 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Attention Modules
Oct 20, 2020
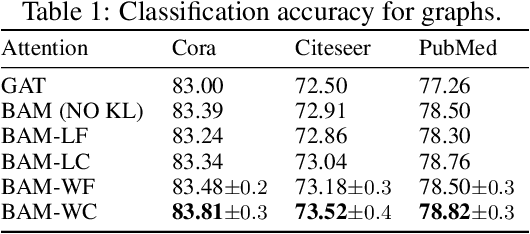
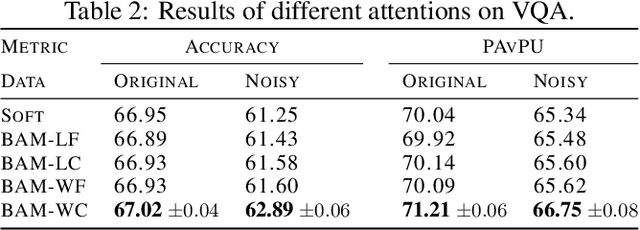

Attention modules, as simple and effective tools, have not only enabled deep neural networks to achieve state-of-the-art results in many domains, but also enhanced their interpretability. Most current models use deterministic attention modules due to their simplicity and ease of optimization. Stochastic counterparts, on the other hand, are less popular despite their potential benefits. The main reason is that stochastic attention often introduces optimization issues or requires significant model changes. In this paper, we propose a scalable stochastic version of attention that is easy to implement and optimize. We construct simplex-constrained attention distributions by normalizing reparameterizable distributions, making the training process differentiable. We learn their parameters in a Bayesian framework where a data-dependent prior is introduced for regularization. We apply the proposed stochastic attention modules to various attention-based models, with applications to graph node classification, visual question answering, image captioning, machine translation, and language understanding. Our experiments show the proposed method brings consistent improvements over the corresponding baselines.
MCMC-Interactive Variational Inference
Oct 02, 2020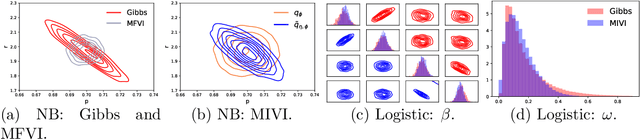

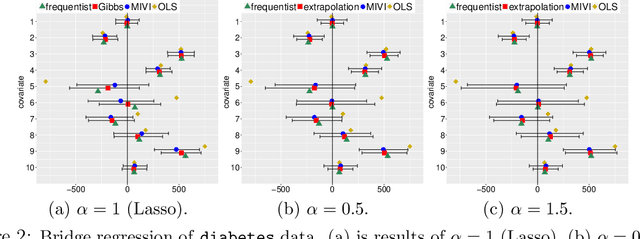
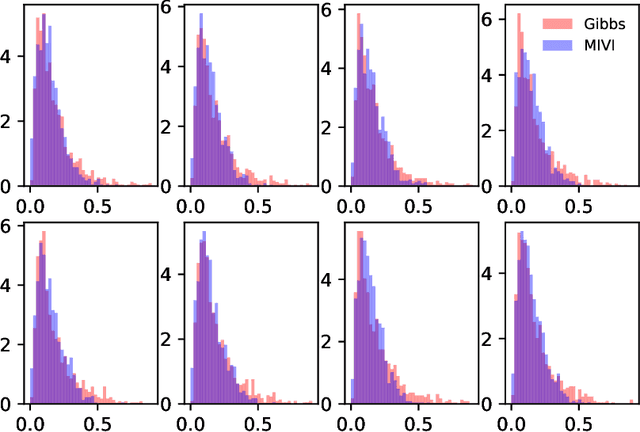
Leveraging well-established MCMC strategies, we propose MCMC-interactive variational inference (MIVI) to not only estimate the posterior in a time constrained manner, but also facilitate the design of MCMC transitions. Constructing a variational distribution followed by a short Markov chain that has parameters to learn, MIVI takes advantage of the complementary properties of variational inference and MCMC to encourage mutual improvement. On one hand, with the variational distribution locating high posterior density regions, the Markov chain is optimized within the variational inference framework to efficiently target the posterior despite a small number of transitions. On the other hand, the optimized Markov chain with considerable flexibility guides the variational distribution towards the posterior and alleviates its underestimation of uncertainty. Furthermore, we prove the optimized Markov chain in MIVI admits extrapolation, which means its marginal distribution gets closer to the true posterior as the chain grows. Therefore, the Markov chain can be used separately as an efficient MCMC scheme. Experiments show that MIVI not only accurately and efficiently approximates the posteriors but also facilitates designs of stochastic gradient MCMC and Gibbs sampling transitions.
