 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp Deviations Bounds for Dirichlet Weighted Sums with Application to analysis of Bayesian algorithms
Apr 06, 2023In this work, we derive sharp non-asymptotic deviation bounds for weighted sums of Dirichlet random variables. These bounds are based on a novel integral representation of the density of a weighted Dirichlet sum. This representation allows us to obtain a Gaussian-like approximation for the sum distribution using geometry and complex analysis methods. Our results generalize similar bounds for the Beta distribution obtained in the seminal paper Alfers and Dinges [1984]. Additionally, our results can be considered a sharp non-asymptotic version of the inverse of Sanov's theorem studied by Ganesh and O'Connell [1999] in the Bayesian setting. Based on these results, we derive new deviation bounds for the Dirichlet process posterior means with application to Bayesian bootstrap. Finally, we apply our estimates to the analysis of the Multinomial Thompson Sampling (TS) algorithm in multi-armed bandits and significantly sharpen the existing regret bounds by making them independent of the size of the arms distribution support.
Fast Rates for Maximum Entropy Exploration
Mar 14, 2023



We consider the reinforcement learning (RL) setting, in which the agent has to act in unknown environment driven by a Markov Decision Process (MDP) with sparse or even reward free signals. In this situation, exploration becomes the main challenge. In this work, we study the maximum entropy exploration problem of two different types. The first type is visitation entropy maximization that was previously considered by Hazan et al. (2019) in the discounted setting. For this type of exploration, we propose an algorithm based on a game theoretic representation that has $\widetilde{\mathcal{O}}(H^3 S^2 A / \varepsilon^2)$ sample complexity thus improving the $\varepsilon$-dependence of Hazan et al. (2019), where $S$ is a number of states, $A$ is a number of actions, $H$ is an episode length, and $\varepsilon$ is a desired accuracy. The second type of entropy we study is the trajectory entropy. This objective function is closely related to the entropy-regularized MDPs, and we propose a simple modification of the UCBVI algorithm that has a sample complexity of order $\widetilde{\mathcal{O}}(1/\varepsilon)$ ignoring dependence in $S, A, H$. Interestingly enough, it is the first theoretical result in RL literature establishing that the exploration problem for the regularized MDPs can be statistically strictly easier (in terms of sample complexity) than for the ordinary MDPs.
Adapting to game trees in zero-sum imperfect information games
Dec 23, 2022Imperfect information games (IIG) are games in which each player only partially observes the current game state. We study how to learn $\epsilon$-optimal strategies in a zero-sum IIG through self-play with trajectory feedback. We give a problem-independent lower bound $\mathcal{O}(H(A_{\mathcal{X}}+B_{\mathcal{Y}})/\epsilon^2)$ on the required number of realizations to learn these strategies with high probability, where $H$ is the length of the game, $A_{\mathcal{X}}$ and $B_{\mathcal{Y}}$ are the total number of actions for the two players. We also propose two Follow the Regularize leader (FTRL) algorithms for this setting: Balanced-FTRL which matches this lower bound, but requires the knowledge of the information set structure beforehand to define the regularization; and Adaptive-FTRL which needs $\mathcal{O}(H^2(A_{\mathcal{X}}+B_{\mathcal{Y}})/\epsilon^2)$ plays without this requirement by progressively adapting the regularization to the observations.
Understanding Self-Predictive Learning for Reinforcement Learning
Dec 06, 2022



We study the learning dynamics of self-predictive learning for reinforcement learning, a family of algorithms that learn representations by minimizing the prediction error of their own future latent representations. Despite its recent empirical success, such algorithms have an apparent defect: trivial representations (such as constants) minimize the prediction error, yet it is obviously undesirable to converge to such solutions. Our central insight is that careful designs of the optimization dynamics are critical to learning meaningful representations. We identify that a faster paced optimization of the predictor and semi-gradient updates on the representation, are crucial to preventing the representation collapse. Then in an idealized setup, we show self-predictive learning dynamics carries out spectral decomposition on the state transition matrix, effectively capturing information of the transition dynamics. Building on the theoretical insights, we propose bidirectional self-predictive learning, a novel self-predictive algorithm that learns two representations simultaneously. We examine the robustness of our theoretical insights with a number of small-scale experiments and showcase the promise of the novel representation learning algorithm with large-scale experiments.
