 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Step Greedy and Approximate Real Time Dynamic Programming
Sep 10, 2019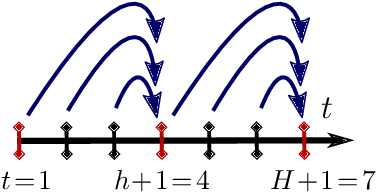

Real Time Dynamic Programming (RTDP) is a well-known Dynamic Programming (DP) based algorithm that combines planning and learning to find an optimal policy for an MDP. It is a planning algorithm because it uses the MDP's model (reward and transition functions) to calculate a 1-step greedy policy w.r.t.~an optimistic value function, by which it acts. It is a learning algorithm because it updates its value function only at the states it visits while interacting with the environment. As a result, unlike DP, RTDP does not require uniform access to the state space in each iteration, which makes it particularly appealing when the state space is large and simultaneously updating all the states is not computationally feasible. In this paper, we study a generalized multi-step greedy version of RTDP, which we call $h$-RTDP, in its exact form, as well as in three approximate settings: approximate model, approximate value updates, and approximate state abstraction. We analyze the sample, computation, and space complexities of $h$-RTDP and establish that increasing $h$ improves sample and space complexity, with the cost of additional offline computational operations. For the approximate cases, we prove that the asymptotic performance of $h$-RTDP is the same as that of a corresponding approximate DP -- the best one can hope for without further assumptions on the approximation errors. $h$-RTDP is the first algorithm with a provably improved sample complexity when increasing the lookahead horizon.
Prediction, Consistency, Curvature: Representation Learning for Locally-Linear Control
Sep 04, 2019


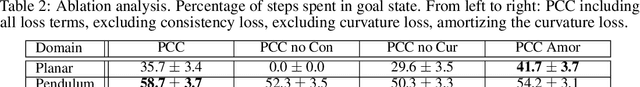
Many real-world sequential decision-making problems can be formulated as optimal control with high-dimensional observations and unknown dynamics. A promising approach is to embed the high-dimensional observations into a lower-dimensional latent representation space, estimate the latent dynamics model, then utilize this model for control in the latent space. An important open question is how to learn a representation that is amenable to existing control algorithms? In this paper, we focus on learning representations for locally-linear control algorithms, such as iterative LQR (iLQR). By formulating and analyzing the representation learning problem from an optimal control perspective, we establish three underlying principles that the learned representation should comprise: 1) accurate prediction in the observation space, 2) consistency between latent and observation space dynamics, and 3) low curvature in the latent space transitions. These principles naturally correspond to a loss function that consists of three terms: prediction, consistency, and curvature (PCC). Crucially, to make PCC tractable, we derive an amortized variational bound for the PCC loss function. Extensive experiments on benchmark domains demonstrate that the new variational-PCC learning algorithm benefits from significantly more stable and reproducible training, and leads to superior control performance. Further ablation studies give support to the importance of all three PCC components for learning a good latent space for control.
Randomized Exploration in Generalized Linear Bandits
Jun 21, 2019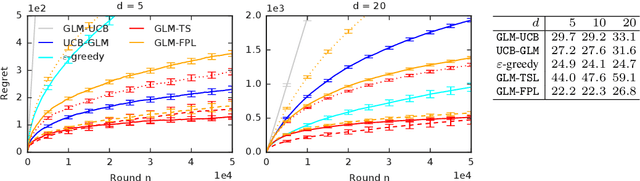
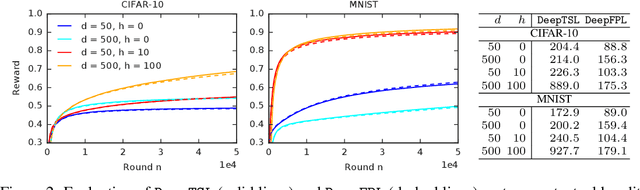
We study two randomized algorithms for generalized linear bandits, GLM-TSL and GLM-FPL. GLM-TSL samples a generalized linear model (GLM) from the Laplace approximation to the posterior distribution. GLM-FPL, a new algorithm proposed in this work, fits a GLM to a randomly perturbed history of past rewards. We prove a $\tilde{O}(d \sqrt{n} + d^2)$ upper bound on the $n$-round regret of GLM-TSL, where $d$ is the number of features. This is the first regret bound of a Thompson sampling-like algorithm in GLM bandits where the leading term is $\tilde{O}(d \sqrt{n})$. We apply both GLM-TSL and GLM-FPL to logistic and neural network bandits, and show that they perform well empirically. In more complex models, GLM-FPL is significantly faster. Our results showcase the role of randomization, beyond posterior sampling, in exploration.