Variational Temporal Deep Generative Model for Radar HRRP Target Recognition
Sep 28, 2020
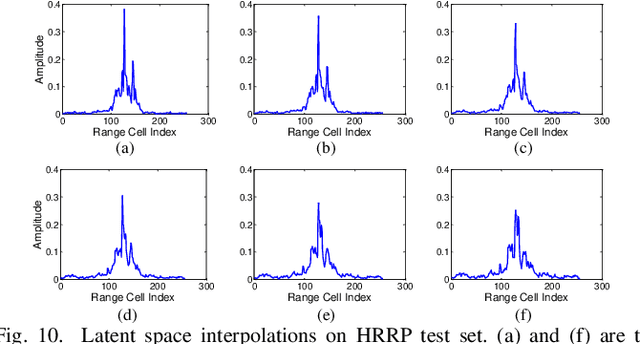
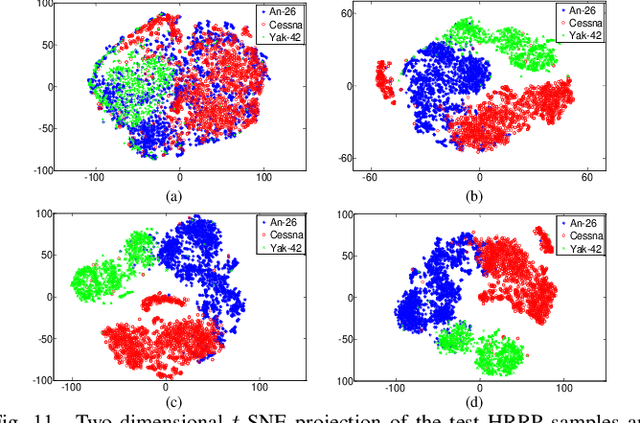
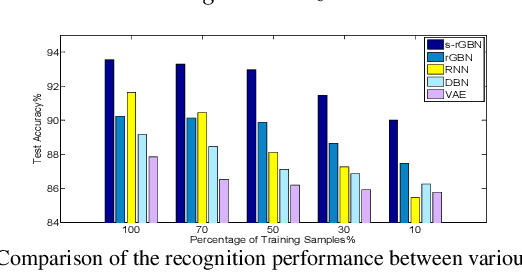
We develop a recurrent gamma belief network (rGBN) for radar automatic target recognition (RATR) based on high-resolution range profile (HRRP), which characterizes the temporal dependence across the range cells of HRRP. The proposed rGBN adopts a hierarchy of gamma distributions to build its temporal deep generative model. For scalable training and fast out-of-sample prediction, we propose the hybrid of a stochastic-gradient Markov chain Monte Carlo (MCMC) and a recurrent variational inference model to perform posterior inference. To utilize the label information to extract more discriminative latent representations, we further propose supervised rGBN to jointly model the HRRP samples and their corresponding labels. Experimental results on synthetic and measured HRRP data show that the proposed models are efficient in computation, have good classification accuracy and generalization ability, and provide highly interpretable multi-stochastic-layer latent structure.
