 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Head Encoding for Extreme Label Classification
Dec 13, 2024



The number of categories of instances in the real world is normally huge, and each instance may contain multiple labels. To distinguish these massive labels utilizing machine learning, eXtreme Label Classification (XLC) has been established. However, as the number of categories increases, the number of parameters and nonlinear operations in the classifier also rises. This results in a Classifier Computational Overload Problem (CCOP). To address this, we propose a Multi-Head Encoding (MHE) mechanism, which replaces the vanilla classifier with a multi-head classifier. During the training process, MHE decomposes extreme labels into the product of multiple short local labels, with each head trained on these local labels. During testing, the predicted labels can be directly calculated from the local predictions of each head. This reduces the computational load geometrically. Then, according to the characteristics of different XLC tasks, e.g., single-label, multi-label, and model pretraining tasks, three MHE-based implementations, i.e., Multi-Head Product, Multi-Head Cascade, and Multi-Head Sampling, are proposed to more effectively cope with CCOP. Moreover, we theoretically demonstrate that MHE can achieve performance approximately equivalent to that of the vanilla classifier by generalizing the low-rank approximation problem from Frobenius-norm to Cross-Entropy. Experimental results show that the proposed methods achieve state-of-the-art performance while significantly streamlining the training and inference processes of XLC tasks. The source code has been made public at https://github.com/Anoise/MHE.
Act Now: A Novel Online Forecasting Framework for Large-Scale Streaming Data
Nov 28, 2024



In this paper, we find that existing online forecasting methods have the following issues: 1) They do not consider the update frequency of streaming data and directly use labels (future signals) to update the model, leading to information leakage. 2) Eliminating information leakage can exacerbate concept drift and online parameter updates can damage prediction accuracy. 3) Leaving out a validation set cuts off the model's continued learning. 4) Existing GPU devices cannot support online learning of large-scale streaming data. To address the above issues, we propose a novel online learning framework, Act-Now, to improve the online prediction on large-scale streaming data. Firstly, we introduce a Random Subgraph Sampling (RSS) algorithm designed to enable efficient model training. Then, we design a Fast Stream Buffer (FSB) and a Slow Stream Buffer (SSB) to update the model online. FSB updates the model immediately with the consistent pseudo- and partial labels to avoid information leakage. SSB updates the model in parallel using complete labels from earlier times. Further, to address concept drift, we propose a Label Decomposition model (Lade) with statistical and normalization flows. Lade forecasts both the statistical variations and the normalized future values of the data, integrating them through a combiner to produce the final predictions. Finally, we propose to perform online updates on the validation set to ensure the consistency of model learning on streaming data. Extensive experiments demonstrate that the proposed Act-Now framework performs well on large-scale streaming data, with an average 28.4% and 19.5% performance improvement, respectively. Experiments can be reproduced via https://github.com/Anoise/Act-Now.
Minusformer: Improving Time Series Forecasting by Progressively Learning Residuals
Feb 04, 2024



In this paper, we find that ubiquitous time series (TS) forecasting models are prone to severe overfitting. To cope with this problem, we embrace a de-redundancy approach to progressively reinstate the intrinsic values of TS for future intervals. Specifically, we renovate the vanilla Transformer by reorienting the information aggregation mechanism from addition to subtraction. Then, we incorporate an auxiliary output branch into each block of the original model to construct a highway leading to the ultimate prediction. The output of subsequent modules in this branch will subtract the previously learned results, enabling the model to learn the residuals of the supervision signal, layer by layer. This designing facilitates the learning-driven implicit progressive decomposition of the input and output streams, empowering the model with heightened versatility, interpretability, and resilience against overfitting. Since all aggregations in the model are minus signs, which is called Minusformer. Extensive experiments demonstrate the proposed method outperform existing state-of-the-art methods, yielding an average performance improvement of 11.9% across various datasets.
