 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRebooting ACGAN: Auxiliary Classifier GANs with Stable Training
Nov 01, 2021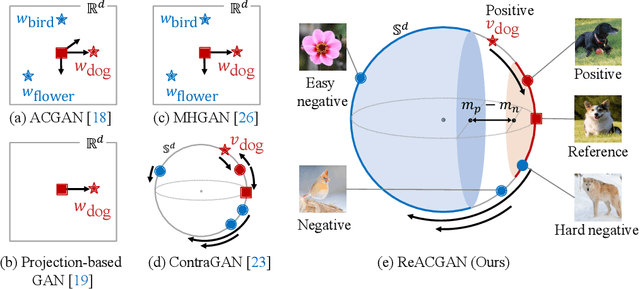
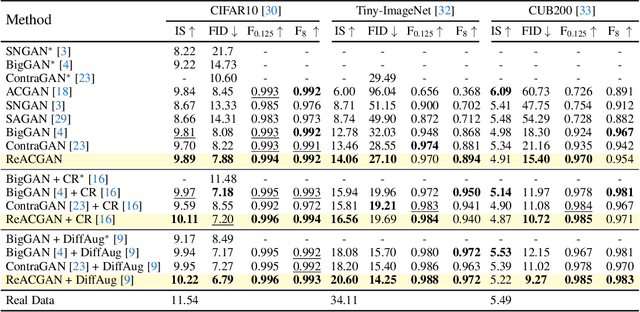
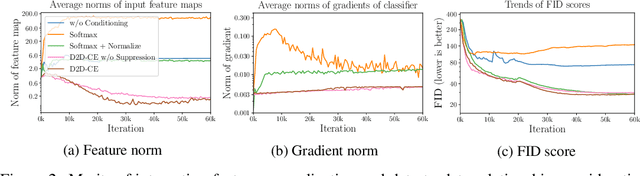
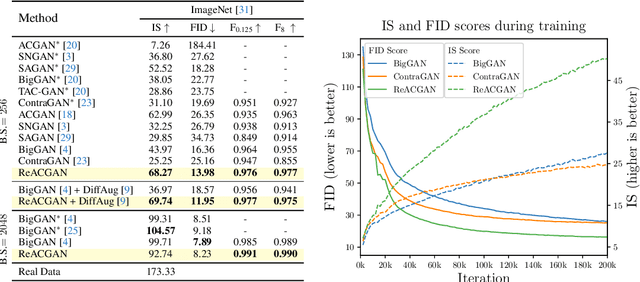
Conditional Generative Adversarial Networks (cGAN) generate realistic images by incorporating class information into GAN. While one of the most popular cGANs is an auxiliary classifier GAN with softmax cross-entropy loss (ACGAN), it is widely known that training ACGAN is challenging as the number of classes in the dataset increases. ACGAN also tends to generate easily classifiable samples with a lack of diversity. In this paper, we introduce two cures for ACGAN. First, we identify that gradient exploding in the classifier can cause an undesirable collapse in early training, and projecting input vectors onto a unit hypersphere can resolve the problem. Second, we propose the Data-to-Data Cross-Entropy loss (D2D-CE) to exploit relational information in the class-labeled dataset. On this foundation, we propose the Rebooted Auxiliary Classifier Generative Adversarial Network (ReACGAN). The experimental results show that ReACGAN achieves state-of-the-art generation results on CIFAR10, Tiny-ImageNet, CUB200, and ImageNet datasets. We also verify that ReACGAN benefits from differentiable augmentations and that D2D-CE harmonizes with StyleGAN2 architecture. Model weights and a software package that provides implementations of representative cGANs and all experiments in our paper are available at https://github.com/POSTECH-CVLab/PyTorch-StudioGAN.
