 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Blame the ELBO! A Linear VAE Perspective on Posterior Collapse
Nov 06, 2019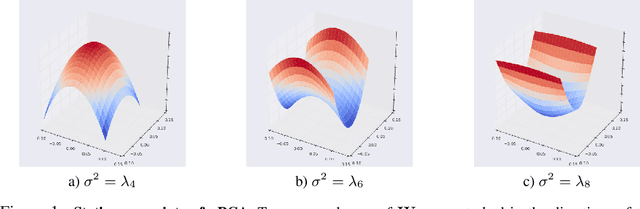
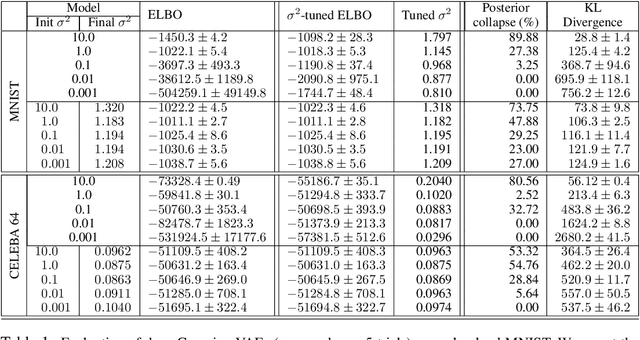
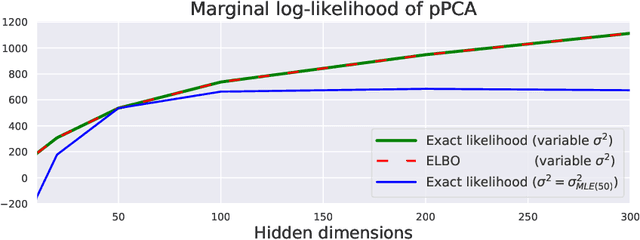
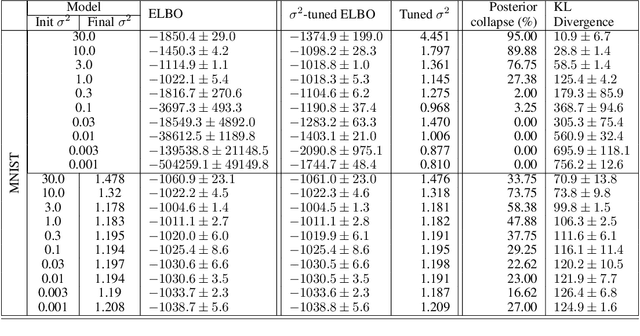
Posterior collapse in Variational Autoencoders (VAEs) arises when the variational posterior distribution closely matches the prior for a subset of latent variables. This paper presents a simple and intuitive explanation for posterior collapse through the analysis of linear VAEs and their direct correspondence with Probabilistic PCA (pPCA). We explain how posterior collapse may occur in pPCA due to local maxima in the log marginal likelihood. Unexpectedly, we prove that the ELBO objective for the linear VAE does not introduce additional spurious local maxima relative to log marginal likelihood. We show further that training a linear VAE with exact variational inference recovers an identifiable global maximum corresponding to the principal component directions. Empirically, we find that our linear analysis is predictive even for high-capacity, non-linear VAEs and helps explain the relationship between the observation noise, local maxima, and posterior collapse in deep Gaussian VAEs.