Active Learning for Binary Classification with Abstention
Jun 01, 2019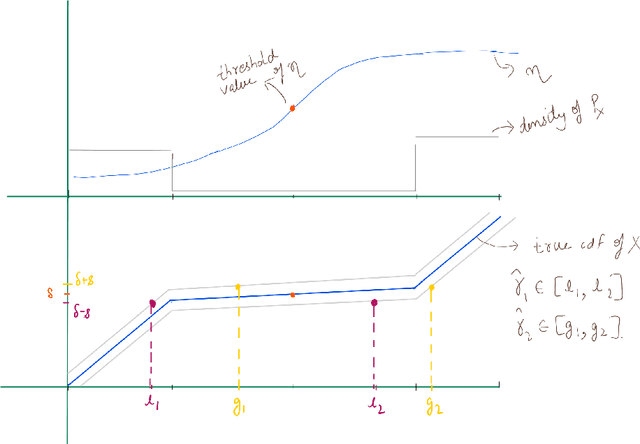
We construct and analyze active learning algorithms for the problem of binary classification with abstention. We consider three abstention settings: \emph{fixed-cost} and two variants of \emph{bounded-rate} abstention, and for each of them propose an active learning algorithm. All the proposed algorithms can work in the most commonly used active learning models, i.e., \emph{membership-query}, \emph{pool-based}, and \emph{stream-based} sampling. We obtain upper-bounds on the excess risk of our algorithms in a general non-parametric framework and establish their minimax near-optimality by deriving matching lower-bounds. Since our algorithms rely on the knowledge of some smoothness parameters of the regression function, we then describe a new strategy to adapt to these unknown parameters in a data-driven manner. Since the worst case computational complexity of our proposed algorithms increases exponentially with the dimension of the input space, we conclude the paper with a computationally efficient variant of our algorithm whose computational complexity has a polynomial dependence over a smaller but rich class of learning problems.
Tight Regret Bounds for Model-Based Reinforcement Learning with Greedy Policies
May 27, 2019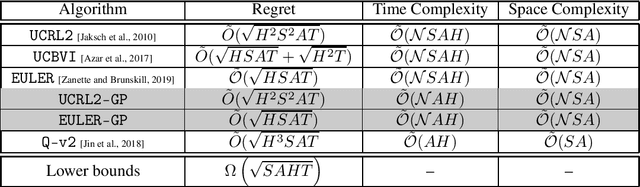
State-of-the-art efficient model-based Reinforcement Learning (RL) algorithms typically act by iteratively solving empirical models, i.e., by performing \emph{full-planning} on Markov Decision Processes (MDPs) built by the gathered experience. In this paper, we focus on model-based RL in the finite-state finite-horizon MDP setting and establish that exploring with \emph{greedy policies} -- act by \emph{1-step planning} -- can achieve tight minimax performance in terms of regret, $\tilde{\mathcal{O}}(\sqrt{HSAT})$. Thus, full-planning in model-based RL can be avoided altogether without any performance degradation, and, by doing so, the computational complexity decreases by a factor of $S$. The results are based on a novel analysis of real-time dynamic programming, then extended to model-based RL. Specifically, we generalize existing algorithms that perform full-planning to such that act by 1-step planning. For these generalizations, we prove regret bounds with the same rate as their full-planning counterparts.