Curiosity in hindsight
Nov 18, 2022



Consider the exploration in sparse-reward or reward-free environments, such as Montezuma's Revenge. The curiosity-driven paradigm dictates an intuitive technique: At each step, the agent is rewarded for how much the realized outcome differs from their predicted outcome. However, using predictive error as intrinsic motivation is prone to fail in stochastic environments, as the agent may become hopelessly drawn to high-entropy areas of the state-action space, such as a noisy TV. Therefore it is important to distinguish between aspects of world dynamics that are inherently predictable and aspects that are inherently unpredictable: The former should constitute a source of intrinsic reward, whereas the latter should not. In this work, we study a natural solution derived from structural causal models of the world: Our key idea is to learn representations of the future that capture precisely the unpredictable aspects of each outcome -- not any more, not any less -- which we use as additional input for predictions, such that intrinsic rewards do vanish in the limit. First, we propose incorporating such hindsight representations into the agent's model to disentangle "noise" from "novelty", yielding Curiosity in Hindsight: a simple and scalable generalization of curiosity that is robust to all types of stochasticity. Second, we implement this framework as a drop-in modification of any prediction-based exploration bonus, and instantiate it for the recently introduced BYOL-Explore algorithm as a prime example, resulting in the noise-robust "BYOL-Hindsight". Third, we illustrate its behavior under various stochasticities in a grid world, and find improvements over BYOL-Explore in hard-exploration Atari games with sticky actions. Importantly, we show SOTA results in exploring Montezuma with sticky actions, while preserving performance in the non-sticky setting.
Optimistic Posterior Sampling for Reinforcement Learning with Few Samples and Tight Guarantees
Sep 28, 2022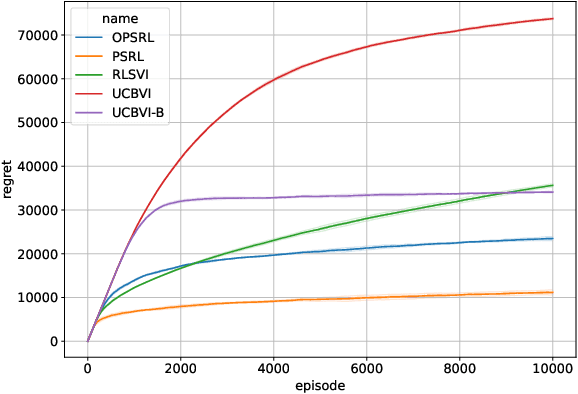
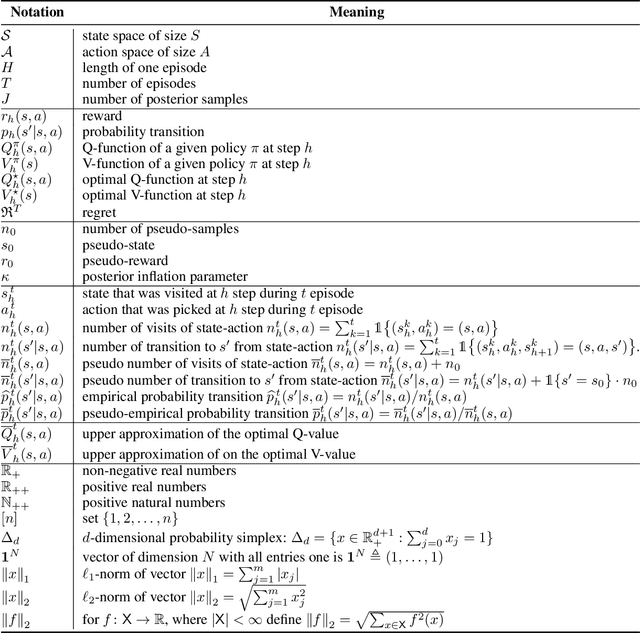
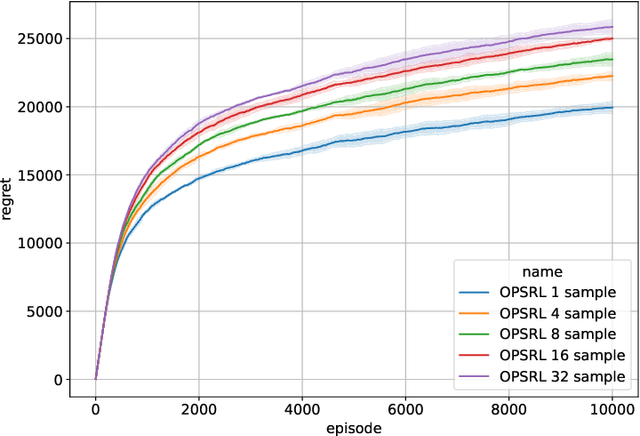
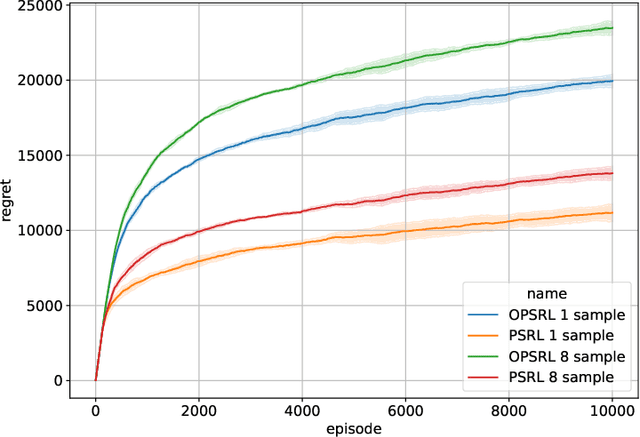