Brick-by-Brick: Combinatorial Construction with Deep Reinforcement Learning
Oct 29, 2021
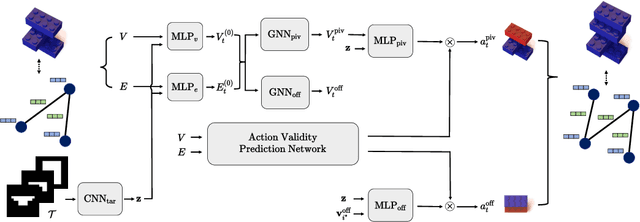
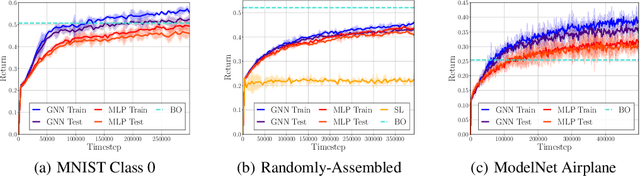
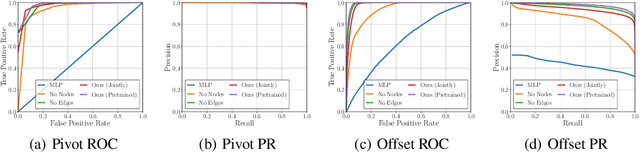
Discovering a solution in a combinatorial space is prevalent in many real-world problems but it is also challenging due to diverse complex constraints and the vast number of possible combinations. To address such a problem, we introduce a novel formulation, combinatorial construction, which requires a building agent to assemble unit primitives (i.e., LEGO bricks) sequentially -- every connection between two bricks must follow a fixed rule, while no bricks mutually overlap. To construct a target object, we provide incomplete knowledge about the desired target (i.e., 2D images) instead of exact and explicit volumetric information to the agent. This problem requires a comprehensive understanding of partial information and long-term planning to append a brick sequentially, which leads us to employ reinforcement learning. The approach has to consider a variable-sized action space where a large number of invalid actions, which would cause overlap between bricks, exist. To resolve these issues, our model, dubbed Brick-by-Brick, adopts an action validity prediction network that efficiently filters invalid actions for an actor-critic network. We demonstrate that the proposed method successfully learns to construct an unseen object conditioned on a single image or multiple views of a target object.
Differentiable Spline Approximations
Oct 04, 2021
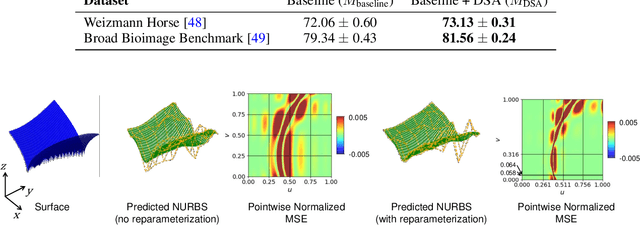


The paradigm of differentiable programming has significantly enhanced the scope of machine learning via the judicious use of gradient-based optimization. However, standard differentiable programming methods (such as autodiff) typically require that the machine learning models be differentiable, limiting their applicability. Our goal in this paper is to use a new, principled approach to extend gradient-based optimization to functions well modeled by splines, which encompass a large family of piecewise polynomial models. We derive the form of the (weak) Jacobian of such functions and show that it exhibits a block-sparse structure that can be computed implicitly and efficiently. Overall, we show that leveraging this redesigned Jacobian in the form of a differentiable "layer" in predictive models leads to improved performance in diverse applications such as image segmentation, 3D point cloud reconstruction, and finite element analysis.
