 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptMark: Robust Multi-bit Diffusion Watermarking via Inference Time Optimization
Aug 29, 2025



Watermarking diffusion-generated images is crucial for copyright protection and user tracking. However, current diffusion watermarking methods face significant limitations: zero-bit watermarking systems lack the capacity for large-scale user tracking, while multi-bit methods are highly sensitive to certain image transformations or generative attacks, resulting in a lack of comprehensive robustness. In this paper, we propose OptMark, an optimization-based approach that embeds a robust multi-bit watermark into the intermediate latents of the diffusion denoising process. OptMark strategically inserts a structural watermark early to resist generative attacks and a detail watermark late to withstand image transformations, with tailored regularization terms to preserve image quality and ensure imperceptibility. To address the challenge of memory consumption growing linearly with the number of denoising steps during optimization, OptMark incorporates adjoint gradient methods, reducing memory usage from O(N) to O(1). Experimental results demonstrate that OptMark achieves invisible multi-bit watermarking while ensuring robust resilience against valuemetric transformations, geometric transformations, editing, and regeneration attacks.
Ego-centric Predictive Model Conditioned on Hand Trajectories
Aug 28, 2025In egocentric scenarios, anticipating both the next action and its visual outcome is essential for understanding human-object interactions and for enabling robotic planning. However, existing paradigms fall short of jointly modeling these aspects. Vision-Language-Action (VLA) models focus on action prediction but lack explicit modeling of how actions influence the visual scene, while video prediction models generate future frames without conditioning on specific actions, often resulting in implausible or contextually inconsistent outcomes. To bridge this gap, we propose a unified two-stage predictive framework that jointly models action and visual future in egocentric scenarios, conditioned on hand trajectories. In the first stage, we perform consecutive state modeling to process heterogeneous inputs (visual observations, language, and action history) and explicitly predict future hand trajectories. In the second stage, we introduce causal cross-attention to fuse multi-modal cues, leveraging inferred action signals to guide an image-based Latent Diffusion Model (LDM) for frame-by-frame future video generation. Our approach is the first unified model designed to handle both egocentric human activity understanding and robotic manipulation tasks, providing explicit predictions of both upcoming actions and their visual consequences. Extensive experiments on Ego4D, BridgeData, and RLBench demonstrate that our method outperforms state-of-the-art baselines in both action prediction and future video synthesis.
Reinforcement Learning in Vision: A Survey
Aug 11, 2025Recent advances at the intersection of reinforcement learning (RL) and visual intelligence have enabled agents that not only perceive complex visual scenes but also reason, generate, and act within them. This survey offers a critical and up-to-date synthesis of the field. We first formalize visual RL problems and trace the evolution of policy-optimization strategies from RLHF to verifiable reward paradigms, and from Proximal Policy Optimization to Group Relative Policy Optimization. We then organize more than 200 representative works into four thematic pillars: multi-modal large language models, visual generation, unified model frameworks, and vision-language-action models. For each pillar we examine algorithmic design, reward engineering, benchmark progress, and we distill trends such as curriculum-driven training, preference-aligned diffusion, and unified reward modeling. Finally, we review evaluation protocols spanning set-level fidelity, sample-level preference, and state-level stability, and we identify open challenges that include sample efficiency, generalization, and safe deployment. Our goal is to provide researchers and practitioners with a coherent map of the rapidly expanding landscape of visual RL and to highlight promising directions for future inquiry. Resources are available at: https://github.com/weijiawu/Awesome-Visual-Reinforcement-Learning.
VLA-Touch: Enhancing Vision-Language-Action Models with Dual-Level Tactile Feedback
Jul 23, 2025Tactile feedback is generally recognized to be crucial for effective interaction with the physical world. However, state-of-the-art Vision-Language-Action (VLA) models lack the ability to interpret and use tactile signals, limiting their effectiveness in contact-rich tasks. Incorporating tactile feedback into these systems is challenging due to the absence of large multi-modal datasets. We present VLA-Touch, an approach that enhances generalist robot policies with tactile sensing \emph{without fine-tuning} the base VLA. Our method introduces two key innovations: (1) a pipeline that leverages a pretrained tactile-language model that provides semantic tactile feedback for high-level task planning, and (2) a diffusion-based controller that refines VLA-generated actions with tactile signals for contact-rich manipulation. Through real-world experiments, we demonstrate that our dual-level integration of tactile feedback improves task planning efficiency while enhancing execution precision. Code is open-sourced at \href{https://github.com/jxbi1010/VLA-Touch}{this URL}.
