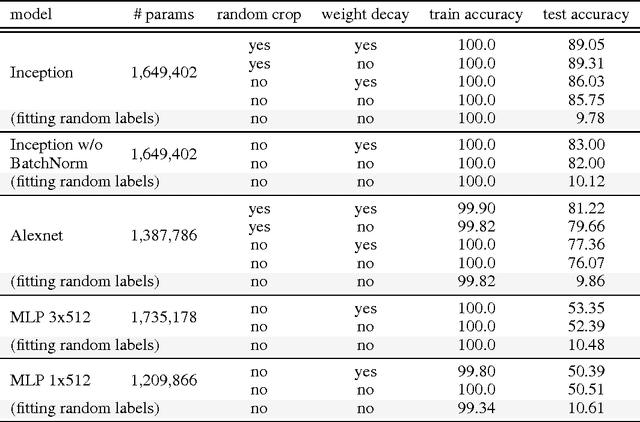
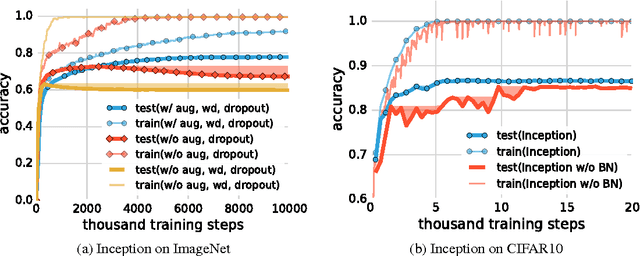
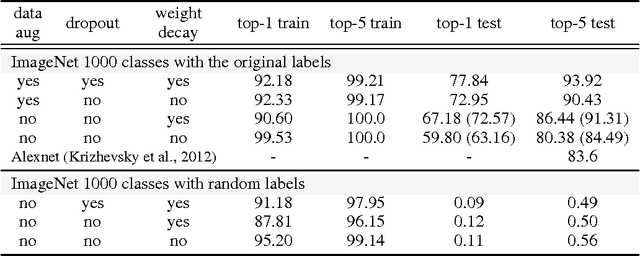
Despite their massive size, successful deep artificial neural networks can exhibit a remarkably small difference between training and test performance. Conventional wisdom attributes small generalization error either to properties of the model family, or to the regularization techniques used during training. Through extensive systematic experiments, we show how these traditional approaches fail to explain why large neural networks generalize well in practice. Specifically, our experiments establish that state-of-the-art convolutional networks for image classification trained with stochastic gradient methods easily fit a random labeling of the training data. This phenomenon is qualitatively unaffected by explicit regularization, and occurs even if we replace the true images by completely unstructured random noise. We corroborate these experimental findings with a theoretical construction showing that simple depth two neural networks already have perfect finite sample expressivity as soon as the number of parameters exceeds the number of data points as it usually does in practice. We interpret our experimental findings by comparison with traditional models.
Equality of Opportunity in Supervised Learning
Oct 07, 2016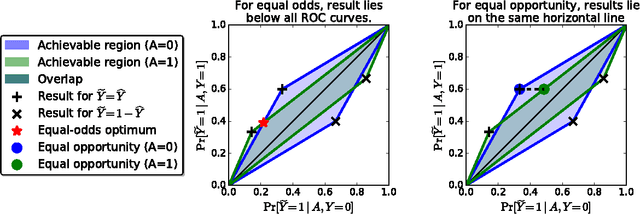
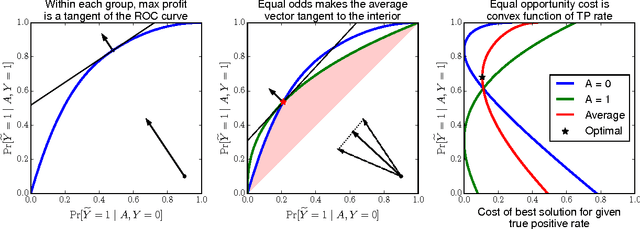
We propose a criterion for discrimination against a specified sensitive attribute in supervised learning, where the goal is to predict some target based on available features. Assuming data about the predictor, target, and membership in the protected group are available, we show how to optimally adjust any learned predictor so as to remove discrimination according to our definition. Our framework also improves incentives by shifting the cost of poor classification from disadvantaged groups to the decision maker, who can respond by improving the classification accuracy. In line with other studies, our notion is oblivious: it depends only on the joint statistics of the predictor, the target and the protected attribute, but not on interpretation of individualfeatures. We study the inherent limits of defining and identifying biases based on such oblivious measures, outlining what can and cannot be inferred from different oblivious tests. We illustrate our notion using a case study of FICO credit scores.
