 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lie We Tell: Correcting the Euclidean Fallacy in Vision Language Action Policies via Score Matching on Tangent Space
Jun 01, 2026Diffusion-based Vision-Language-Action policies achieve remarkable success in robotic manipulation, yet commit a fundamental geometric error we term the $\textbf{Euclidean Fallacy}$: representing SE(3) poses as flat $\mathbb{R}^{12}$ vectors. This approximation induces (1) manifold drift violating SO(3) constraints, (2) broken equivariance under coordinate transformations, and (3) non-geodesic trajectories with excessive kinematic cost. We introduce $\textbf{Lie Diffuser Actor (LDA)}$, a diffusion framework operating intrinsically on SE(3). Our method injects noise through left-invariant SDEs, predicts scores in the tangent space, and retracts samples via the exponential map. This formulation eliminates manifold drift by construction while guaranteeing coordinate-frame equivariance and geodesic optimality. On CALVIN ABC$\rightarrow$D, LDA improves average task length from $3.27$ to $3.51$ ($+7.3\%$). We further validate our method on real robot and the results show that our methodology outperforms the baseline on majority tasks.
SceneFoundry: Generating Interactive Infinite 3D Worlds
Jan 09, 2026The ability to automatically generate large-scale, interactive, and physically realistic 3D environments is crucial for advancing robotic learning and embodied intelligence. However, existing generative approaches often fail to capture the functional complexity of real-world interiors, particularly those containing articulated objects with movable parts essential for manipulation and navigation. This paper presents SceneFoundry, a language-guided diffusion framework that generates apartment-scale 3D worlds with functionally articulated furniture and semantically diverse layouts for robotic training. From natural language prompts, an LLM module controls floor layout generation, while diffusion-based posterior sampling efficiently populates the scene with articulated assets from large-scale 3D repositories. To ensure physical usability, SceneFoundry employs differentiable guidance functions to regulate object quantity, prevent articulation collisions, and maintain sufficient walkable space for robotic navigation. Extensive experiments demonstrate that our framework generates structurally valid, semantically coherent, and functionally interactive environments across diverse scene types and conditions, enabling scalable embodied AI research.
CritiFusion: Semantic Critique and Spectral Alignment for Faithful Text-to-Image Generation
Dec 31, 2025Recent text-to-image diffusion models have achieved remarkable visual fidelity but often struggle with semantic alignment to complex prompts. We introduce CritiFusion, a novel inference-time framework that integrates a multimodal semantic critique mechanism with frequency-domain refinement to improve text-to-image consistency and detail. The proposed CritiCore module leverages a vision-language model and multiple large language models to enrich the prompt context and produce high-level semantic feedback, guiding the diffusion process to better align generated content with the prompt's intent. Additionally, SpecFusion merges intermediate generation states in the spectral domain, injecting coarse structural information while preserving high-frequency details. No additional model training is required. CritiFusion serves as a plug-in refinement stage compatible with existing diffusion backbones. Experiments on standard benchmarks show that our method notably improves human-aligned metrics of text-to-image correspondence and visual quality. CritiFusion consistently boosts performance on human preference scores and aesthetic evaluations, achieving results on par with state-of-the-art reward optimization approaches. Qualitative results further demonstrate superior detail, realism, and prompt fidelity, indicating the effectiveness of our semantic critique and spectral alignment strategy.
Towards Open-Vocabulary Industrial Defect Understanding with a Large-Scale Multimodal Dataset
Dec 30, 2025We present IMDD-1M, the first large-scale Industrial Multimodal Defect Dataset comprising 1,000,000 aligned image-text pairs, designed to advance multimodal learning for manufacturing and quality inspection. IMDD-1M contains high-resolution real-world defects spanning over 60 material categories and more than 400 defect types, each accompanied by expert-verified annotations and fine-grained textual descriptions detailing defect location, severity, and contextual attributes. This dataset enables a wide spectrum of applications, including classification, segmentation, retrieval, captioning, and generative modeling. Building upon IMDD-1M, we train a diffusion-based vision-language foundation model from scratch, specifically tailored for industrial scenarios. The model serves as a generalizable foundation that can be efficiently adapted to specialized domains through lightweight fine-tuning. With less than 5% of the task-specific data required by dedicated expert models, it achieves comparable performance, highlighting the potential of data-efficient foundation model adaptation for industrial inspection and generation, paving the way for scalable, domain-adaptive, and knowledge-grounded manufacturing intelligence.
Generative Digital Twins: Vision-Language Simulation Models for Executable Industrial Systems
Dec 23, 2025We propose a Vision-Language Simulation Model (VLSM) that unifies visual and textual understanding to synthesize executable FlexScript from layout sketches and natural-language prompts, enabling cross-modal reasoning for industrial simulation systems. To support this new paradigm, the study constructs the first large-scale dataset for generative digital twins, comprising over 120,000 prompt-sketch-code triplets that enable multimodal learning between textual descriptions, spatial structures, and simulation logic. In parallel, three novel evaluation metrics, Structural Validity Rate (SVR), Parameter Match Rate (PMR), and Execution Success Rate (ESR), are proposed specifically for this task to comprehensively evaluate structural integrity, parameter fidelity, and simulator executability. Through systematic ablation across vision encoders, connectors, and code-pretrained language backbones, the proposed models achieve near-perfect structural accuracy and high execution robustness. This work establishes a foundation for generative digital twins that integrate visual reasoning and language understanding into executable industrial simulation systems.
Semiconductor Defect Pattern Classification by Self-Proliferation-and-Attention Neural Network
Dec 01, 2022