Binary Classification with Bounded Abstention Rate
May 23, 2019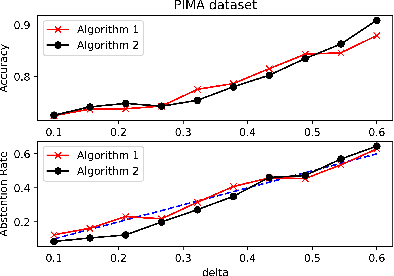
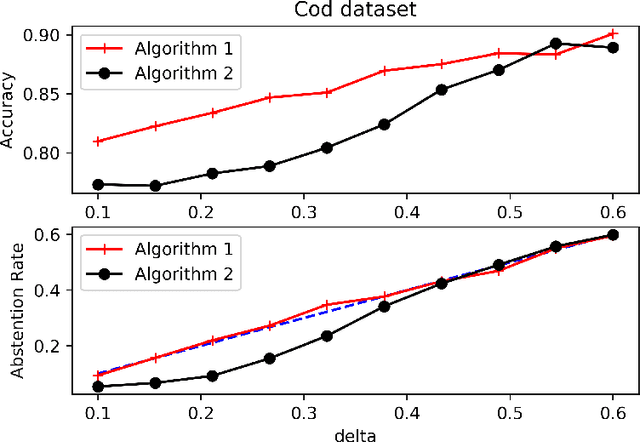
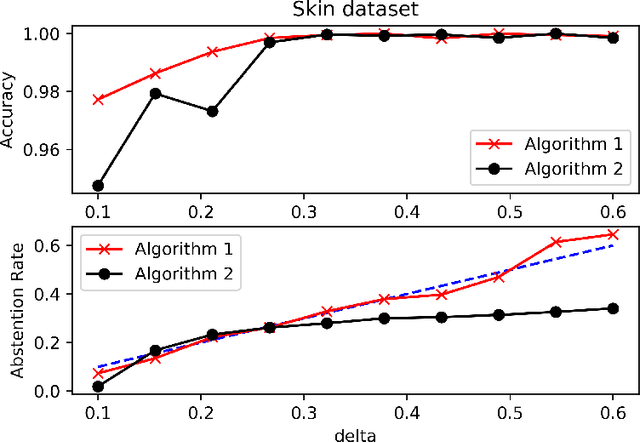
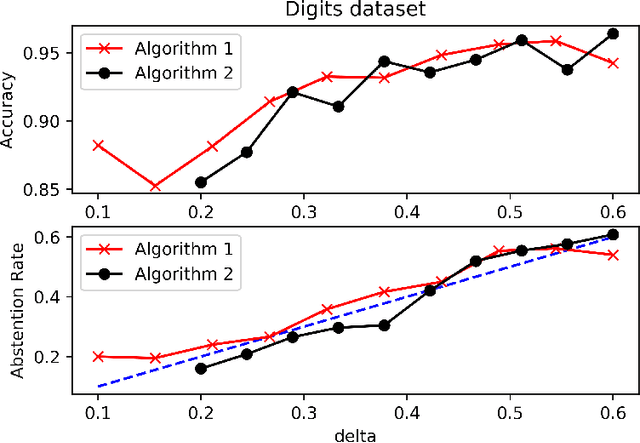
We consider the problem of binary classification with abstention in the relatively less studied \emph{bounded-rate} setting. We begin by obtaining a characterization of the Bayes optimal classifier for an arbitrary input-label distribution $P_{XY}$. Our result generalizes and provides an alternative proof for the result first obtained by \cite{chow1957optimum}, and then re-derived by \citet{denis2015consistency}, under a continuity assumption on $P_{XY}$. We then propose a plug-in classifier that employs unlabeled samples to decide the region of abstention and derive an upper-bound on the excess risk of our classifier under standard \emph{H\"older smoothness} and \emph{margin} assumptions. Unlike the plug-in rule of \citet{denis2015consistency}, our constructed classifier satisfies the abstention constraint with high probability and can also deal with discontinuities in the empirical cdf. We also derive lower-bounds that demonstrate the minimax near-optimality of our proposed algorithm. To address the excessive complexity of the plug-in classifier in high dimensions, we propose a computationally efficient algorithm that builds upon prior work on convex loss surrogates, and obtain bounds on its excess risk in the \emph{realizable} case. We empirically compare the performance of the proposed algorithm with a baseline on a number of UCI benchmark datasets.
Perturbed-History Exploration in Stochastic Linear Bandits
Mar 21, 2019
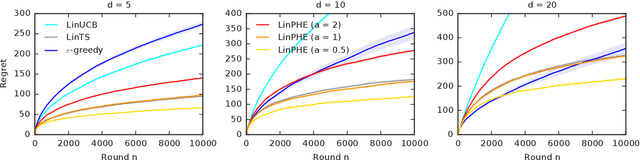
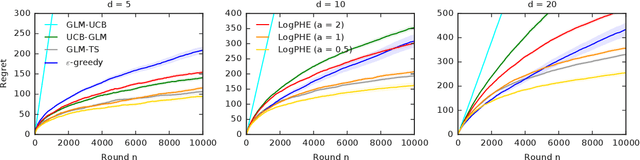
We propose a new online algorithm for minimizing the cumulative regret in stochastic linear bandits. The key idea is to build a perturbed history, which mixes the history of observed rewards with a pseudo-history of randomly generated i.i.d. pseudo-rewards. Our algorithm, perturbed-history exploration in a linear bandit (LinPHE), estimates a linear model from its perturbed history and pulls the arm with the highest value under that model. We prove a $\tilde{O}(d \sqrt{n})$ gap-free bound on the expected $n$-round regret of LinPHE, where $d$ is the number of features. Our analysis relies on novel concentration and anti-concentration bounds on the weighted sum of Bernoulli random variables. To show the generality of our design, we extend LinPHE to a logistic reward model. We evaluate both algorithms empirically and show that they are practical.