Gradient Descent Learns Linear Dynamical Systems
Sep 16, 2016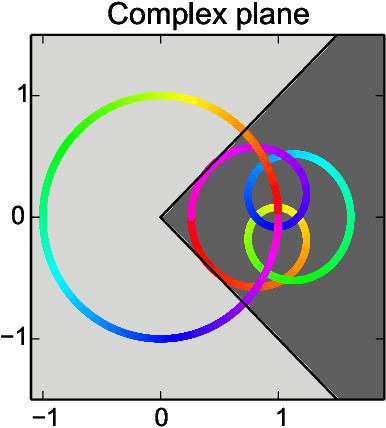
We prove that gradient descent efficiently converges to the global optimizer of the maximum likelihood objective of an unknown linear time-invariant dynamical system from a sequence of noisy observations generated by the system. Even though the objective function is non-convex, we provide polynomial running time and sample complexity bounds under strong but natural assumptions. Linear systems identification has been studied for many decades, yet, to the best of our knowledge, these are the first polynomial guarantees for the problem we consider.
Preserving Statistical Validity in Adaptive Data Analysis
Mar 02, 2016
A great deal of effort has been devoted to reducing the risk of spurious scientific discoveries, from the use of sophisticated validation techniques, to deep statistical methods for controlling the false discovery rate in multiple hypothesis testing. However, there is a fundamental disconnect between the theoretical results and the practice of data analysis: the theory of statistical inference assumes a fixed collection of hypotheses to be tested, or learning algorithms to be applied, selected non-adaptively before the data are gathered, whereas in practice data is shared and reused with hypotheses and new analyses being generated on the basis of data exploration and the outcomes of previous analyses. In this work we initiate a principled study of how to guarantee the validity of statistical inference in adaptive data analysis. As an instance of this problem, we propose and investigate the question of estimating the expectations of $m$ adaptively chosen functions on an unknown distribution given $n$ random samples. We show that, surprisingly, there is a way to estimate an exponential in $n$ number of expectations accurately even if the functions are chosen adaptively. This gives an exponential improvement over standard empirical estimators that are limited to a linear number of estimates. Our result follows from a general technique that counter-intuitively involves actively perturbing and coordinating the estimates, using techniques developed for privacy preservation. We give additional applications of this technique to our question.
