 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoment Matching Denoising Gibbs Sampling
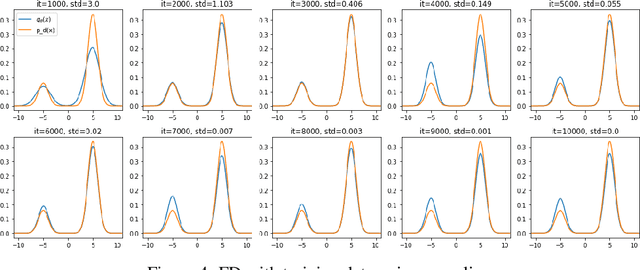
May 19, 2023Energy-Based Models (EBMs) offer a versatile framework for modeling complex data distributions. However, training and sampling from EBMs continue to pose significant challenges. The widely-used Denoising Score Matching (DSM) method for scalable EBM training suffers from inconsistency issues, causing the energy model to learn a `noisy' data distribution. In this work, we propose an efficient sampling framework: (pseudo)-Gibbs sampling with moment matching, which enables effective sampling from the underlying clean model when given a `noisy' model that has been well-trained via DSM. We explore the benefits of our approach compared to related methods and demonstrate how to scale the method to high-dimensional datasets.
Towards Healing the Blindness of Score Matching
Sep 15, 2022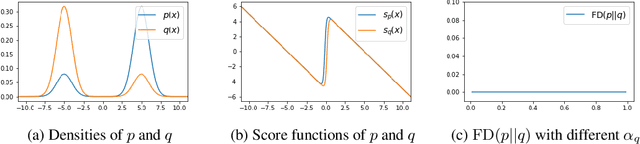
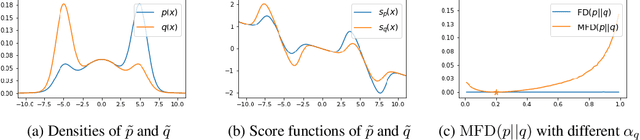
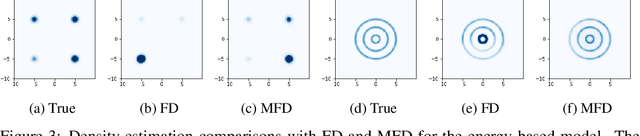
Score-based divergences have been widely used in machine learning and statistics applications. Despite their empirical success, a blindness problem has been observed when using these for multi-modal distributions. In