 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQRF: Implicit Neural Representations with Quantum Radiance Fields
Nov 16, 2022



Photorealistic rendering of real-world scenes is a tremendous challenge with a wide range of applications, including mixed reality (MR), and virtual reality (VR). Neural networks, which have long been investigated in the context of solving differential equations, have previously been introduced as implicit representations for photorealistic rendering. However, realistic rendering using classic computing is challenging because it requires time-consuming optical ray marching, and suffer computational bottlenecks due to the curse of dimensionality. In this paper, we propose Quantum Radiance Fields (QRF), which integrate the quantum circuit, quantum activation function, and quantum volume rendering for implicit scene representation. The results indicate that QRF not only exploits the advantage of quantum computing, such as high speed, fast convergence, and high parallelism, but also ensure high quality of volume rendering.
360-MLC: Multi-view Layout Consistency for Self-training and Hyper-parameter Tuning
Oct 24, 2022We present 360-MLC, a self-training method based on multi-view layout consistency for finetuning monocular room-layout models using unlabeled 360-images only. This can be valuable in practical scenarios where a pre-trained model needs to be adapted to a new data domain without using any ground truth annotations. Our simple yet effective assumption is that multiple layout estimations in the same scene must define a consistent geometry regardless of their camera positions. Based on this idea, we leverage a pre-trained model to project estimated layout boundaries from several camera views into the 3D world coordinate. Then, we re-project them back to the spherical coordinate and build a probability function, from which we sample the pseudo-labels for self-training. To handle unconfident pseudo-labels, we evaluate the variance in the re-projected boundaries as an uncertainty value to weight each pseudo-label in our loss function during training. In addition, since ground truth annotations are not available during training nor in testing, we leverage the entropy information in multiple layout estimations as a quantitative metric to measure the geometry consistency of the scene, allowing us to evaluate any layout estimator for hyper-parameter tuning, including model selection without ground truth annotations. Experimental results show that our solution achieves favorable performance against state-of-the-art methods when self-training from three publicly available source datasets to a unique, newly labeled dataset consisting of multi-view of the same scenes.
BiFuse++: Self-supervised and Efficient Bi-projection Fusion for 360 Depth Estimation
Sep 07, 2022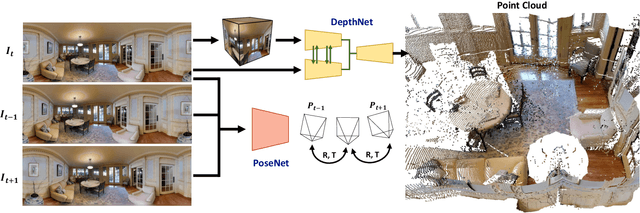
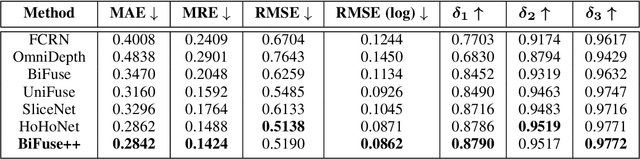

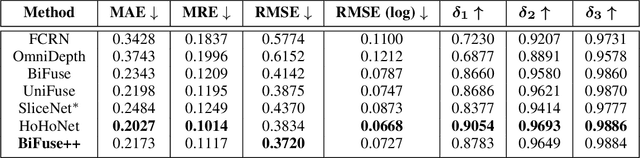
Due to the rise of spherical cameras, monocular 360 depth estimation becomes an important technique for many applications (e.g., autonomous systems). Thus, state-of-the-art frameworks for monocular 360 depth estimation such as bi-projection fusion in BiFuse are proposed. To train such a framework, a large number of panoramas along with the corresponding depth ground truths captured by laser sensors are required, which highly increases the cost of data collection. Moreover, since such a data collection procedure is time-consuming, the scalability of extending these methods to different scenes becomes a challenge. To this end, self-training a network for monocular depth estimation from 360 videos is one way to alleviate this issue. However, there are no existing frameworks that incorporate bi-projection fusion into the self-training scheme, which highly limits the self-supervised performance since bi-projection fusion can leverage information from different projection types. In this paper, we propose BiFuse++ to explore the combination of bi-projection fusion and the self-training scenario. To be specific, we propose a new fusion module and Contrast-Aware Photometric Loss to improve the performance of BiFuse and increase the stability of self-training on real-world videos. We conduct both supervised and self-supervised experiments on benchmark datasets and achieve state-of-the-art performance.
