 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-to-text Generation with Macro Planning
Feb 04, 2021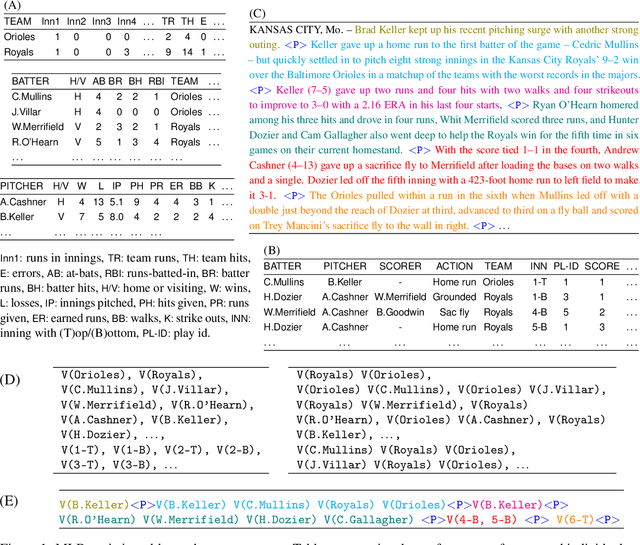
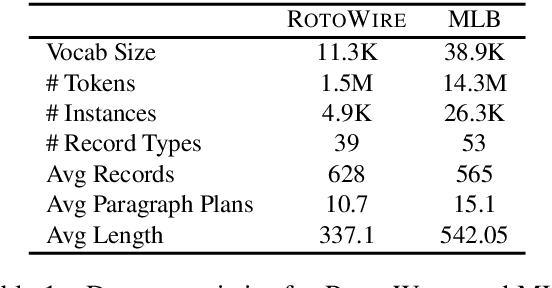
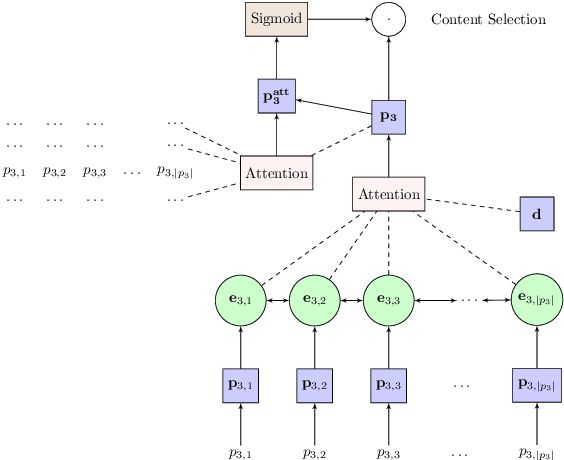
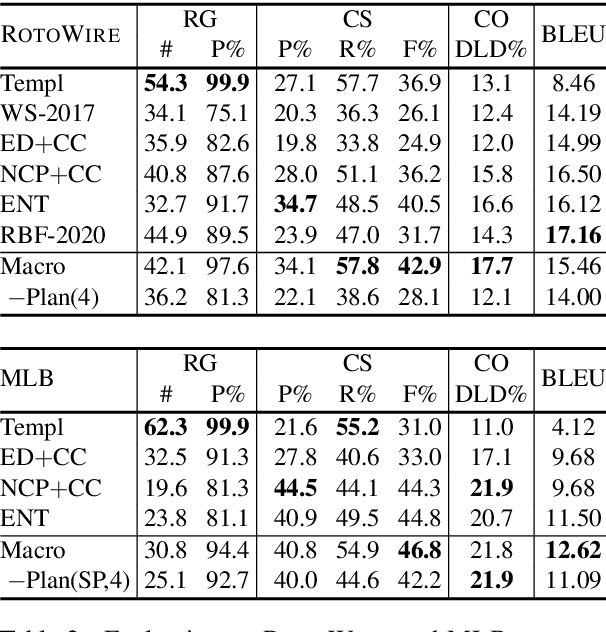
Recent approaches to data-to-text generation have adopted the very successful encoder-decoder architecture or variants thereof. These models generate text which is fluent (but often imprecise) and perform quite poorly at selecting appropriate content and ordering it coherently. To overcome some of these issues, we propose a neural model with a macro planning stage followed by a generation stage reminiscent of traditional methods which embrace separate modules for planning and surface realization. Macro plans represent high level organization of important content such as entities, events and their interactions; they are learnt from data and given as input to the generator. Extensive experiments on two data-to-text benchmarks (RotoWire and MLB) show that our approach outperforms competitive baselines in terms of automatic and human evaluation.
