 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient AI Supercomputer Networking using MRC and SRv6
May 05, 2026Tail latency dominates the performance of synchronous pretraining jobs when running at very large scales. We describe a three-pronged approach: (1) a new RDMA-based transport protocol, MRC, sprays across many paths and actively load-balances between them, eliminating the issue of flow collisions (2) the use of multi-plane Clos topologies to get the benefits of high switch radix and redundancy, allowing training clusters well over 100K GPUs to be built as two-tier topologies while increasing physical redundancy, and (3) the use of static source-routing using SRv6 to allow MRC the freedom to bypass failures by itself. We describe our experiences running MRC and static SRv6 routing in production in OpenAI and Microsoft's largest training clusters, where it has been used to train the latest frontier models. We demonstrate how MRC allows AI training jobs to ride out many network failures that previously would have interrupted training.
LICA: Layered Image Composition Annotations for Graphic Design Research
Mar 17, 2026We introduce LICA (Layered Image Composition Annotations), a large-scale dataset of 1,550,244 multi-layer graphic design compositions designed to advance structured understanding and generation of graphic layouts1. In addition to ren- dered PNG images, LICA represents each design as a hierarchical composition of typed components including text, image, vector, and group elements, each paired with rich per-element metadata such as spatial geometry, typographic attributes, opacity, and visibility. The dataset spans 20 design categories and 971,850 unique templates, providing broad coverage of real-world design structures. We further introduce graphic design video as a new and largely unexplored challenge for current vision-language models through 27,261 animated layouts annotated with per-component keyframes and motion parameters. Beyond scale, LICA establishes a new paradigm of research tasks for graphic design, enabling structured investiga- tions into problems such as layer-aware inpainting, structured layout generation, controlled design editing, and temporally-aware generative modeling. By repre- senting design as a system of compositional layers and relationships, the dataset supports research on models that operate directly on design structure rather than pixels alone.
Empower Large Language Model to Perform Better on Industrial Domain-Specific Question Answering
May 19, 2023Large Language Model (LLM) has gained popularity and achieved remarkable results in open-domain tasks, but its performance in real industrial domain-specific scenarios is average since there is no specific knowledge in it. This issue has attracted widespread attention, but there are few relevant benchmarks available. In this paper, we provide a benchmark Question Answering (QA) dataset named MSQA, which is about Microsoft products and IT technical problems encountered by customers. This dataset contains industry cloud-specific QA knowledge, which is not available for general LLM, so it is well suited for evaluating methods aimed at improving domain-specific capabilities of LLM. In addition, we propose a new model interaction paradigm that can empower LLM to achieve better performance on domain-specific tasks where it is not proficient. Extensive experiments demonstrate that the approach following our model fusion framework outperforms the commonly used LLM with retrieval methods.
Can Connected Autonomous Vehicles really improve mixed traffic efficiency in realistic scenarios?
Jul 11, 2021
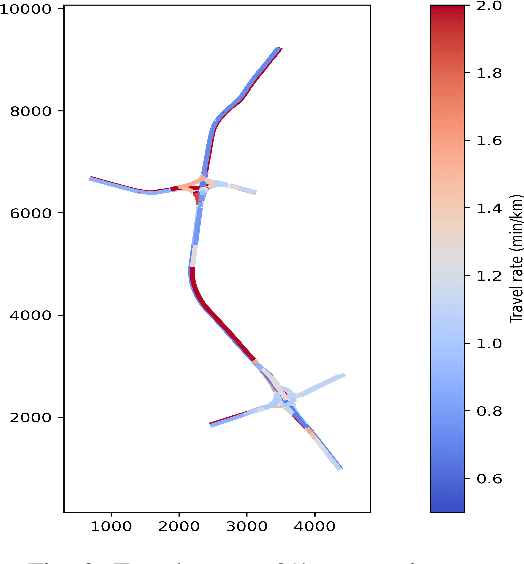
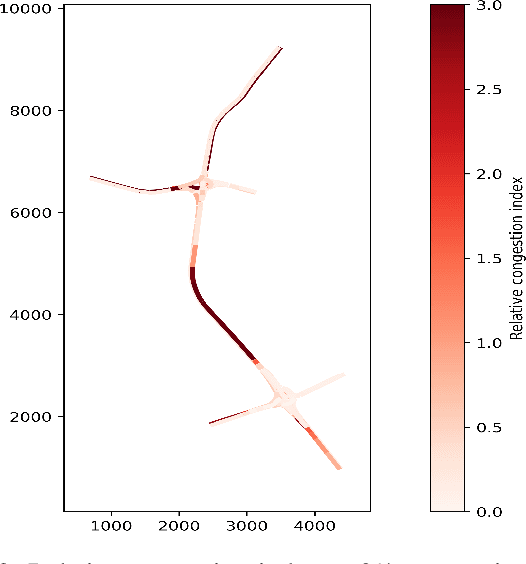
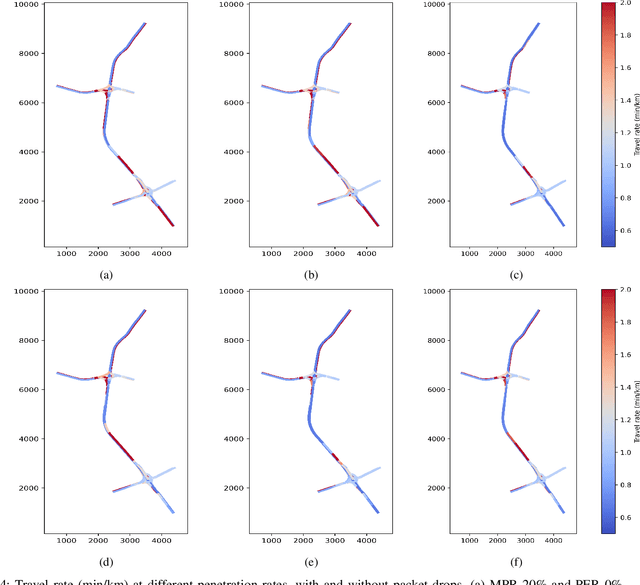
Connected autonomous vehicles (CAVs) can supplement the information from their own sensors with information from surrounding CAVs for decision making and control. This has the potential to improve traffic efficiency. CAVs face additional challenges in their driving, however, when they interact with human-driven vehicles (HDVs) in mixed-traffic environments due to the uncertainty in human's driving behavior e.g. larger reaction times, perception errors, etc. While a lot of research has investigated the impact of CAVs on traffic safety and efficiency at different penetration rates, all have assumed either perfect communication or very simple scenarios with imperfect communication. In practice, the presence of communication delays and packet losses means that CAVs might receive only partial information from surrounding vehicles, and this can have detrimental effects on their performance. This paper investigates the impact of CAVs on traffic efficiency in realistic communication and road network scenarios (i.e. imperfect communication and large-scale road network). We analyze the effect of unreliable communication links on CAVs operation in mixed traffic with various penetration rates and evaluate traffic performance in congested traffic scenarios on a large-scale road network (the M50 motorway, in Ireland). Results show that CAVs can significantly improve traffic efficiency in congested traffic scenarios at high penetration rates. The scale of the improvement depends on communication reliability, with a packet drop rate of 70% leading to an increase in traffic congestion by 28.7% and 11.88% at 40% and 70% penetration rates respectively compared to perfect communication.