Efficient Exploration with Self-Imitation Learning via Trajectory-Conditioned Policy
Jul 24, 2019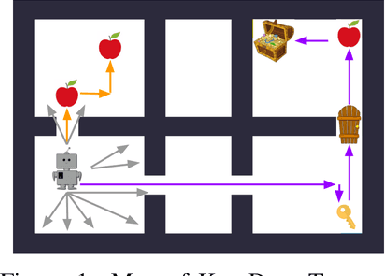
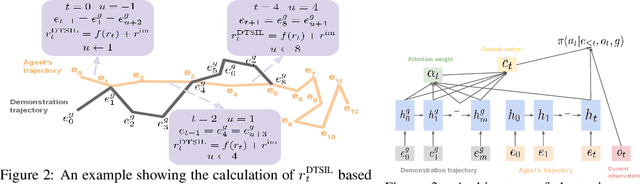
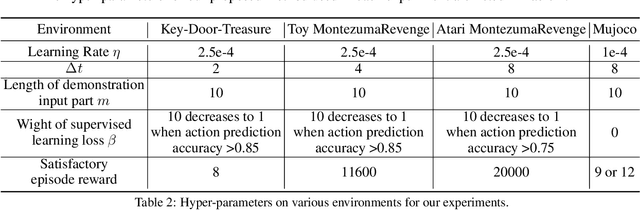
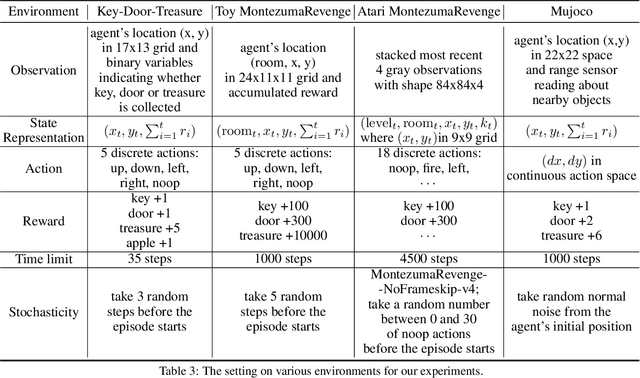
This paper proposes a method for learning a trajectory-conditioned policy to imitate diverse demonstrations from the agent's own past experiences. We demonstrate that such self-imitation drives exploration in diverse directions and increases the chance of finding a globally optimal solution in reinforcement learning problems, especially when the reward is sparse and deceptive. Our method significantly outperforms existing self-imitation learning and count-based exploration methods on various sparse-reward reinforcement learning tasks with local optima. In particular, we report a state-of-the-art score of more than 25,000 points on Montezuma's Revenge without using expert demonstrations or resetting to arbitrary states.
Striving for Simplicity in Off-policy Deep Reinforcement Learning
Jul 10, 2019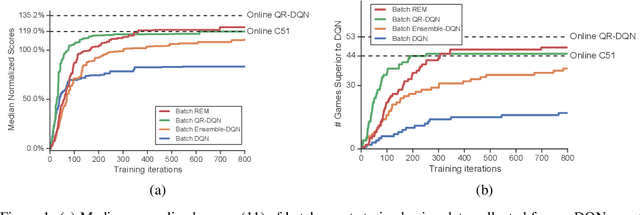
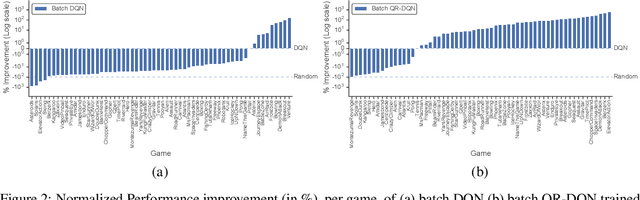

Reflecting on the advances of off-policy deep reinforcement learning (RL) algorithms since the development of DQN in 2013, it is important to ask: are the complexities of recent off-policy methods really necessary? In an attempt to isolate the contributions of various factors of variation in off-policy deep RL and to help design simpler algorithms, this paper investigates a set of related questions: First, can effective policies be learned given only access to logged offline experience? Second, how much of the benefits of recent distributional RL algorithms is attributed to improvements in exploration versus exploitation behavior? Third, can simpler off-policy RL algorithms outperform distributional RL without learning explicit distributions over returns? This paper uses a batch RL experimental setup on Atari 2600 games to investigate these questions. Unexpectedly, we find that batch RL algorithms trained solely on logged experiences of a DQN agent are able to significantly outperform online DQN. Our experiments suggest that the benefits of distributional RL mainly stem from better exploitation. We present a simple and novel variant of ensemble Q-learning called Random Ensemble Mixture (REM), which enforces optimal Bellman consistency on random convex combinations of the Q-heads of a multi-head Q-network. The batch REM agent trained offline on DQN data outperforms the batch QR-DQN and online C51 algorithms.