Convolutional Hough Matching Networks for Robust and Efficient Visual Correspondence
Sep 11, 2021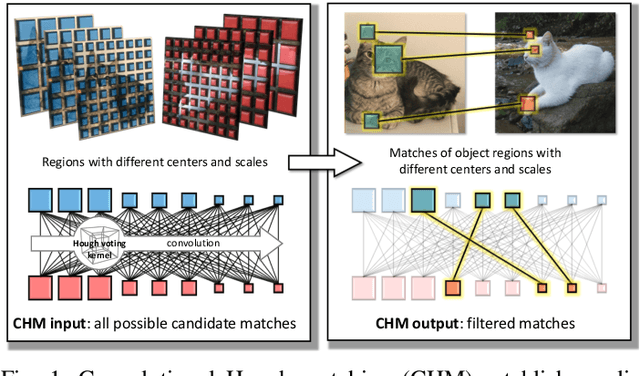
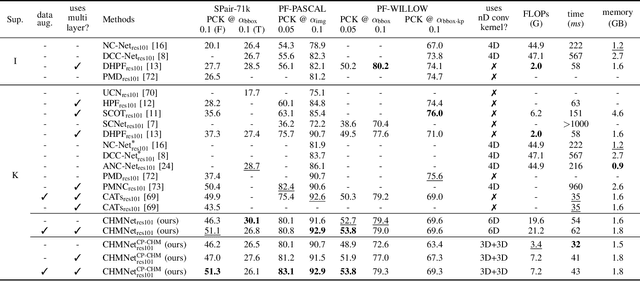
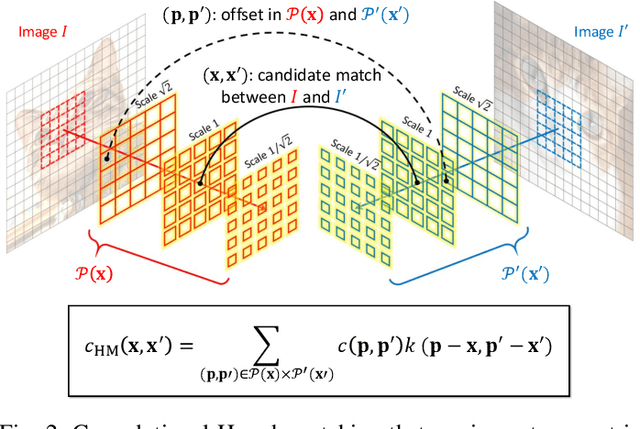
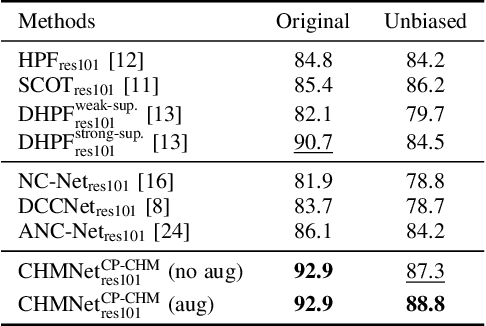
Despite advances in feature representation, leveraging geometric relations is crucial for establishing reliable visual correspondences under large variations of images. In this work we introduce a Hough transform perspective on convolutional matching and propose an effective geometric matching algorithm, dubbed Convolutional Hough Matching (CHM). The method distributes similarities of candidate matches over a geometric transformation space and evaluates them in a convolutional manner. We cast it into a trainable neural layer with a semi-isotropic high-dimensional kernel, which learns non-rigid matching with a small number of interpretable parameters. To further improve the efficiency of high-dimensional voting, we also propose to use an efficient kernel decomposition with center-pivot neighbors, which significantly sparsifies the proposed semi-isotropic kernels without performance degradation. To validate the proposed techniques, we develop the neural network with CHM layers that perform convolutional matching in the space of translation and scaling. Our method sets a new state of the art on standard benchmarks for semantic visual correspondence, proving its strong robustness to challenging intra-class variations.