Graph Gamma Process Generalized Linear Dynamical Systems
Jul 25, 2020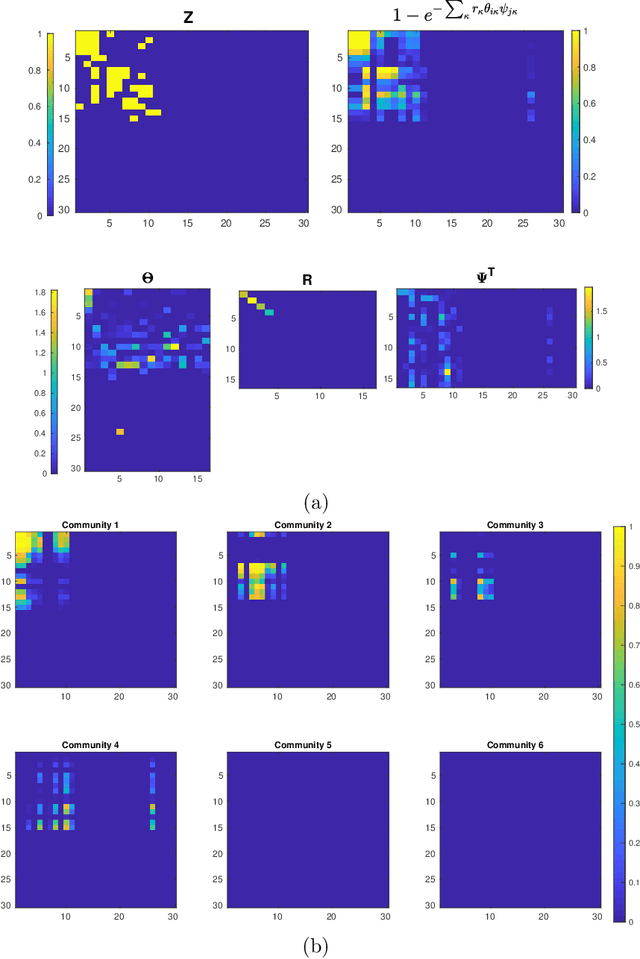
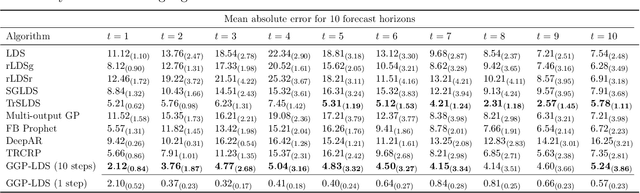

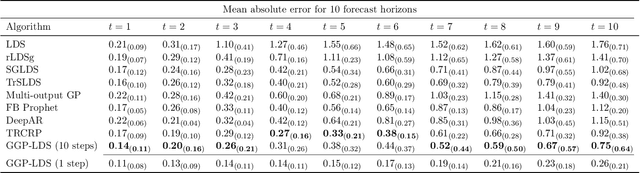
We introduce graph gamma process (GGP) linear dynamical systems to model real-valued multivariate time series. For temporal pattern discovery, the latent representation under the model is used to decompose the time series into a parsimonious set of multivariate sub-sequences. In each sub-sequence, different data dimensions often share similar temporal patterns but may exhibit distinct magnitudes, and hence allowing the superposition of all sub-sequences to exhibit diverse behaviors at different data dimensions. We further generalize the proposed model by replacing the Gaussian observation layer with the negative binomial distribution to model multivariate count time series. Generated from the proposed GGP is an infinite dimensional directed sparse random graph, which is constructed by taking the logical OR operation of countably infinite binary adjacency matrices that share the same set of countably infinite nodes. Each of these adjacency matrices is associated with a weight to indicate its activation strength, and places a finite number of edges between a finite subset of nodes belonging to the same node community. We use the generated random graph, whose number of nonzero-degree nodes is finite, to define both the sparsity pattern and dimension of the latent state transition matrix of a (generalized) linear dynamical system. The activation strength of each node community relative to the overall activation strength is used to extract a multivariate sub-sequence, revealing the data pattern captured by the corresponding community. On both synthetic and real-world time series, the proposed nonparametric Bayesian dynamic models, which are initialized at random, consistently exhibit good predictive performance in comparison to a variety of baseline models, revealing interpretable latent state transition patterns and decomposing the time series into distinctly behaved sub-sequences.
