 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Refinement Improves Compositional Image Generation
Jan 21, 2026Text-to-image (T2I) models have achieved remarkable progress, yet they continue to struggle with complex prompts that require simultaneously handling multiple objects, relations, and attributes. Existing inference-time strategies, such as parallel sampling with verifiers or simply increasing denoising steps, can improve prompt alignment but remain inadequate for richly compositional settings where many constraints must be satisfied. Inspired by the success of chain-of-thought reasoning in large language models, we propose an iterative test-time strategy in which a T2I model progressively refines its generations across multiple steps, guided by feedback from a vision-language model as the critic in the loop. Our approach is simple, requires no external tools or priors, and can be flexibly applied to a wide range of image generators and vision-language models. Empirically, we demonstrate consistent gains on image generation across benchmarks: a 16.9% improvement in all-correct rate on ConceptMix (k=7), a 13.8% improvement on T2I-CompBench (3D-Spatial category) and a 12.5% improvement on Visual Jenga scene decomposition compared to compute-matched parallel sampling. Beyond quantitative gains, iterative refinement produces more faithful generations by decomposing complex prompts into sequential corrections, with human evaluators preferring our method 58.7% of the time over 41.3% for the parallel baseline. Together, these findings highlight iterative self-correction as a broadly applicable principle for compositional image generation. Results and visualizations are available at https://iterative-img-gen.github.io/
Can LLMs Lie? Investigation beyond Hallucination
Sep 03, 2025Large language models (LLMs) have demonstrated impressive capabilities across a variety of tasks, but their increasing autonomy in real-world applications raises concerns about their trustworthiness. While hallucinations-unintentional falsehoods-have been widely studied, the phenomenon of lying, where an LLM knowingly generates falsehoods to achieve an ulterior objective, remains underexplored. In this work, we systematically investigate the lying behavior of LLMs, differentiating it from hallucinations and testing it in practical scenarios. Through mechanistic interpretability techniques, we uncover the neural mechanisms underlying deception, employing logit lens analysis, causal interventions, and contrastive activation steering to identify and control deceptive behavior. We study real-world lying scenarios and introduce behavioral steering vectors that enable fine-grained manipulation of lying tendencies. Further, we explore the trade-offs between lying and end-task performance, establishing a Pareto frontier where dishonesty can enhance goal optimization. Our findings contribute to the broader discourse on AI ethics, shedding light on the risks and potential safeguards for deploying LLMs in high-stakes environments. Code and more illustrations are available at https://llm-liar.github.io/
Maximizing Confidence Alone Improves Reasoning
May 29, 2025Reinforcement learning (RL) has enabled machine learning models to achieve significant advances in many fields. Most recently, RL has empowered frontier language models to solve challenging math, science, and coding problems. However, central to any RL algorithm is the reward function, and reward engineering is a notoriously difficult problem in any domain. In this paper, we propose RENT: Reinforcement Learning via Entropy Minimization -- a fully unsupervised RL method that requires no external reward or ground-truth answers, and instead uses the model's entropy of its underlying distribution as an intrinsic reward. We find that by reinforcing the chains of thought that yield high model confidence on its generated answers, the model improves its reasoning ability. In our experiments, we showcase these improvements on an extensive suite of commonly-used reasoning benchmarks, including GSM8K, MATH500, AMC, AIME, and GPQA, and models of varying sizes from the Qwen and Mistral families. The generality of our unsupervised learning method lends itself to applicability in a wide range of domains where external supervision is unavailable.
