 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Optimization via Exact Augmented Lagrangian and Randomized Iterative Sketching
May 28, 2023



We consider solving equality-constrained nonlinear, nonconvex optimization problems. This class of problems appears widely in a variety of applications in machine learning and engineering, ranging from constrained deep neural networks, to optimal control, to PDE-constrained optimization. We develop an adaptive inexact Newton method for this problem class. In each iteration, we solve the Lagrangian Newton system inexactly via a randomized iterative sketching solver, and select a suitable stepsize by performing line search on an exact augmented Lagrangian merit function. The randomized solvers have advantages over deterministic linear system solvers by significantly reducing per-iteration flops complexity and storage cost, when equipped with suitable sketching matrices. Our method adaptively controls the accuracy of the randomized solver and the penalty parameters of the exact augmented Lagrangian, to ensure that the inexact Newton direction is a descent direction of the exact augmented Lagrangian. This allows us to establish a global almost sure convergence. We also show that a unit stepsize is admissible locally, so that our method exhibits a local linear convergence. Furthermore, we prove that the linear convergence can be strengthened to superlinear convergence if we gradually sharpen the adaptive accuracy condition on the randomized solver. We demonstrate the superior performance of our method on benchmark nonlinear problems in CUTEst test set, constrained logistic regression with data from LIBSVM, and a PDE-constrained problem.
* 25 pages, 4 figures
Fully Stochastic Trust-Region Sequential Quadratic Programming for Equality-Constrained Optimization Problems
Nov 29, 2022


We propose a trust-region stochastic sequential quadratic programming algorithm (TR-StoSQP) to solve nonlinear optimization problems with stochastic objectives and deterministic equality constraints. We consider a fully stochastic setting, where in each iteration a single sample is generated to estimate the objective gradient. The algorithm adaptively selects the trust-region radius and, compared to the existing line-search StoSQP schemes, allows us to employ indefinite Hessian matrices (i.e., Hessians without modification) in SQP subproblems. As a trust-region method for constrained optimization, our algorithm needs to address an infeasibility issue -- the linearized equality constraints and trust-region constraints might lead to infeasible SQP subproblems. In this regard, we propose an \textit{adaptive relaxation technique} to compute the trial step that consists of a normal step and a tangential step. To control the lengths of the two steps, we adaptively decompose the trust-region radius into two segments based on the proportions of the feasibility and optimality residuals to the full KKT residual. The normal step has a closed form, while the tangential step is solved from a trust-region subproblem, to which a solution ensuring the Cauchy reduction is sufficient for our study. We establish the global almost sure convergence guarantee for TR-StoSQP, and illustrate its empirical performance on both a subset of problems in the CUTEst test set and constrained logistic regression problems using data from the LIBSVM collection.
Latent Multimodal Functional Graphical Model Estimation
Oct 31, 2022Joint multimodal functional data acquisition, where functional data from multiple modes are measured simultaneously from the same subject, has emerged as an exciting modern approach enabled by recent engineering breakthroughs in the neurological and biological sciences. One prominent motivation to acquire such data is to enable new discoveries of the underlying connectivity by combining multimodal signals. Despite the scientific interest, there remains a gap in principled statistical methods for estimating the graph underlying multimodal functional data. To this end, we propose a new integrative framework that models the data generation process and identifies operators mapping from the observation space to the latent space. We then develop an estimator that simultaneously estimates the transformation operators and the latent graph. This estimator is based on the partial correlation operator, which we rigorously extend from the multivariate to the functional setting. Our procedure is provably efficient, with the estimator converging to a stationary point with quantifiable statistical error. Furthermore, we show recovery of the latent graph under mild conditions. Our work is applied to analyze simultaneously acquired multimodal brain imaging data where the graph indicates functional connectivity of the brain. We present simulation and empirical results that support the benefits of joint estimation.