Deep Hough Voting for Robust Global Registration
Sep 09, 2021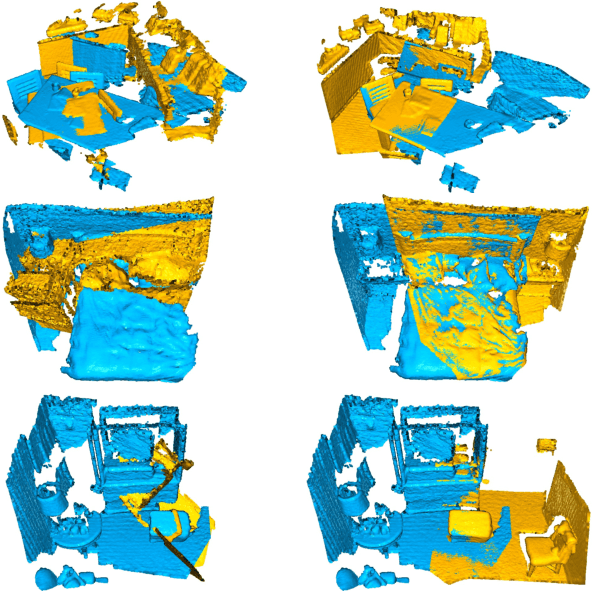
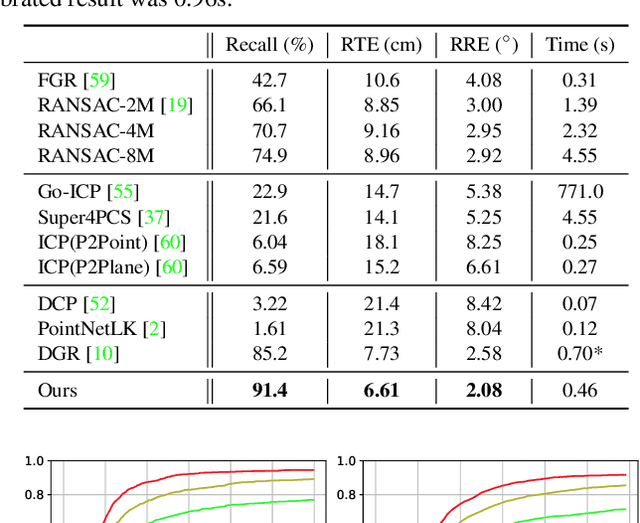
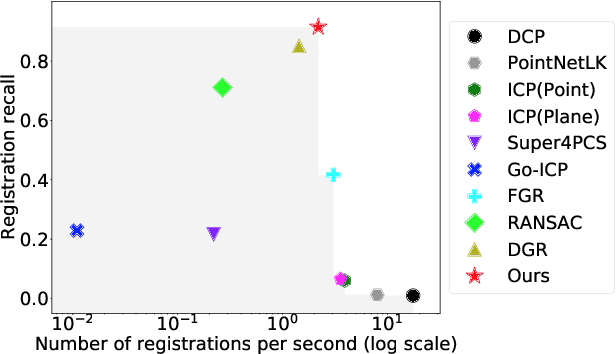
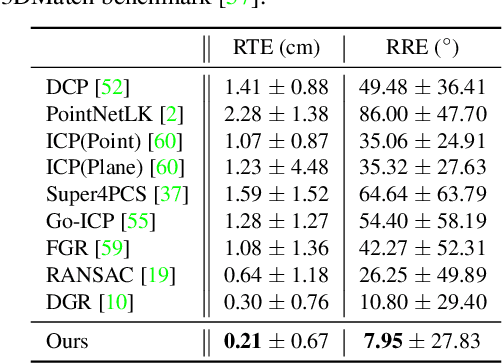
Point cloud registration is the task of estimating the rigid transformation that aligns a pair of point cloud fragments. We present an efficient and robust framework for pairwise registration of real-world 3D scans, leveraging Hough voting in the 6D transformation parameter space. First, deep geometric features are extracted from a point cloud pair to compute putative correspondences. We then construct a set of triplets of correspondences to cast votes on the 6D Hough space, representing the transformation parameters in sparse tensors. Next, a fully convolutional refinement module is applied to refine the noisy votes. Finally, we identify the consensus among the correspondences from the Hough space, which we use to predict our final transformation parameters. Our method outperforms state-of-the-art methods on 3DMatch and 3DLoMatch benchmarks while achieving comparable performance on KITTI odometry dataset. We further demonstrate the generalizability of our approach by setting a new state-of-the-art on ICL-NUIM dataset, where we integrate our module into a multi-way registration pipeline.