Abstractive Query Focused Summarization with Query-Free Resources
Dec 29, 2020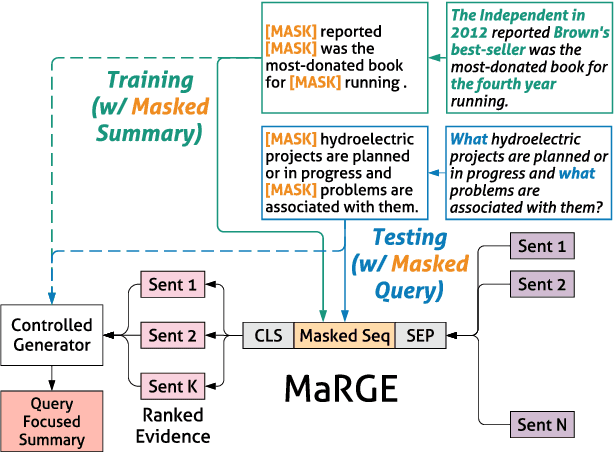
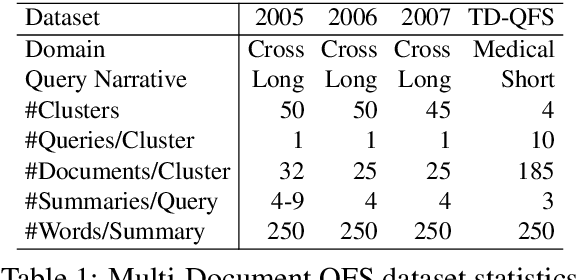
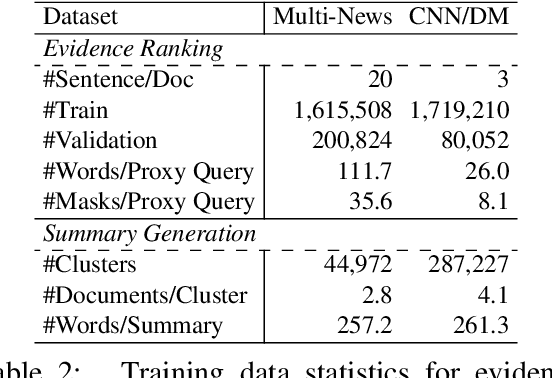
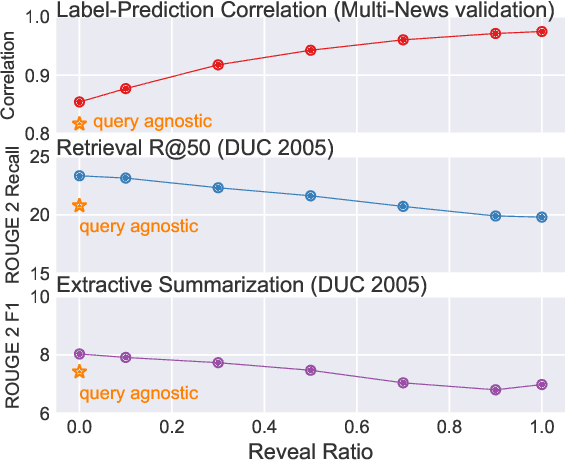
The availability of large-scale datasets has driven the development of neural sequence-to-sequence models to generate generic summaries, i.e., summaries which do not correspond to any pre-specified queries. However, due to the lack of training data, query focused summarization (QFS) has been studied mainly with extractive methods. In this work, we consider the problem of leveraging only generic summarization resources to build an abstractive QFS system. We propose Marge, a Masked ROUGE Regression framework composed of a novel unified representation for summaries and queries, and a distantly supervised training task for answer evidence estimation. To further utilize generic data for generation, three attributes are incorporated during training and inference to control the shape of the final summary: evidence rank, query guidance, and summary length. Despite learning from minimal supervision, our system achieves state-of-the-art results in the distantly supervised setting across domains and query types.