Similarity of Neural Network Representations Revisited
May 14, 2019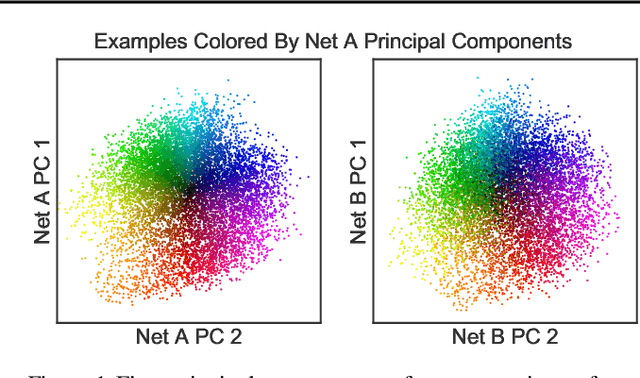

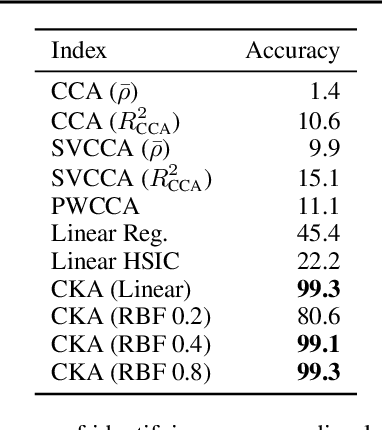
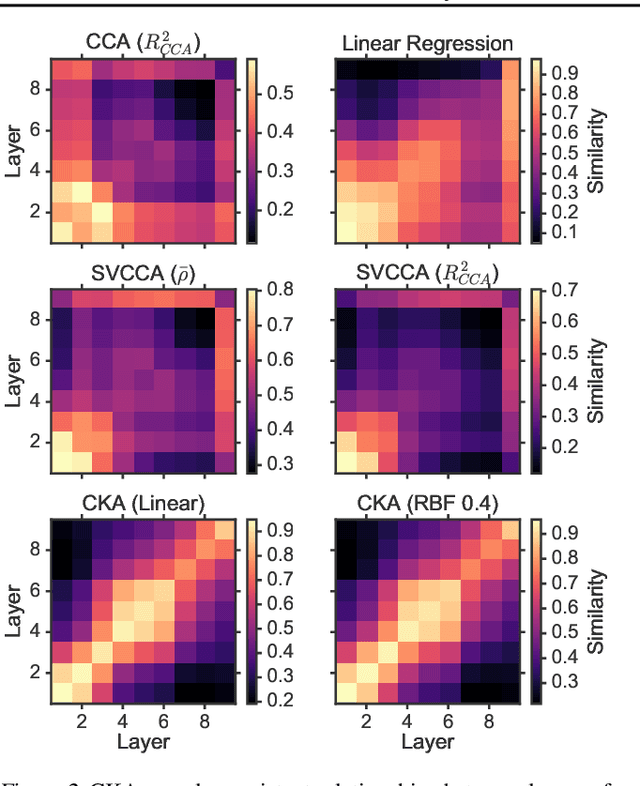
Recent work has sought to understand the behavior of neural networks by comparing representations between layers and between different trained models. We examine methods for comparing neural network representations based on canonical correlation analysis (CCA). We show that CCA belongs to a family of statistics for measuring multivariate similarity, but that neither CCA nor any other statistic that is invariant to invertible linear transformation can measure meaningful similarities between representations of higher dimension than the number of data points. We introduce a similarity index that measures the relationship between representational similarity matrices and does not suffer from this limitation. This similarity index is equivalent to centered kernel alignment (CKA) and is also closely connected to CCA. Unlike CCA, CKA can reliably identify correspondences between representations in networks trained from different initializations.