We consider reinforcement learning in an environment modeled by an episodic, finite, stage-dependent Markov decision process of horizon $H$ with $S$ states, and $A$ actions. The performance of an agent is measured by the regret after interacting with the environment for $T$ episodes. We propose an optimistic posterior sampling algorithm for reinforcement learning (OPSRL), a simple variant of posterior sampling that only needs a number of posterior samples logarithmic in $H$, $S$, $A$, and $T$ per state-action pair. For OPSRL we guarantee a high-probability regret bound of order at most $\widetilde{\mathcal{O}}(\sqrt{H^3SAT})$ ignoring $\text{poly}\log(HSAT)$ terms. The key novel technical ingredient is a new sharp anti-concentration inequality for linear forms which may be of independent interest. Specifically, we extend the normal approximation-based lower bound for Beta distributions by Alfers and Dinges [1984] to Dirichlet distributions. Our bound matches the lower bound of order $\Omega(\sqrt{H^3SAT})$, thereby answering the open problems raised by Agrawal and Jia [2017b] for the episodic setting.
BYOL-Explore: Exploration by Bootstrapped Prediction
Jun 16, 2022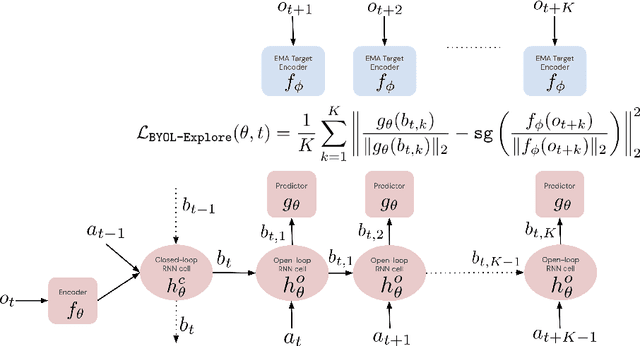
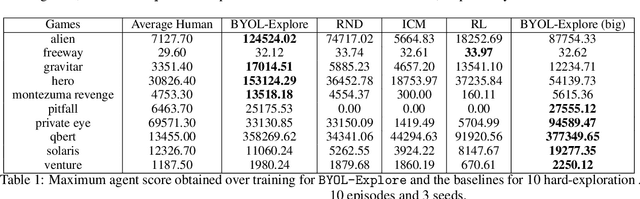

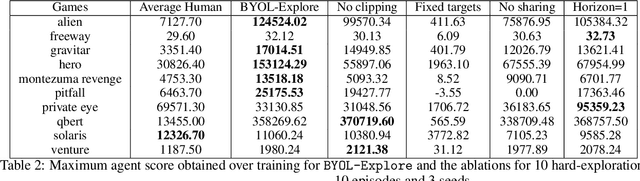
We present BYOL-Explore, a conceptually simple yet general approach for curiosity-driven exploration in visually-complex environments. BYOL-Explore learns a world representation, the world dynamics, and an exploration policy all-together by optimizing a single prediction loss in the latent space with no additional auxiliary objective. We show that BYOL-Explore is effective in DM-HARD-8, a challenging partially-observable continuous-action hard-exploration benchmark with visually-rich 3-D environments. On this benchmark, we solve the majority of the tasks purely through augmenting the extrinsic reward with BYOL-Explore s intrinsic reward, whereas prior work could only get off the ground with human demonstrations. As further evidence of the generality of BYOL-Explore, we show that it achieves superhuman performance on the ten hardest exploration games in Atari while having a much simpler design than other competitive agents.