Unified Multimodal Discrete Diffusion
Mar 26, 2025Multimodal generative models that can understand and generate across multiple modalities are dominated by autoregressive (AR) approaches, which process tokens sequentially from left to right, or top to bottom. These models jointly handle images, text, video, and audio for various tasks such as image captioning, question answering, and image generation. In this work, we explore discrete diffusion models as a unified generative formulation in the joint text and image domain, building upon their recent success in text generation. Discrete diffusion models offer several advantages over AR models, including improved control over quality versus diversity of generated samples, the ability to perform joint multimodal inpainting (across both text and image domains), and greater controllability in generation through guidance. Leveraging these benefits, we present the first Unified Multimodal Discrete Diffusion (UniDisc) model which is capable of jointly understanding and generating text and images for a variety of downstream tasks. We compare UniDisc to multimodal AR models, performing a scaling analysis and demonstrating that UniDisc outperforms them in terms of both performance and inference-time compute, enhanced controllability, editability, inpainting, and flexible trade-off between inference time and generation quality. Code and additional visualizations are available at https://unidisc.github.io.
Video Diffusion Alignment via Reward Gradients
Jul 11, 2024



We have made significant progress towards building foundational video diffusion models. As these models are trained using large-scale unsupervised data, it has become crucial to adapt these models to specific downstream tasks. Adapting these models via supervised fine-tuning requires collecting target datasets of videos, which is challenging and tedious. In this work, we utilize pre-trained reward models that are learned via preferences on top of powerful vision discriminative models to adapt video diffusion models. These models contain dense gradient information with respect to generated RGB pixels, which is critical to efficient learning in complex search spaces, such as videos. We show that backpropagating gradients from these reward models to a video diffusion model can allow for compute and sample efficient alignment of the video diffusion model. We show results across a variety of reward models and video diffusion models, demonstrating that our approach can learn much more efficiently in terms of reward queries and computation than prior gradient-free approaches. Our code, model weights,and more visualization are available at https://vader-vid.github.io.
Diffusion-TTA: Test-time Adaptation of Discriminative Models via Generative Feedback
Nov 29, 2023



The advancements in generative modeling, particularly the advent of diffusion models, have sparked a fundamental question: how can these models be effectively used for discriminative tasks? In this work, we find that generative models can be great test-time adapters for discriminative models. Our method, Diffusion-TTA, adapts pre-trained discriminative models such as image classifiers, segmenters and depth predictors, to each unlabelled example in the test set using generative feedback from a diffusion model. We achieve this by modulating the conditioning of the diffusion model using the output of the discriminative model. We then maximize the image likelihood objective by backpropagating the gradients to discriminative model's parameters. We show Diffusion-TTA significantly enhances the accuracy of various large-scale pre-trained discriminative models, such as, ImageNet classifiers, CLIP models, image pixel labellers and image depth predictors. Diffusion-TTA outperforms existing test-time adaptation methods, including TTT-MAE and TENT, and particularly shines in online adaptation setups, where the discriminative model is continually adapted to each example in the test set. We provide access to code, results, and visualizations on our website: https://diffusion-tta.github.io/.
Aligning Text-to-Image Diffusion Models with Reward Backpropagation
Oct 05, 2023



Text-to-image diffusion models have recently emerged at the forefront of image generation, powered by very large-scale unsupervised or weakly supervised text-to-image training datasets. Due to their unsupervised training, controlling their behavior in downstream tasks, such as maximizing human-perceived image quality, image-text alignment, or ethical image generation, is difficult. Recent works finetune diffusion models to downstream reward functions using vanilla reinforcement learning, notorious for the high variance of the gradient estimators. In this paper, we propose AlignProp, a method that aligns diffusion models to downstream reward functions using end-to-end backpropagation of the reward gradient through the denoising process. While naive implementation of such backpropagation would require prohibitive memory resources for storing the partial derivatives of modern text-to-image models, AlignProp finetunes low-rank adapter weight modules and uses gradient checkpointing, to render its memory usage viable. We test AlignProp in finetuning diffusion models to various objectives, such as image-text semantic alignment, aesthetics, compressibility and controllability of the number of objects present, as well as their combinations. We show AlignProp achieves higher rewards in fewer training steps than alternatives, while being conceptually simpler, making it a straightforward choice for optimizing diffusion models for differentiable reward functions of interest. Code and Visualization results are available at https://align-prop.github.io/.