this work, we discuss the blindness problem and propose a new family of divergences that can mitigate the blindness problem. We illustrate our proposed divergence in the context of density estimation and report improved performance compared to traditional approaches.
Integrated Weak Learning
Jun 19, 2022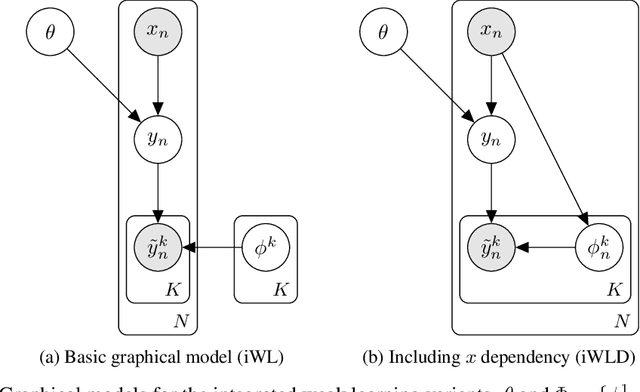
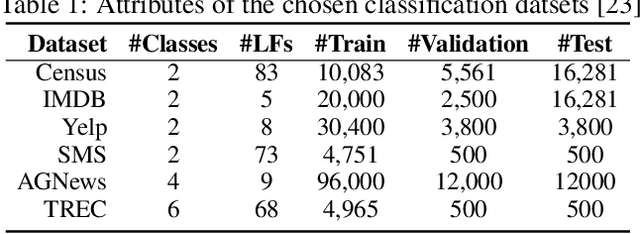
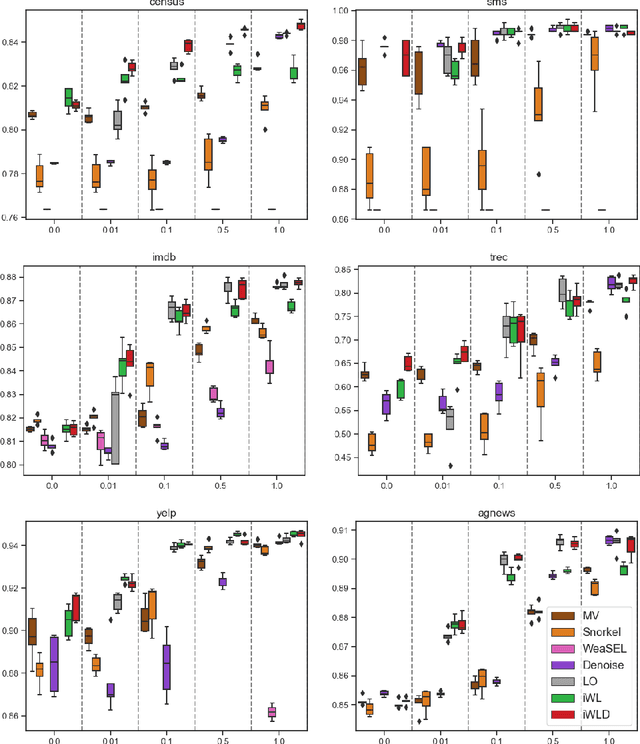
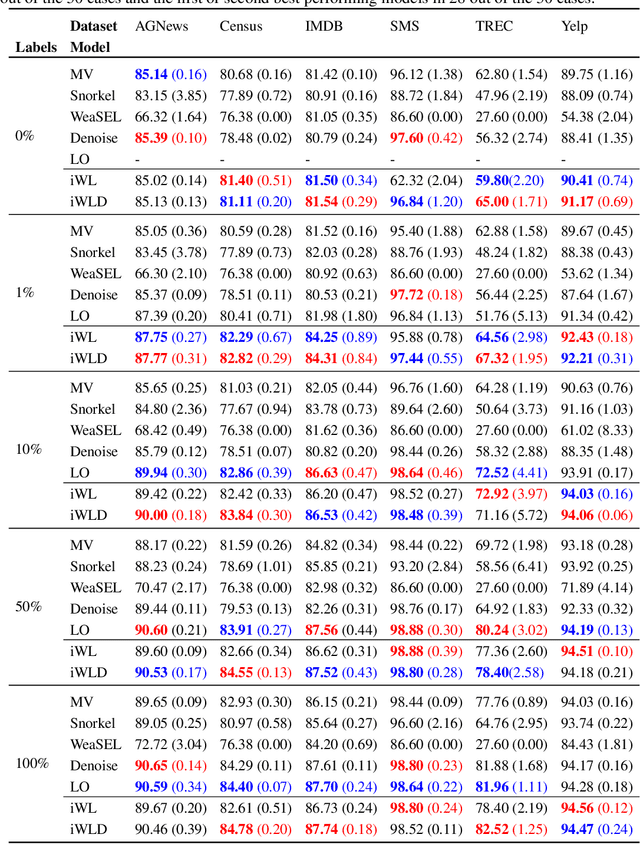
We introduce Integrated Weak Learning, a principled framework that integrates weak supervision into the training process of machine learning models. Our approach jointly trains the end-model and a label model that aggregates multiple sources of weak supervision. We introduce a label model that can learn to aggregate weak supervision sources differently for different datapoints and takes into consideration the performance of the end-model during training. We show that our approach outperforms existing weak learning techniques across a set of 6 benchmark classification datasets. When both a small amount of labeled data and weak supervision are present the increase in performance is both consistent and large, reliably getting a 2-5 point test F1 score gain over non-integrated methods.
