 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical3D Adapters for Long Video-to-text Summarization
Oct 10, 2022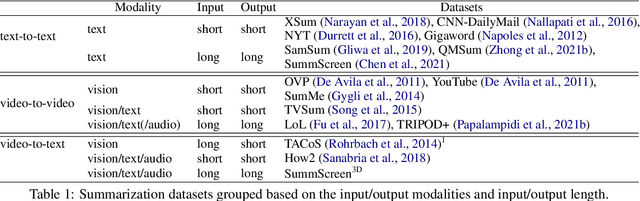
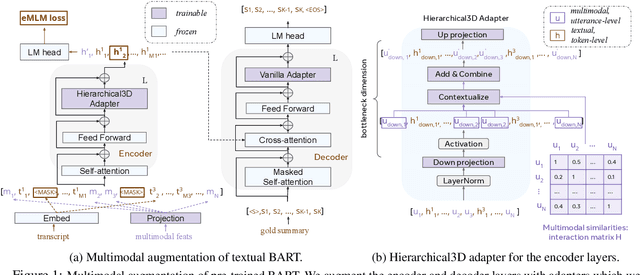
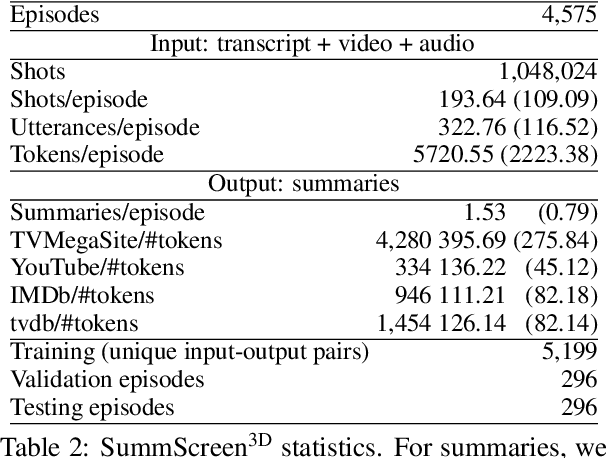
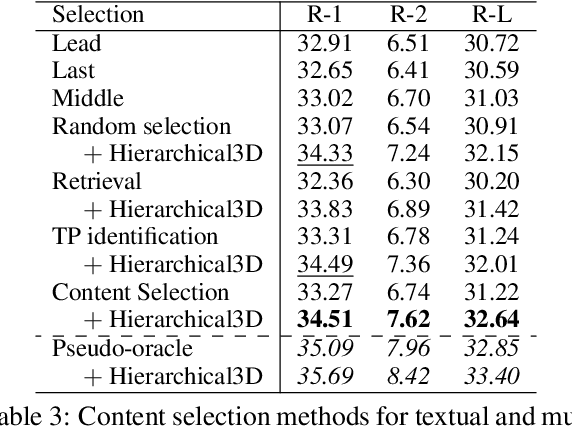
In this paper, we focus on video-to-text summarization and investigate how to best utilize multimodal information for summarizing long inputs (e.g., an hour-long TV show) into long outputs (e.g., a multi-sentence summary). We extend SummScreen (Chen et al., 2021), a dialogue summarization dataset consisting of transcripts of TV episodes with reference summaries, and create a multimodal variant by collecting corresponding full-length videos. We incorporate multimodal information into a pre-trained textual summarizer efficiently using adapter modules augmented with a hierarchical structure while tuning only 3.8\% of model parameters. Our experiments demonstrate that multimodal information offers superior performance over more memory-heavy and fully fine-tuned textual summarization methods.