Semiconductor Defect Detection by Hybrid Classical-Quantum Deep Learning
Aug 06, 2022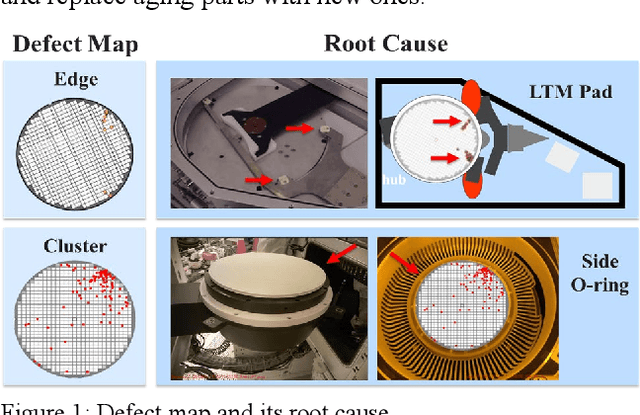



With the rapid development of artificial intelligence and autonomous driving technology, the demand for semiconductors is projected to rise substantially. However, the massive expansion of semiconductor manufacturing and the development of new technology will bring many defect wafers. If these defect wafers have not been correctly inspected, the ineffective semiconductor processing on these defect wafers will cause additional impact to our environment, such as excessive carbon dioxide emission and energy consumption. In this paper, we utilize the information processing advantages of quantum computing to promote the defect learning defect review (DLDR). We propose a classical-quantum hybrid algorithm for deep learning on near-term quantum processors. By tuning parameters implemented on it, quantum circuit driven by our framework learns a given DLDR task, include of wafer defect map classification, defect pattern classification, and hotspot detection. In addition, we explore parametrized quantum circuits with different expressibility and entangling capacities. These results can be used to build a future roadmap to develop circuit-based quantum deep learning for semiconductor defect detection.
Autoregressive 3D Shape Generation via Canonical Mapping
Apr 05, 2022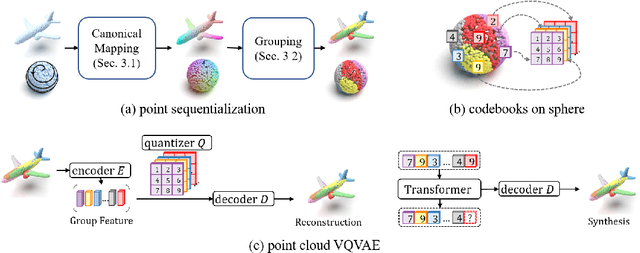
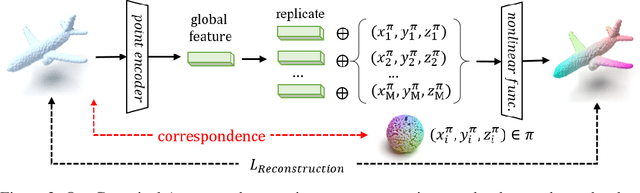
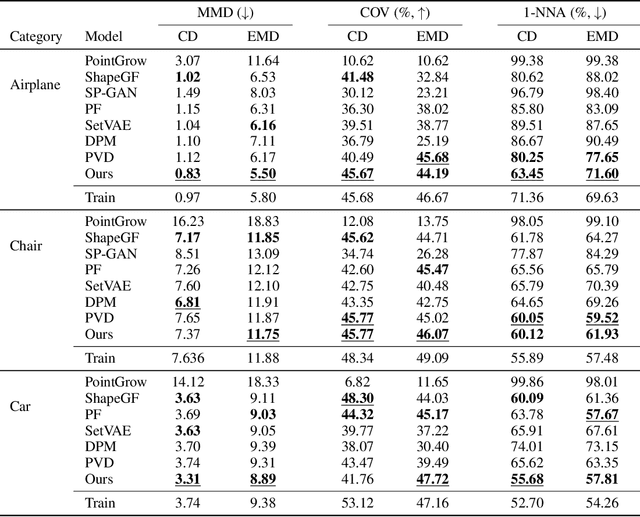
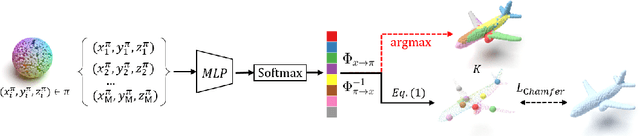
With the capacity of modeling long-range dependencies in sequential data, transformers have shown remarkable performances in a variety of generative tasks such as image, audio, and text generation. Yet, taming them in generating less structured and voluminous data formats such as high-resolution point clouds have seldom been explored due to ambiguous sequentialization processes and infeasible computation burden. In this paper, we aim to further exploit the power of transformers and employ them for the task of 3D point cloud generation. The key idea is to decompose point clouds of one category into semantically aligned sequences of shape compositions, via a learned canonical space. These shape compositions can then be quantized and used to learn a context-rich composition codebook for point cloud generation. Experimental results on point cloud reconstruction and unconditional generation show that our model performs favorably against state-of-the-art approaches. Furthermore, our model can be easily extended to multi-modal shape completion as an application for conditional shape generation.