Implicit Distributional Reinforcement Learning
Jul 13, 2020
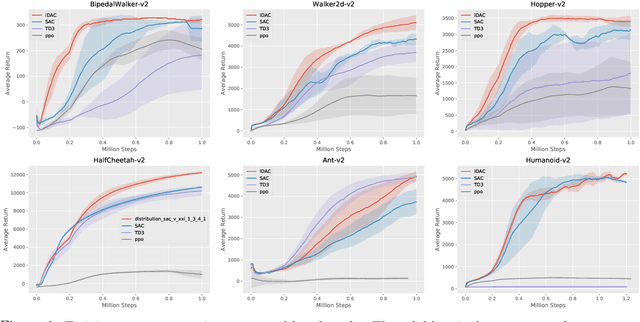
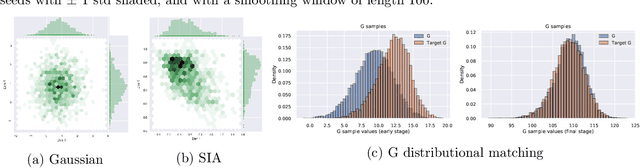
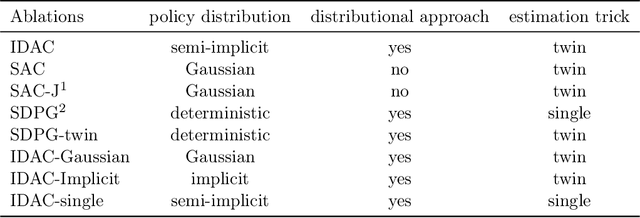
To improve the sample efficiency of policy-gradient based reinforcement learning algorithms, we propose implicit distributional actor critic (IDAC) that consists of a distributional critic, built on two deep generator networks (DGNs), and a semi-implicit actor (SIA), powered by a flexible policy distribution. We adopt a distributional perspective on the discounted cumulative return and model it with a state-action-dependent implicit distribution, which is approximated by the DGNs that take state-action pairs and random noises as their input. Moreover, we use the SIA to provide a semi-implicit policy distribution, which mixes the policy parameters with a reparameterizable distribution that is not constrained by an analytic density function. In this way, the policy's marginal distribution is implicit, providing the potential to model complex properties such as covariance structure and skewness, but its parameter and entropy can still be estimated. We incorporate these features with an off-policy algorithm framework to solve problems with continuous action space, and compare IDAC with the state-of-art algorithms on representative OpenAI Gym environments. We observe that IDAC outperforms these baselines for most tasks.
Bayesian Graph Neural Networks with Adaptive Connection Sampling
Jun 30, 2020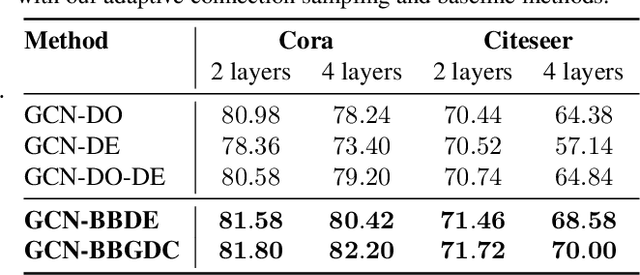


We propose a unified framework for adaptive connection sampling in graph neural networks (GNNs) that generalizes existing stochastic regularization methods for training GNNs. The proposed framework not only alleviates over-smoothing and over-fitting tendencies of deep GNNs, but also enables learning with uncertainty in graph analytic tasks with GNNs. Instead of using fixed sampling rates or hand-tuning them as model hyperparameters in existing stochastic regularization methods, our adaptive connection sampling can be trained jointly with GNN model parameters in both global and local fashions. GNN training with adaptive connection sampling is shown to be mathematically equivalent to an efficient approximation of training Bayesian GNNs. Experimental results with ablation studies on benchmark datasets validate that adaptively learning the sampling rate given graph training data is the key to boost the performance of GNNs in semi-supervised node classification, less prone to over-smoothing and over-fitting with more robust prediction.