Train faster, generalize better: Stability of stochastic gradient descent
Feb 07, 2016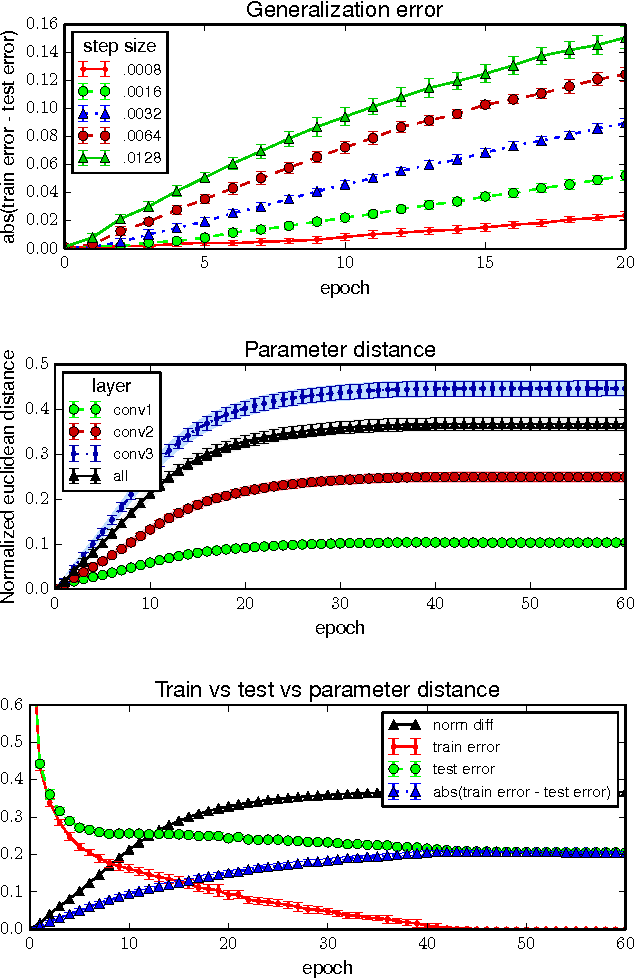
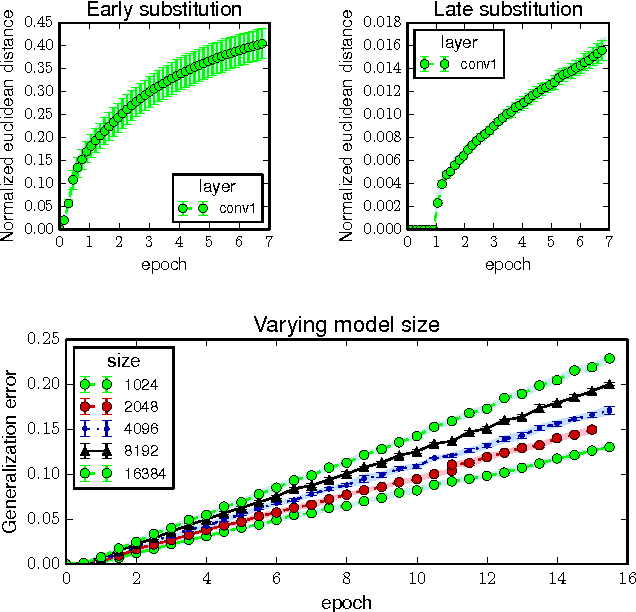
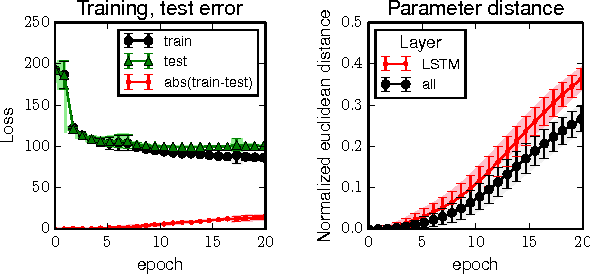
We show that parametric models trained by a stochastic gradient method (SGM) with few iterations have vanishing generalization error. We prove our results by arguing that SGM is algorithmically stable in the sense of Bousquet and Elisseeff. Our analysis only employs elementary tools from convex and continuous optimization. We derive stability bounds for both convex and non-convex optimization under standard Lipschitz and smoothness assumptions. Applying our results to the convex case, we provide new insights for why multiple epochs of stochastic gradient methods generalize well in practice. In the non-convex case, we give a new interpretation of common practices in neural networks, and formally show that popular techniques for training large deep models are indeed stability-promoting. Our findings conceptually underscore the importance of reducing training time beyond its obvious benefit.
