 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical and Reproducible Symbolic Music Generation by Large Language Models with Structural Embeddings
Jul 29, 2024



Music generation introduces challenging complexities to large language models. Symbolic structures of music often include vertical harmonization as well as horizontal counterpoint, urging various adaptations and enhancements for large-scale Transformers. However, existing works share three major drawbacks: 1) their tokenization requires domain-specific annotations, such as bars and beats, that are typically missing in raw MIDI data; 2) the pure impact of enhancing token embedding methods is hardly examined without domain-specific annotations; and 3) existing works to overcome the aforementioned drawbacks, such as MuseNet, lack reproducibility. To tackle such limitations, we develop a MIDI-based music generation framework inspired by MuseNet, empirically studying two structural embeddings that do not rely on domain-specific annotations. We provide various metrics and insights that can guide suitable encoding to deploy. We also verify that multiple embedding configurations can selectively boost certain musical aspects. By providing open-source implementations via HuggingFace, our findings shed light on leveraging large language models toward practical and reproducible music generation.
Learning to Explore and Select for Coverage-Conditioned Retrieval-Augmented Generation
Jul 01, 2024



Interactions with billion-scale large language models typically yield long-form responses due to their extensive parametric capacities, along with retrieval-augmented features. While detailed responses provide insightful viewpoint of a specific subject, they frequently generate redundant and less engaging content that does not meet user interests. In this work, we focus on the role of query outlining (i.e., selected sequence of queries) in scenarios that users request a specific range of information, namely coverage-conditioned ($C^2$) scenarios. For simulating $C^2$ scenarios, we construct QTree, 10K sets of information-seeking queries decomposed with various perspectives on certain topics. By utilizing QTree, we train QPlanner, a 7B language model generating customized query outlines that follow coverage-conditioned queries. We analyze the effectiveness of generated outlines through automatic and human evaluation, targeting on retrieval-augmented generation (RAG). Moreover, the experimental results demonstrate that QPlanner with alignment training can further provide outlines satisfying diverse user interests. Our resources are available at https://github.com/youngerous/qtree.
The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models
Jun 09, 2024