Deep Autoencoding Topic Model with Scalable Hybrid Bayesian Inference
Jun 15, 2020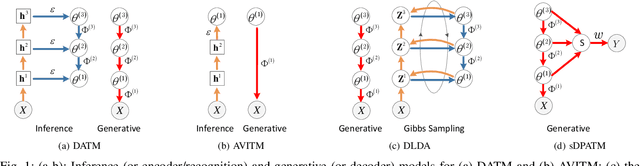
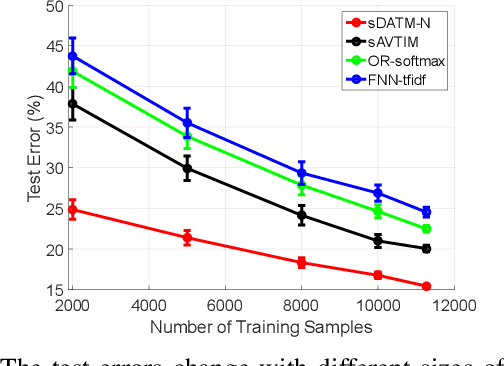
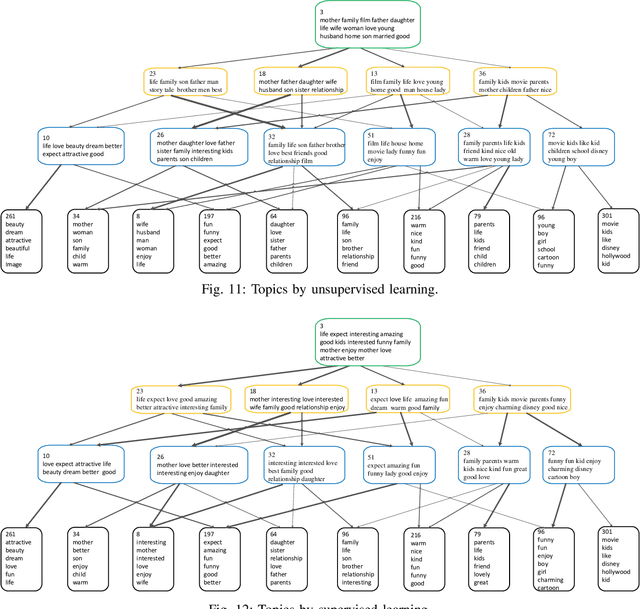
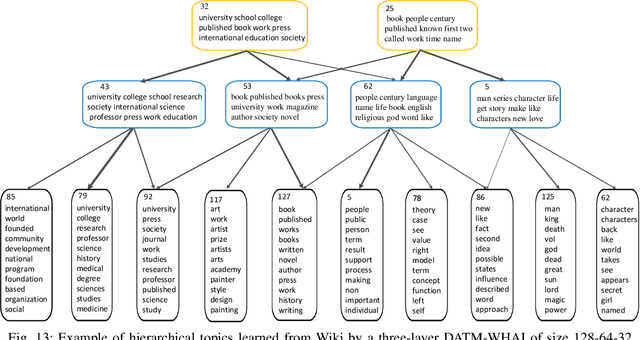
To build a flexible and interpretable model for document analysis, we develop deep autoencoding topic model (DATM) that uses a hierarchy of gamma distributions to construct its multi-stochastic-layer generative network. In order to provide scalable posterior inference for the parameters of the generative network, we develop topic-layer-adaptive stochastic gradient Riemannian MCMC that jointly learns simplex-constrained global parameters across all layers and topics, with topic and layer specific learning rates. Given a posterior sample of the global parameters, in order to efficiently infer the local latent representations of a document under DATM across all stochastic layers, we propose a Weibull upward-downward variational encoder that deterministically propagates information upward via a deep neural network, followed by a Weibull distribution based stochastic downward generative model. To jointly model documents and their associated labels, we further propose supervised DATM that enhances the discriminative power of its latent representations. The efficacy and scalability of our models are demonstrated on both unsupervised and supervised learning tasks on big corpora.
Pairwise Supervised Hashing with Bernoulli Variational Auto-Encoder and Self-Control Gradient Estimator
May 21, 2020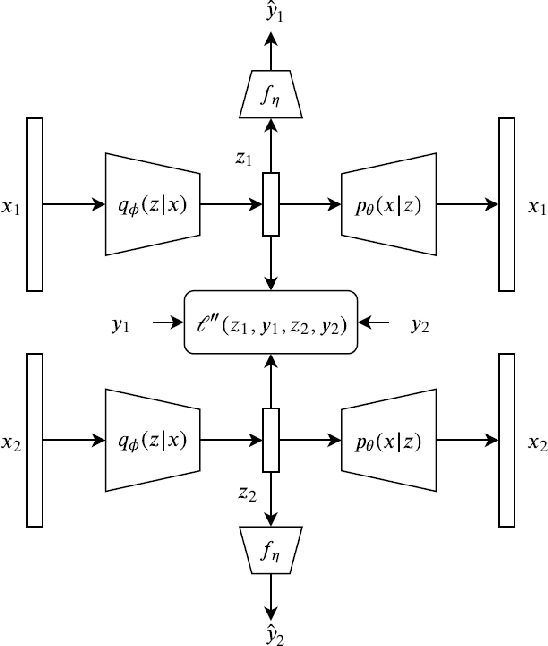
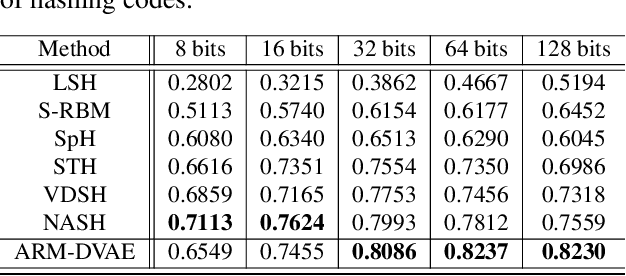
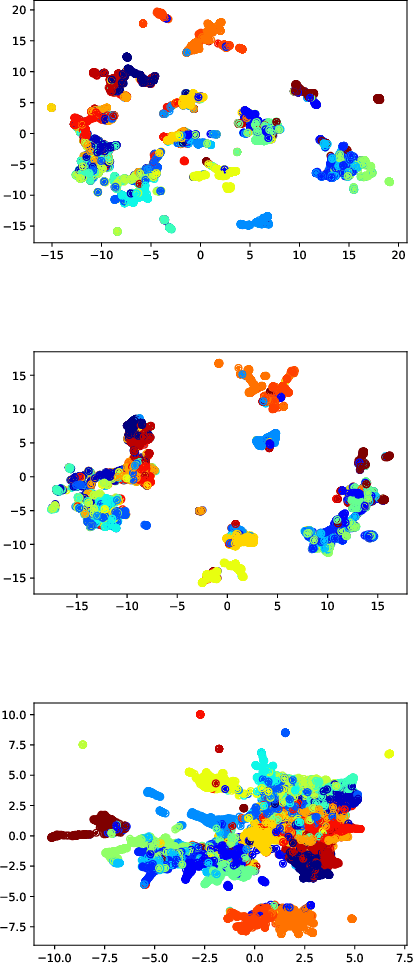