Explainable Abuse Detection as Intent Classification and Slot Filling
Oct 06, 2022

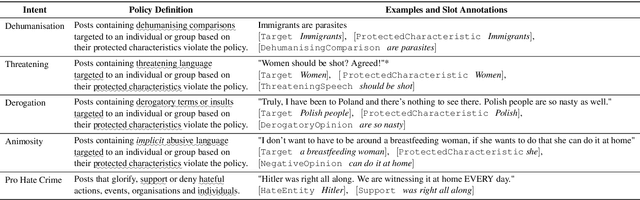
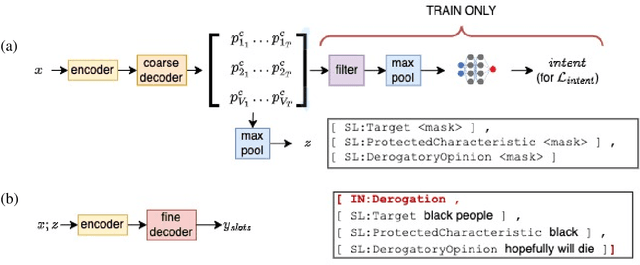
To proactively offer social media users a safe online experience, there is a need for systems that can detect harmful posts and promptly alert platform moderators. In order to guarantee the enforcement of a consistent policy, moderators are provided with detailed guidelines. In contrast, most state-of-the-art models learn what abuse is from labelled examples and as a result base their predictions on spurious cues, such as the presence of group identifiers, which can be unreliable. In this work we introduce the concept of policy-aware abuse detection, abandoning the unrealistic expectation that systems can reliably learn which phenomena constitute abuse from inspecting the data alone. We propose a machine-friendly representation of the policy that moderators wish to enforce, by breaking it down into a collection of intents and slots. We collect and annotate a dataset of 3,535 English posts with such slots, and show how architectures for intent classification and slot filling can be used for abuse detection, while providing a rationale for model decisions.
Meta-Learning a Cross-lingual Manifold for Semantic Parsing
Sep 27, 2022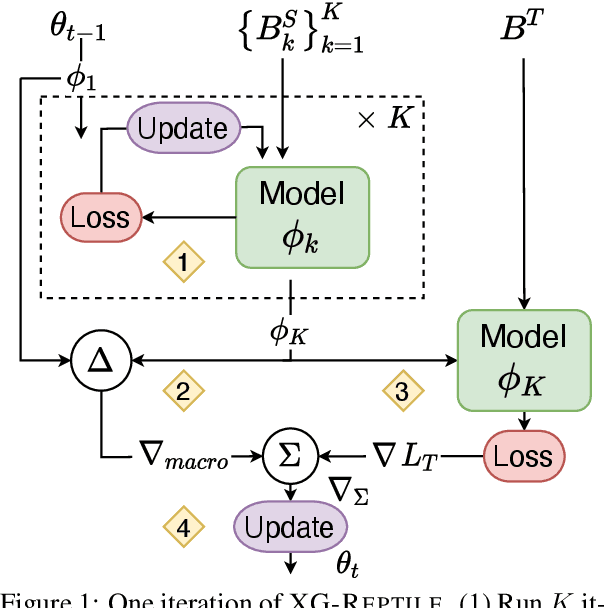

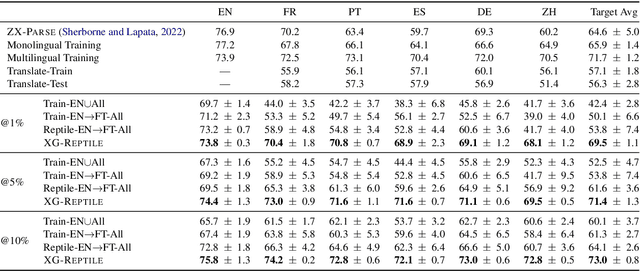
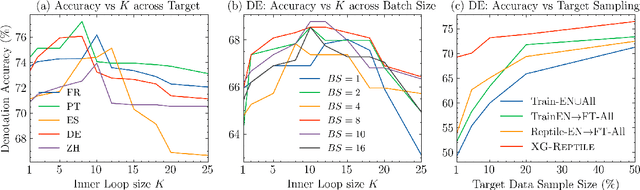
Localizing a semantic parser to support new languages requires effective cross-lingual generalization. Recent work has found success with machine-translation or zero-shot methods although these approaches can struggle to model how native speakers ask questions. We consider how to effectively leverage minimal annotated examples in new languages for few-shot cross-lingual semantic parsing. We introduce a first-order meta-learning algorithm to train a semantic parser with maximal sample efficiency during cross-lingual transfer. Our algorithm uses high-resource languages to train the parser and simultaneously optimizes for cross-lingual generalization for lower-resource languages. Results across six languages on ATIS demonstrate that our combination of generalization steps yields accurate semantic parsers sampling $\le$10% of source training data in each new language. Our approach also trains a competitive model on Spider using English with generalization to Chinese similarly sampling $\le$10% of training data.