Learning to Discover Reflection Symmetry via Polar Matching Convolution
Sep 03, 2021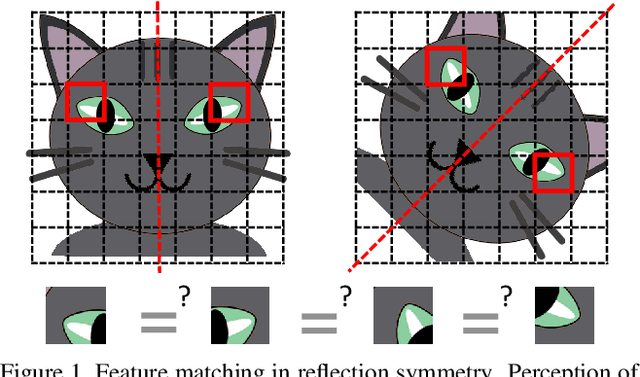
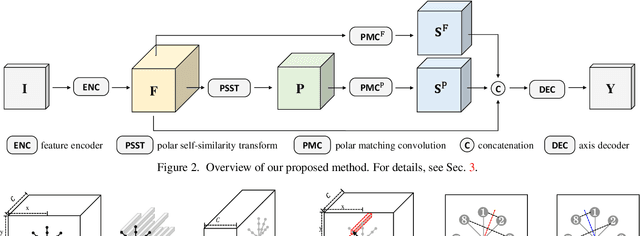
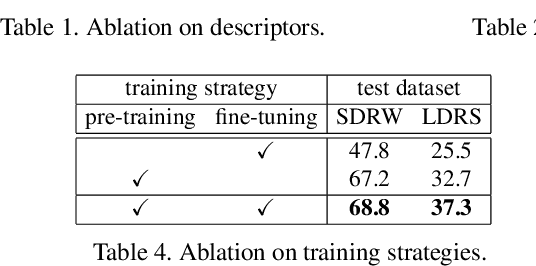
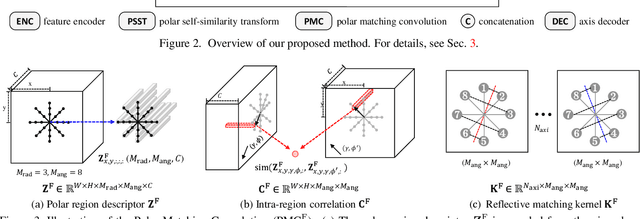
The task of reflection symmetry detection remains challenging due to significant variations and ambiguities of symmetry patterns in the wild. Furthermore, since the local regions are required to match in reflection for detecting a symmetry pattern, it is hard for standard convolutional networks, which are not equivariant to rotation and reflection, to learn the task. To address the issue, we introduce a new convolutional technique, dubbed the polar matching convolution, which leverages a polar feature pooling, a self-similarity encoding, and a systematic kernel design for axes of different angles. The proposed high-dimensional kernel convolution network effectively learns to discover symmetry patterns from real-world images, overcoming the limitations of standard convolution. In addition, we present a new dataset and introduce a self-supervised learning strategy by augmenting the dataset with synthesizing images. Experiments demonstrate that our method outperforms state-of-the-art methods in terms of accuracy and robustness.
Self-Calibrating Neural Radiance Fields
Sep 02, 2021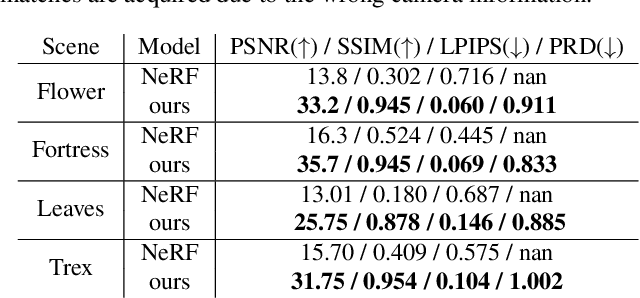
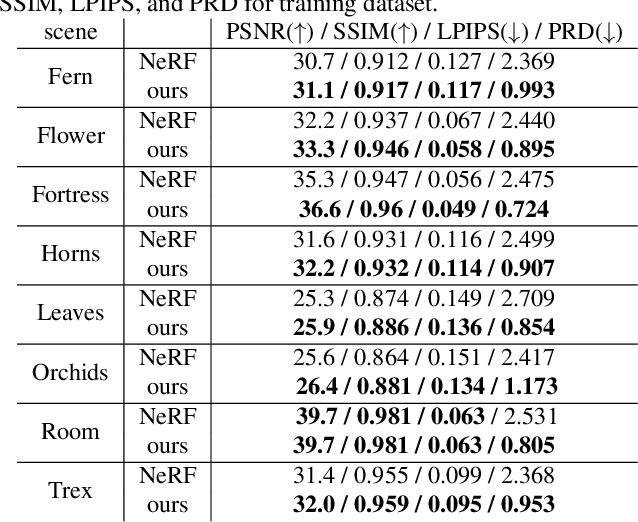

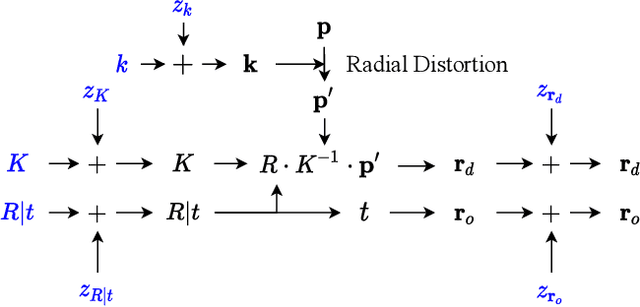