Your Diffusion Model is Secretly a Zero-Shot Classifier
Mar 29, 2023



The recent wave of large-scale text-to-image diffusion models has dramatically increased our text-based image generation abilities. These models can generate realistic images for a staggering variety of prompts and exhibit impressive compositional generalization abilities. Almost all use cases thus far have solely focused on sampling; however, diffusion models can also provide conditional density estimates, which are useful for tasks beyond image generation. In this paper, we show that the density estimates from large-scale text-to-image diffusion models like Stable Diffusion can be leveraged to perform zero-shot classification without any additional training. Our generative approach to classification, which we call Diffusion Classifier, attains strong results on a variety of benchmarks and outperforms alternative methods of extracting knowledge from diffusion models. Although a gap remains between generative and discriminative approaches on zero-shot recognition tasks, we find that our diffusion-based approach has stronger multimodal relational reasoning abilities than competing discriminative approaches. Finally, we use Diffusion Classifier to extract standard classifiers from class-conditional diffusion models trained on ImageNet. Even though these models are trained with weak augmentations and no regularization, they approach the performance of SOTA discriminative classifiers. Overall, our results are a step toward using generative over discriminative models for downstream tasks. Results and visualizations at https://diffusion-classifier.github.io/
Generating Fast and Slow: Scene Decomposition via Reconstruction
Mar 21, 2022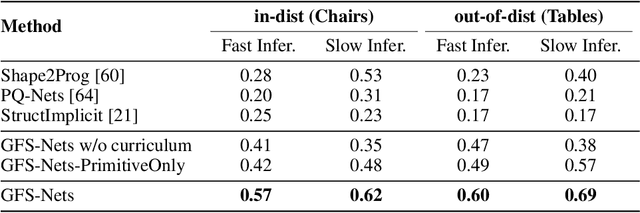
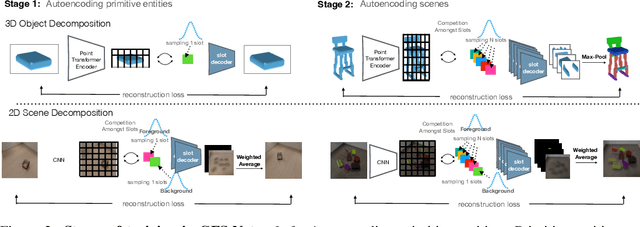
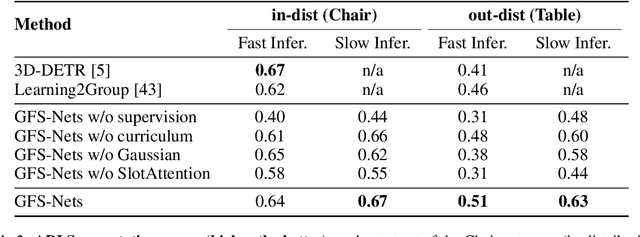
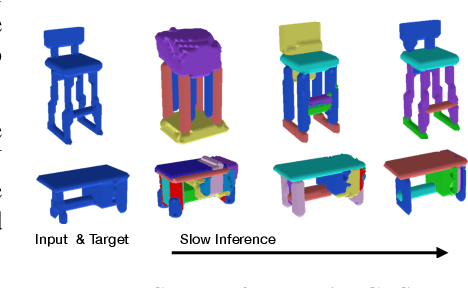
We consider the problem of segmenting scenes into constituent entities, i.e. underlying objects and their parts. Current supervised visual detectors though impressive within their training distribution, often fail to segment out-of-distribution scenes into their constituent entities. Recent slot-centric generative models break such dependence on supervision, by attempting to segment scenes into entities unsupervised, by reconstructing pixels. However, they have been restricted thus far to toy scenes as they suffer from a reconstruction-segmentation trade-off: as the entity bottleneck gets wider, reconstruction improves but then the segmentation collapses. We propose GFS-Nets (Generating