Text Summarization with Oracle Expectation
Sep 26, 2022
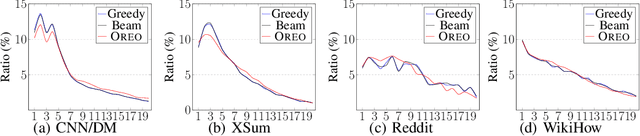
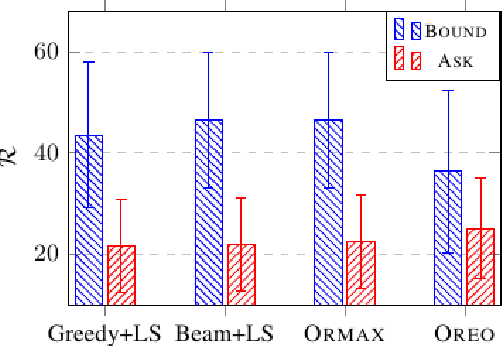
Extractive summarization produces summaries by identifying and concatenating the most important sentences in a document. Since most summarization datasets do not come with gold labels indicating whether document sentences are summary-worthy, different labeling algorithms have been proposed to extrapolate oracle extracts for model training. In this work, we identify two flaws with the widely used greedy labeling approach: it delivers suboptimal and deterministic oracles. To alleviate both issues, we propose a simple yet effective labeling algorithm that creates soft, expectation-based sentence labels. We define a new learning objective for extractive summarization which incorporates learning signals from multiple oracle summaries and prove it is equivalent to estimating the oracle expectation for each document sentence. Without any architectural modifications, the proposed labeling scheme achieves superior performance on a variety of summarization benchmarks across domains and languages, in both supervised and zero-shot settings.
Conditional Generation with a Question-Answering Blueprint
Jul 01, 2022
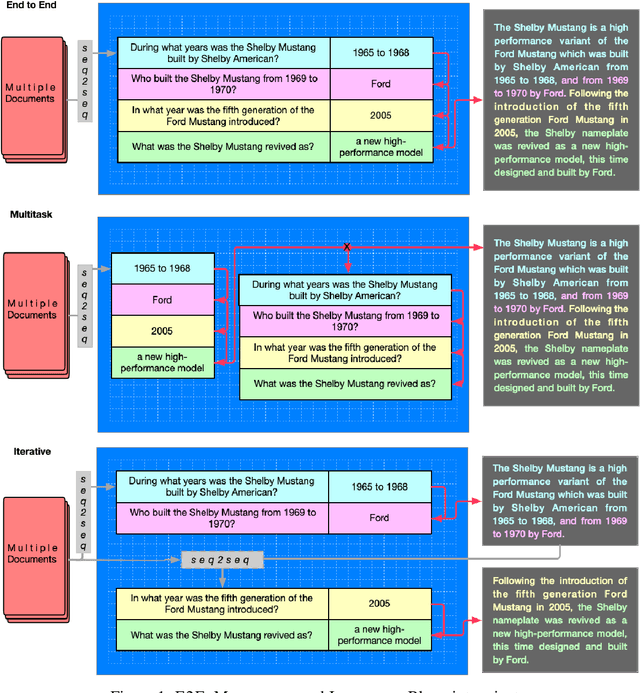
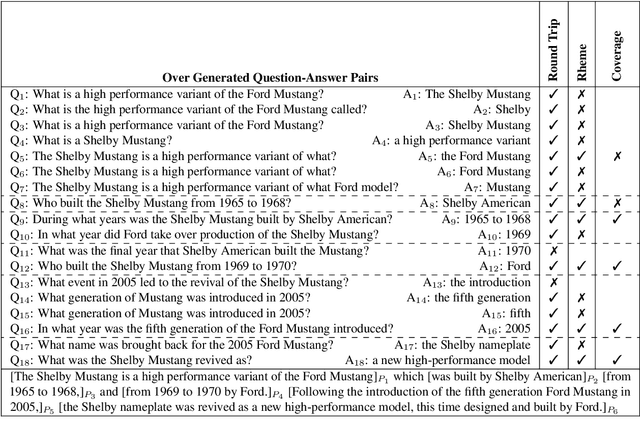
The ability to convey relevant and faithful information is critical for many tasks in conditional generation and yet remains elusive for neural seq-to-seq models whose outputs often reveal hallucinations and fail to correctly cover important details. In this work, we advocate planning as a useful intermediate representation for rendering conditional generation less opaque and more grounded. Our work proposes a new conceptualization of text plans as a sequence of question-answer (QA) pairs. We enhance existing datasets (e.g., for summarization) with a QA blueprint operating as a proxy for both content selection (i.e.,~what to say) and planning (i.e.,~in what order). We obtain blueprints automatically by exploiting state-of-the-art question generation technology and convert input-output pairs into input-blueprint-output tuples. We develop Transformer-based models, each varying in how they incorporate the blueprint in the generated output (e.g., as a global plan or iteratively). Evaluation across metrics and datasets demonstrates that blueprint models are more factual than alternatives which do not resort to planning and allow tighter control of the generation output.
