 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Data Gap: Bridging LLMs to Enterprise Data Integration
Dec 29, 2024Leading large language models (LLMs) are trained on public data. However, most of the world's data is dark data that is not publicly accessible, mainly in the form of private organizational or enterprise data. We show that the performance of methods based on LLMs seriously degrades when tested on real-world enterprise datasets. Current benchmarks, based on public data, overestimate the performance of LLMs. We release a new benchmark dataset, the GOBY Benchmark, to advance discovery in enterprise data integration. Based on our experience with this enterprise benchmark, we propose techniques to uplift the performance of LLMs on enterprise data, including (1) hierarchical annotation, (2) runtime class-learning, and (3) ontology synthesis. We show that, once these techniques are deployed, the performance on enterprise data becomes on par with that of public data. The Goby benchmark can be obtained at https://goby-benchmark.github.io/.
BEAVER: An Enterprise Benchmark for Text-to-SQL
Sep 03, 2024Existing text-to-SQL benchmarks have largely been constructed using publicly available tables from the web with human-generated tests containing question and SQL statement pairs. They typically show very good results and lead people to think that LLMs are effective at text-to-SQL tasks. In this paper, we apply off-the-shelf LLMs to a benchmark containing enterprise data warehouse data. In this environment, LLMs perform poorly, even when standard prompt engineering and RAG techniques are utilized. As we will show, the reasons for poor performance are largely due to three characteristics: (1) public LLMs cannot train on enterprise data warehouses because they are largely in the "dark web", (2) schemas of enterprise tables are more complex than the schemas in public data, which leads the SQL-generation task innately harder, and (3) business-oriented questions are often more complex, requiring joins over multiple tables and aggregations. As a result, we propose a new dataset BEAVER, sourced from real enterprise data warehouses together with natural language queries and their correct SQL statements which we collected from actual user history. We evaluated this dataset using recent LLMs and demonstrated their poor performance on this task. We hope this dataset will facilitate future researchers building more sophisticated text-to-SQL systems which can do better on this important class of data.
QirK: Question Answering via Intermediate Representation on Knowledge Graphs
Aug 14, 2024

We demonstrate QirK, a system for answering natural language questions on Knowledge Graphs (KG). QirK can answer structurally complex questions that are still beyond the reach of emerging Large Language Models (LLMs). It does so using a unique combination of database technology, LLMs, and semantic search over vector embeddings. The glue for these components is an intermediate representation (IR). The input question is mapped to IR using LLMs, which is then repaired into a valid relational database query with the aid of a semantic search on vector embeddings. This allows a practical synthesis of LLM capabilities and KG reliability. A short video demonstrating QirK is available at https://youtu.be/6c81BLmOZ0U.
Making LLMs Work for Enterprise Data Tasks
Jul 22, 2024Large language models (LLMs) know little about enterprise database tables in the private data ecosystem, which substantially differ from web text in structure and content. As LLMs' performance is tied to their training data, a crucial question is how useful they can be in improving enterprise database management and analysis tasks. To address this, we contribute experimental results on LLMs' performance for text-to-SQL and semantic column-type detection tasks on enterprise datasets. The performance of LLMs on enterprise data is significantly lower than on benchmark datasets commonly used. Informed by our findings and feedback from industry practitioners, we identify three fundamental challenges -- latency, cost, and quality -- and propose potential solutions to use LLMs in enterprise data workflows effectively.
CHORUS: Foundation Models for Unified Data Discovery and Exploration
Jun 16, 2023We explore the application of foundation models to data discovery and exploration tasks. Foundation models are large language models (LLMs) that show promising performance on a range of diverse tasks unrelated to their training. We show that these models are highly applicable to the data discovery and data exploration domain. When carefully used, they have superior capability on three representative tasks: table-class detection, column-type annotation and join-column prediction. On all three tasks, we show that a foundation-model-based approach outperforms the task-specific models and so the state of the art. Further, our approach often surpasses human-expert task performance. This suggests a future direction in which disparate data management tasks can be unified under foundation models.