Show-o2: Improved Native Unified Multimodal Models
Jun 18, 2025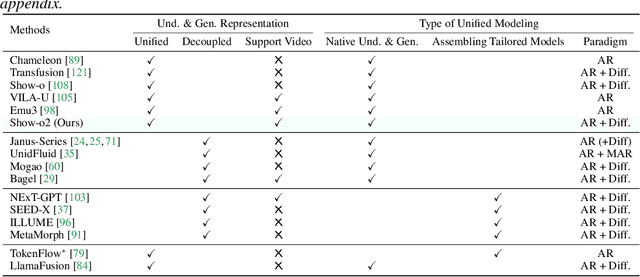
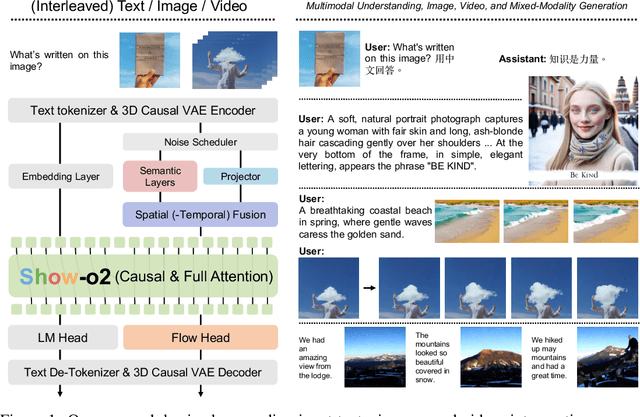

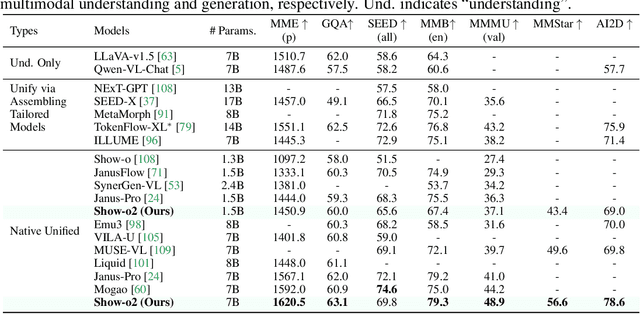
This paper presents improved native unified multimodal models, \emph{i.e.,} Show-o2, that leverage autoregressive modeling and flow matching. Built upon a 3D causal variational autoencoder space, unified visual representations are constructed through a dual-path of spatial (-temporal) fusion, enabling scalability across image and video modalities while ensuring effective multimodal understanding and generation. Based on a language model, autoregressive modeling and flow matching are natively applied to the language head and flow head, respectively, to facilitate text token prediction and image/video generation. A two-stage training recipe is designed to effectively learn and scale to larger models. The resulting Show-o2 models demonstrate versatility in handling a wide range of multimodal understanding and generation tasks across diverse modalities, including text, images, and videos. Code and models are released at https://github.com/showlab/Show-o.
macOSWorld: A Multilingual Interactive Benchmark for GUI Agents
Jun 05, 2025



Graphical User Interface (GUI) agents show promising capabilities for automating computer-use tasks and facilitating accessibility, but existing interactive benchmarks are mostly English-only, covering web-use or Windows, Linux, and Android environments, but not macOS. macOS is a major OS with distinctive GUI patterns and exclusive applications. To bridge the gaps, we present macOSWorld, the first comprehensive benchmark for evaluating GUI agents on macOS. macOSWorld features 202 multilingual interactive tasks across 30 applications (28 macOS-exclusive), with task instructions and OS interfaces offered in 5 languages (English, Chinese, Arabic, Japanese, and Russian). As GUI agents are shown to be vulnerable to deception attacks, macOSWorld also includes a dedicated safety benchmarking subset. Our evaluation on six GUI agents reveals a dramatic gap: proprietary computer-use agents lead at above 30% success rate, while open-source lightweight research models lag at below 2%, highlighting the need for macOS domain adaptation. Multilingual benchmarks also expose common weaknesses, especially in Arabic, with a 27.5% average degradation compared to English. Results from safety benchmarking also highlight that deception attacks are more general and demand immediate attention. macOSWorld is available at https://github.com/showlab/macosworld.