Semiconductor manufacturing is on the cusp of a revolution: the Internet of Things (IoT). With IoT we can connect all the equipment and feed information back to the factory so that quality issues can be detected. In this situation, more and more edge devices are used in wafer inspection equipment. This edge device must have the ability to quickly detect defects. Therefore, how to develop a high-efficiency architecture for automatic defect classification to be suitable for edge devices is the primary task. In this paper, we present a novel architecture that can perform defect classification in a more efficient way. The first function is self-proliferation, using a series of linear transformations to generate more feature maps at a cheaper cost. The second function is self-attention, capturing the long-range dependencies of feature map by the channel-wise and spatial-wise attention mechanism. We named this method as self-proliferation-and-attention neural network. This method has been successfully applied to various defect pattern classification tasks. Compared with other latest methods, SP&A-Net has higher accuracy and lower computation cost in many defect inspection tasks.
QRF: Implicit Neural Representations with Quantum Radiance Fields
Nov 16, 2022



Photorealistic rendering of real-world scenes is a tremendous challenge with a wide range of applications, including mixed reality (MR), and virtual reality (VR). Neural networks, which have long been investigated in the context of solving differential equations, have previously been introduced as implicit representations for photorealistic rendering. However, realistic rendering using classic computing is challenging because it requires time-consuming optical ray marching, and suffer computational bottlenecks due to the curse of dimensionality. In this paper, we propose Quantum Radiance Fields (QRF), which integrate the quantum circuit, quantum activation function, and quantum volume rendering for implicit scene representation. The results indicate that QRF not only exploits the advantage of quantum computing, such as high speed, fast convergence, and high parallelism, but also ensure high quality of volume rendering.
Semiconductor Defect Detection by Hybrid Classical-Quantum Deep Learning
Aug 06, 2022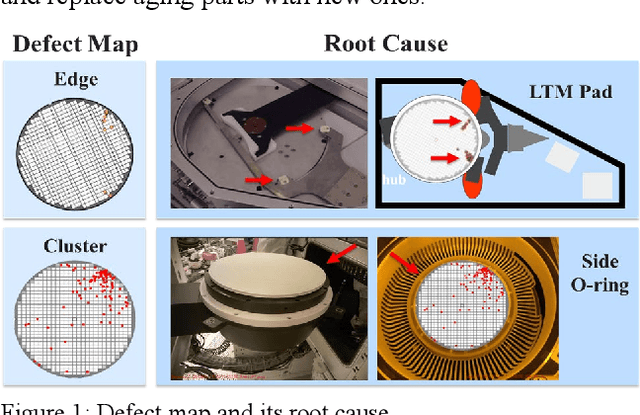



With the rapid development of artificial intelligence and autonomous driving technology, the demand for semiconductors is projected to rise substantially. However, the massive expansion of semiconductor manufacturing and the development of new technology will bring many defect wafers. If these defect wafers have not been correctly inspected, the ineffective semiconductor processing on these defect wafers will cause additional impact to our environment, such as excessive carbon dioxide emission and energy consumption. In this paper, we utilize the information processing advantages of quantum computing to promote the defect learning defect review (DLDR). We propose a classical-quantum hybrid algorithm for deep learning on near-term quantum processors. By tuning parameters implemented on it, quantum circuit driven by our framework learns a given DLDR task, include of wafer defect map classification, defect pattern classification, and hotspot detection. In addition, we explore parametrized quantum circuits with different expressibility and entangling capacities. These results can be used to build a future roadmap to develop circuit-based quantum deep learning for semiconductor defect detection.