Learning to Generalize from Sparse and Underspecified Rewards
Feb 19, 2019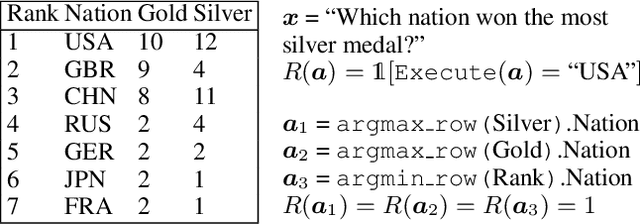


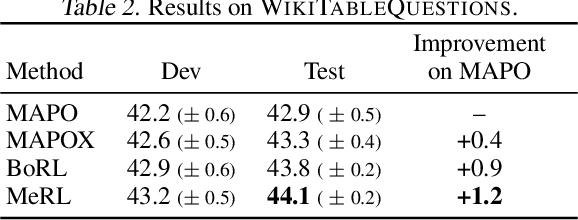
We consider the problem of learning from sparse and underspecified rewards, where an agent receives a complex input, such as a natural language instruction, and needs to generate a complex response, such as an action sequence, while only receiving binary success-failure feedback. Such success-failure rewards are often underspecified: they do not distinguish between purposeful and accidental success. Generalization from underspecified rewards hinges on discounting spurious trajectories that attain accidental success, while learning from sparse feedback requires effective exploration. We address exploration by using a mode covering direction of KL divergence to collect a diverse set of successful trajectories, followed by a mode seeking KL divergence to train a robust policy. We propose Meta Reward Learning (MeRL) to construct an auxiliary reward function that provides more refined feedback for learning. The parameters of the auxiliary reward function are optimized with respect to the validation performance of a trained policy. The MeRL approach outperforms our alternative reward learning technique based on Bayesian Optimization, and achieves the state-of-the-art on weakly-supervised semantic parsing. It improves previous work by 1.2% and 2.4% on WikiTableQuestions and WikiSQL datasets respectively.
Understanding the impact of entropy on policy optimization
Nov 29, 2018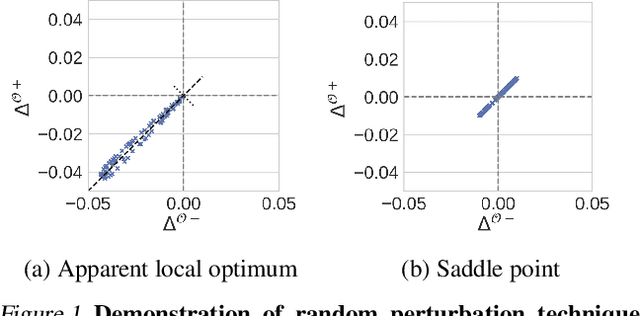
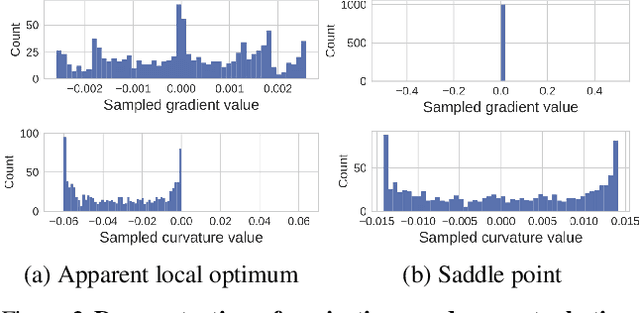
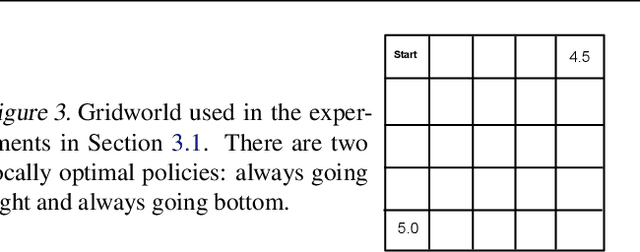
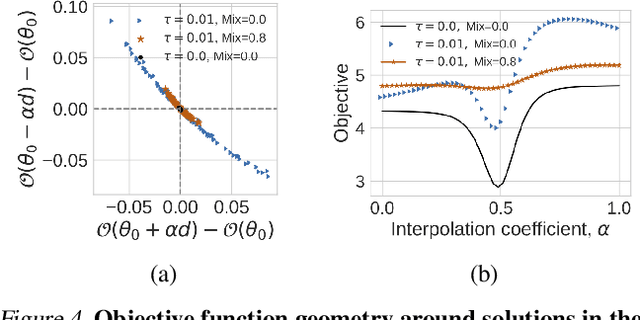
Entropy regularization is commonly used to improve policy optimization in reinforcement learning. It is believed to help with exploration by encouraging the selection of more stochastic policies. In this work, we analyze this claim and, through new visualizations of the optimization landscape, we observe that incorporating entropy in policy optimization serves as