Mining Robust Default Configurations for Resource-constrained AutoML
Feb 20, 2022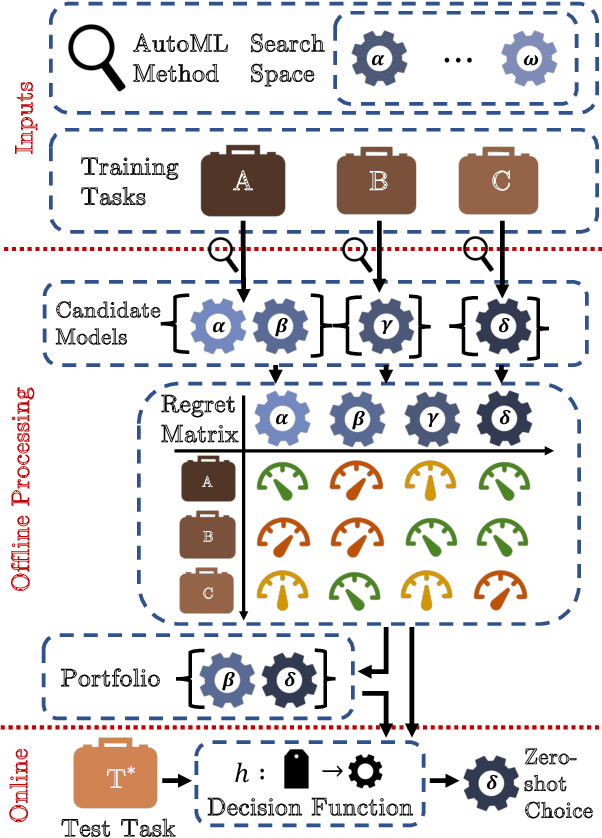
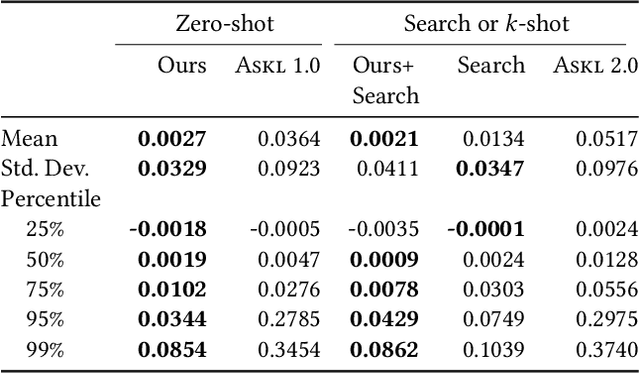
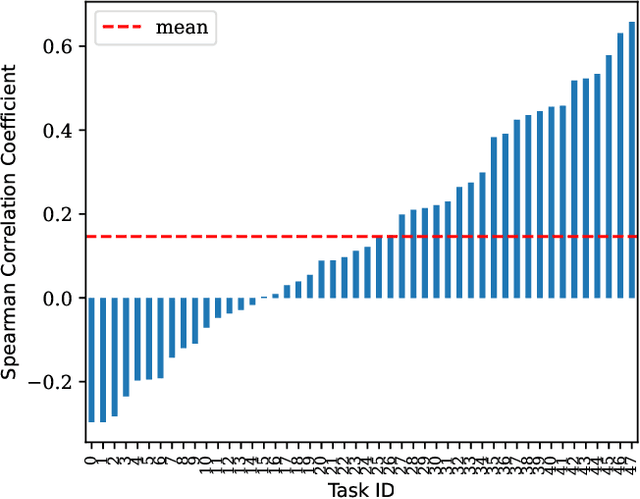
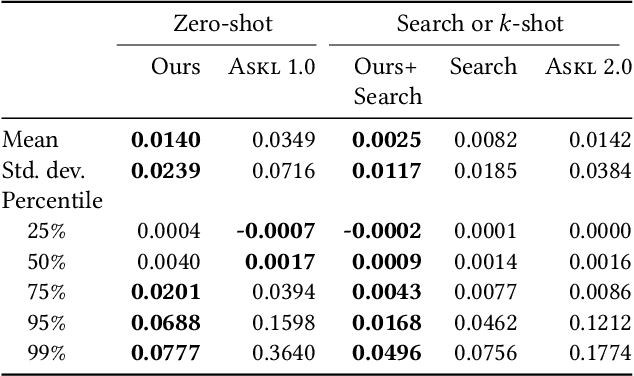
Automatic machine learning (AutoML) is a key enabler of the mass deployment of the next generation of machine learning systems. A key desideratum for future ML systems is the automatic selection of models and hyperparameters. We present a novel method of selecting performant configurations for a given task by performing offline autoML and mining over a diverse set of tasks. By mining the training tasks, we can select a compact portfolio of configurations that perform well over a wide variety of tasks, as well as learn a strategy to select portfolio configurations for yet-unseen tasks. The algorithm runs in a zero-shot manner, that is without training any models online except the chosen one. In a compute- or time-constrained setting, this virtually instant selection is highly performant. Further, we show that our approach is effective for warm-starting existing autoML platforms. In both settings, we demonstrate an improvement on the state-of-the-art by testing over 62 classification and regression datasets. We also demonstrate the utility of recommending data-dependent default configurations that outperform widely used hand-crafted defaults.
Causal Relational Learning
Apr 07, 2020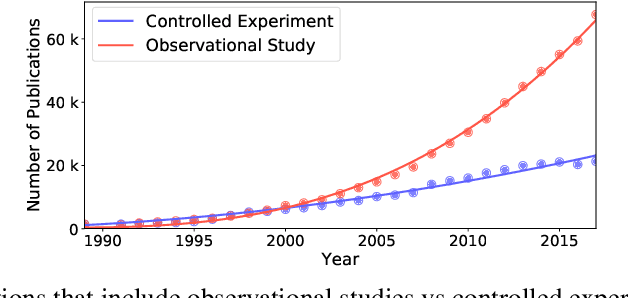



Causal inference is at the heart of empirical research in natural and social sciences and is critical for scientific discovery and informed decision making. The gold standard in causal inference is performing randomized controlled trials; unfortunately these are not always feasible due to ethical, legal, or cost constraints. As an alternative, methodologies for causal inference from observational data have been developed in statistical studies and social sciences. However, existing methods critically rely on restrictive assumptions such as the study population consisting of homogeneous elements that can be represented in a single flat table, where each row is referred to as a unit. In contrast, in many real-world settings, the study domain naturally consists of heterogeneous elements with complex relational structure, where the data is naturally represented in multiple related tables. In this paper, we present a formal framework for causal inference from such relational data. We propose a declarative language called CaRL for capturing causal background knowledge and assumptions and specifying causal queries using simple Datalog-like rules.CaRL provides a foundation for inferring causality and reasoning about the effect of complex interventions in relational domains. We present an extensive experimental evaluation on real relational data to illustrate the applicability of CaRL in social sciences and healthcare.