As language models (LMs) become capable of handling a wide range of tasks, their evaluation is becoming as challenging as their development. Most generation benchmarks currently assess LMs using abstract evaluation criteria like helpfulness and harmlessness, which often lack the flexibility and granularity of human assessment. Additionally, these benchmarks tend to focus disproportionately on specific capabilities such as instruction following, leading to coverage bias. To overcome these limitations, we introduce the BiGGen Bench, a principled generation benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, closely mirroring the nuanced discernment of human evaluation. We apply this benchmark to assess 103 frontier LMs using five evaluator LMs. Our code, data, and evaluation results are all publicly available at https://github.com/prometheus-eval/prometheus-eval/tree/main/BiGGen-Bench.
LG AI Research & KAIST at EHRSQL 2024: Self-Training Large Language Models with Pseudo-Labeled Unanswerable Questions for a Reliable Text-to-SQL System on EHRs
May 18, 2024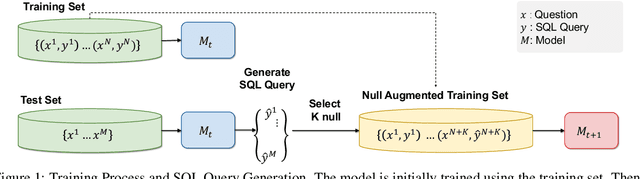
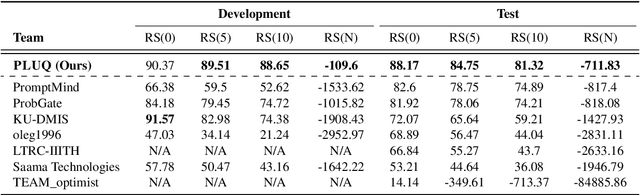
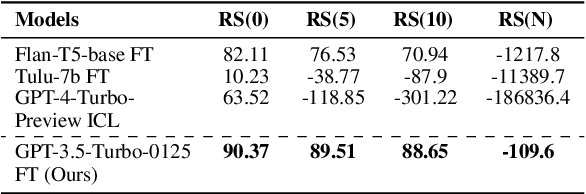
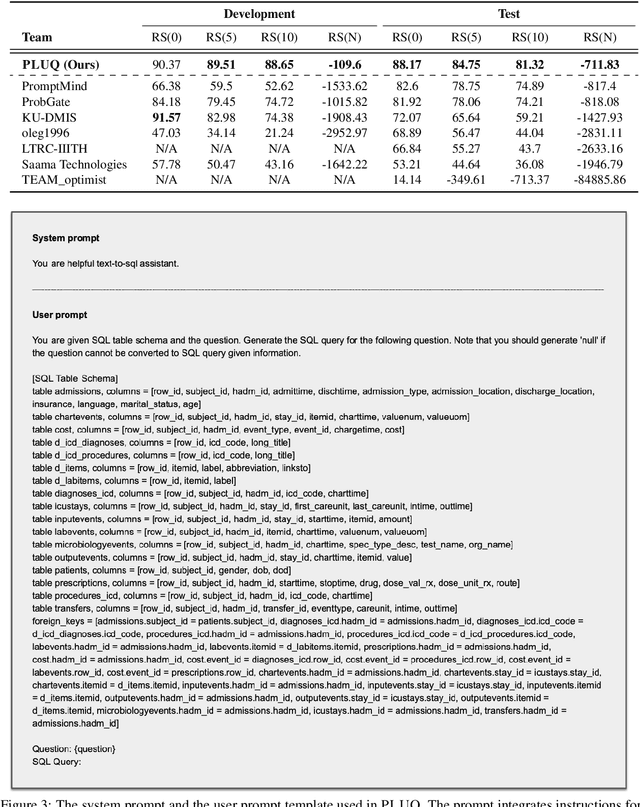
Text-to-SQL models are pivotal for making Electronic Health Records (EHRs) accessible to healthcare professionals without SQL knowledge. With the advancements in large language models, these systems have become more adept at translating complex questions into SQL queries. Nonetheless, the critical need for reliability in healthcare necessitates these models to accurately identify unanswerable questions or uncertain predictions, preventing misinformation. To address this problem, we present a self-training strategy using pseudo-labeled unanswerable questions to enhance the reliability of text-to-SQL models for EHRs. This approach includes a two-stage training process followed by a filtering method based on the token entropy and query execution. Our methodology's effectiveness is validated by our top performance in the EHRSQL 2024 shared task, showcasing the potential to improve healthcare decision-making through more reliable text-to-SQL systems.
Understanding the Capabilities and Limitations of Large Language Models for Cultural Commonsense
May 07, 2024



Large language models (LLMs) have demonstrated substantial commonsense understanding through numerous benchmark evaluations. However, their understanding of cultural commonsense remains largely unexamined. In this paper, we conduct a comprehensive examination of the capabilities and limitations of several state-of-the-art LLMs in the context of cultural commonsense tasks. Using several general and cultural commonsense benchmarks, we find that (1) LLMs have a significant discrepancy in performance when tested on culture-specific commonsense knowledge for different cultures; (2) LLMs' general commonsense capability is affected by cultural context; and (3) The language used to query the LLMs can impact their performance on cultural-related tasks. Our study points to the inherent bias in the cultural understanding of LLMs and provides insights that can help develop culturally aware language models.
Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models
May 02, 2024



Proprietary LMs such as GPT-4 are often employed to assess the quality of responses from various LMs. However, concerns including transparency, controllability, and affordability strongly motivate the development of open-source LMs specialized in evaluations. On the other hand, existing open evaluator LMs exhibit critical shortcomings: 1) they issue scores that significantly diverge from those assigned by humans, and 2) they lack the flexibility to perform both direct assessment and pairwise ranking, the two most prevalent forms of assessment. Additionally, they do not possess the ability to evaluate based on custom evaluation criteria, focusing instead on general attributes like helpfulness and harmlessness. To address these issues, we introduce Prometheus 2, a more powerful evaluator LM than its predecessor that closely mirrors human and GPT-4 judgements. Moreover, it is capable of processing both direct assessment and pair-wise ranking formats grouped with a user-defined evaluation criteria. On four direct assessment benchmarks and four pairwise ranking benchmarks, Prometheus 2 scores the highest correlation and agreement with humans and proprietary LM judges among all tested open evaluator LMs. Our models, code, and data are all publicly available at https://github.com/prometheus-eval/prometheus-eval.
Small Language Models Need Strong Verifiers to Self-Correct Reasoning
Apr 26, 2024