Out-of-Distribution Detection with Class Ratio Estimation
Jun 08, 2022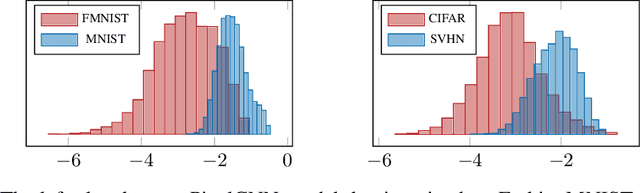
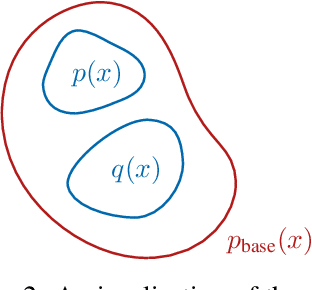
Density-based Out-of-distribution (OOD) detection has recently been shown unreliable for the task of detecting OOD images. Various density ratio based approaches achieve good empirical performance, however methods typically lack a principled probabilistic modelling explanation. In this work, we propose to unify density ratio based methods under a novel framework that builds energy-based models and employs differing base distributions. Under our framework, the density ratio can be viewed as the unnormalized density of an implicit semantic distribution. Further, we propose to directly estimate the density ratio of a data sample through class ratio estimation. We report competitive results on OOD image problems in comparison with recent work that alternatively requires training of deep generative models for the task. Our approach enables a simple and yet effective path towards solving the OOD detection problem.
Improving VAE-based Representation Learning
May 28, 2022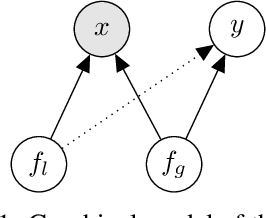

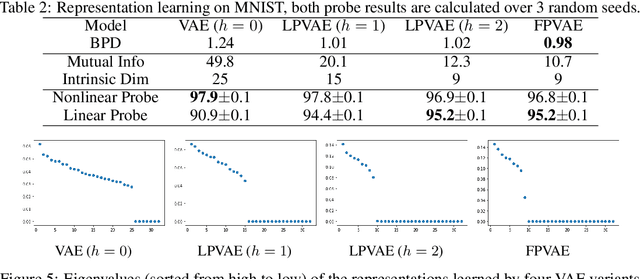
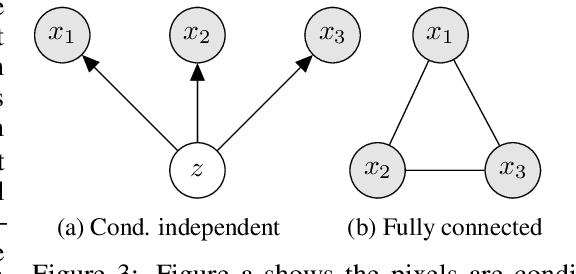
Latent variable models like the Variational Auto-Encoder (VAE) are commonly used to learn representations of images. However, for downstream tasks like semantic classification, the representations learned by VAE are less competitive than other non-latent variable models. This has led to some speculations that latent variable models may be fundamentally unsuitable for representation learning. In this work, we study what properties are required for good representations and how different VAE structure choices could affect the learned properties. We show that by using a decoder that prefers to learn local features, the remaining global features can be well captured by the latent, which significantly improves performance of a downstream classification task. We further apply the proposed model to semi-supervised learning tasks and demonstrate improvements in data efficiency.
