 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Persistent Effects of Lexicality in Large Language Models
Jun 03, 2026Representations extracted from large language models (LLMs) play an important role in many downstream applications. However, the structure of these representations is often influenced by lexical overlap rather than semantic content. Our understanding of the relationship between this lexical influence and semantic content, and its implications for downstream tasks, remains limited. In this work, we investigate representations to quantify the effect of lexical overlap relative to semantic content. We consider several adversarial semantic stress tests and further connect our findings to the information theory perspective. We find that lexical influence extends across the depth of models, consistently across architectures, training regimes, and objective functions, including the models trained for semantic similarity. Moreover, we observe a mid-depth region in which both lexical and semantic signals degrade simultaneously, indicating a transitional regime where representations are poor for both surface form and meaning. We further demonstrate the effect of lexical influence on downstream uses of LLMs using summarization and model editing as a case study.
Pando: Do Interpretability Methods Work When Models Won't Explain Themselves?
Apr 13, 2026Mechanistic interpretability is often motivated for alignment auditing, where a model's verbal explanations can be absent, incomplete, or misleading. Yet many evaluations do not control whether black-box prompting alone can recover the target behavior, so apparent gains from white-box tools may reflect elicitation rather than internal signal; we call this the elicitation confounder. We introduce Pando, a model-organism benchmark that breaks this confound via an explanation axis: models are trained to produce either faithful explanations of the true rule, no explanation, or confident but unfaithful explanations of a disjoint distractor rule. Across 720 finetuned models implementing hidden decision-tree rules, agents predict held-out model decisions from $10$ labeled query-response pairs, optionally augmented with one interpretability tool output. When explanations are faithful, black-box elicitation matches or exceeds all white-box methods; when explanations are absent or misleading, gradient-based attribution improves accuracy by 3-5 percentage points, and relevance patching, RelP, gives the largest gains, while logit lens, sparse autoencoders, and circuit tracing provide no reliable benefit. Variance decomposition suggests gradients track decision computation, which fields causally drive the output, whereas other readouts are dominated by task representation, biases toward field identity and value. We release all models, code, and evaluation infrastructure.
DSPA: Dynamic SAE Steering for Data-Efficient Preference Alignment
Mar 23, 2026Preference alignment is usually achieved by weight-updating training on preference data, which adds substantial alignment-stage compute and provides limited mechanistic visibility. We propose Dynamic SAE Steering for Preference Alignment (DSPA), an inference-time method that makes sparse autoencoder (SAE) steering prompt-conditional. From preference triples, DSPA computes a conditional-difference map linking prompt features to generation-control features; during decoding, it modifies only token-active latents, without base-model weight updates. Across Gemma-2-2B/9B and Qwen3-8B, DSPA improves MT-Bench and is competitive on AlpacaEval while preserving multiple-choice accuracy. Under restricted preference data, DSPA remains robust and can rival the two-stage RAHF-SCIT pipeline while requiring up to $4.47\times$ fewer alignment-stage FLOPs. Finally, we audit the SAE features DSPA modifies, finding that preference directions are dominated by discourse and stylistic signals, and provide theory clarifying the conditional-difference map estimate and when top-$k$ ablation is principled.
Humanizing Machines: Rethinking LLM Anthropomorphism Through a Multi-Level Framework of Design
Aug 25, 2025Large Language Models (LLMs) increasingly exhibit \textbf{anthropomorphism} characteristics -- human-like qualities portrayed across their outlook, language, behavior, and reasoning functions. Such characteristics enable more intuitive and engaging human-AI interactions. However, current research on anthropomorphism remains predominantly risk-focused, emphasizing over-trust and user deception while offering limited design guidance. We argue that anthropomorphism should instead be treated as a \emph{concept of design} that can be intentionally tuned to support user goals. Drawing from multiple disciplines, we propose that the anthropomorphism of an LLM-based artifact should reflect the interaction between artifact designers and interpreters. This interaction is facilitated by cues embedded in the artifact by the designers and the (cognitive) responses of the interpreters to the cues. Cues are categorized into four dimensions: \textit{perceptive, linguistic, behavioral}, and \textit{cognitive}. By analyzing the manifestation and effectiveness of each cue, we provide a unified taxonomy with actionable levers for practitioners. Consequently, we advocate for function-oriented evaluations of anthropomorphic design.
Position: Mechanistic Interpretability Should Prioritize Feature Consistency in SAEs
May 26, 2025Sparse Autoencoders (SAEs) are a prominent tool in mechanistic interpretability (MI) for decomposing neural network activations into interpretable features. However, the aspiration to identify a canonical set of features is challenged by the observed inconsistency of learned SAE features across different training runs, undermining the reliability and efficiency of MI research. This position paper argues that mechanistic interpretability should prioritize feature consistency in SAEs -- the reliable convergence to equivalent feature sets across independent runs. We propose using the Pairwise Dictionary Mean Correlation Coefficient (PW-MCC) as a practical metric to operationalize consistency and demonstrate that high levels are achievable (0.80 for TopK SAEs on LLM activations) with appropriate architectural choices. Our contributions include detailing the benefits of prioritizing consistency; providing theoretical grounding and synthetic validation using a model organism, which verifies PW-MCC as a reliable proxy for ground-truth recovery; and extending these findings to real-world LLM data, where high feature consistency strongly correlates with the semantic similarity of learned feature explanations. We call for a community-wide shift towards systematically measuring feature consistency to foster robust cumulative progress in MI.
Towards Responsible Natural Language Annotation for the Varieties of Arabic
Mar 17, 2022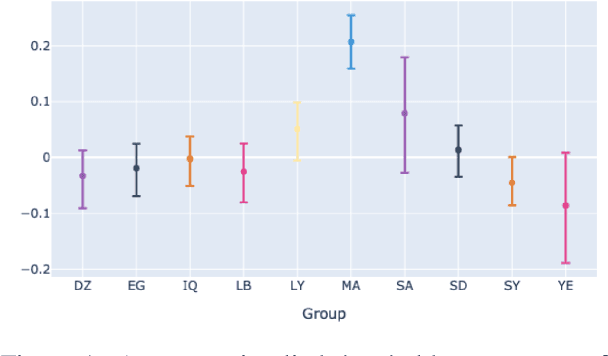
When building NLP models, there is a tendency to aim for broader coverage, often overlooking cultural and (socio)linguistic nuance. In this position paper, we make the case for care and attention to such nuances, particularly in dataset annotation, as well as the inclusion of cultural and linguistic expertise in the process. We present a playbook for responsible dataset creation for polyglossic, multidialectal languages. This work is informed by a study on Arabic annotation of social media content.