 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Inference of the Lensing Convergence from Photometric Catalogs with Bayesian Graph Neural Networks
Nov 15, 2022We present a Bayesian graph neural network (BGNN) that can estimate the weak lensing convergence ($\kappa$) from photometric measurements of galaxies along a given line of sight. The method is of particular interest in strong gravitational time delay cosmography (TDC), where characterizing the "external convergence" ($\kappa_{\rm ext}$) from the lens environment and line of sight is necessary for precise inference of the Hubble constant ($H_0$). Starting from a large-scale simulation with a $\kappa$ resolution of $\sim$1$'$, we introduce fluctuations on galaxy-galaxy lensing scales of $\sim$1$''$ and extract random sightlines to train our BGNN. We then evaluate the model on test sets with varying degrees of overlap with the training distribution. For each test set of 1,000 sightlines, the BGNN infers the individual $\kappa$ posteriors, which we combine in a hierarchical Bayesian model to yield constraints on the hyperparameters governing the population. For a test field well sampled by the training set, the BGNN recovers the population mean of $\kappa$ precisely and without bias, resulting in a contribution to the $H_0$ error budget well under 1\%. In the tails of the training set with sparse samples, the BGNN, which can ingest all available information about each sightline, extracts more $\kappa$ signal compared to a simplified version of the traditional method based on matching galaxy number counts, which is limited by sample variance. Our hierarchical inference pipeline using BGNNs promises to improve the $\kappa_{\rm ext}$ characterization for precision TDC. The implementation of our pipeline is available as a public Python package, Node to Joy.
Normalizing Flows for Hierarchical Bayesian Analysis: A Gravitational Wave Population Study
Nov 15, 2022We propose parameterizing the population distribution of the gravitational wave population modeling framework (Hierarchical Bayesian Analysis) with a normalizing flow. We first demonstrate the merit of this method on illustrative experiments and then analyze four parameters of the latest LIGO data release: primary mass, secondary mass, redshift, and effective spin. Our results show that despite the small and notoriously noisy dataset, the posterior predictive distributions (assuming a prior over the parameters of the flow) of the observed gravitational wave population recover structure that agrees with robust previous phenomenological modeling results while being less susceptible to biases introduced by less-flexible distribution models. Therefore, the method forms a promising flexible, reliable replacement for population inference distributions, even when data is highly noisy.
A Neural Network Subgrid Model of the Early Stages of Planet Formation
Nov 08, 2022



Planet formation is a multi-scale process in which the coagulation of $\mathrm{\mu m}$-sized dust grains in protoplanetary disks is strongly influenced by the hydrodynamic processes on scales of astronomical units ($\approx 1.5\times 10^8 \,\mathrm{km}$). Studies are therefore dependent on subgrid models to emulate the micro physics of dust coagulation on top of a large scale hydrodynamic simulation. Numerical simulations which include the relevant physical effects are complex and computationally expensive. Here, we present a fast and accurate learned effective model for dust coagulation, trained on data from high resolution numerical coagulation simulations. Our model captures details of the dust coagulation process that were so far not tractable with other dust coagulation prescriptions with similar computational efficiency.
$\texttt{Mangrove}$: Learning Galaxy Properties from Merger Trees
Oct 24, 2022Efficiently mapping baryonic properties onto dark matter is a major challenge in astrophysics. Although semi-analytic models (SAMs) and hydrodynamical simulations have made impressive advances in reproducing galaxy observables across cosmologically significant volumes, these methods still require significant computation times, representing a barrier to many applications. Graph Neural Networks (GNNs) have recently proven to be the natural choice for learning physical relations. Among the most inherently graph-like structures found in astrophysics are the dark matter merger trees that encode the evolution of dark matter halos. In this paper we introduce a new, graph-based emulator framework, $\texttt{Mangrove}$, and show that it emulates the galactic stellar mass, cold gas mass and metallicity, instantaneous and time-averaged star formation rate, and black hole mass -- as predicted by a SAM -- with root mean squared error up to two times lower than other methods across a $(75 Mpc/h)^3$ simulation box in 40 seconds, 4 orders of magnitude faster than the SAM. We show that $\texttt{Mangrove}$ allows for quantification of the dependence of galaxy properties on merger history. We compare our results to the current state of the art in the field and show significant improvements for all target properties. $\texttt{Mangrove}$ is publicly available.