Unsupervised Opinion Summarization with Content Planning
Dec 14, 2020
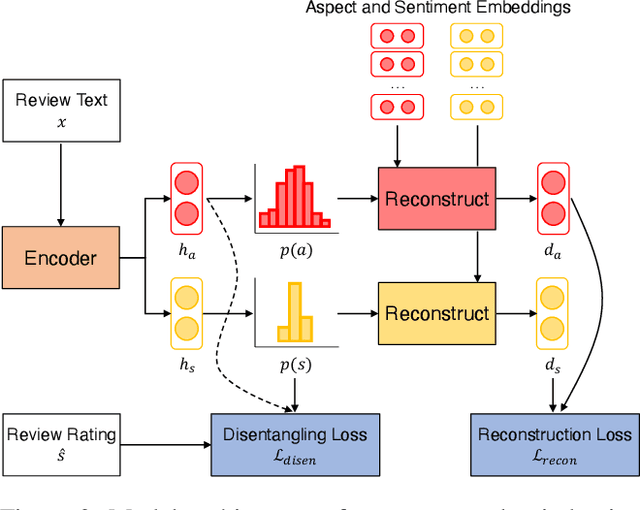
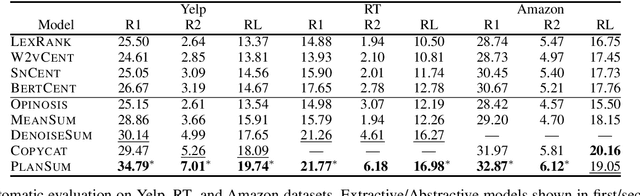
The recent success of deep learning techniques for abstractive summarization is predicated on the availability of large-scale datasets. When summarizing reviews (e.g., for products or movies), such training data is neither available nor can be easily sourced, motivating the development of methods which rely on synthetic datasets for supervised training. We show that explicitly incorporating content planning in a summarization model not only yields output of higher quality, but also allows the creation of synthetic datasets which are more natural, resembling real world document-summary pairs. Our content plans take the form of aspect and sentiment distributions which we induce from data without access to expensive annotations. Synthetic datasets are created by sampling pseudo-reviews from a Dirichlet distribution parametrized by our content planner, while our model generates summaries based on input reviews and induced content plans. Experimental results on three domains show that our approach outperforms competitive models in generating informative, coherent, and fluent summaries that capture opinion consensus.
Movie Summarization via Sparse Graph Construction
Dec 14, 2020
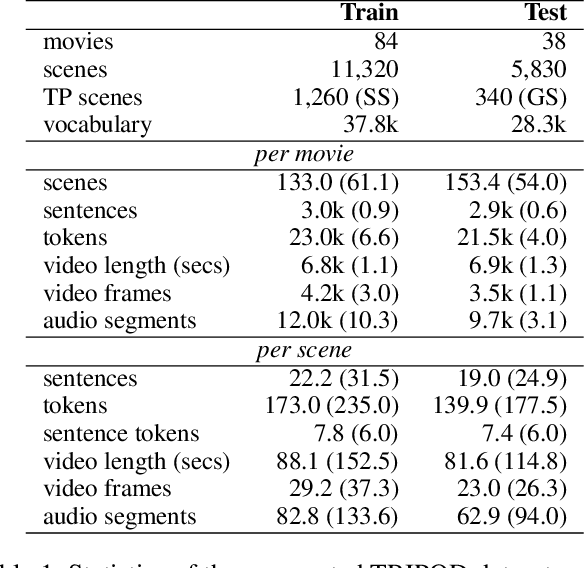
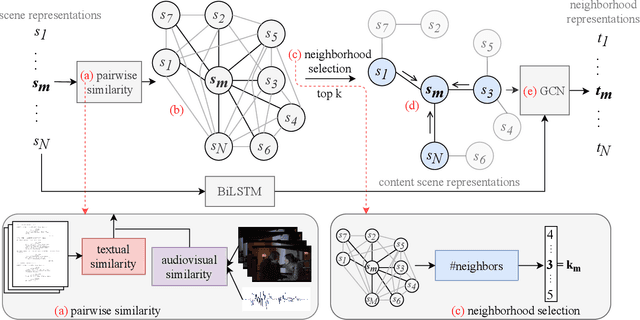
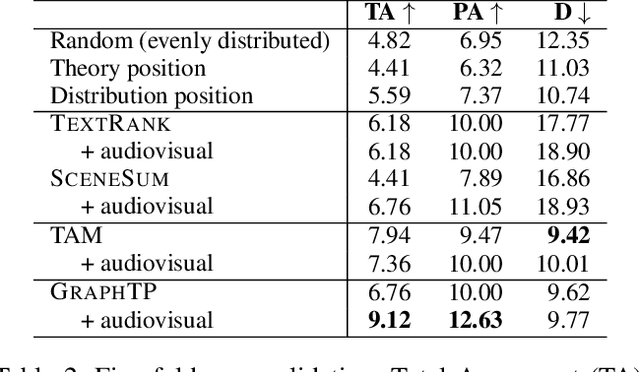
