 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval as Generation: A Unified Framework with Self-Triggered Information Planning
Apr 13, 2026We revisit retrieval-augmented generation (RAG) by embedding retrieval control directly into generation. Instead of treating retrieval as an external intervention, we express retrieval decisions within token-level decoding, enabling end-to-end coordination without additional controllers or classifiers. Under the paradigm of Retrieval as Generation, we propose \textbf{GRIP} (\textbf{G}eneration-guided \textbf{R}etrieval with \textbf{I}nformation \textbf{P}lanning), a unified framework in which the model regulates retrieval behavior through control-token emission. Central to GRIP is \textit{Self-Triggered Information Planning}, which allows the model to decide when to retrieve, how to reformulate queries, and when to terminate, all within a single autoregressive trajectory. This design tightly couples retrieval and reasoning and supports dynamic multi-step inference with on-the-fly evidence integration. To supervise these behaviors, we construct a structured training set covering answerable, partially answerable, and multi-hop queries, each aligned with specific token patterns. Experiments on five QA benchmarks show that GRIP surpasses strong RAG baselines and is competitive with GPT-4o while using substantially fewer parameters.
* Github: https://github.com/WisdomShell/GRIP HuggingFace:https://huggingface.co/collections/WisdomShell/grip
Instruction Data Selection via Answer Divergence
Apr 12, 2026Instruction tuning relies on large instruction-response corpora whose quality and composition strongly affect downstream performance. We propose Answer Divergence-Guided Selection (ADG), which selects instruction data based on the geometric structure of multi-sample outputs. ADG draws several high-temperature generations per instruction, maps responses into an embedding space, and computes an output divergence score that jointly encodes dispersion magnitude and shape anisotropy. High scores correspond to instructions whose answers are both far apart and multi-modal, rather than clustered paraphrases along a single direction. Across two backbones and three public instruction pools, fine-tuning on only 10K ADG-selected examples consistently outperforms strong selectors on six benchmarks spanning reasoning, knowledge, and coding. Analyses further show that both dispersion magnitude and shape anisotropy are necessary, supporting answer divergence as a practical signal for instruction data selection. Code and appendix are included in the supplementary materials.
* Github: https://github.com/WisdomShell/ADG Project: https://wisdomshell.github.io/ADG/
Enhancing Non-mass Breast Ultrasound Cancer Classification With Knowledge Transfer
Apr 18, 2022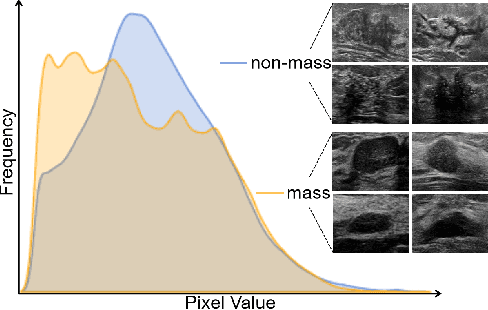

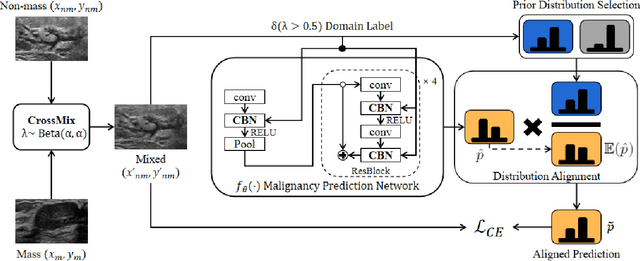
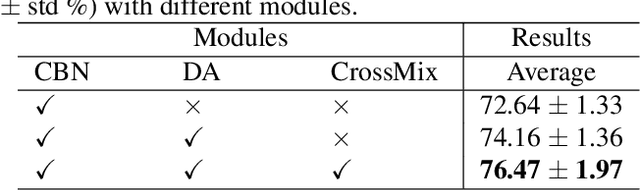
Much progress has been made in the deep neural network (DNN) based diagnosis of mass lesions breast ultrasound (BUS) images. However, the non-mass lesion is less investigated because of the limited data. Based on the insight that mass data is sufficient and shares the same knowledge structure with non-mass data of identifying the malignancy of a lesion based on the ultrasound image, we propose a novel transfer learning framework to enhance the generalizability of the DNN model for non-mass BUS with the help of mass BUS. Specifically, we train a shared DNN with combined non-mass and mass data. With the prior of different marginal distributions in input and output space, we employ two domain alignment strategies in the proposed transfer learning framework with the insight of capturing domain-specific distribution to address the issue of domain shift. Moreover, we propose a cross-domain semantic-preserve data generation module called CrossMix to recover the missing distribution between non-mass and mass data that is not presented in training data. Experimental results on an in-house dataset demonstrate that the DNN model trained with combined data by our framework achieves a 10% improvement in AUC on the malignancy prediction task of non-mass BUS compared to training directly on non-mass data.