a regularizer. We show that even with access to the exact gradient, policy optimization is difficult due to the geometry of the objective function. We qualitatively show that, in some environments, entropy regularization can make the optimization landscape smoother, thereby connecting local optima and enabling the use of larger learning rates. This manuscript presents new tools for understanding the underlying optimization landscape and highlights the challenge of designing general-purpose policy optimization algorithms in reinforcement learning.
Contingency-Aware Exploration in Reinforcement Learning
Nov 05, 2018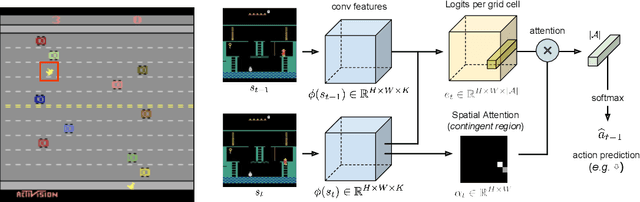
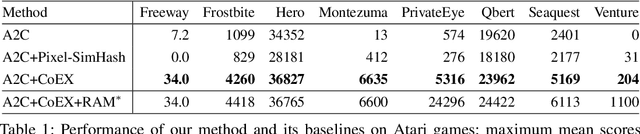
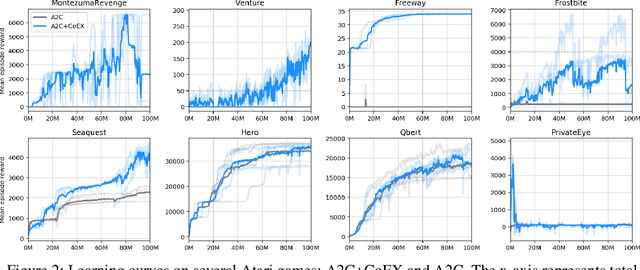
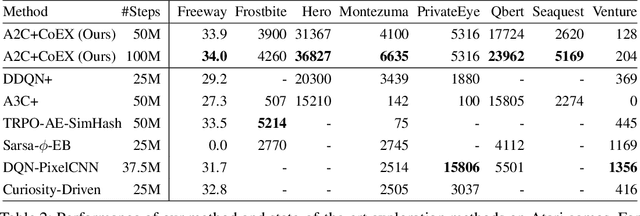
This paper investigates whether learning contingency-awareness and controllable aspects of an environment can lead to better exploration in reinforcement learning. To investigate this question, we consider an instantiation of this hypothesis evaluated on the Arcade Learning Element (ALE). In this study, we develop an attentive dynamics model (ADM) that discovers controllable elements of the observations, which are often associated with the location of the character in Atari games. The ADM is trained in a self-supervised fashion to predict the actions taken by the agent. The learned contingency information is used as a part of the state representation for exploration purposes. We demonstrate that combining A2C with count-based exploration using our representation achieves impressive results on a set of notoriously challenging Atari games due to sparse rewards. For example, we report a state-of-the-art score of >6600 points on Montezuma's Revenge without using expert demonstrations, explicit high-level information (e.g., RAM states), or supervised data. Our experiments confirm that indeed contingency-awareness is an extremely powerful concept for tackling exploration problems in reinforcement learning and opens up interesting research questions for further investigations.