A WINNER+ Based 3-D Non-Stationary Wideband MIMO Channel Model
Dec 01, 2023In this paper, a three-dimensional (3-D) non-stationary wideband multiple-input multiple-output (MIMO) channel model based on the WINNER+ channel model is proposed. The angular distributions of clusters in both the horizontal and vertical planes are jointly considered. The receiver and clusters can be moving, which makes the model more general. Parameters including number of clusters, powers, delays, azimuth angles of departure (AAoDs), azimuth angles of arrival (AAoAs), elevation angles of departure (EAoDs), and elevation angles of arrival (EAoAs) are time-variant. The cluster time evolution is modeled using a birth-death process. Statistical properties, including spatial cross-correlation function (CCF), temporal autocorrelation function (ACF), Doppler power spectrum density (PSD), level-crossing rate (LCR), average fading duration (AFD), and stationary interval are investigated and analyzed. The LCR, AFD, and stationary interval of the proposed channel model are validated against the measurement data. Numerical and simulation results show that the proposed channel model has the ability to reproduce the main properties of real non-stationary channels. Furthermore, the proposed channel model can be adapted to various communication scenarios by adjusting different parameter values.
Does Long-Term Series Forecasting Need Complex Attention and Extra Long Inputs?
Jun 13, 2023



As Transformer-based models have achieved impressive performance on various time series tasks, Long-Term Series Forecasting (LTSF) tasks have also received extensive attention in recent years. However, due to the inherent computational complexity and long sequences demanding of Transformer-based methods, its application on LTSF tasks still has two major issues that need to be further investigated: 1) Whether the sparse attention mechanism designed by these methods actually reduce the running time on real devices; 2) Whether these models need extra long input sequences to guarantee their performance? The answers given in this paper are negative. Therefore, to better copy with these two issues, we design a lightweight Period-Attention mechanism (Periodformer), which renovates the aggregation of long-term subseries via explicit