Perturbed-History Exploration in Stochastic Multi-Armed Bandits
Feb 26, 2019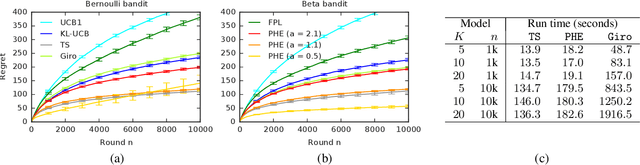
We propose an online algorithm for cumulative regret minimization in a stochastic multi-armed bandit. The algorithm adds $O(t)$ i.i.d. pseudo-rewards to its history in round $t$ and then pulls the arm with the highest estimated value in its perturbed history. Therefore, we call it perturbed-history exploration (PHE). The pseudo-rewards are designed to offset the underestimated values of arms in round $t$ with a sufficiently high probability. We analyze PHE in a $K$-armed bandit and prove a $O(K \Delta^{-1} \log n)$ bound on its $n$-round regret, where $\Delta$ is the minimum gap between the expected rewards of the optimal and suboptimal arms. The key to our analysis is a novel argument that shows that randomized Bernoulli rewards lead to optimism. We compare PHE empirically to several baselines and show that it is competitive with the best of them.
Lyapunov-based Safe Policy Optimization for Continuous Control
Jan 28, 2019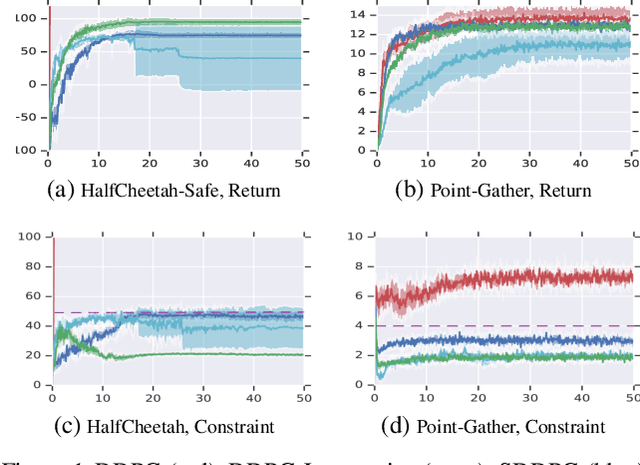
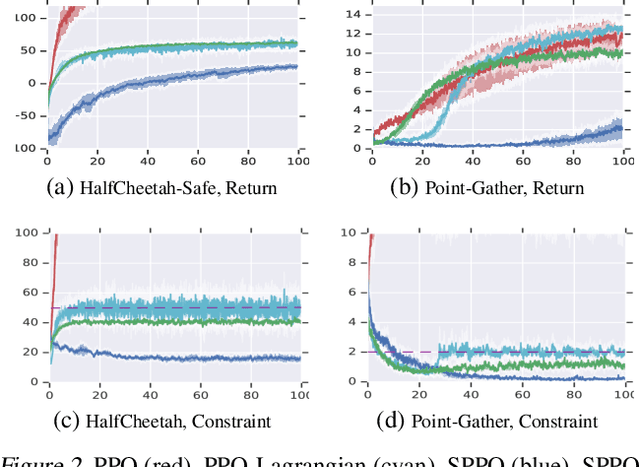
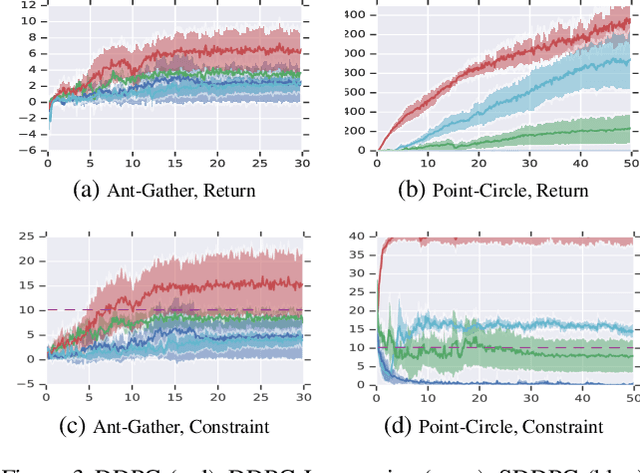
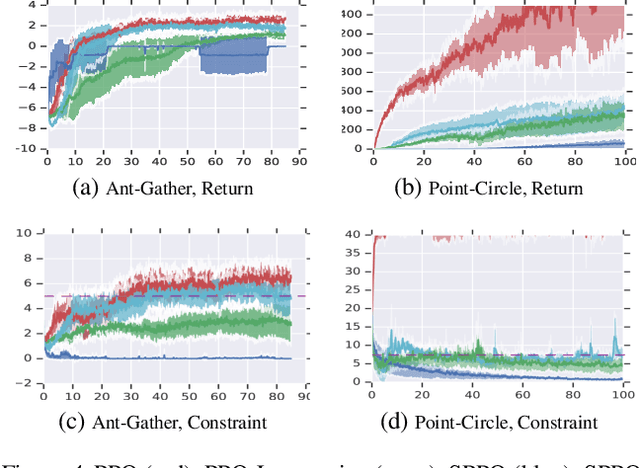
We study continuous action reinforcement learning problems in which it is crucial that the agent interacts with the environment only through {\em safe} policies, i.e.,~policies that do not take the agent to undesirable situations. We formulate these problems as {\em constrained} Markov decision processes (CMDPs) and present safe policy optimization algorithms that are based on a {\em Lyapunov} approach to solve them. Our algorithms can use any standard policy gradient (PG) method, such as deep deterministic policy gradient (DDPG) or proximal policy optimization (PPO), to train a neural network policy, while guaranteeing near-constraint satisfaction for every policy update by projecting either the policy parameter or the action onto the set of feasible