We summarize full-length movies by creating shorter videos containing their most informative scenes. We explore the hypothesis that a summary can be created by assembling scenes which are turning points (TPs), i.e., key events in a movie that describe its storyline. We propose a model that identifies TP scenes by building a sparse movie graph that represents relations between scenes and is constructed using multimodal information. According to human judges, the summaries created by our approach are more informative and complete, and receive higher ratings, than the outputs of sequence-based models and general-purpose summarization algorithms. The induced graphs are interpretable, displaying different topology for different movie genres.
Extractive Opinion Summarization in Quantized Transformer Spaces
Dec 08, 2020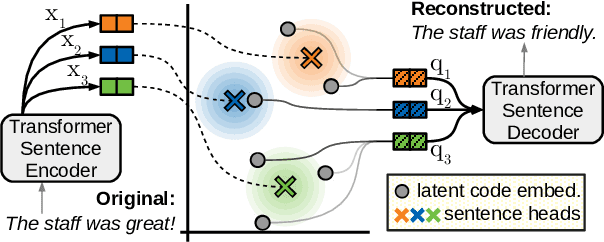

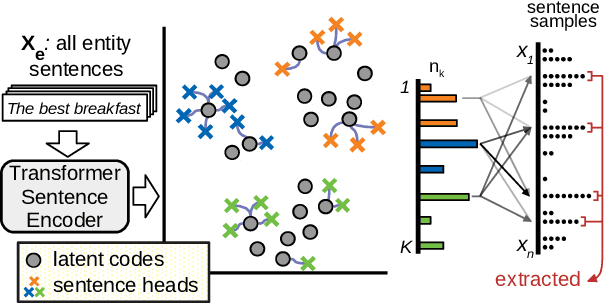
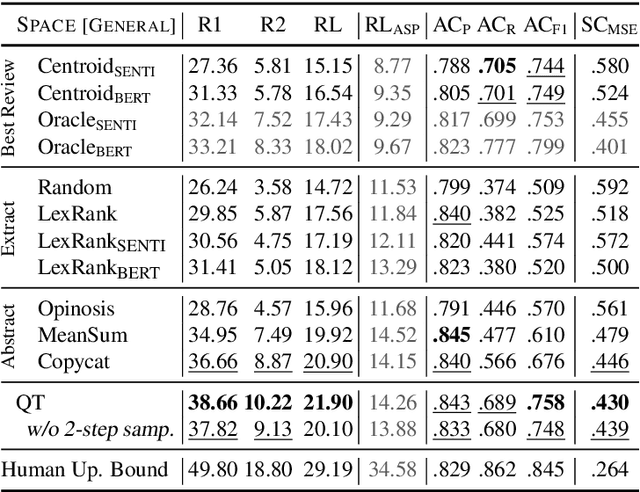
We present the Quantized Transformer (QT), an unsupervised system for extractive opinion summarization. QT is inspired by Vector-Quantized Variational Autoencoders, which we repurpose for popularity-driven summarization. It uses a clustering interpretation of the quantized space and a novel extraction algorithm to discover popular opinions among hundreds of reviews, a significant step towards opinion summarization of practical scope. In addition, QT enables controllable summarization without further training, by utilizing properties of the quantized space to extract aspect-specific summaries. We also make publicly available SPACE, a large-scale evaluation benchmark for opinion summarizers, comprising general and aspect-specific summaries for 50 hotels. Experiments demonstrate the promise of our approach, which is validated by human studies where judges showed clear preference for our method over competitive baselines.