The SZ flux-mass relation at low halo masses: improvements with symbolic regression and strong constraints on baryonic feedback
Sep 05, 2022
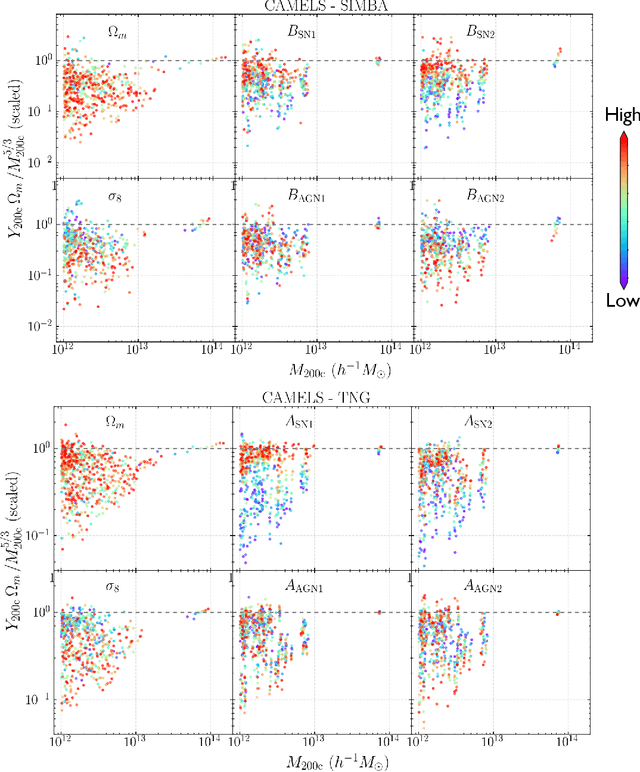
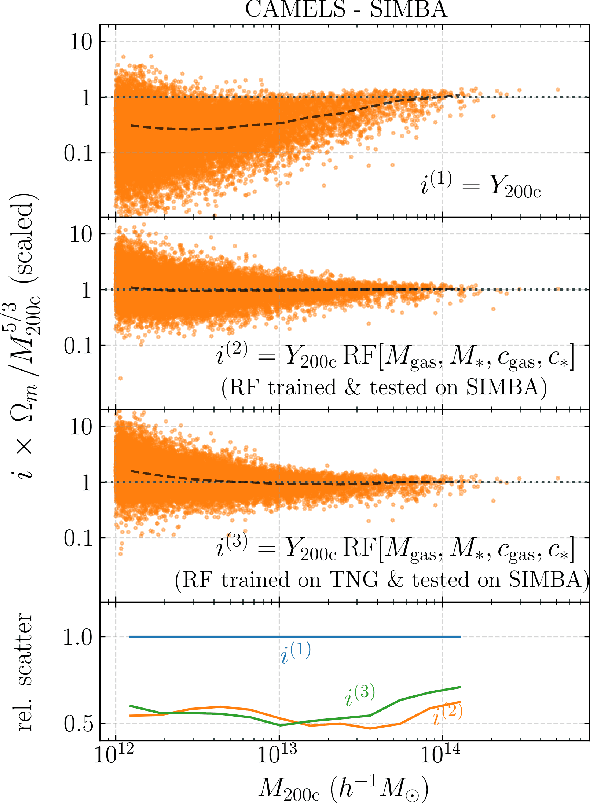

Ionized gas in the halo circumgalactic medium leaves an imprint on the cosmic microwave background via the thermal Sunyaev-Zeldovich (tSZ) effect. Feedback from active galactic nuclei (AGN) and supernovae can affect the measurements of the integrated tSZ flux of halos ($Y_\mathrm{SZ}$) and cause its relation with the halo mass ($Y_\mathrm{SZ}-M$) to deviate from the self-similar power-law prediction of the virial theorem. We perform a comprehensive study of such deviations using CAMELS, a suite of hydrodynamic simulations with extensive variations in feedback prescriptions. We use a combination of two machine learning tools (random forest and symbolic regression) to search for analogues of the $Y-M$ relation which are more robust to feedback processes for low masses ($M\lesssim 10^{14}\, h^{-1} \, M_\odot$); we find that simply replacing $Y\rightarrow Y(1+M_*/M_\mathrm{gas})$ in the relation makes it remarkably self-similar. This could serve as a robust multiwavelength mass proxy for low-mass clusters and galaxy groups. Our methodology can also be generally useful to improve the domain of validity of other astrophysical scaling relations. We also forecast that measurements of the $Y-M$ relation could provide percent-level constraints on certain combinations of feedback parameters and/or rule out a