solutions induced by the state-dependent linearized Lyapunov constraints. Compared to the existing constrained PG algorithms, ours are more data efficient as they are able to utilize both on-policy and off-policy data. Moreover, our action-projection algorithm often leads to less conservative policy updates and allows for natural integration into an end-to-end PG training pipeline. We evaluate our algorithms and compare them with the state-of-the-art baselines on several simulated (MuJoCo) tasks, as well as a real-world indoor robot navigation problem, demonstrating their effectiveness in terms of balancing performance and constraint satisfaction. Videos of the experiments can be found in the following link: https://drive.google.com/file/d/1pzuzFqWIE710bE2U6DmS59AfRzqK2Kek/view?usp=sharing .
Garbage In, Reward Out: Bootstrapping Exploration in Multi-Armed Bandits
Nov 13, 2018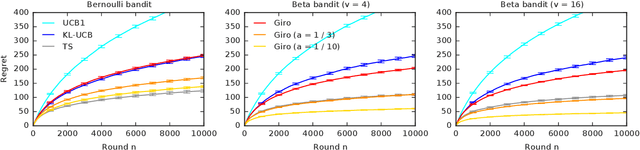
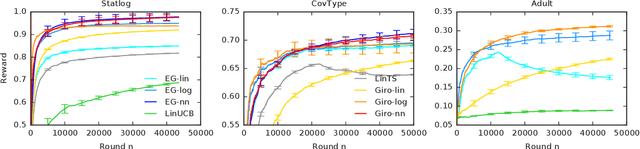
We propose a multi-armed bandit algorithm that explores based on randomizing its history. The key idea is to estimate the value of the arm from the bootstrap sample of its history, where we add pseudo observations after each pull of the arm. The pseudo observations seem to be harmful. But on the contrary, they guarantee that the bootstrap sample is optimistic with a high probability. Because of this, we call our algorithm Giro, which is an abbreviation for garbage in, reward out. We analyze Giro in a $K$-armed Bernoulli bandit and prove a $O(K \Delta^{-1} \log n)$ bound on its $n$-round regret, where $\Delta$ denotes the difference in the expected rewards of the optimal and best suboptimal arms. The main advantage of our exploration strategy is that it can be applied to any reward function generalization, such as neural networks. We evaluate Giro and its contextual variant on multiple synthetic and real-world problems, and observe that Giro is comparable to or better than state-of-the-art algorithms.