Latent Topology Induction for Understanding Contextualized Representations
Jun 03, 2022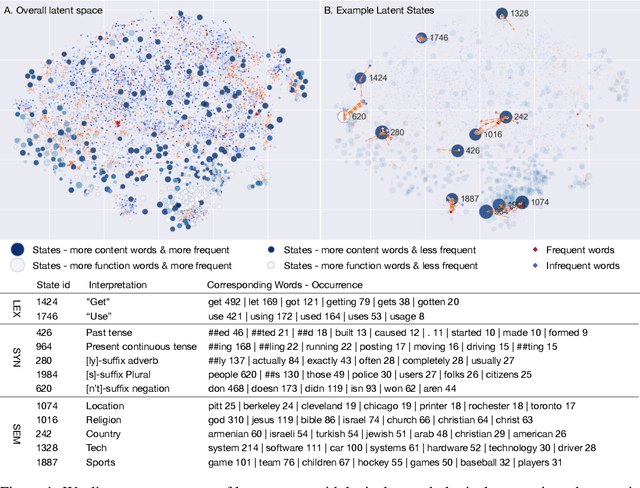
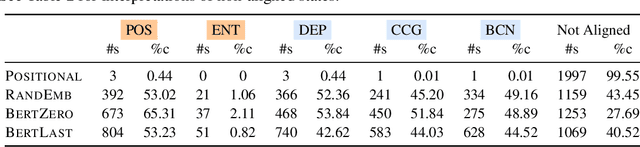
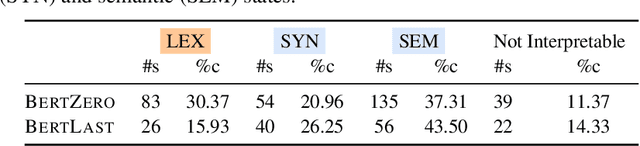
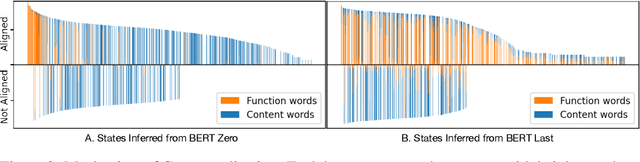
In this work, we study the representation space of contextualized embeddings and gain insight into the hidden topology of large language models. We show there exists a network of latent states that summarize linguistic properties of contextualized representations. Instead of seeking alignments to existing well-defined annotations, we infer this latent network in a fully unsupervised way using a structured variational autoencoder. The induced states not only serve as anchors that mark the topology (neighbors and connectivity) of the representation manifold but also reveal the internal mechanism of encoding sentences. With the induced network, we: (1). decompose the representation space into a spectrum of latent states which encode fine-grained word meanings with lexical, morphological, syntactic and semantic information; (2). show state-state transitions encode rich phrase constructions and serve as the backbones of the latent space. Putting the two together, we show that sentences are represented as a traversal over the latent network where state-state transition chains encode syntactic templates and state-word emissions fill in the content. We demonstrate these insights with extensive experiments and visualizations.
A Well-Composed Text is Half Done! Composition Sampling for Diverse Conditional Generation
Mar 28, 2022
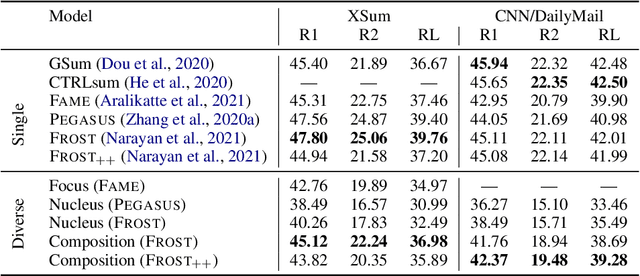

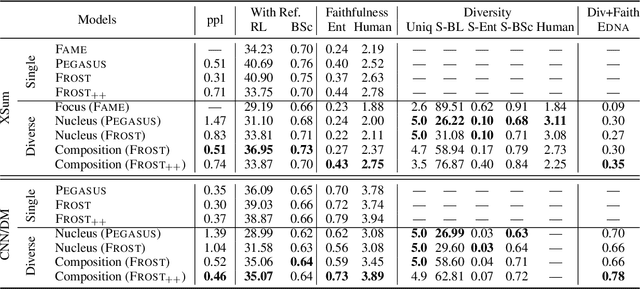
We propose Composition Sampling, a simple but effective method to generate diverse outputs for conditional generation of higher quality compared to previous stochastic decoding strategies. It builds on recently proposed plan-based neural generation models (Narayan et al, 2021) that are trained to first create a composition of the output and then generate by conditioning on it and the input. Our approach avoids text degeneration by first sampling a composition in the form of an entity chain and then using beam search to generate the best possible text grounded to this entity chain. Experiments on summarization (CNN/DailyMail and XSum) and question generation (SQuAD), using existing and newly proposed automatic metrics together with human-based evaluation, demonstrate that Composition Sampling is currently the best available decoding strategy for generating diverse meaningful outputs.