Strategic Classification
Nov 22, 2015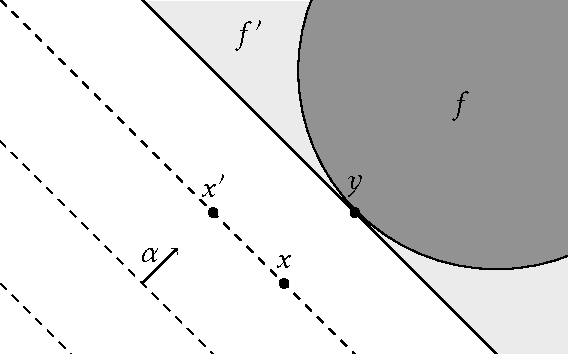
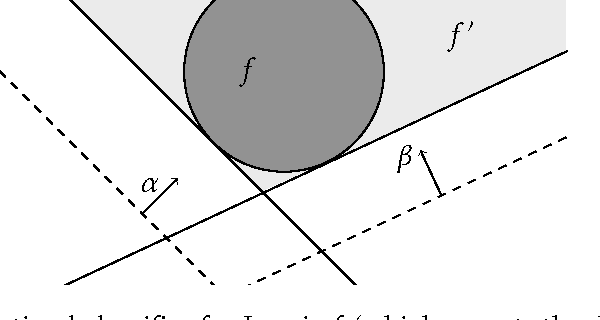
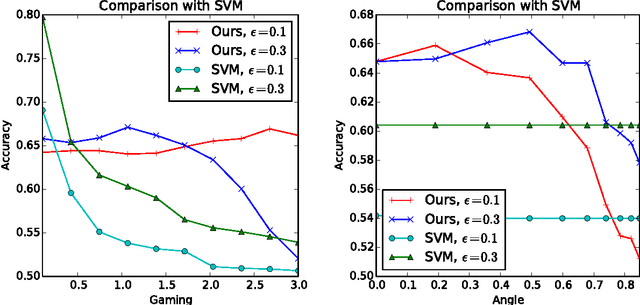
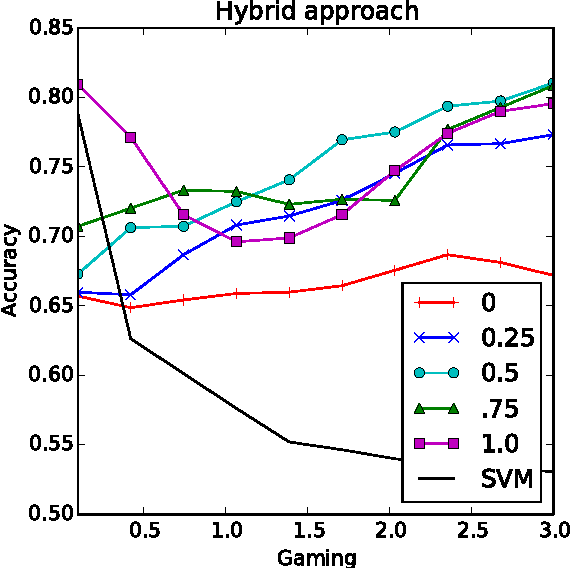
Machine learning relies on the assumption that unseen test instances of a classification problem follow the same distribution as observed training data. However, this principle can break down when machine learning is used to make important decisions about the welfare (employment, education, health) of strategic individuals. Knowing information about the classifier, such individuals may manipulate their attributes in order to obtain a better classification outcome. As a result of this behavior---often referred to as gaming---the performance of the classifier may deteriorate sharply. Indeed, gaming is a well-known obstacle for using machine learning methods in practice; in financial policy-making, the problem is widely known as Goodhart's law. In this paper, we formalize the problem, and pursue algorithms for learning classifiers that are robust to gaming. We model classification as a sequential game between a player named "Jury" and a player named "Contestant." Jury designs a classifier, and Contestant receives an input to the classifier, which he may change at some cost. Jury's goal is to achieve high classification accuracy with respect to Contestant's original input and some underlying target classification function. Contestant's goal is to achieve a favorable classification outcome while taking into account the cost of achieving it. For a natural class of cost functions, we obtain computationally efficient learning algorithms which are near-optimal. Surprisingly, our algorithms are efficient even on concept classes that are computationally hard to learn. For general cost functions, designing an approximately optimal strategy-proof classifier, for inverse-polynomial approximation, is NP-hard.