In this work, we propose a camera self-calibration algorithm for generic cameras with arbitrary non-linear distortions. We jointly learn the geometry of the scene and the accurate camera parameters without any calibration objects. Our camera model consists of a pinhole model, a fourth order radial distortion, and a generic noise model that can learn arbitrary non-linear camera distortions. While traditional self-calibration algorithms mostly rely on geometric constraints, we additionally incorporate photometric consistency. This requires learning the geometry of the scene, and we use Neural Radiance Fields (NeRF). We also propose a new geometric loss function, viz., projected ray distance loss, to incorporate geometric consistency for complex non-linear camera models. We validate our approach on standard real image datasets and demonstrate that our model can learn the camera intrinsics and extrinsics (pose) from scratch without COLMAP initialization. Also, we show that learning accurate camera models in a differentiable manner allows us to improve PSNR over baselines. Our module is an easy-to-use plugin that can be applied to NeRF variants to improve performance. The code and data are currently available at https://github.com/POSTECH-CVLab/SCNeRF.
Relational Embedding for Few-Shot Classification
Aug 22, 2021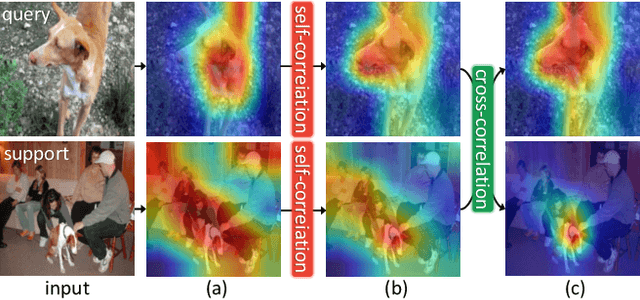
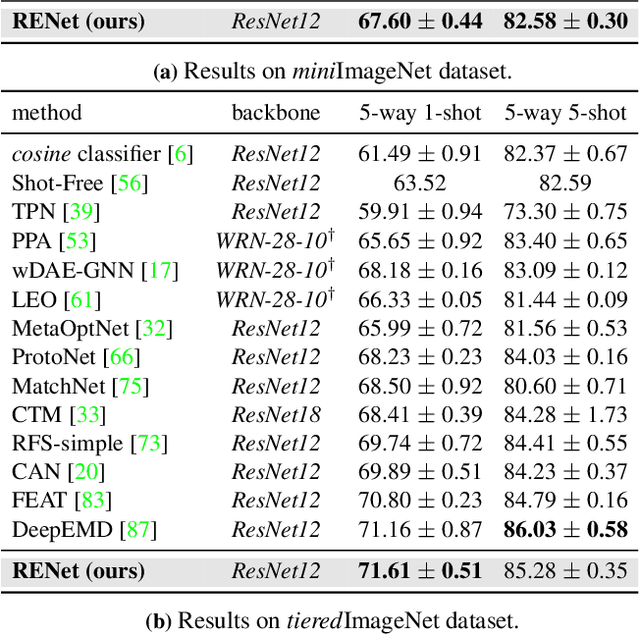
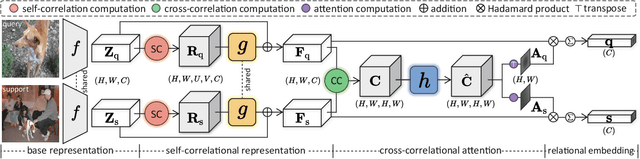
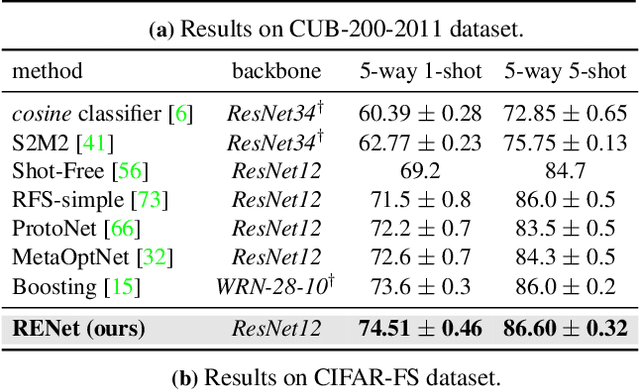
We propose to address the problem of few-shot classification by meta-learning "what to observe" and "where to attend" in a relational perspective. Our method leverages relational patterns within and between images via self-correlational representation (SCR) and cross-correlational attention (CCA). Within each image, the