Generalization Gap in Amortized Inference
May 23, 2022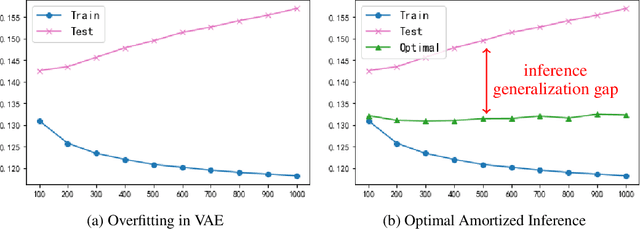
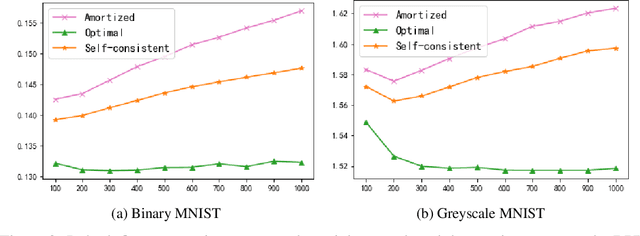
The ability of likelihood-based probabilistic models to generalize to unseen data is central to many machine learning applications such as lossless compression. In this work, we study the generalizations of a popular class of probabilistic models - the Variational Auto-Encoder (VAE). We point out the two generalization gaps that can affect the generalization ability of VAEs and show that the over-fitting phenomenon is usually dominated by the amortized inference network. Based on this observation we propose a new training objective, inspired by the classic wake-sleep algorithm, to improve the generalizations properties of amortized inference. We also demonstrate how it can improve generalization performance in the context of image modeling and lossless compression.
Parallel Neural Local Lossless Compression
Jan 23, 2022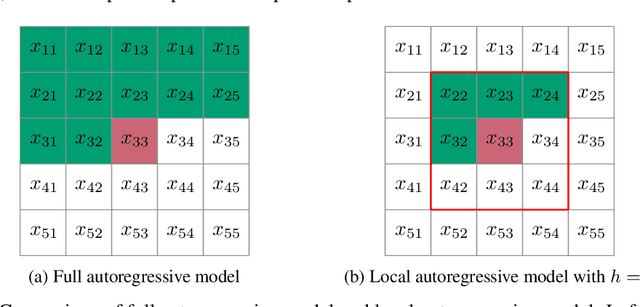
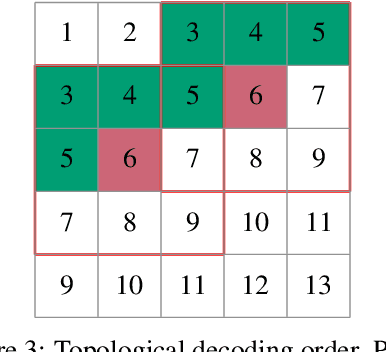

The recently proposed Neural Local Lossless Compression (NeLLoC), which is based on a local autoregressive model, has achieved state-of-the-art (SOTA) out-of-distribution (OOD) generalization performance in the image compression task. In addition to the encouragement of OOD generalization, the local model also allows parallel inference in the decoding stage. In this paper, we propose a parallelization scheme for local autoregressive models. We discuss the practicalities of implementing this scheme, and provide experimental evidence of significant gains in compression runtime compared to the previous, non-parallel implementation.