major part of the parameter space of supernova and AGN feedback models used in current state-of-the-art hydrodynamic simulations. Our results can be useful for using upcoming SZ surveys (e.g. SO, CMB-S4) and galaxy surveys (e.g. DESI and Rubin) to constrain the nature of baryonic feedback. Finally, we find that the an alternative relation, $Y-M_*$, provides complementary information on feedback than $Y-M$.
Automated discovery of interpretable gravitational-wave population models
Jul 25, 2022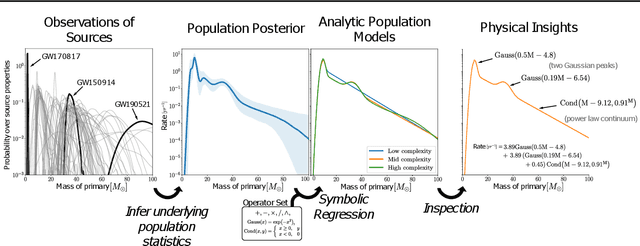

We present an automatic approach to discover analytic population models for gravitational-wave (GW) events from data. As more gravitational-wave (GW) events are detected, flexible models such as Gaussian Mixture Models have become more important in fitting the distribution of GW properties due to their expressivity. However, flexible models come with many parameters that lack physical motivation, making interpreting the implication of these models challenging. In this work, we demonstrate symbolic regression can complement flexible models by distilling the posterior predictive distribution of such flexible models into interpretable analytic expressions. We recover common GW population models such as a power-law-plus-Gaussian, and find a new empirical population model which combines accuracy and simplicity. This demonstrates a strategy to automatically discover interpretable population models in the ever-growing GW catalog, which can potentially be applied to other astrophysical phenomena.