One Policy is Enough: Parallel Exploration with a Single Policy is Minimax Optimal for Reward-Free Reinforcement Learning
May 31, 2022While parallelism has been extensively used in Reinforcement Learning (RL), the quantitative effects of parallel exploration are not well understood theoretically. We study the benefits of simple parallel exploration for reward-free RL for linear Markov decision processes (MDPs) and two-player zero-sum Markov games (MGs). In contrast to the existing literature focused on approaches that encourage agents to explore over a diverse set of policies, we show that using a single policy to guide exploration across all agents is sufficient to obtain an almost-linear speedup in all cases compared to their fully sequential counterpart. Further, we show that this simple procedure is minimax optimal up to logarithmic factors in the reward-free setting for both linear MDPs and two-player zero-sum MGs. From a practical perspective, our paper shows that a single policy is sufficient and provably optimal for incorporating parallelism during the exploration phase.
Pessimism meets VCG: Learning Dynamic Mechanism Design via Offline Reinforcement Learning
May 05, 2022Dynamic mechanism design has garnered significant attention from both computer scientists and economists in recent years. By allowing agents to interact with the seller over multiple rounds, where agents' reward functions may change with time and are state dependent, the framework is able to model a rich class of real world problems. In these works, the interaction between agents and sellers are often assumed to follow a Markov Decision Process (MDP). We focus on the setting where the reward and transition functions of such an MDP are not known a priori, and we are attempting to recover the optimal mechanism using an a priori collected data set. In the setting where the function approximation is employed to handle large state spaces, with only mild assumptions on the expressiveness of the function class, we are able to design a dynamic mechanism using offline reinforcement learning algorithms. Moreover, learned mechanisms approximately have three key desiderata: efficiency, individual rationality, and truthfulness. Our algorithm is based on the pessimism principle and only requires a mild assumption on the coverage of the offline data set. To the best of our knowledge, our work provides the first offline RL algorithm for dynamic mechanism design without assuming uniform coverage.
Personalized Federated Learning with Multiple Known Clusters
Apr 28, 2022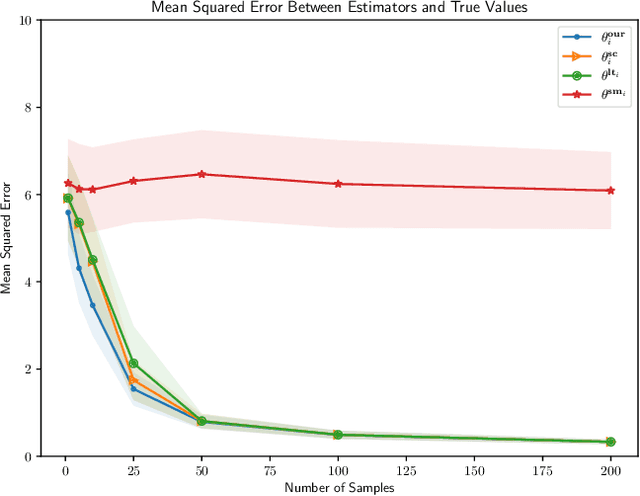
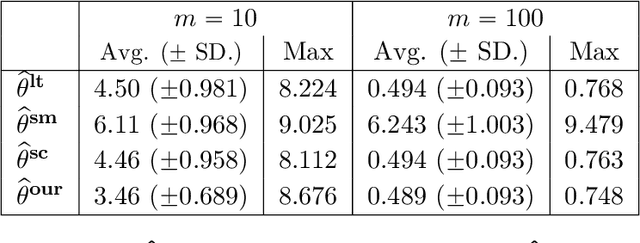
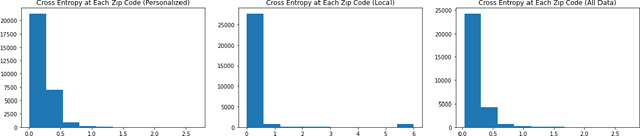
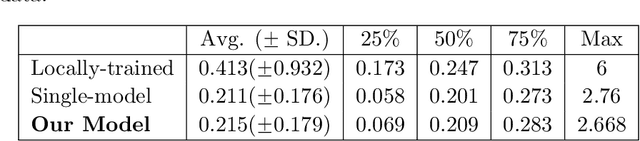
We consider the problem of personalized federated learning when there are known cluster structures within users. An intuitive approach would be to regularize the parameters so that users in the same cluster share similar model weights. The distances between the clusters can then be regularized to reflect the similarity between different clusters of users. We develop an algorithm that allows each cluster to communicate independently and derive the convergence results. We study a hierarchical linear model to theoretically demonstrate that our approach outperforms agents learning independently and agents learning a single shared weight. Finally, we demonstrate the advantages of our approach using both simulated and real-world data.