periodicity and short-term subseries via built-in proximity. Meanwhile, a gating mechanism is embedded into Periodformer to regulate the influence of the attention module on the prediction results. Furthermore, to take full advantage of GPUs for fast hyperparameter optimization (e.g., finding the suitable input length), a Multi-GPU Asynchronous parallel algorithm based on Bayesian Optimization (MABO) is presented. MABO allocates a process to each GPU via a queue mechanism, and then creates multiple trials at a time for asynchronous parallel search, which greatly reduces the search time. Compared with the state-of-the-art methods, the prediction error of Periodformer reduced by 13% and 26% for multivariate and univariate forecasting, respectively. In addition, MABO reduces the average search time by 46% while finding better hyperparameters. As a conclusion, this paper indicates that LTSF may not need complex attention and extra long input sequences. The code has been open sourced on Github.
A General 3D Non-Stationary Wireless Channel Model for 5G and Beyond
Jan 17, 2021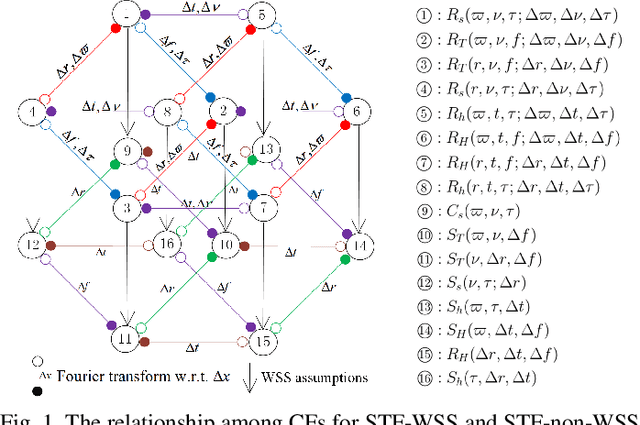
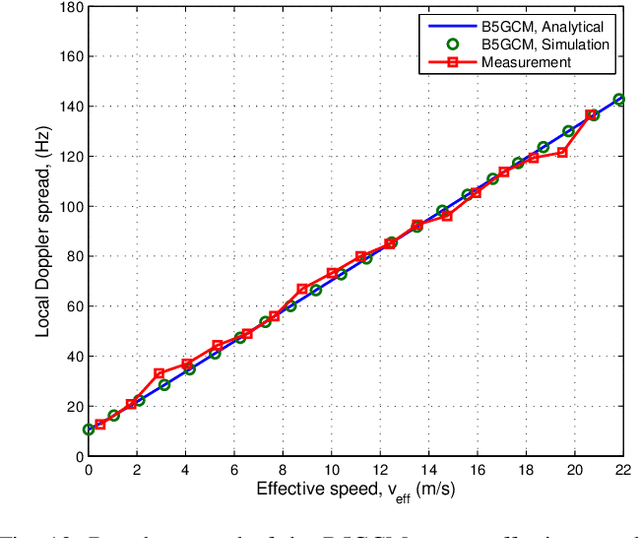
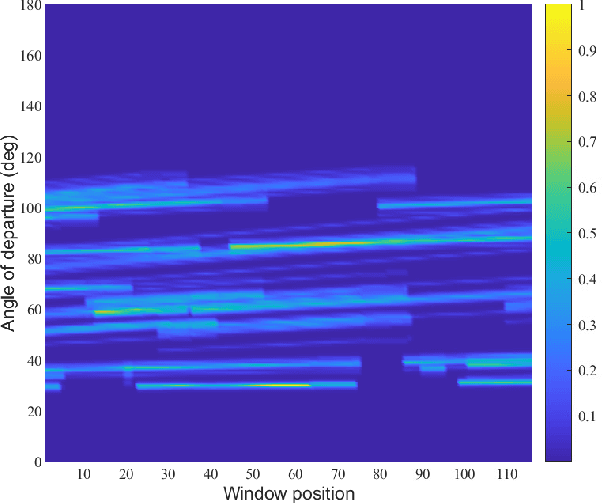
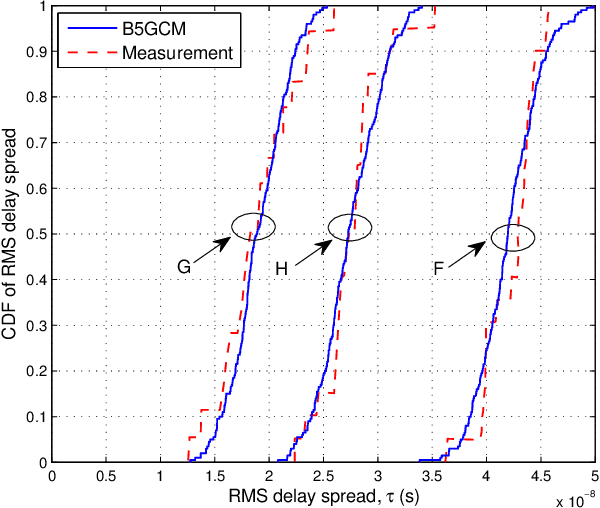
In this paper, a novel three-dimensional (3D) non-stationary geometry-based stochastic model (GBSM) for the fifth generation (5G) and beyond 5G (B5G) systems is proposed. The proposed B5G channel model (B5GCM) is designed to capture various channel characteristics in (B)5G systems such as space-time-frequency (STF) non-stationarity, spherical wavefront (SWF), high delay resolution, time-variant velocities and directions of motion of the transmitter, receiver, and scatterers, spatial consistency, etc. By combining different channel properties into a general channel model framework, the proposed B5GCM is able to be applied to multiple frequency bands and multiple scenarios, including massive multiple-input multiple-output (MIMO), vehicle-to-vehicle (V2V), high-speed train (HST), and millimeter wave-terahertz (mmWave-THz) communication scenarios. Key statistics of the proposed B5GCM are obtained and compared with those of standard 5G channel models and corresponding measurement data, showing the generalization and usefulness of the proposed model.