SCR module transforms a base feature map into a self-correlation tensor and learns to extract structural patterns from the tensor. Between the images, the CCA module computes cross-correlation between two image representations and learns to produce co-attention between them. Our Relational Embedding Network (RENet) combines the two relational modules to learn relational embedding in an end-to-end manner. In experimental evaluation, it achieves consistent improvements over state-of-the-art methods on four widely used few-shot classification benchmarks of miniImageNet, tieredImageNet, CUB-200-2011, and CIFAR-FS.
Sphynx: ReLU-Efficient Network Design for Private Inference
Jun 17, 2021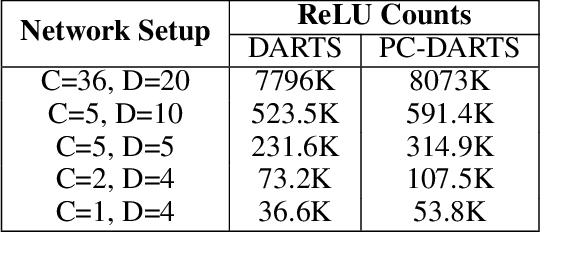
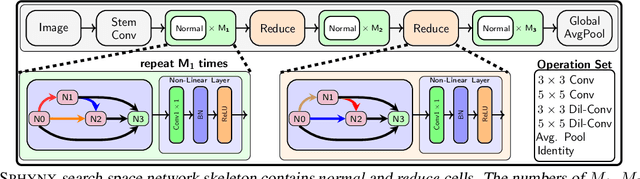
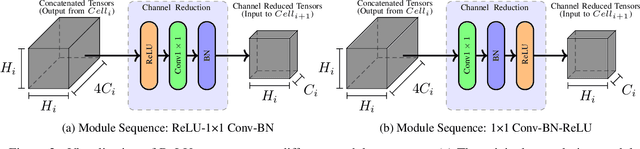

The emergence of deep learning has been accompanied by privacy concerns surrounding users' data and service providers' models. We focus on private inference (PI), where the goal is to perform inference on a user's data sample using a service provider's model. Existing PI methods for deep networks enable cryptographically secure inference with little drop in functionality; however, they incur severe latency costs, primarily caused by non-linear network operations (such as ReLUs). This paper presents Sphynx, a ReLU-efficient network design method based on micro-search strategies for convolutional cell design. Sphynx achieves Pareto dominance over all existing private inference methods on CIFAR-100. We also design large-scale networks that support cryptographically private inference on Tiny-ImageNet and ImageNet.