Meta-Learning for Domain Generalization in Semantic Parsing
Oct 22, 2020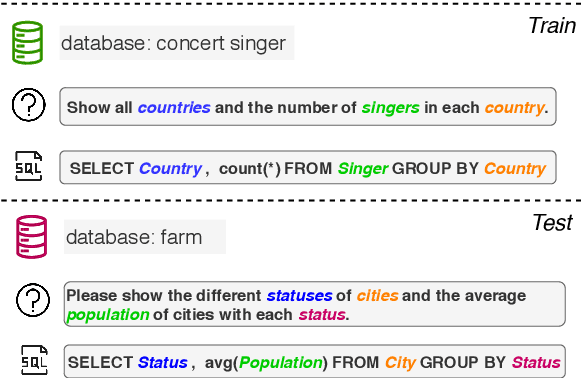
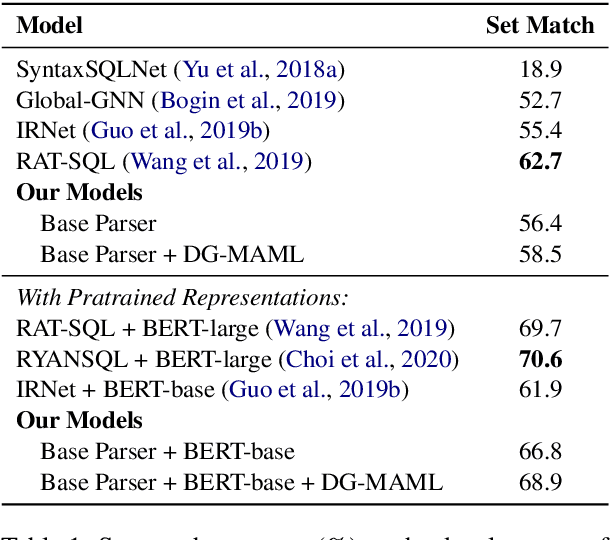
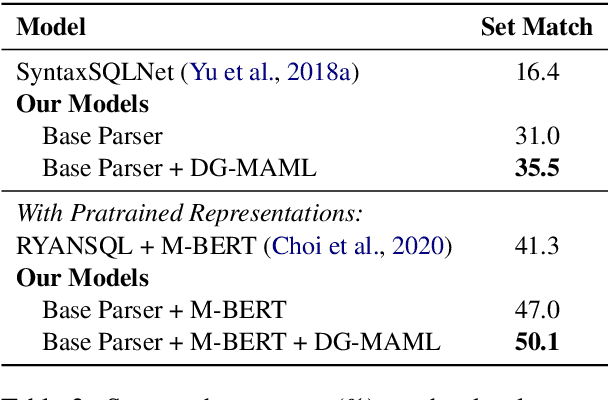
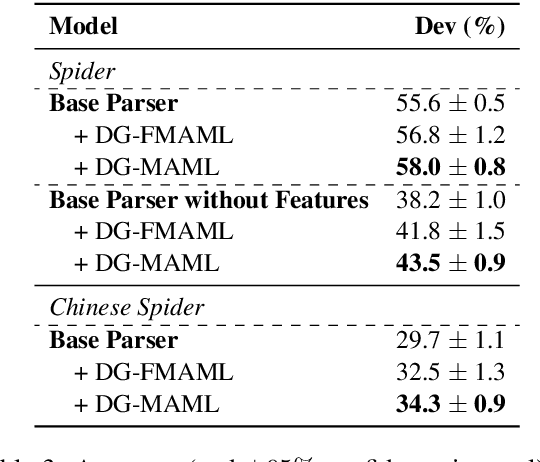
The importance of building semantic parsers which can be applied to new domains and generate programs unseen at training has long been acknowledged, and datasets testing out-of-domain performance are becoming increasingly available. However, little or no attention has been devoted to studying learning algorithms or objectives which promote domain generalization, with virtually all existing approaches relying on standard supervised learning. In this work, we use a meta-learning framework which targets specifically zero-shot domain generalization for semantic parsing. We apply a model-agnostic training algorithm that simulates zero-shot parsing by constructing virtual train and test sets from disjoint domains. The learning objective capitalizes on the intuition that gradient steps that improve source-domain performance should also improve target-domain performance, thus encouraging a parser to generalize well to unseen target domains. Experimental results on the (English) Spider and Chinese Spider datasets show that the meta-learning objective significantly boosts the performance of a baseline parser.