Data Efficient 3D Learner via Knowledge Transferred from 2D Model
Mar 17, 2022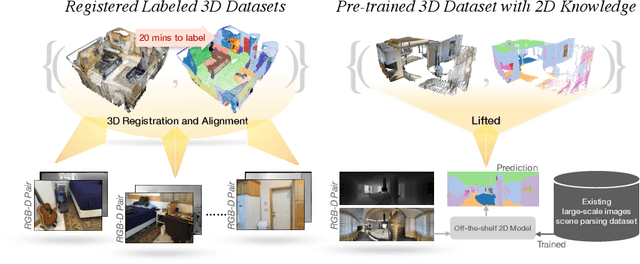
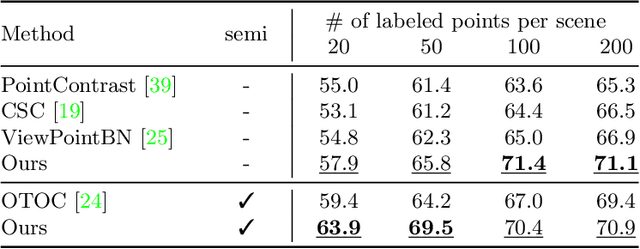
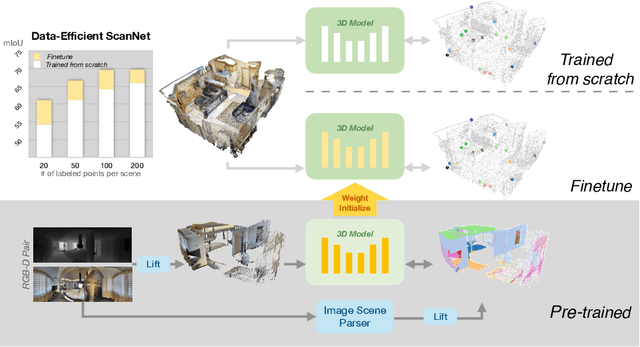
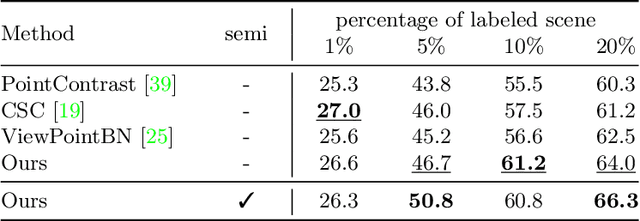
Collecting and labeling the registered 3D point cloud is costly. As a result, 3D resources for training are typically limited in quantity compared to the 2D images counterpart. In this work, we deal with the data scarcity challenge of 3D tasks by transferring knowledge from strong 2D models via RGB-D images. Specifically, we utilize a strong and well-trained semantic segmentation model for 2D images to augment RGB-D images with pseudo-label. The augmented dataset can then be used to pre-train 3D models. Finally, by simply fine-tuning on a few labeled 3D instances, our method already outperforms existing state-of-the-art that is tailored for 3D label efficiency. We also show that the results of mean-teacher and entropy minimization can be improved by our pre-training, suggesting that the transferred knowledge is helpful in semi-supervised setting. We verify the effectiveness of our approach on two popular 3D models and three different tasks. On ScanNet official evaluation, we establish new state-of-the-art semantic segmentation results on the data-efficient track.