Robust Simulation-Based Inference in Cosmology with Bayesian Neural Networks
Jul 20, 2022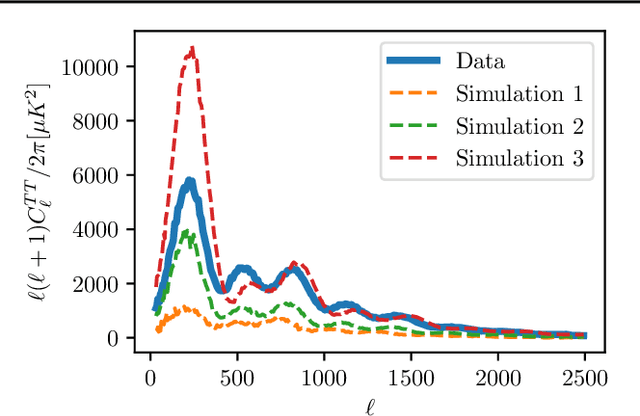
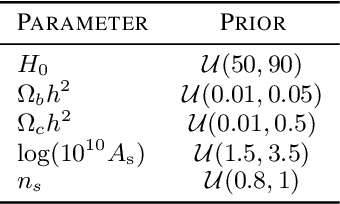
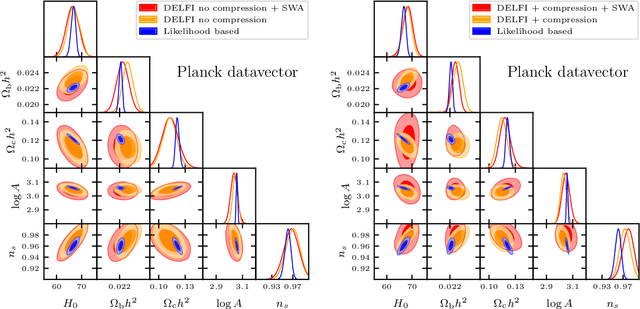
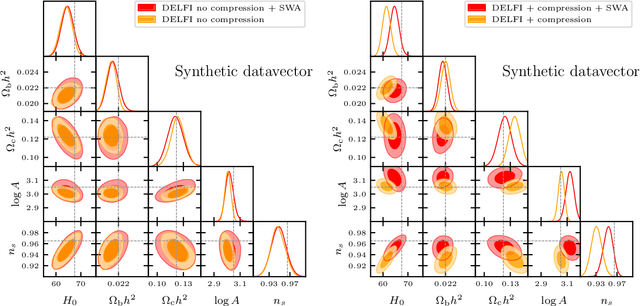
Simulation-based inference (SBI) is rapidly establishing itself as a standard machine learning technique for analyzing data in cosmological surveys. Despite continual improvements to the quality of density estimation by learned models, applications of such techniques to real data are entirely reliant on the generalization power of neural networks far outside the training distribution, which is mostly unconstrained. Due to the imperfections in scientist-created simulations, and the large computational expense of generating all possible parameter combinations, SBI methods in cosmology are vulnerable to such generalization issues. Here, we discuss the effects of both issues, and show how using a Bayesian neural network framework for training SBI can mitigate biases, and result in more reliable inference outside the training set. We introduce cosmoSWAG, the first application of Stochastic Weight Averaging to cosmology, and apply it to SBI trained for inference on the cosmic microwave background.
Predicting the Thermal Sunyaev-Zel'dovich Field using Modular and Equivariant Set-Based Neural Networks