Compositional Generalization via Semantic Tagging
Oct 22, 2020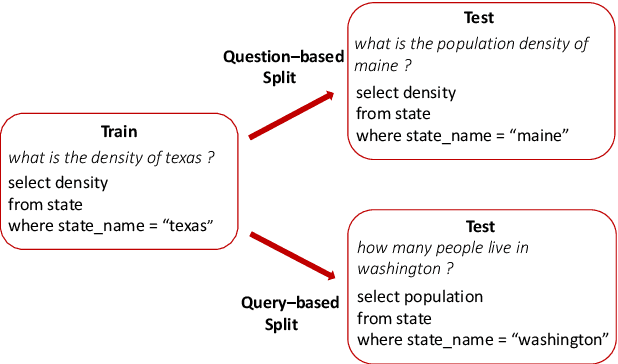

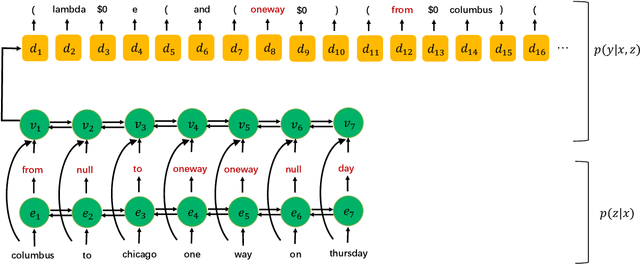
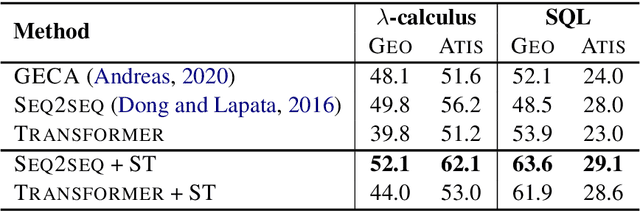
Although neural sequence-to-sequence models have been successfully applied to semantic parsing, they struggle to perform well on query-based data splits that require \emph{composition generalization}, an ability of systematically generalizing to unseen composition of seen components. Motivated by the explicitly built-in compositionality in traditional statistical semantic parsing, we propose a new decoding framework that preserves the expressivity and generality of sequence-to-sequence models while featuring explicit lexicon-style alignments and disentangled information processing. Specifically, we decompose decoding into two phases where an input utterance is first tagged with semantic symbols representing the meanings of its individual words, and then a sequence-to-sequence model is used to predict the final meaning representation conditioning on the utterance and the predicted tag sequence. Experimental results on three semantic parsing datasets with query-based splits show that the proposed approach consistently improves compositional generalization of sequence-to-sequence models across different model architectures, domains and semantic formalisms.