KL-Entropy-Regularized RL with a Generative Model is Minimax Optimal
May 27, 2022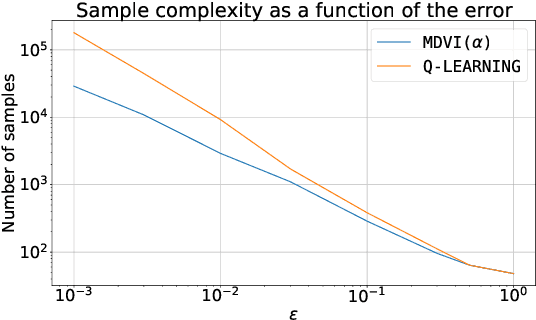

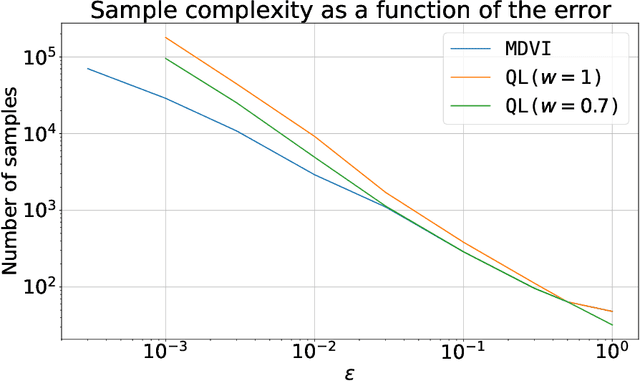
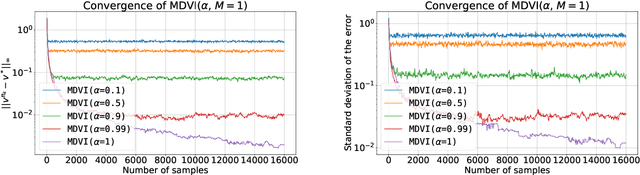
In this work, we consider and analyze the sample complexity of model-free reinforcement learning with a generative model. Particularly, we analyze mirror descent value iteration (MDVI) by Geist et al. (2019) and Vieillard et al. (2020a), which uses the Kullback-Leibler divergence and entropy regularization in its value and policy updates. Our analysis shows that it is nearly minimax-optimal for finding an $\varepsilon$-optimal policy when $\varepsilon$ is sufficiently small. This is the first theoretical result that demonstrates that a simple model-free algorithm without variance-reduction can be nearly minimax-optimal under the considered setting.
From Dirichlet to Rubin: Optimistic Exploration in RL without Bonuses
May 16, 2022
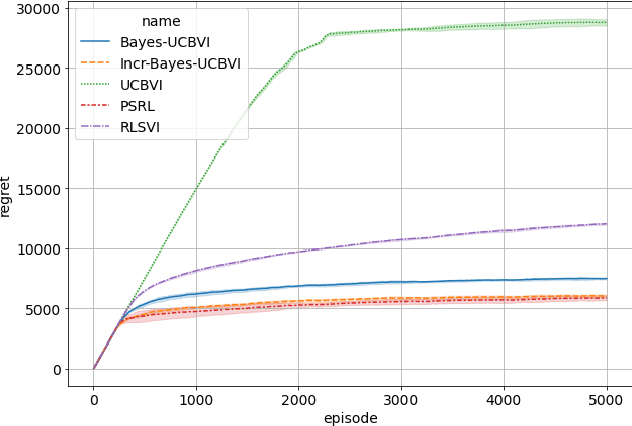
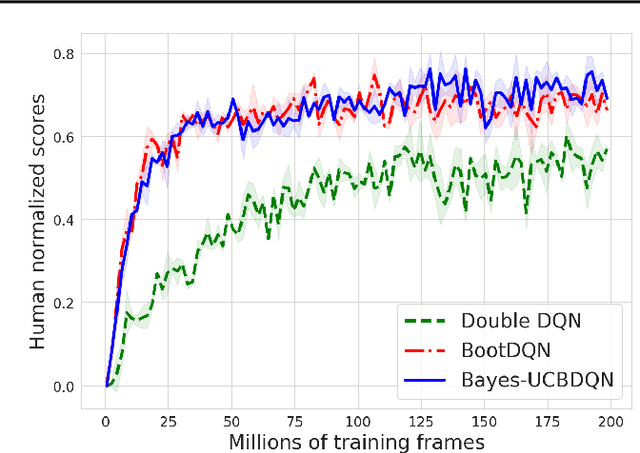
We propose the Bayes-UCBVI algorithm for reinforcement learning in tabular, stage-dependent, episodic Markov decision process: a natural extension of the Bayes-UCB algorithm by Kaufmann et al. (2012) for multi-armed bandits. Our method uses the quantile of a Q-value function posterior as upper confidence bound on the optimal Q-value function. For Bayes-UCBVI, we prove a regret bound of order $\widetilde{O}(\sqrt{H^3SAT})$ where $H$ is the length of one episode, $S$ is the number of states, $A$ the number of