Feb 28, 2022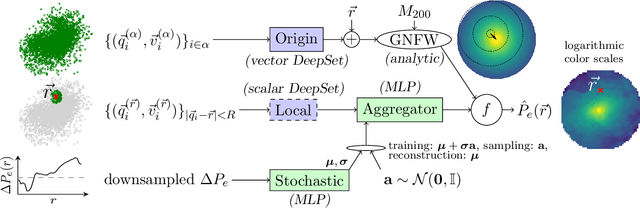
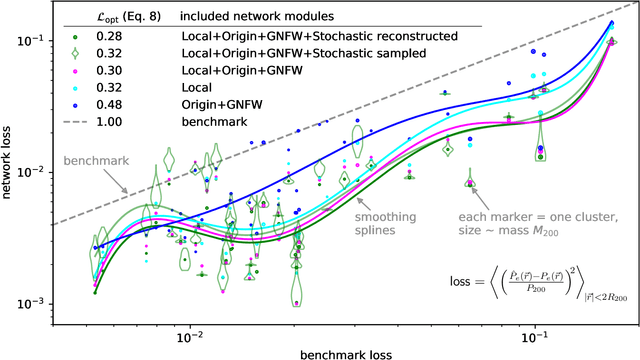
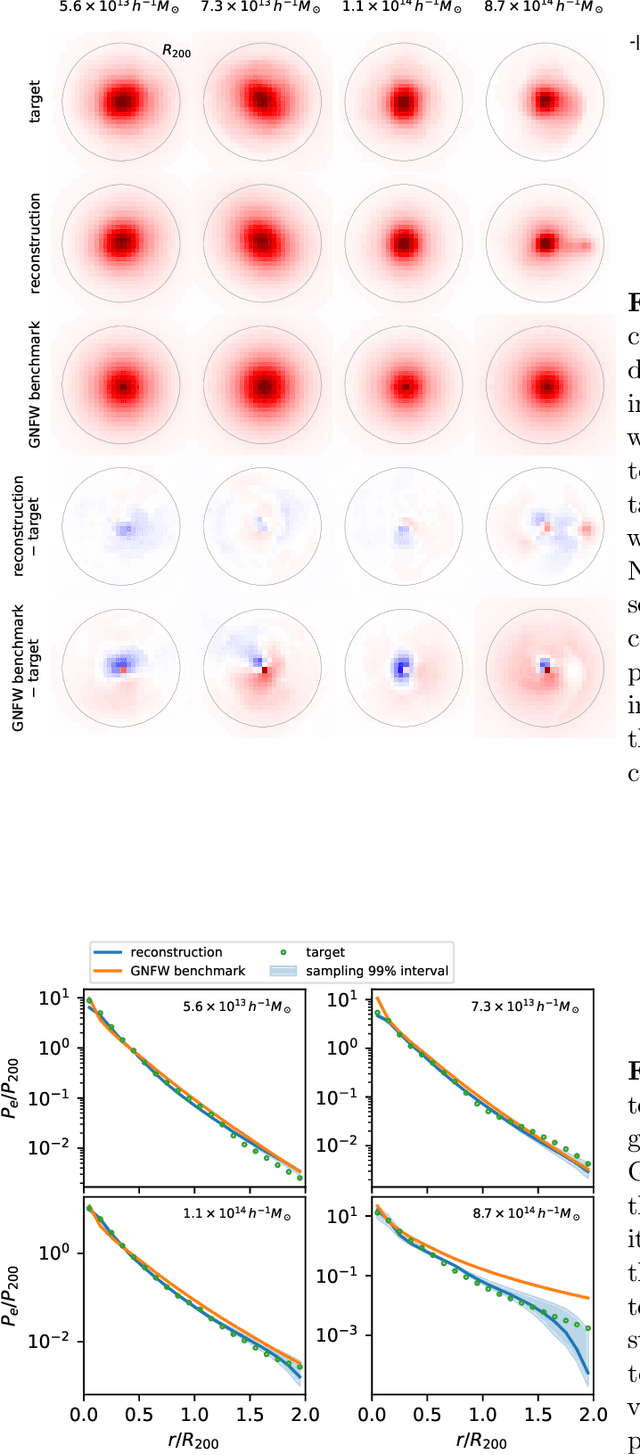
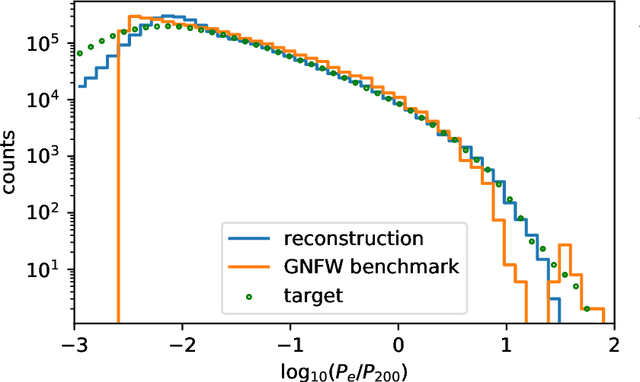
Theoretical uncertainty limits our ability to extract cosmological information from baryonic fields such as the thermal Sunyaev-Zel'dovich (tSZ) effect. Being sourced by the electron pressure field, the tSZ effect depends on baryonic physics that is usually modeled by expensive hydrodynamic simulations. We train neural networks on the IllustrisTNG-300 cosmological simulation to predict the continuous electron pressure field in galaxy clusters from gravity-only simulations. Modeling clusters is challenging for neural networks as most of the gas pressure is concentrated in a handful of voxels and even the largest hydrodynamical simulations contain only a few hundred clusters that can be used for training. Instead of conventional convolutional neural net (CNN) architectures, we choose to employ a rotationally equivariant DeepSets architecture to operate directly on the set of dark matter particles. We argue that set-based architectures provide distinct advantages over CNNs. For example, we can enforce exact rotational and permutation equivariance, incorporate existing knowledge on the tSZ field, and work with sparse fields as are standard in cosmology. We compose our architecture with separate, physically meaningful