Semantic hashing has become a crucial component of fast similarity search in many large-scale information retrieval systems, in particular, for text data. Variational auto-encoders (VAEs) with binary latent variables as hashing codes provide state-of-the-art performance in terms of precision for document retrieval. We propose a pairwise loss function with discrete latent VAE to reward within-class similarity and between-class dissimilarity for supervised hashing. Instead of solving the optimization relying on existing biased gradient estimators, an unbiased low-variance gradient estimator is adopted to optimize the hashing function by evaluating the non-differentiable loss function over two correlated sets of binary hashing codes to control the variance of gradient estimates. This new semantic hashing framework achieves superior performance compared to the state-of-the-arts, as demonstrated by our comprehensive experiments.
* To appear in UAI 2020
Mutual Information Gradient Estimation for Representation Learning
May 03, 2020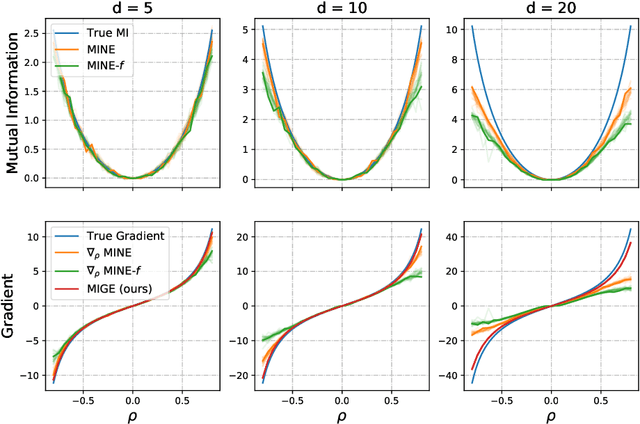
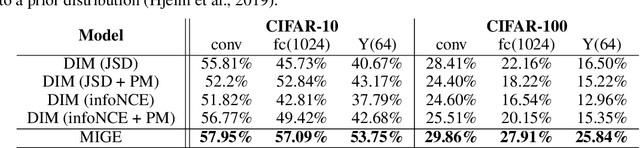
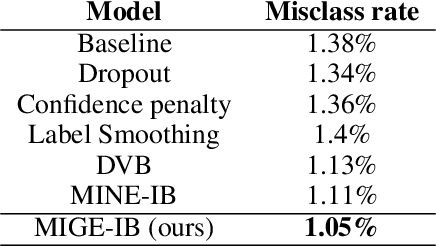
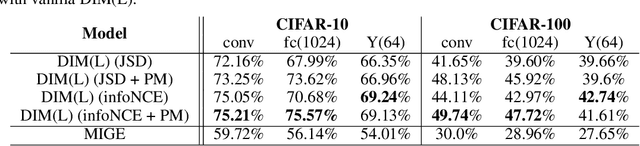
Mutual Information (MI) plays an important role in representation learning. However, MI is unfortunately intractable in continuous and high-dimensional settings. Recent advances establish tractable and scalable MI estimators to discover useful representation. However, most of the existing methods are not capable of providing an accurate estimation of MI with low-variance when the MI is large. We argue that directly estimating the gradients of MI is more appealing for representation learning than estimating MI in itself. To this end, we propose the Mutual Information Gradient Estimator (MIGE) for representation learning based on the score estimation of implicit distributions. MIGE exhibits a tight and smooth gradient estimation of MI in the high-dimensional and large-MI settings. We expand the applications of MIGE in both unsupervised learning of deep representations based on InfoMax and the Information Bottleneck method. Experimental results have indicated significant performance improvement in learning useful representation.