L-SVRG and L-Katyusha with Adaptive Sampling
Jan 31, 2022



Stochastic gradient-based optimization methods, such as L-SVRG and its accelerated variant L-Katyusha [12], are widely used to train machine learning models. Theoretical and empirical performance of L-SVRG and L-Katyusha can be improved by sampling the observations from a non-uniform distribution [17]. However, to design a desired sampling distribution, Qian et al.[17] rely on prior knowledge of smoothness constants that can be computationally intractable to obtain in practice when the dimension of the model parameter is high. We propose an adaptive sampling strategy for L-SVRG and L-Katyusha that learns the sampling distribution with little computational overhead, while allowing it to change with iterates, and at the same time does not require any prior knowledge on the problem parameters. We prove convergence guarantees for L-SVRG and L-Katyusha for convex objectives when the sampling distribution changes with iterates. These results show that even without prior information, the proposed adaptive sampling strategy matches, and in some cases even surpasses, the performance of the sampling scheme in Qian et al.[17]. Extensive simulations support our theory and the practical utility of the proposed sampling scheme on real data.
Adaptive Client Sampling in Federated Learning via Online Learning with Bandit Feedback
Dec 28, 2021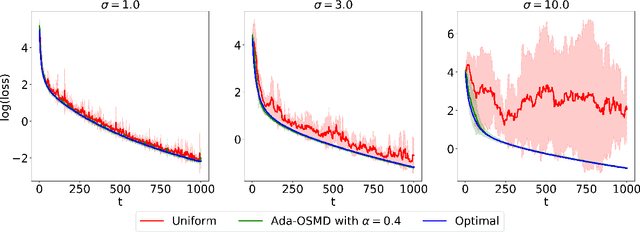
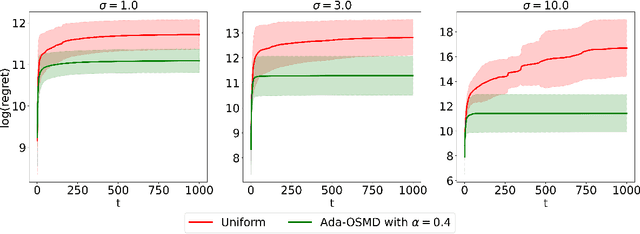
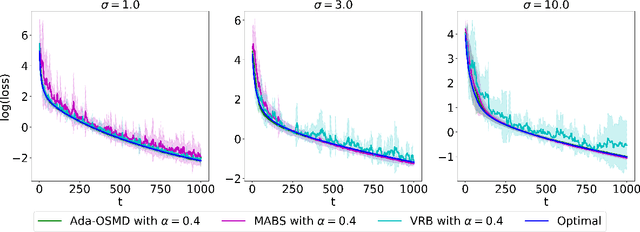
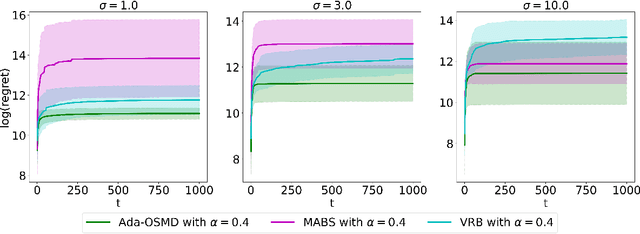
In federated learning (FL) problems, client sampling plays a key role in the convergence speed of training algorithm. However, while being an important problem in FL, client sampling is lack of study. In this paper, we propose an online learning with bandit feedback framework to understand the client sampling problem in FL. By adapting an Online Stochastic Mirror Descent algorithm to minimize the variance of gradient estimation, we propose a new adaptive client sampling algorithm. Besides, we use online ensemble method and doubling trick to automatically choose the tuning parameters in the algorithm. Theoretically, we show dynamic regret bound with comparator as the theoretically optimal sampling sequence; we also include the total variation of this sequence in our upper bound, which is a natural measure of the intrinsic difficulty of the problem. To the best of our knowledge, these theoretical contributions are novel to existing literature. Moreover, by implementing both synthetic and real data experiments, we show empirical evidence of the advantages of our proposed algorithms over widely-used uniform sampling and also other online learning based sampling strategies in previous studies. We also examine its robustness to the choice of tuning parameters. Finally, we discuss its possible extension to sampling without replacement and personalized FL objective. While the original goal is to solve client sampling problem, this work has more general applications on stochastic gradient descent and stochastic coordinate descent methods.