Hypercorrelation Squeeze for Few-Shot Segmentation
Apr 04, 2021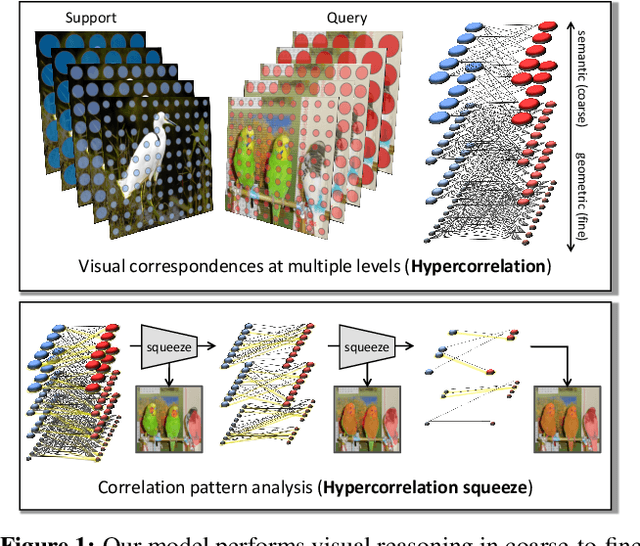
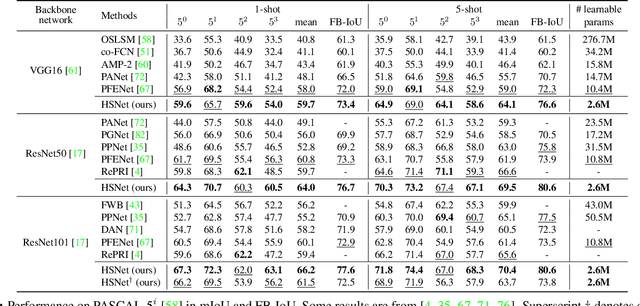
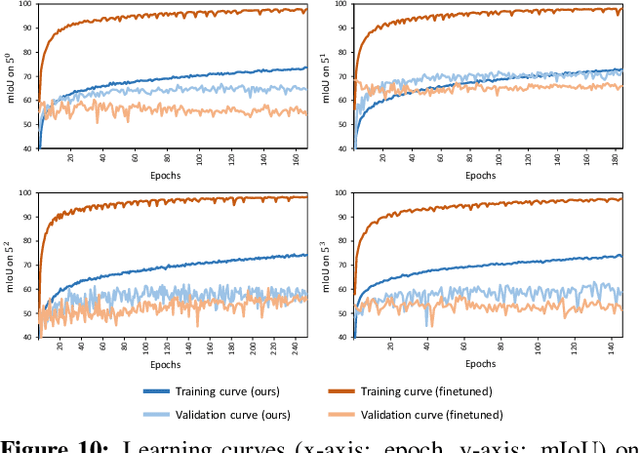
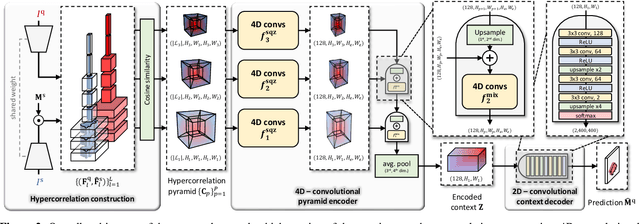
Few-shot semantic segmentation aims at learning to segment a target object from a query image using only a few annotated support images of the target class. This challenging task requires to understand diverse levels of visual cues and analyze fine-grained correspondence relations between the query and the support images. To address the problem, we propose Hypercorrelation Squeeze Networks (HSNet) that leverages multi-level feature correlation and efficient 4D convolutions. It extracts diverse features from different levels of intermediate convolutional layers and constructs a collection of 4D correlation tensors, i.e., hypercorrelations. Using efficient center-pivot 4D convolutions in a pyramidal architecture, the method gradually squeezes high-level semantic and low-level geometric cues of the hypercorrelation into precise segmentation masks in coarse-to-fine manner. The significant performance improvements on standard few-shot segmentation benchmarks of PASCAL-5i, COCO-20i, and FSS-1000 verify the efficacy of the proposed method.