Discrete Action On-Policy Learning with Action-Value Critic
Feb 21, 2020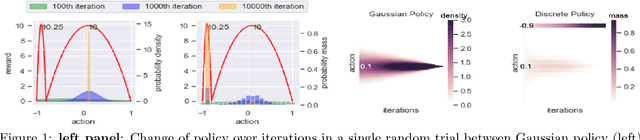
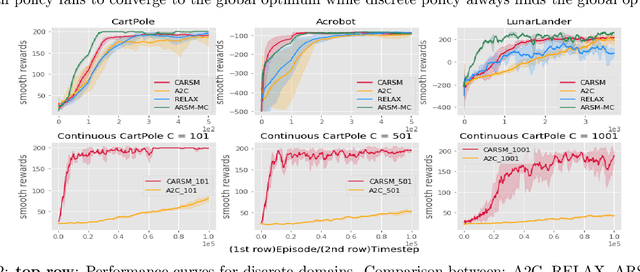
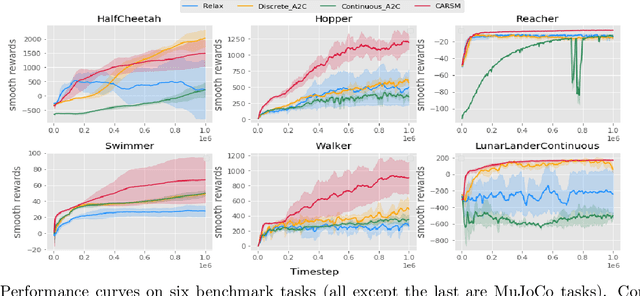
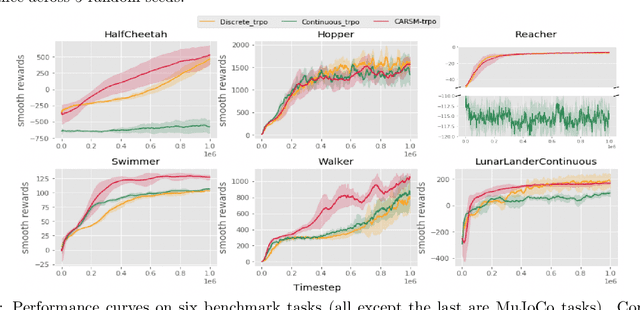
Reinforcement learning (RL) in discrete action space is ubiquitous in real-world applications, but its complexity grows exponentially with the action-space dimension, making it challenging to apply existing on-policy gradient based deep RL algorithms efficiently. To effectively operate in multidimensional discrete action spaces, we construct a critic to estimate action-value functions, apply it on correlated actions, and combine these critic estimated action values to control the variance of gradient estimation. We follow rigorous statistical analysis to design how to generate and combine these correlated actions, and how to sparsify the gradients by shutting down the contributions from certain dimensions. These efforts result in a new discrete action on-policy RL algorithm that empirically outperforms related on-policy algorithms relying on variance control techniques. We demonstrate these properties on OpenAI Gym benchmark tasks, and illustrate how discretizing the action space could benefit the exploration phase and hence facilitate convergence to a better local optimal solution thanks to the flexibility of discrete policy.