Dynamic Regret Minimization for Control of Non-stationary Linear Dynamical Systems
Nov 06, 2021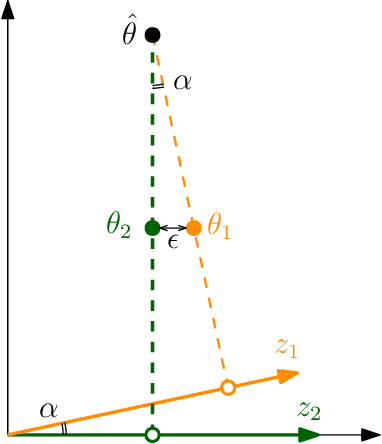
We consider the problem of controlling a Linear Quadratic Regulator (LQR) system over a finite horizon $T$ with fixed and known cost matrices $Q,R$, but unknown and non-stationary dynamics $\{A_t, B_t\}$. The sequence of dynamics matrices can be arbitrary, but with a total variation, $V_T$, assumed to be $o(T)$ and unknown to the controller. Under the assumption that a sequence of stabilizing, but potentially sub-optimal controllers is available for all $t$, we present an algorithm that achieves the optimal dynamic regret of $\tilde{\mathcal{O}}\left(V_T^{2/5}T^{3/5}\right)$. With piece-wise constant dynamics, our algorithm achieves the optimal regret of $\tilde{\mathcal{O}}(\sqrt{ST})$ where $S$ is the number of switches. The crux of our algorithm is an adaptive non-stationarity detection strategy, which builds on an approach recently developed for contextual Multi-armed Bandit problems. We also argue that non-adaptive forgetting (e.g., restarting or using sliding window learning with a static window size) may not be regret optimal for the LQR problem, even when the window size is optimally tuned with the knowledge of $V_T$. The main technical challenge in the analysis of our algorithm is to prove that the ordinary least squares (OLS) estimator has a small bias when the parameter to be estimated is non-stationary. Our analysis also highlights that the key motif driving the regret is that the LQR problem is in spirit a bandit problem with linear feedback and locally quadratic cost. This motif is more universal than the LQR problem itself, and therefore we believe our results should find wider application.