modules, making it amenable to interpretation. For example, we can separately study the influence of local and cluster-scale environment, determine that cluster triaxiality has negligible impact, and train a module that corrects for mis-centering. Our model improves by 70 % on analytic profiles fit to the same simulation data. We argue that the electron pressure field, viewed as a function of a gravity-only simulation, has inherent stochasticity, and model this property through a conditional-VAE extension to the network. This modification yields further improvement by 7 %, it is limited by our small training set however. (abridged)
Rediscovering orbital mechanics with machine learning
Feb 04, 2022
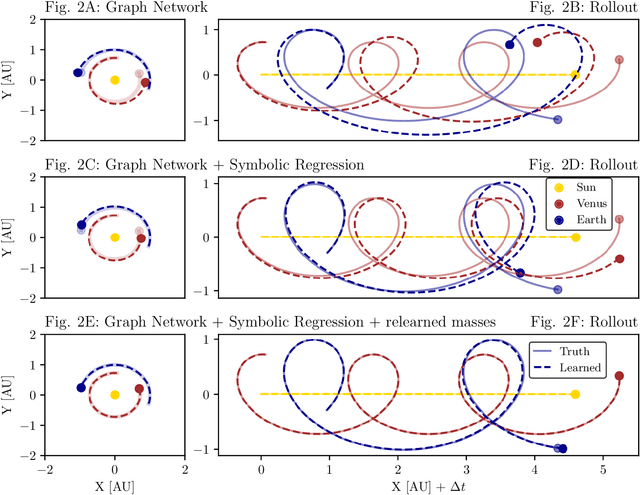
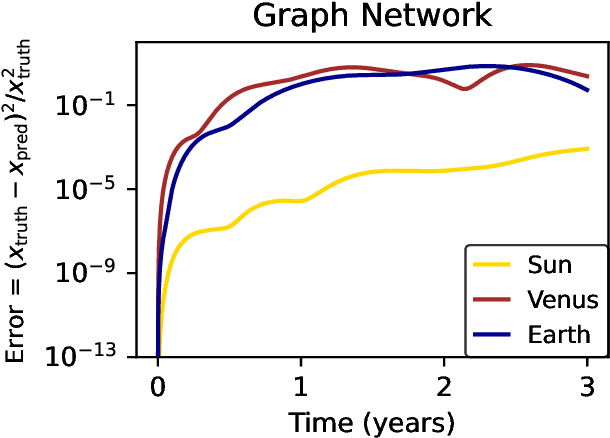
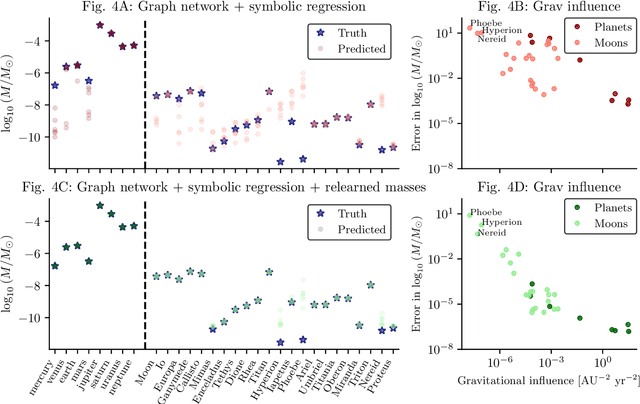
We present an approach for using machine learning to automatically discover the governing equations and hidden properties of real physical systems from observations. We train a "graph neural network" to simulate the dynamics of our solar system's Sun, planets, and large moons from 30 years of trajectory data. We then use symbolic regression to discover an analytical expression for the force law implicitly learned by the neural network, which our results showed is equivalent to Newton's law of gravitation. The key assumptions that were required were