Hierarchical Sketch Induction for Paraphrase Generation
Mar 21, 2022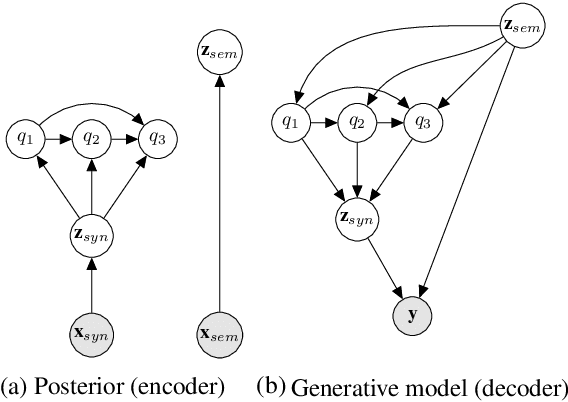
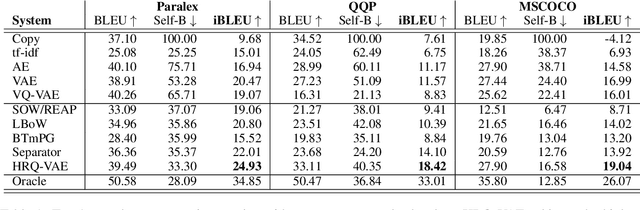
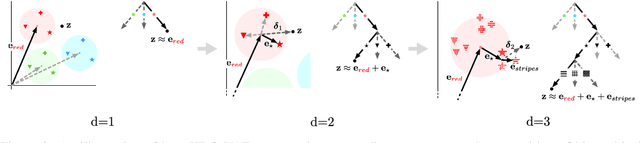

We propose a generative model of paraphrase generation, that encourages syntactic diversity by conditioning on an explicit syntactic sketch. We introduce Hierarchical Refinement Quantized Variational Autoencoders (HRQ-VAE), a method for learning decompositions of dense encodings as a sequence of discrete latent variables that make iterative refinements of increasing granularity. This hierarchy of codes is learned through end-to-end training, and represents fine-to-coarse grained information about the input. We use HRQ-VAE to encode the syntactic form of an input sentence as a path through the hierarchy, allowing us to more easily predict syntactic sketches at test time. Extensive experiments, including a human evaluation, confirm that HRQ-VAE learns a hierarchical representation of the input space, and generates paraphrases of higher quality than previous systems.