Memory Augmented Policy Optimization for Program Synthesis and Semantic Parsing
Oct 31, 2018
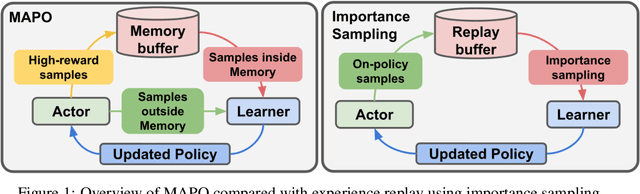
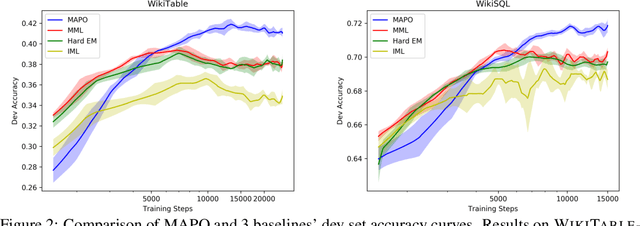

We present Memory Augmented Policy Optimization (MAPO), a simple and novel way to leverage a memory buffer of promising trajectories to reduce the variance of policy gradient estimate. MAPO is applicable to deterministic environments with discrete actions, such as structured prediction and combinatorial optimization tasks. We express the expected return objective as a weighted sum of two terms: an expectation over the high-reward trajectories inside the memory buffer, and a separate expectation over trajectories outside the buffer. To make an efficient algorithm of MAPO, we propose: (1) memory weight clipping to accelerate and stabilize training; (2) systematic exploration to discover high-reward trajectories; (3) distributed sampling from inside and outside of the memory buffer to scale up training. MAPO improves the sample efficiency and robustness of policy gradient, especially on tasks with sparse rewards. We evaluate MAPO on weakly supervised program synthesis from natural language (semantic parsing). On the WikiTableQuestions benchmark, we improve the state-of-the-art by 2.6%, achieving an accuracy of 46.3%. On the WikiSQL benchmark, MAPO achieves an accuracy of 74.9% with only weak supervision, outperforming several strong baselines with full supervision. Our source code is available at https://github.com/crazydonkey200/neural-symbolic-machines
Sequence to Sequence Mixture Model for Diverse Machine Translation
Oct 17, 2018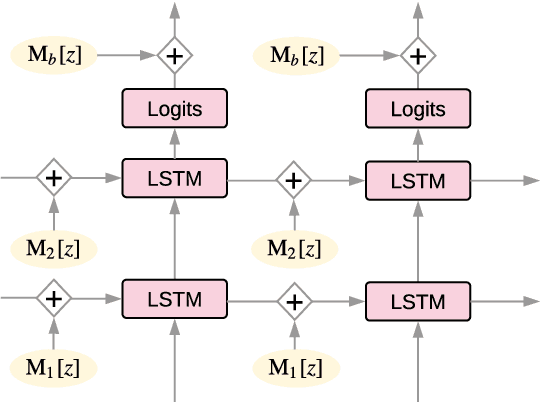
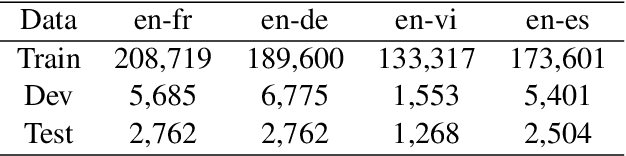
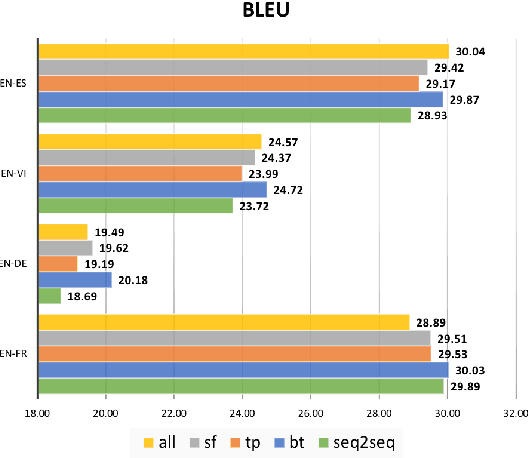
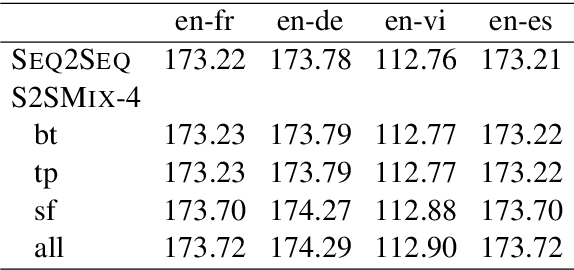