translational and rotational equivariance, and Newton's second and third laws of motion. Our approach correctly discovered the form of the symbolic force law. Furthermore, our approach did not require any assumptions about the masses of planets and moons or physical constants. They, too, were accurately inferred through our methods. Though, of course, the classical law of gravitation has been known since Isaac Newton, our result serves as a validation that our method can discover unknown laws and hidden properties from observed data. More broadly this work represents a key step toward realizing the potential of machine learning for accelerating scientific discovery.
Augmenting astrophysical scaling relations with machine learning : application to reducing the SZ flux-mass scatter
Jan 17, 2022
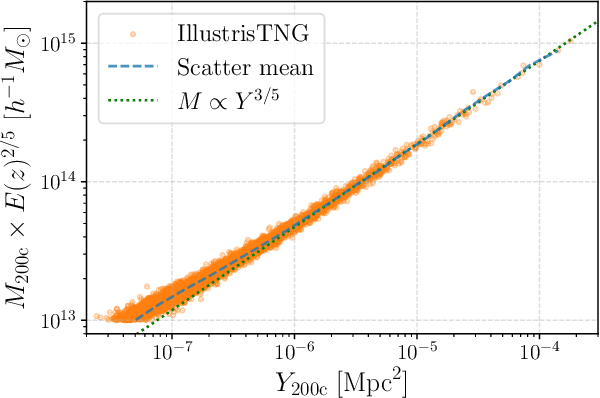
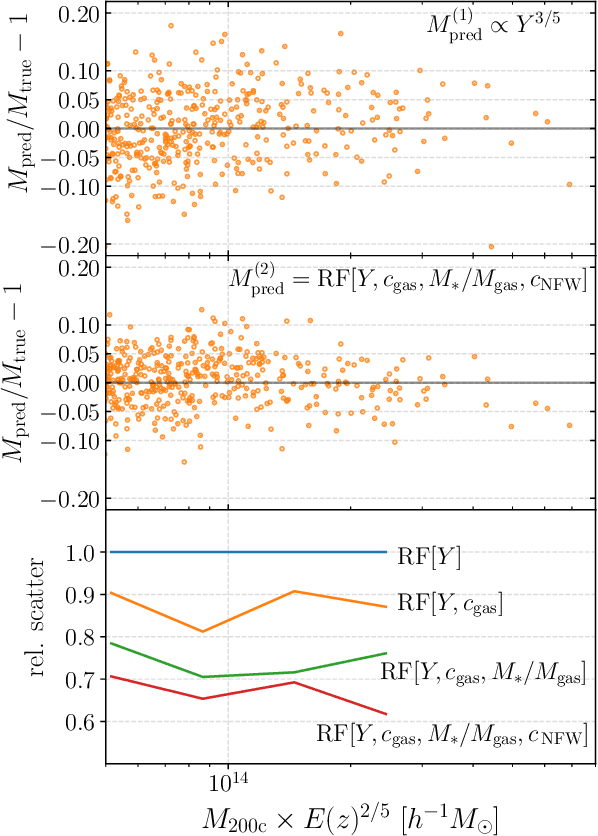
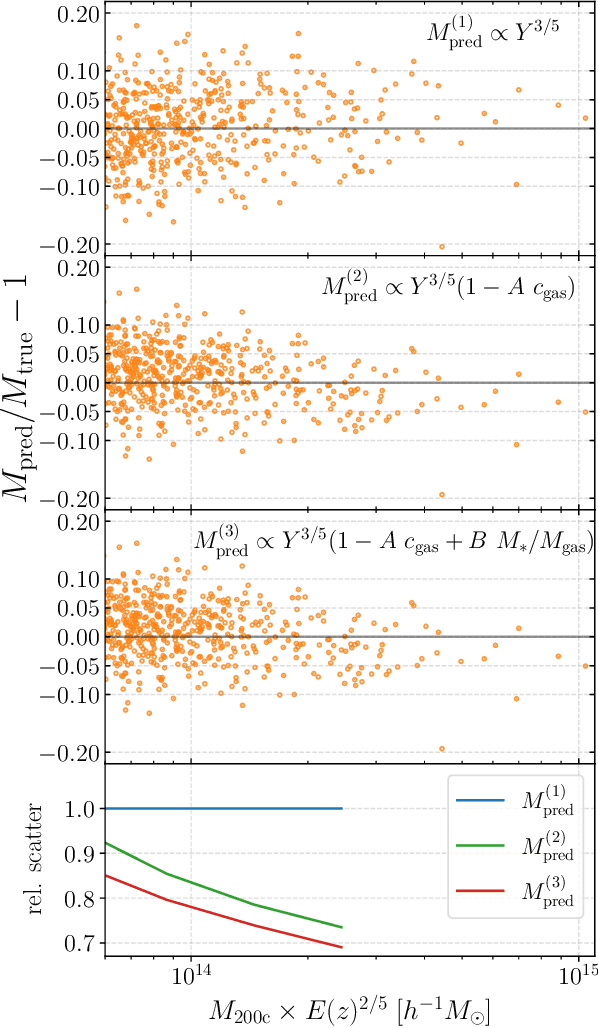
Complex systems (stars, supernovae, galaxies, and clusters) often exhibit low scatter relations between observable properties (e.g., luminosity, velocity dispersion, oscillation period, temperature). These scaling relations can illuminate the underlying physics and can provide observational tools for estimating masses and distances. Machine learning can provide a systematic way to search for new scaling relations (or for simple extensions to existing