Noisy Self-Knowledge Distillation for Text Summarization
Sep 15, 2020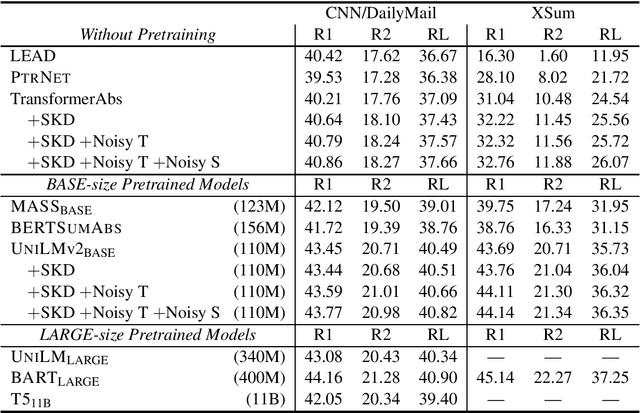
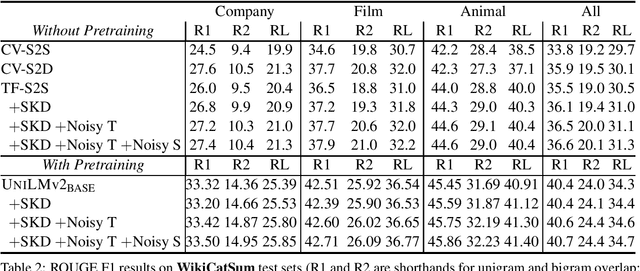
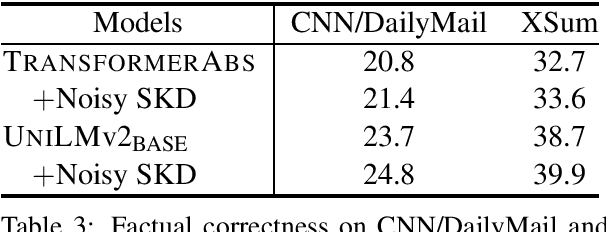

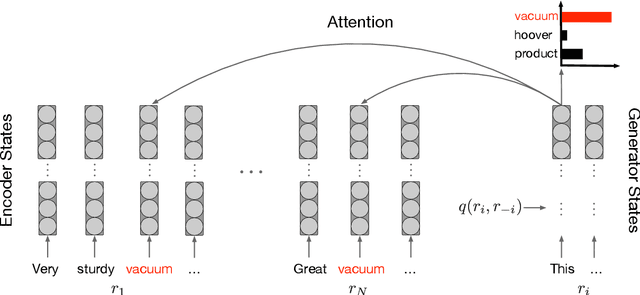
In this paper we apply self-knowledge distillation to text summarization which we argue can alleviate problems with maximum-likelihood training on single reference and noisy datasets. Instead of relying on one-hot annotation labels, our student summarization model is trained with guidance from a teacher which generates smoothed labels to help regularize training. Furthermore, to better model uncertainty during training, we introduce multiple noise signals for both teacher and student models. We demonstrate experimentally on three benchmarks that our framework boosts the performance of both pretrained and non-pretrained summarizers achieving state-of-the-art results.
Few-Shot Learning for Abstractive Multi-Document Opinion Summarization
Apr 30, 2020
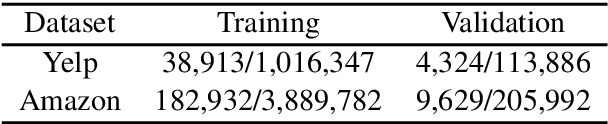
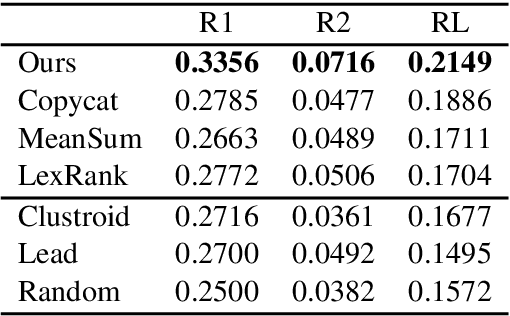
Opinion summarization is an automatic creation of text reflecting subjective information expressed in multiple documents, such as user reviews of a product. The task is practically important and has attracted a lot of attention. However, due to a high cost of summary production, datasets large enough for training supervised models are lacking. Instead, the task has been traditionally approached with extractive methods that learn to select text fragments in an unsupervised or weakly-supervised way. Recently, it has been shown that abstractive summaries, potentially more fluent and better at reflecting conflicting information, can also be produced in an unsupervised fashion. However, these models, not being exposed to the actual summaries, fail to capture their essential properties. In this work, we show that even a handful of summaries is sufficient to bootstrap generation of the summary text with all expected properties, such as writing style, informativeness, fluency, and sentiment preservation. We start by training a language model to generate a new product review given available reviews of the product. The model is aware of the properties: it proceeds with first generating property values and then producing a review conditioned on them. We do not use any summaries in this stage and the property values are derived from reviews with no manual effort. In the second stage, we fine-tune the module predicting the property values on a few available summaries. This lets us switch the generator to the summarization mode. Our approach substantially outperforms previous extractive and abstractive methods in automatic and human evaluation.