CLA-NeRF: Category-Level Articulated Neural Radiance Field
Feb 01, 2022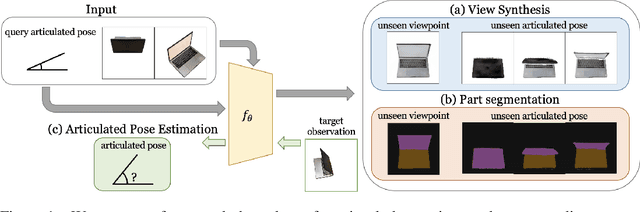
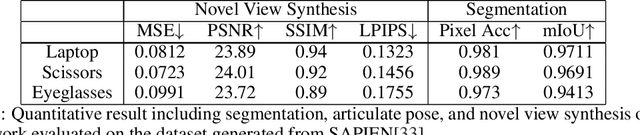
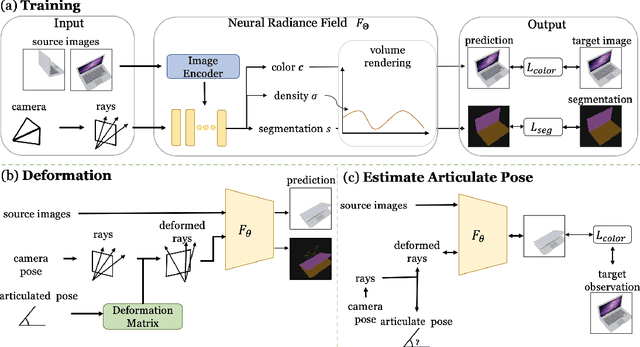
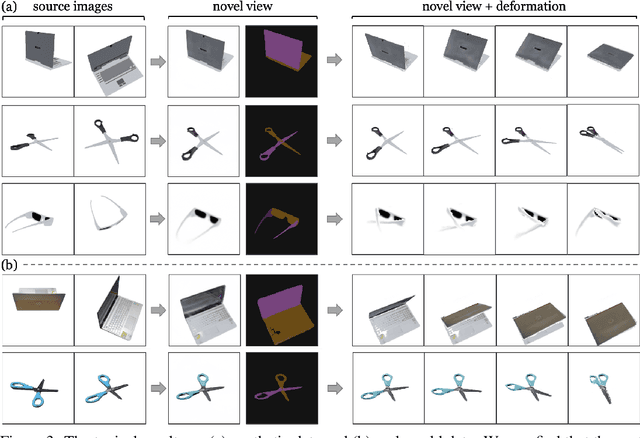
We propose CLA-NeRF -- a Category-Level Articulated Neural Radiance Field that can perform view synthesis, part segmentation, and articulated pose estimation. CLA-NeRF is trained at the object category level using no CAD models and no depth, but a set of RGB images with ground truth camera poses and part segments. During inference, it only takes a few RGB views (i.e., few-shot) of an unseen 3D object instance within the known category to infer the object part segmentation and the neural radiance field. Given an articulated pose as input, CLA-NeRF can perform articulation-aware volume rendering to generate the corresponding RGB image at any camera pose. Moreover, the articulated pose of an object can be estimated via inverse rendering. In our experiments, we evaluate the framework across five categories on both synthetic and real-world data. In all cases, our method shows realistic deformation results and accurate articulated pose estimation. We believe that both few-shot articulated object rendering and articulated pose estimation open doors for robots to perceive and interact with unseen articulated objects.
