 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Generalisation for Explainable Hate Speech Detection
Jun 04, 2025Hate speech detection is key to online content moderation, but current models struggle to generalise beyond their training data. This has been linked to dataset biases and the use of sentence-level labels, which fail to teach models the underlying structure of hate speech. In this work, we show that even when models are trained with more fine-grained, span-level annotations (e.g., "artists" is labeled as target and "are parasites" as dehumanising comparison), they struggle to disentangle the meaning of these labels from the surrounding context. As a result, combinations of expressions that deviate from those seen during training remain particularly difficult for models to detect. We investigate whether training on a dataset where expressions occur with equal frequency across all contexts can improve generalisation. To this end, we create U-PLEAD, a dataset of ~364,000 synthetic posts, along with a novel compositional generalisation benchmark of ~8,000 manually validated posts. Training on a combination of U-PLEAD and real data improves compositional generalisation while achieving state-of-the-art performance on the human-sourced PLEAD.
Explainability and Hate Speech: Structured Explanations Make Social Media Moderators Faster
Jun 06, 2024



Content moderators play a key role in keeping the conversation on social media healthy. While the high volume of content they need to judge represents a bottleneck to the moderation pipeline, no studies have explored how models could support them to make faster decisions. There is, by now, a vast body of research into detecting hate speech, sometimes explicitly motivated by a desire to help improve content moderation, but published research using real content moderators is scarce. In this work we investigate the effect of explanations on the speed of real-world moderators. Our experiments show that while generic explanations do not affect their speed and are often ignored, structured explanations lower moderators' decision making time by 7.4%.
Explainable Abuse Detection as Intent Classification and Slot Filling
Oct 06, 2022

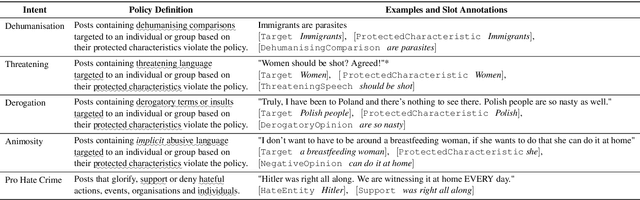
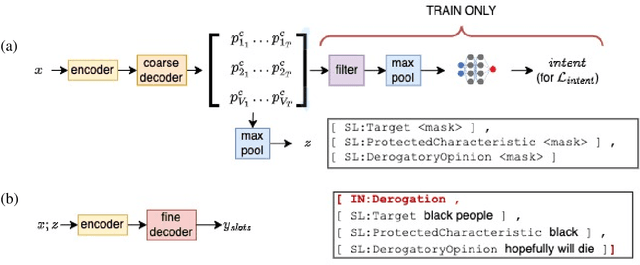
To proactively offer social media users a safe online experience, there is a need for systems that can detect harmful posts and promptly alert platform moderators. In order to guarantee the enforcement of a consistent policy, moderators are provided with detailed guidelines. In contrast, most state-of-the-art models learn what abuse is from labelled examples and as a result base their predictions on spurious cues, such as the presence of group identifiers, which can be unreliable. In this work we introduce the concept of policy-aware abuse detection, abandoning the unrealistic expectation that systems can reliably learn which phenomena constitute abuse from inspecting the data alone. We propose a machine-friendly representation of the policy that moderators wish to enforce, by breaking it down into a collection of intents and slots. We collect and annotate a dataset of 3,535 English posts with such slots, and show how architectures for intent classification and slot filling can be used for abuse detection, while providing a rationale for model decisions.