Data-to-text Generation with Variational Sequential Planning
Feb 28, 2022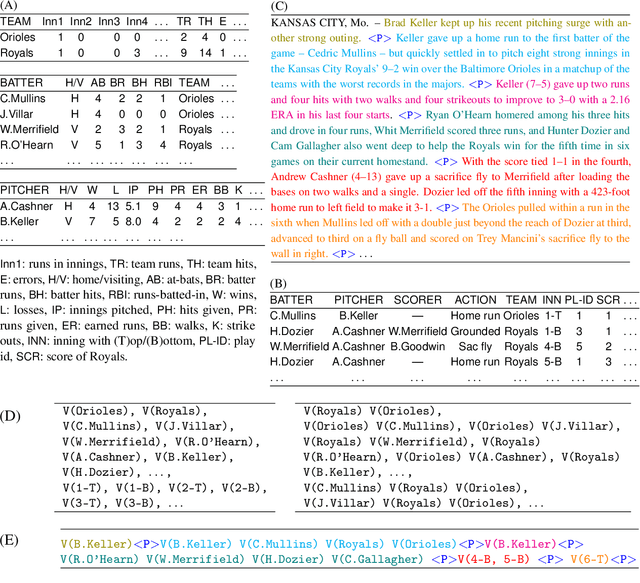
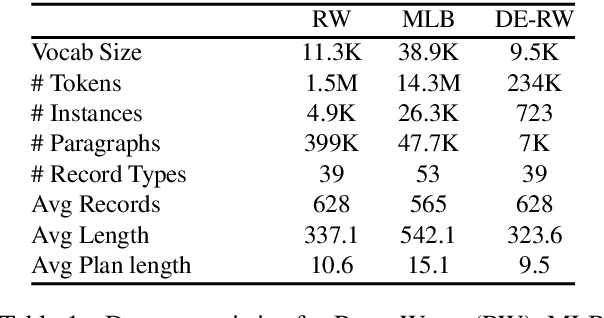
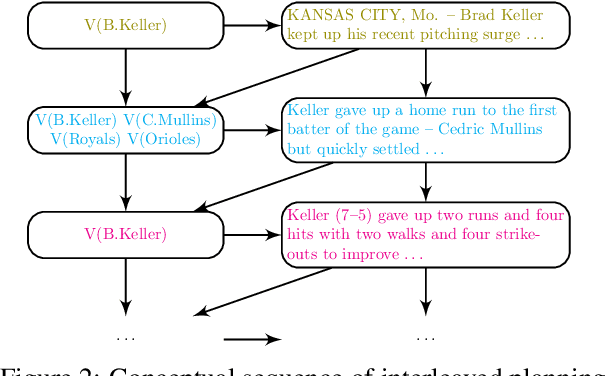
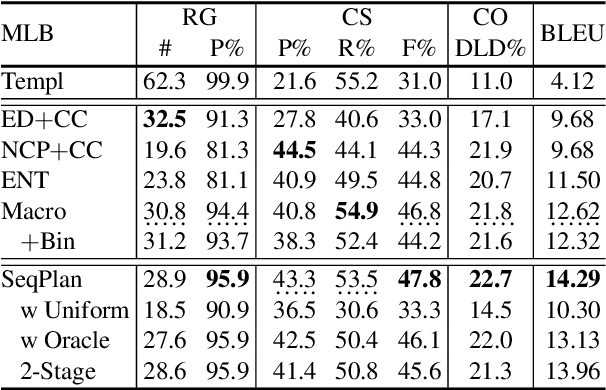
We consider the task of data-to-text generation, which aims to create textual output from non-linguistic input. We focus on generating long-form text, i.e., documents with multiple paragraphs, and propose a neural model enhanced with a planning component responsible for organizing high-level information in a coherent and meaningful way. We infer latent plans sequentially with a structured variational model, while interleaving the steps of planning and generation. Text is generated by conditioning on previous variational decisions and previously generated text. Experiments on two data-to-text benchmarks (RotoWire and MLB) show that our model outperforms strong baselines and is sample efficient in the face of limited training data (e.g., a few hundred instances).
Models and Datasets for Cross-Lingual Summarisation
Feb 19, 2022
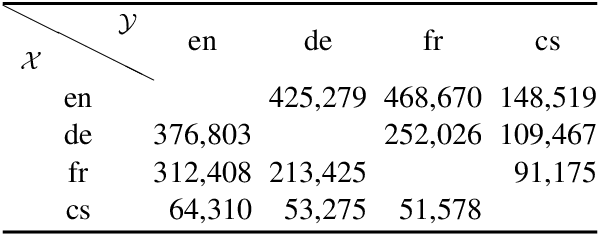
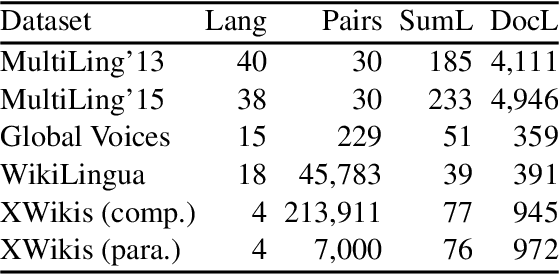

We present a cross-lingual summarisation corpus with long documents in a source language associated with multi-sentence summaries in a target language. The corpus covers twelve language pairs and directions for four European languages, namely Czech, English, French and German, and the methodology for its creation can be applied to several other languages. We derive cross-lingual document-summary instances from Wikipedia by combining lead paragraphs and articles' bodies from language aligned Wikipedia titles. We analyse the proposed cross-lingual summarisation task with automatic metrics and validate it with a human study. To illustrate the utility of our dataset we report experiments with multi-lingual pre-trained models in supervised, zero- and few-shot, and out-of-domain scenarios.