AFEC: Active Forgetting of Negative Transfer in Continual Learning
Nov 04, 2021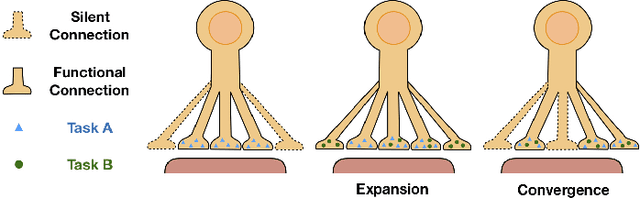
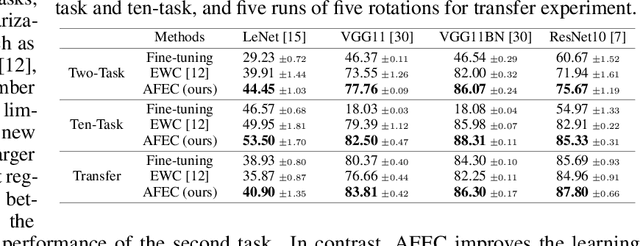
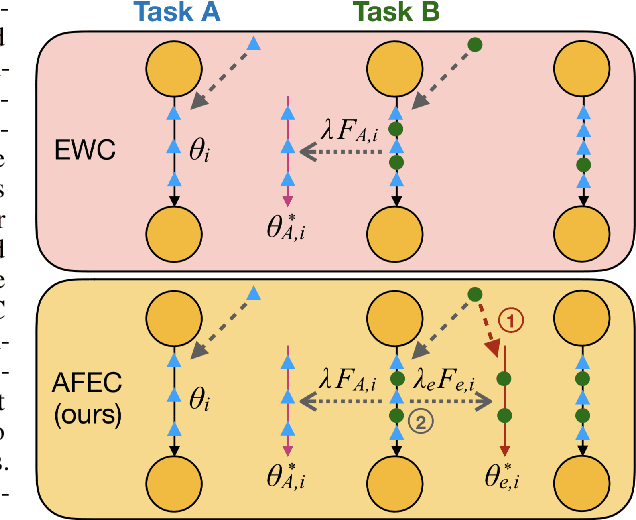
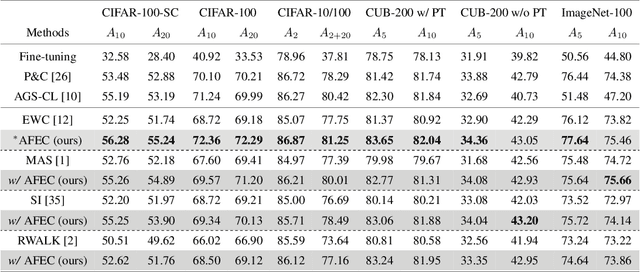
Continual learning aims to learn a sequence of tasks from dynamic data distributions. Without accessing to the old training samples, knowledge transfer from the old tasks to each new task is difficult to determine, which might be either positive or negative. If the old knowledge interferes with the learning of a new task, i.e., the forward knowledge transfer is negative, then precisely remembering the old tasks will further aggravate the interference, thus decreasing the performance of continual learning. By contrast, biological neural networks can actively forget the old knowledge that conflicts with the learning of a new experience, through regulating the learning-triggered synaptic expansion and synaptic convergence. Inspired by the biological active forgetting, we propose to actively forget the old knowledge that limits the learning of new tasks to benefit continual learning. Under the framework of Bayesian continual learning, we develop a novel approach named Active Forgetting with synaptic Expansion-Convergence (AFEC). Our method dynamically expands parameters to learn each new task and then selectively combines them, which is formally consistent with the underlying mechanism of biological active forgetting. We extensively evaluate AFEC on a variety of continual learning benchmarks, including CIFAR-10 regression tasks, visual classification tasks and Atari reinforcement tasks, where AFEC effectively improves the learning of new tasks and achieves the state-of-the-art performance in a plug-and-play way.