Self-correction has emerged as a promising solution to boost the reasoning performance of large language models (LLMs), where LLMs refine their solutions using self-generated critiques that pinpoint the errors. This work explores whether smaller-size (<= 13B) language models (LMs) have the ability of self-correction on reasoning tasks with minimal inputs from stronger LMs. We propose a novel pipeline that prompts smaller LMs to collect self-correction data that supports the training of self-refinement abilities. First, we leverage correct solutions to guide the model in critiquing their incorrect responses. Second, the generated critiques, after filtering, are used for supervised fine-tuning of the self-correcting reasoner through solution refinement. Our experimental results show improved self-correction abilities of two models on five datasets spanning math and commonsense reasoning, with notable performance gains when paired with a strong GPT-4-based verifier, though limitations are identified when using a weak self-verifier for determining when to correct.
Reinforcement Learning from Reflective Feedback (RLRF): Aligning and Improving LLMs via Fine-Grained Self-Reflection
Mar 21, 2024



Despite the promise of RLHF in aligning LLMs with human preferences, it often leads to superficial alignment, prioritizing stylistic changes over improving downstream performance of LLMs. Underspecified preferences could obscure directions to align the models. Lacking exploration restricts identification of desirable outputs to improve the models. To overcome these challenges, we propose a novel framework: Reinforcement Learning from Reflective Feedback (RLRF), which leverages fine-grained feedback based on detailed criteria to improve the core capabilities of LLMs. RLRF employs a self-reflection mechanism to systematically explore and refine LLM responses, then fine-tuning the models via a RL algorithm along with promising responses. Our experiments across Just-Eval, Factuality, and Mathematical Reasoning demonstrate the efficacy and transformative potential of RLRF beyond superficial surface-level adjustment.
YTCommentQA: Video Question Answerability in Instructional Videos
Jan 30, 2024



Instructional videos provide detailed how-to guides for various tasks, with viewers often posing questions regarding the content. Addressing these questions is vital for comprehending the content, yet receiving immediate answers is difficult. While numerous computational models have been developed for Video Question Answering (Video QA) tasks, they are primarily trained on questions generated based on video content, aiming to produce answers from within the content. However, in real-world situations, users may pose questions that go beyond the video's informational boundaries, highlighting the necessity to determine if a video can provide the answer. Discerning whether a question can be answered by video content is challenging due to the multi-modal nature of videos, where visual and verbal information are intertwined. To bridge this gap, we present the YTCommentQA dataset, which contains naturally-generated questions from YouTube, categorized by their answerability and required modality to answer -- visual, script, or both. Experiments with answerability classification tasks demonstrate the complexity of YTCommentQA and emphasize the need to comprehend the combined role of visual and script information in video reasoning. The dataset is available at https://github.com/lgresearch/YTCommentQA.
Projection Regret: Reducing Background Bias for Novelty Detection via Diffusion Models
Dec 05, 2023



Novelty detection is a fundamental task of machine learning which aims to detect abnormal ($\textit{i.e.}$ out-of-distribution (OOD)) samples. Since diffusion models have recently emerged as the de facto standard generative framework with surprising generation results, novelty detection via diffusion models has also gained much attention. Recent methods have mainly utilized the reconstruction property of in-distribution samples. However, they often suffer from detecting OOD samples that share similar background information to the in-distribution data. Based on our observation that diffusion models can \emph{project} any sample to an in-distribution sample with similar background information, we propose \emph{Projection Regret (PR)}, an efficient novelty detection method that mitigates the bias of non-semantic information. To be specific, PR computes the perceptual distance between the test image and its diffusion-based projection to detect abnormality. Since the perceptual distance often fails to capture semantic changes when the background information is dominant, we cancel out the background bias by comparing it against recursive projections. Extensive experiments demonstrate that PR outperforms the prior art of generative-model-based novelty detection methods by a significant margin.