360-DFPE: Leveraging Monocular 360-Layouts for Direct Floor Plan Estimation
Dec 21, 2021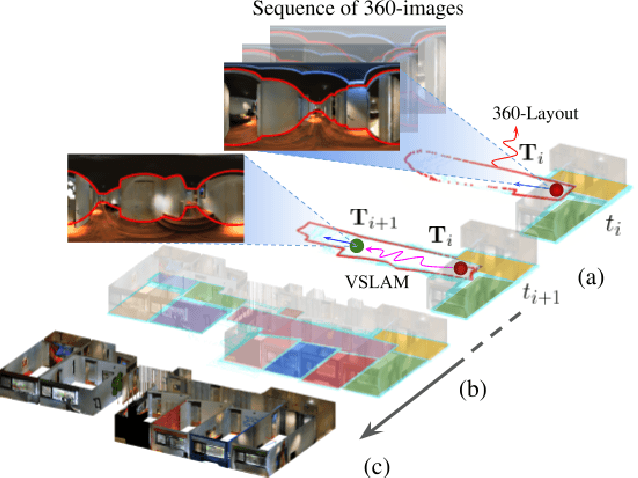
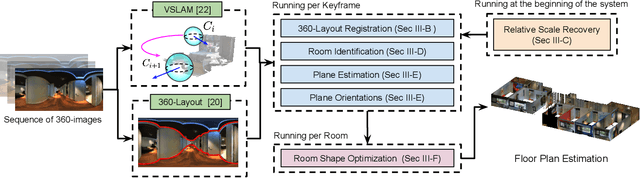
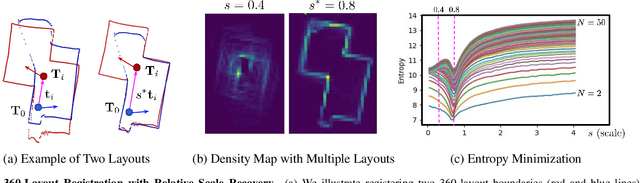
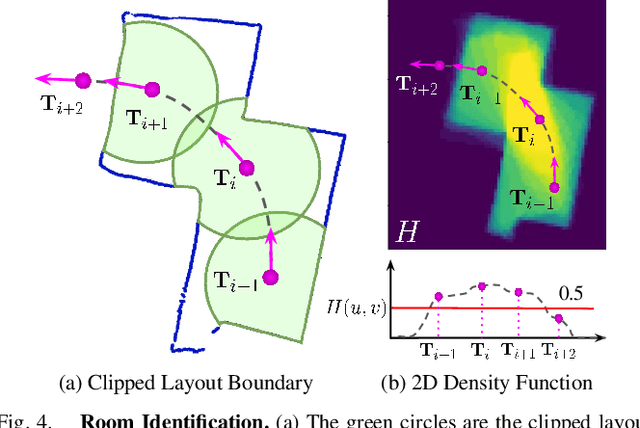
We present 360-DFPE, a sequential floor plan estimation method that directly takes 360-images as input without relying on active sensors or 3D information. Our approach leverages a loosely coupled integration between a monocular visual SLAM solution and a monocular 360-room layout approach, which estimate camera poses and layout geometries, respectively. Since our task is to sequentially capture the floor plan using monocular images, the entire scene structure, room instances, and room shapes are unknown. To tackle these challenges, we first handle the scale difference between visual odometry and layout geometry via formulating an entropy minimization process, which enables us to directly align 360-layouts without knowing the entire scene in advance. Second, to sequentially identify individual rooms, we propose a novel room identification algorithm that tracks every room along the camera exploration using geometry information. Lastly, to estimate the final shape of the room, we propose a shortest path algorithm with an iterative coarse-to-fine strategy, which improves prior formulations with higher accuracy and faster run-time. Moreover, we collect a new floor plan dataset with challenging large-scale scenes, providing both point clouds and sequential 360-image information. Experimental results show that our monocular solution achieves favorable performance against the current state-of-the-art algorithms that rely on active sensors and require the entire scene reconstruction data in advance. Our code and dataset will be released soon.