actions, $T$ the number of episodes, that matches the lower-bound of $\Omega(\sqrt{H^3SAT})$ up to poly-$\log$ terms in $H,S,A,T$ for a large enough $T$. To the best of our knowledge, this is the first algorithm that obtains an optimal dependence on the horizon $H$ (and $S$) without the need for an involved Bernstein-like bonus or noise. Crucial to our analysis is a new fine-grained anti-concentration bound for a weighted Dirichlet sum that can be of independent interest. We then explain how Bayes-UCBVI can be easily extended beyond the tabular setting, exhibiting a strong link between our algorithm and Bayesian bootstrap (Rubin, 1981).
Marginalized Operators for Off-policy Reinforcement Learning
Mar 30, 2022
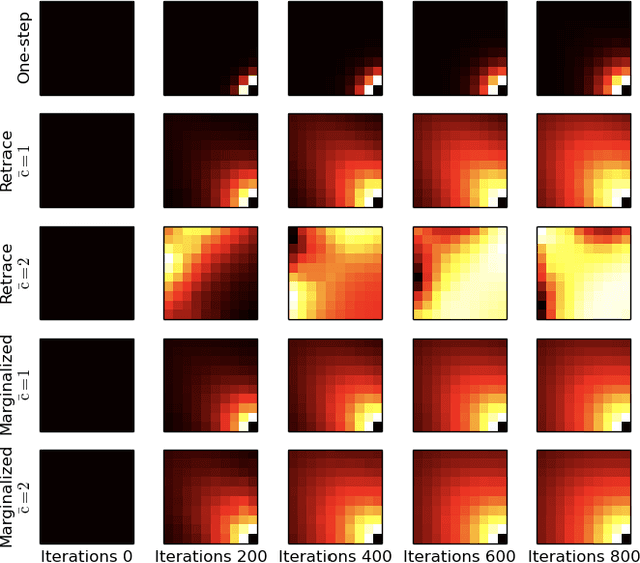
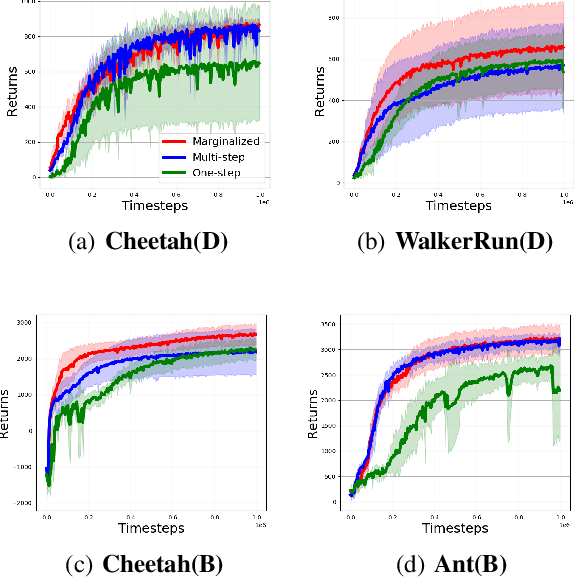
In this work, we propose marginalized operators, a new class of off-policy evaluation operators for reinforcement learning. Marginalized operators strictly generalize generic multi-step operators, such as Retrace, as special cases. Marginalized operators also suggest a form of sample-based estimates with potential variance reduction, compared to sample-based estimates of the original multi-step operators. We show that the estimates for marginalized operators can be computed in a scalable way, which also generalizes prior results on marginalized importance sampling as special cases. Finally, we empirically demonstrate that marginalized operators provide performance gains to off-policy evaluation and downstream policy optimization algorithms.