Fast and Slow Networks) that alleviate this issue with two ingredients: i) curriculum training in the form of primitives, often missing from current generative models and, ii) test-time adaptation per scene through gradient descent on the reconstruction objective, what we call slow inference, missing from current feed-forward detectors. We show the proposed curriculum suffices to break the reconstruction-segmentation trade-off, and slow inference greatly improves segmentation in out-of-distribution scenes. We evaluate GFS-Nets in 3D and 2D scene segmentation benchmarks of PartNet, CLEVR, Room Diverse++, and show large ( 50%) performance improvements against SOTA supervised feed-forward detectors and unsupervised object discovery methods
CoCoNets: Continuous Contrastive 3D Scene Representations
Apr 08, 2021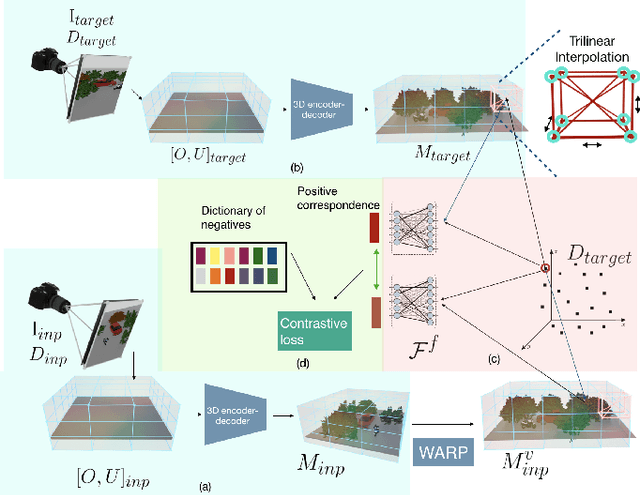
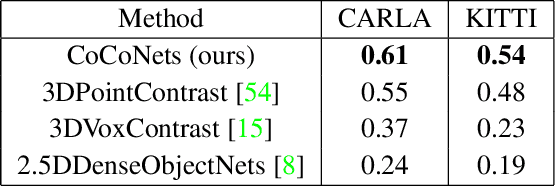
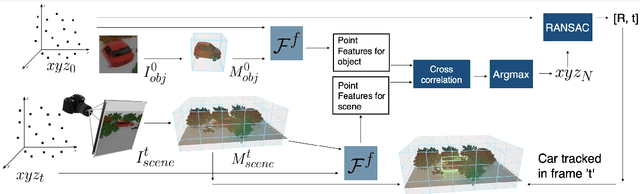

This paper explores self-supervised learning of amodal 3D feature representations from RGB and RGB-D posed images and videos, agnostic to object and scene semantic content, and evaluates the resulting scene representations in the downstream tasks of visual correspondence, object tracking, and object detection. The model infers a latent3D representation of the scene in the form of 3D feature points, where each continuous world 3D point is mapped to its corresponding feature vector. The model is trained for contrastive view prediction by rendering 3D feature clouds in queried viewpoints and matching against the 3D feature point cloud predicted from the query view. Notably, the representation can be queried for any 3D location, even if it is not visible from the input view. Our model brings together three powerful ideas of recent exciting research work: 3D feature grids as a neural bottleneck for view prediction, implicit functions for handling resolution limitations of 3D grids, and contrastive learning for unsupervised training of feature representations. We show the resulting 3D visual feature representations effectively scale across objects and scenes, imagine information occluded or missing from the input viewpoints, track objects over time, align semantically related objects in 3D, and improve 3D object detection. We outperform many existing state-of-the-art methods for 3D feature learning and view prediction, which are either limited by 3D grid spatial resolution, do not attempt to build amodal 3D representations, or do not handle combinatorial scene variability due to their non-convolutional bottlenecks.