Meta-CPR: Generalize to Unseen Large Number of Agents with Communication Pattern Recognition Module
Dec 15, 2021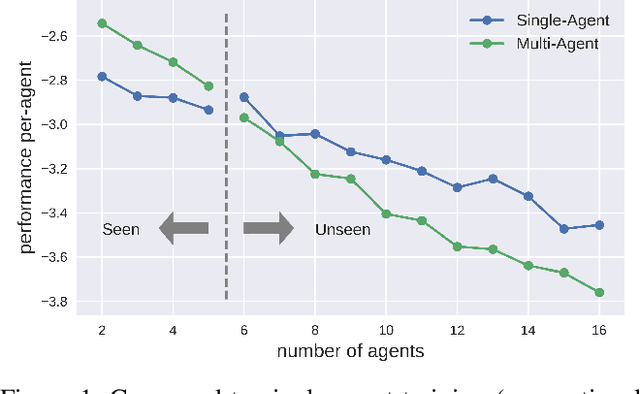
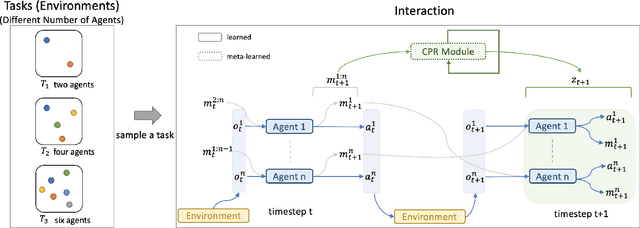
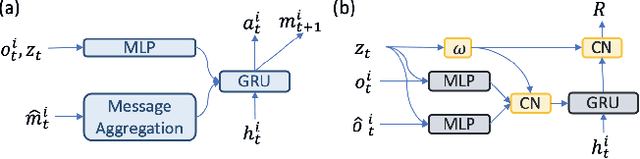
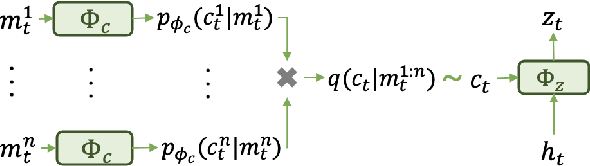
Designing an effective communication mechanism among agents in reinforcement learning has been a challenging task, especially for real-world applications. The number of agents can grow or an environment sometimes needs to interact with a changing number of agents in real-world scenarios. To this end, a multi-agent framework needs to handle various scenarios of agents, in terms of both scales and dynamics, for being practical to real-world applications. We formulate the multi-agent environment with a different number of agents as a multi-tasking problem and propose a meta reinforcement learning (meta-RL) framework to tackle this problem. The proposed framework employs a meta-learned Communication Pattern Recognition (CPR) module to identify communication behavior and extract information that facilitates the training process. Experimental results are poised to demonstrate that the proposed framework (a) generalizes to an unseen larger number of agents and (b) allows the number of agents to change between episodes. The ablation study is also provided to reason the proposed CPR design and show such design is effective.
Leveraging Sequence Embedding and Convolutional Neural Network for Protein Function Prediction
Dec 01, 2021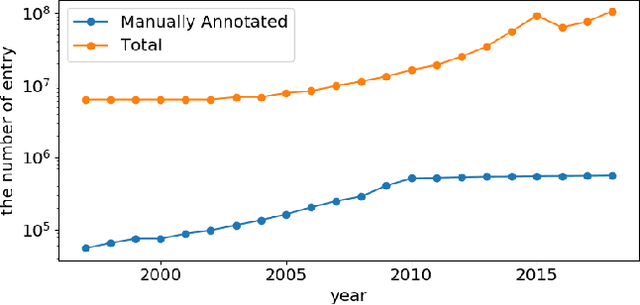
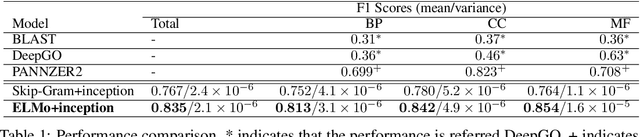
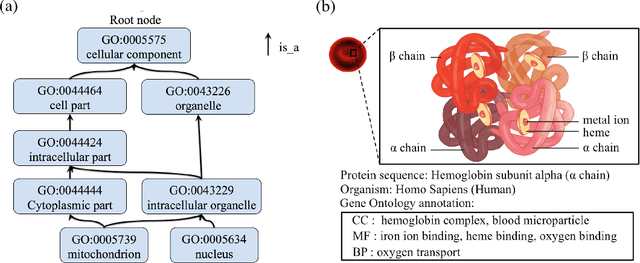
The capability of accurate prediction of protein functions and properties is essential in the biotechnology industry, e.g. drug development and artificial protein synthesis, etc. The main challenges of protein function prediction are the large label space and the lack of labeled training data. Our method leverages unsupervised sequence embedding and the success of deep convolutional neural network to overcome these challenges. In contrast, most of the existing methods delete the rare protein functions to reduce the label space. Furthermore, some existing methods require additional bio-information (e.g., the 3-dimensional structure of the proteins) which is difficult to be determined in biochemical experiments. Our proposed method significantly outperforms the other methods on the publicly available benchmark using only protein sequences as input. This allows the process of identifying protein functions to be sped up.