Joint Gaussian Graphical Model Estimation: A Survey
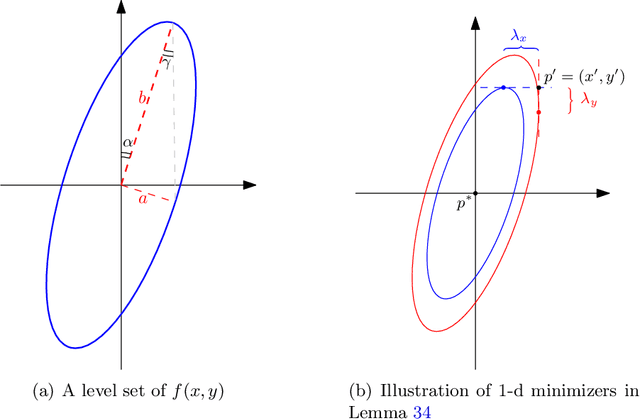
Oct 19, 2021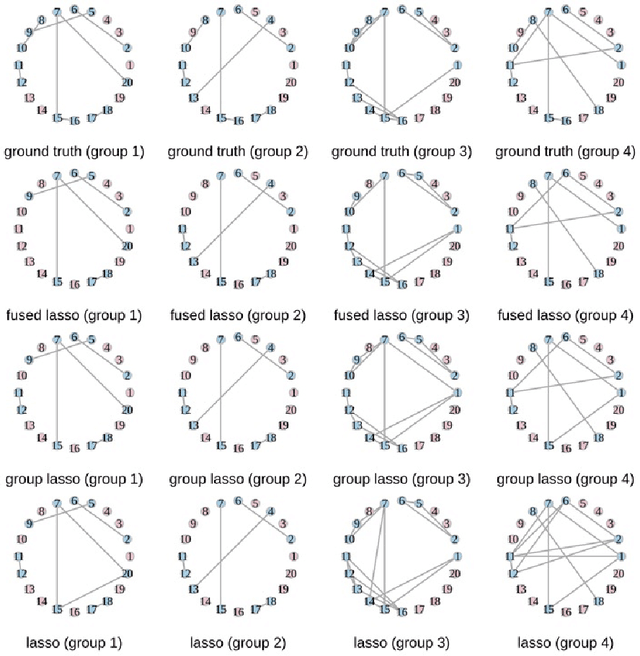
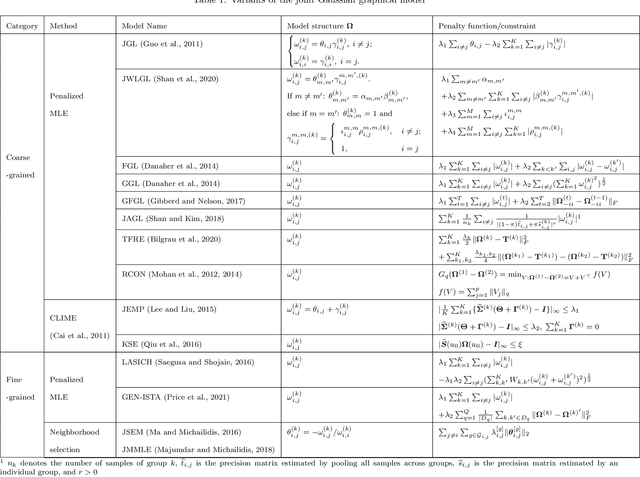
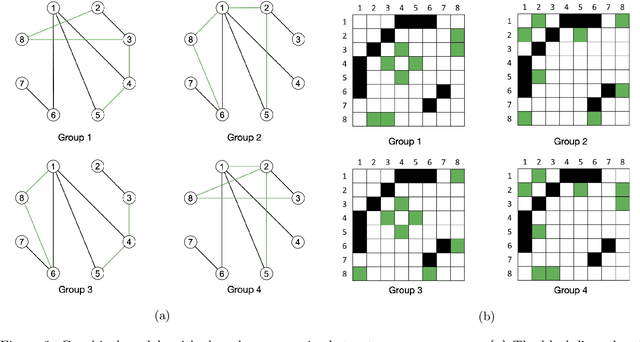

Graphs from complex systems often share a partial underlying structure across domains while retaining individual features. Thus, identifying common structures can shed light on the underlying signal, for instance, when applied to scientific discoveries or clinical diagnoses. Furthermore, growing evidence shows that the shared structure across domains boosts the estimation power of graphs, particularly for high-dimensional data. However, building a joint estimator to extract the common structure may be more complicated than it seems, most often due to data heterogeneity across sources. This manuscript surveys recent work on statistical inference of joint Gaussian graphical models, identifying model structures that fit various data generation processes. Simulations under different data generation processes are implemented with detailed discussions on the choice of models.