D-AR: Diffusion via Autoregressive Models
May 29, 2025This paper presents Diffusion via Autoregressive models (D-AR), a new paradigm recasting the image diffusion process as a vanilla autoregressive procedure in the standard next-token-prediction fashion. We start by designing the tokenizer that converts images into sequences of discrete tokens, where tokens in different positions can be decoded into different diffusion denoising steps in the pixel space. Thanks to the diffusion properties, these tokens naturally follow a coarse-to-fine order, which directly lends itself to autoregressive modeling. Therefore, we apply standard next-token prediction on these tokens, without modifying any underlying designs (either causal masks or training/inference strategies), and such sequential autoregressive token generation directly mirrors the diffusion procedure in image space. That is, once the autoregressive model generates an increment of tokens, we can directly decode these tokens into the corresponding diffusion denoising step in the streaming manner. Our pipeline naturally reveals several intriguing properties, for example, it supports consistent previews when generating only a subset of tokens and enables zero-shot layout-controlled synthesis. On the standard ImageNet benchmark, our method achieves 2.09 FID using a 775M Llama backbone with 256 discrete tokens. We hope our work can inspire future research on unified autoregressive architectures of visual synthesis, especially with large language models. Code and models will be available at https://github.com/showlab/D-AR
UniRL: Self-Improving Unified Multimodal Models via Supervised and Reinforcement Learning
May 29, 2025Unified multimodal large language models such as Show-o and Janus have achieved strong performance across both generation and understanding tasks. However, these models typically rely on large-scale datasets and require substantial computation during the pretraining stage. In addition, several post-training methods have been proposed, but they often depend on external data or are limited to task-specific customization. In this work, we introduce UniRL, a self-improving post-training approach. Our approach enables the model to generate images from prompts and use them as training data in each iteration, without relying on any external image data. Moreover, it enables the two tasks to enhance each other: the generated images are used for understanding, and the understanding results are used to supervise generation. We explore supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO) to optimize the models. UniRL offers three key advantages: (1) it requires no external image data, as all training samples are generated by the model itself during training; (2) it not only improves individual task performance, but also reduces the imbalance between generation and understanding; and (3) it requires only several additional training steps during the post-training stage. We evaluate UniRL on top of Show-o and Janus, achieving a GenEval score of 0.77 for Show-o and 0.65 for Janus. Code and models will be released in https://github.com/showlab/UniRL.
OmniConsistency: Learning Style-Agnostic Consistency from Paired Stylization Data
May 24, 2025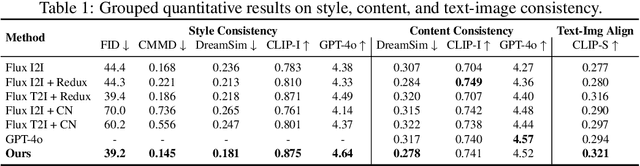
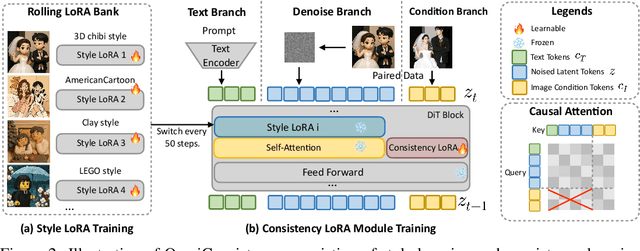


Diffusion models have advanced image stylization significantly, yet two core challenges persist: (1) maintaining consistent stylization in complex scenes, particularly identity, composition, and fine details, and (2) preventing style degradation in image-to-image pipelines with style LoRAs. GPT-4o's exceptional stylization consistency highlights the performance gap between open-source methods and proprietary models. To bridge this gap, we propose \textbf{OmniConsistency}, a universal consistency plugin leveraging large-scale Diffusion Transformers (DiTs). OmniConsistency contributes: (1) an in-context consistency learning framework trained on aligned image pairs for robust generalization; (2) a two-stage progressive learning strategy decoupling style learning from consistency preservation to mitigate style degradation; and (3) a fully plug-and-play design compatible with arbitrary style LoRAs under the Flux framework. Extensive experiments show that OmniConsistency significantly enhances visual coherence and aesthetic quality, achieving performance comparable to commercial state-of-the-art model GPT-4o.
Think or Not? Selective Reasoning via Reinforcement Learning for Vision-Language Models
May 22, 2025Reinforcement Learning (RL) has proven to be an effective post-training strategy for enhancing reasoning in vision-language models (VLMs). Group Relative Policy Optimization (GRPO) is a recent prominent method that encourages models to generate complete reasoning traces before answering, leading to increased token usage and computational cost. Inspired by the human-like thinking process-where people skip reasoning for easy questions but think carefully when needed-we explore how to enable VLMs to first decide when reasoning is necessary. To realize this, we propose TON, a two-stage training strategy: (i) a supervised fine-tuning (SFT) stage with a simple yet effective 'thought dropout' operation, where reasoning traces are randomly replaced with empty thoughts. This introduces a think-or-not format that serves as a cold start for selective reasoning; (ii) a GRPO stage that enables the model to freely explore when to think or not, while maximizing task-aware outcome rewards. Experimental results show that TON can reduce the completion length by up to 90% compared to vanilla GRPO, without sacrificing performance or even improving it. Further evaluations across diverse vision-language tasks-covering a range of reasoning difficulties under both 3B and 7B models-consistently reveal that the model progressively learns to bypass unnecessary reasoning steps as training advances. These findings shed light on the path toward human-like reasoning patterns in reinforcement learning approaches. Our code is available at https://github.com/kokolerk/TON.