Screenplay Summarization Using Latent Narrative Structure
Apr 27, 2020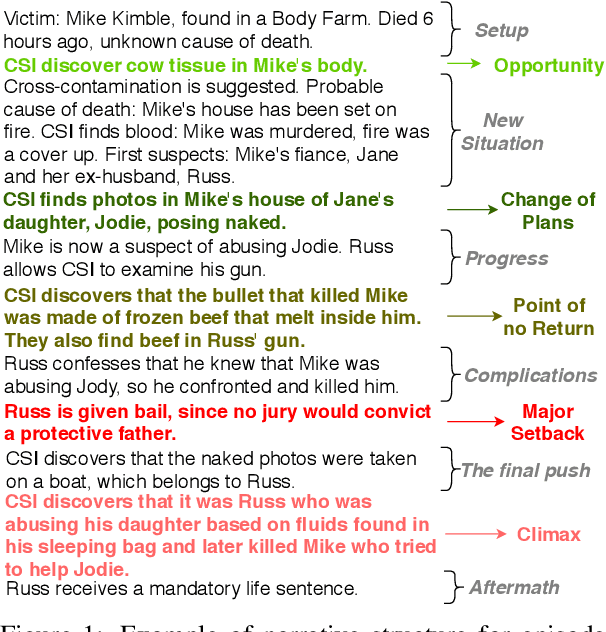

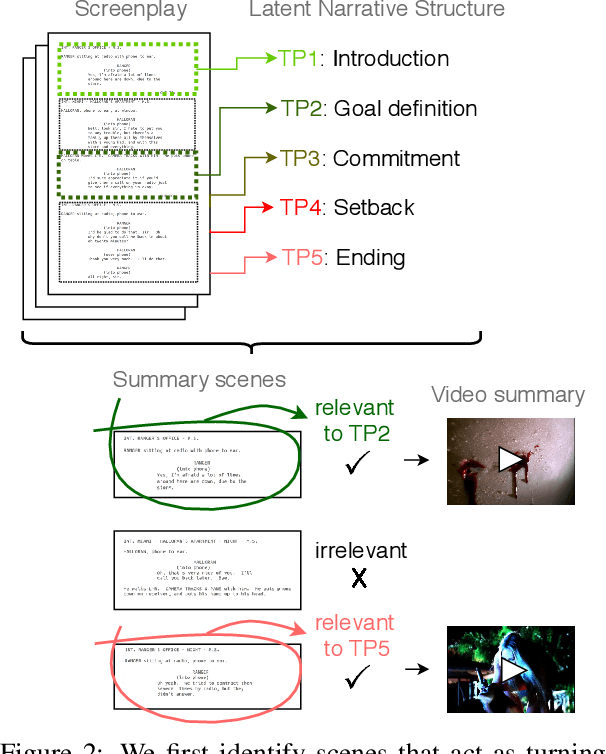
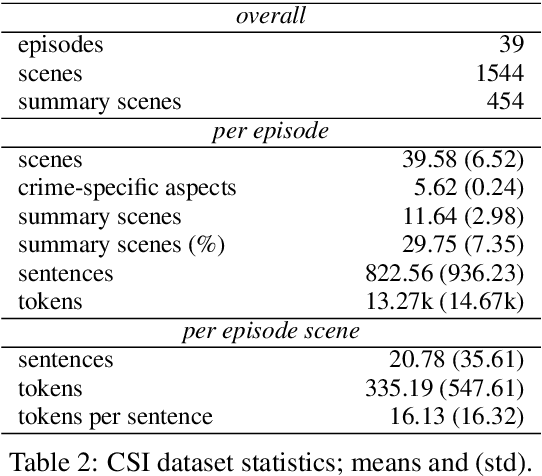
Most general-purpose extractive summarization models are trained on news articles, which are short and present all important information upfront. As a result, such models are biased on position and often perform a smart selection of sentences from the beginning of the document. When summarizing long narratives, which have complex structure and present information piecemeal, simple position heuristics are not sufficient. In this paper, we propose to explicitly incorporate the underlying structure of narratives into general unsupervised and supervised extractive summarization models. We formalize narrative structure in terms of key narrative events (turning points) and treat it as latent in order to summarize screenplays (i.e., extract an optimal sequence of scenes). Experimental results on the CSI corpus of TV screenplays, which we augment with scene-level summarization labels, show that latent turning points correlate with important aspects of a CSI episode and improve summarization performance over general extractive algorithms leading to more complete and diverse summaries.