relations) in abstract high-dimensional parameter spaces. We use a machine learning tool called symbolic regression (SR), which models the patterns in a given dataset in the form of analytic equations. We focus on the Sunyaev-Zeldovich flux$-$cluster mass relation ($Y_\mathrm{SZ}-M$), the scatter in which affects inference of cosmological parameters from cluster abundance data. Using SR on the data from the IllustrisTNG hydrodynamical simulation, we find a new proxy for cluster mass which combines $Y_\mathrm{SZ}$ and concentration of ionized gas ($c_\mathrm{gas}$): $M \propto Y_\mathrm{conc}^{3/5} \equiv Y_\mathrm{SZ}^{3/5} (1-A\, c_\mathrm{gas})$. $Y_\mathrm{conc}$ reduces the scatter in the predicted $M$ by $\sim 20-30$% for large clusters ($M\gtrsim 10^{14}\, h^{-1} \, M_\odot$) at both high and low redshifts, as compared to using just $Y_\mathrm{SZ}$. We show that the dependence on $c_\mathrm{gas}$ is linked to cores of clusters exhibiting larger scatter than their outskirts. Finally, we test $Y_\mathrm{conc}$ on clusters from simulations of the CAMELS project and show that $Y_\mathrm{conc}$ is robust against variations in cosmology, astrophysics, subgrid physics, and cosmic variance. Our results and methodology can be useful for accurate multiwavelength cluster mass estimation from current and upcoming CMB and X-ray surveys like ACT, SO, SPT, eROSITA and CMB-S4.