Flow Based Models For Manifold Data
Sep 29, 2021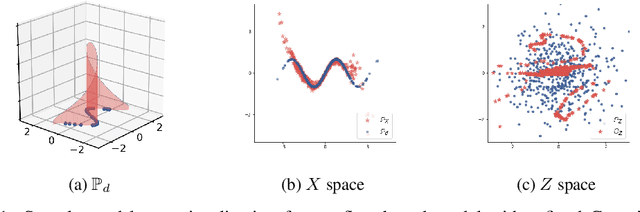
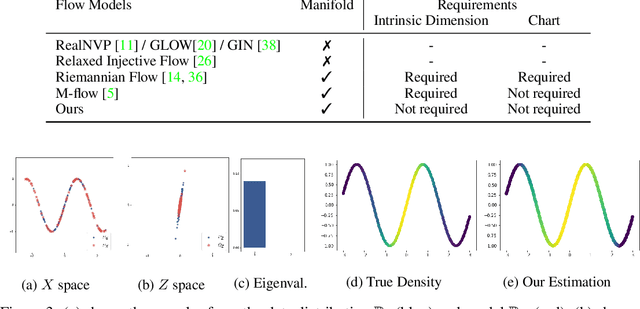

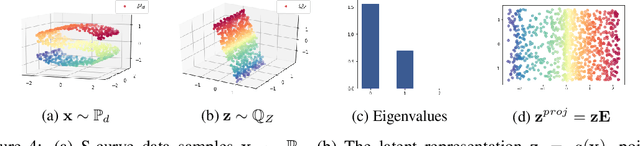
Flow-based generative models typically define a latent space with dimensionality identical to the observational space. In many problems, however, the data does not populate the full ambient data-space that they natively reside in, rather inhabiting a lower-dimensional manifold. In such scenarios, flow-based models are unable to represent data structures exactly as their density will always have support off the data manifold, potentially resulting in degradation of model performance. In addition, the requirement for equal latent and data space dimensionality can unnecessarily increase complexity for contemporary flow models. Towards addressing these problems, we propose to learn a manifold prior that affords benefits to both sample generation and representation quality. An auxiliary benefit of our approach is the ability to identify the intrinsic dimension of the data distribution.
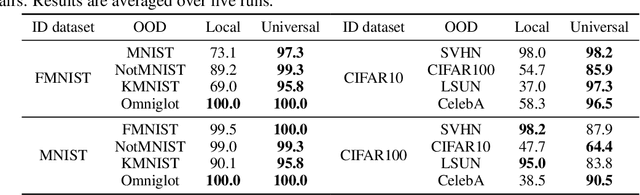
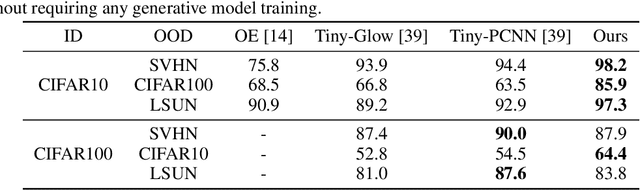
On the Out-of-distribution Generalization of Probabilistic Image Modelling
Sep 04, 2021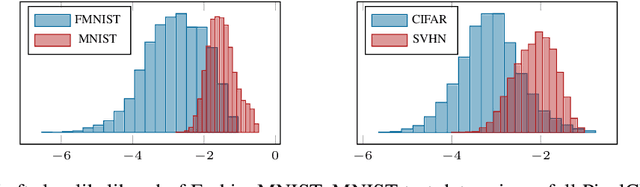


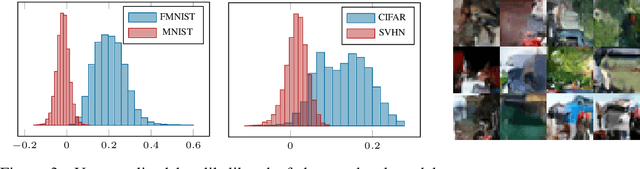
Out-of-distribution (OOD) detection and lossless compression constitute two problems that can be solved by the training of probabilistic models on a first dataset with subsequent likelihood evaluation on a second dataset, where data distributions differ. By defining the generalization of probabilistic models in terms of likelihood we show that, in the case of image models, the OOD generalization ability is dominated by local features. This motivates our proposal of a Local Autoregressive model that exclusively models local image features towards improving OOD performance. We apply the proposed model to OOD detection tasks and achieve state-of-the-art unsupervised OOD detection performance without the introduction of additional data. Additionally, we employ our model to build a new lossless image compressor: NeLLoC (Neural Local Lossless Compressor) and report state-of-the-art compression rates and model size.