Sequence to sequence (SEQ2SEQ) models often lack diversity in their generated translations. This can be attributed to the limitation of SEQ2SEQ models in capturing lexical and syntactic variations in a parallel corpus resulting from different styles, genres, topics, or ambiguity of the translation process. In this paper, we develop a novel sequence to sequence mixture (S2SMIX) model that improves both translation diversity and quality by adopting a committee of specialized translation models rather than a single translation model. Each mixture component selects its own training dataset via optimization of the marginal loglikelihood, which leads to a soft clustering of the parallel corpus. Experiments on four language pairs demonstrate the superiority of our mixture model compared to a SEQ2SEQ baseline with standard or diversity-boosted beam search. Our mixture model uses negligible additional parameters and incurs no extra computation cost during decoding.
Optimal Completion Distillation for Sequence Learning
Oct 02, 2018
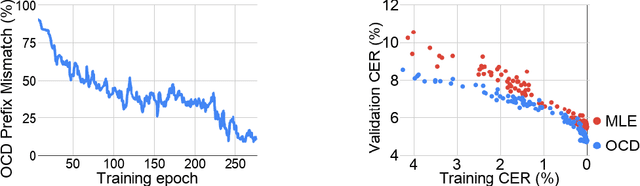

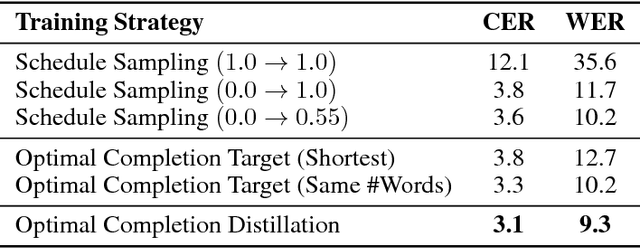
We present Optimal Completion Distillation (OCD), a training procedure for optimizing sequence to sequence models based on edit distance. OCD is efficient, has no hyper-parameters of its own, and does not require pretraining or joint optimization with conditional log-likelihood. Given a partial sequence generated by the model, we first identify the set of optimal suffixes that minimize the total edit distance, using an efficient dynamic programming algorithm. Then, for each position of the generated sequence, we use a target distribution that puts equal probability on the first token of all the optimal suffixes. OCD achieves the state-of-the-art performance on end-to-end speech recognition, on both Wall Street Journal and Librispeech datasets, achieving $9.3\%$ WER and $4.5\%$ WER respectively.