 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMichael W. Mahoney
Union of Intersections (UoI) for Interpretable Data Driven Discovery and Prediction
Nov 02, 2017
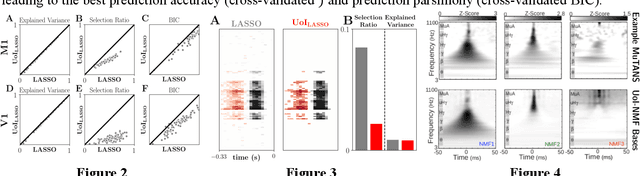
The increasing size and complexity of scientific data could dramatically enhance discovery and prediction for basic scientific applications. Realizing this potential, however, requires novel statistical analysis methods that are both interpretable and predictive. We introduce Union of Intersections (UoI), a flexible, modular, and scalable framework for enhanced model selection and estimation. Methods based on UoI perform model selection and model estimation through intersection and union operations, respectively. We show that UoI-based methods achieve low-variance and nearly unbiased estimation of a small number of interpretable features, while maintaining high-quality prediction accuracy. We perform extensive numerical investigation to evaluate a UoI algorithm ($UoI_{Lasso}$) on synthetic and real data. In doing so, we demonstrate the extraction of interpretable functional networks from human electrophysiology recordings as well as accurate prediction of phenotypes from genotype-phenotype data with reduced features. We also show (with the $UoI_{L1Logistic}$ and $UoI_{CUR}$ variants of the basic framework) improved prediction parsimony for classification and matrix factorization on several benchmark biomedical data sets. These results suggest that methods based on the UoI framework could improve interpretation and prediction in data-driven discovery across scientific fields.
Rethinking generalization requires revisiting old ideas: statistical mechanics approaches and complex learning behavior
Oct 26, 2017
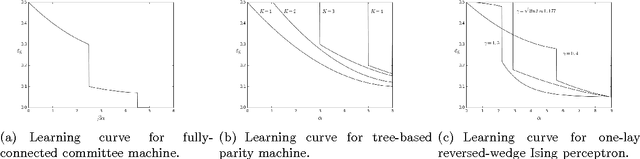

We describe an approach to understand the peculiar and counterintuitive generalization properties of deep neural networks. The approach involves going beyond worst-case theoretical capacity control frameworks that have been popular in machine learning in recent years to revisit old ideas in the statistical mechanics of neural networks. Within this approach, we present a prototypical Very Simple Deep Learning (VSDL) model, whose behavior is controlled by two control parameters, one describing an effective amount of data, or load, on the network (that decreases when noise is added to the input), and one with an effective temperature interpretation (that increases when algorithms are early stopped). Using this model, we describe how a very simple application of ideas from the statistical mechanics theory of generalization provides a strong qualitative description of recently-observed empirical results regarding the inability of deep neural networks not to overfit training data, discontinuous learning and sharp transitions in the generalization properties of learning algorithms, etc.
LASAGNE: Locality And Structure Aware Graph Node Embedding
Oct 17, 2017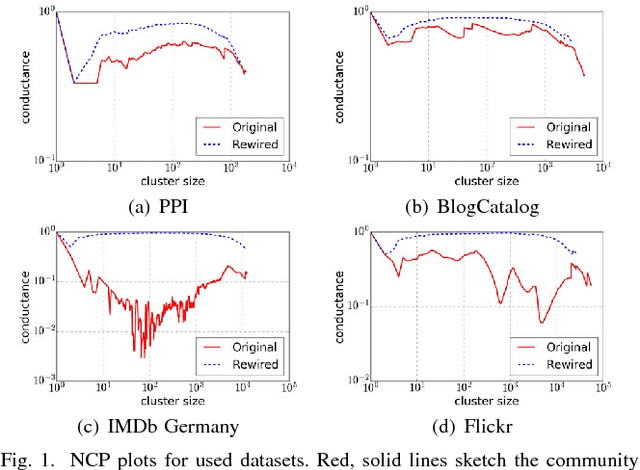
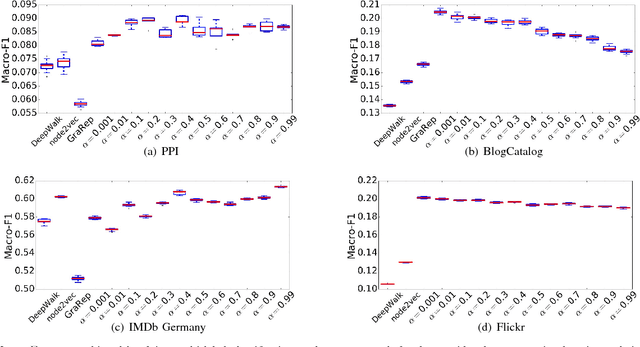
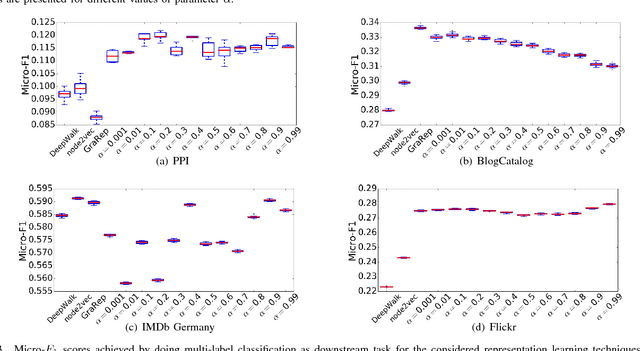
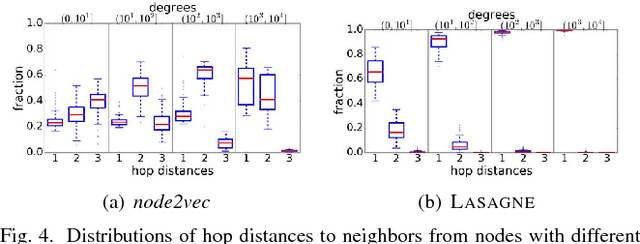
In this work we propose Lasagne, a methodology to learn locality and structure aware graph node embeddings in an unsupervised way. In particular, we show that the performance of existing random-walk based approaches depends strongly on the structural properties of the graph, e.g., the size of the graph, whether the graph has a flat or upward-sloping Network Community Profile (NCP), whether the graph is expander-like, whether the classes of interest are more k-core-like or more peripheral, etc. For larger graphs with flat NCPs that are strongly expander-like, existing methods lead to random walks that expand rapidly, touching many dissimilar nodes, thereby leading to lower-quality vector representations that are less useful for downstream tasks. Rather than relying on global random walks or neighbors within fixed hop distances, Lasagne exploits strongly local Approximate Personalized PageRank stationary distributions to more precisely engineer local information into node embeddings. This leads, in particular, to more meaningful and more useful vector representations of nodes in poorly-structured graphs. We show that Lasagne leads to significant improvement in downstream multi-label classification for larger graphs with flat NCPs, that it is comparable for smaller graphs with upward-sloping NCPs, and that is comparable to existing methods for link prediction tasks.
A Bootstrap Method for Error Estimation in Randomized Matrix Multiplication
Aug 06, 2017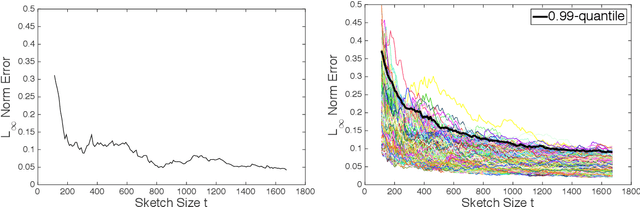

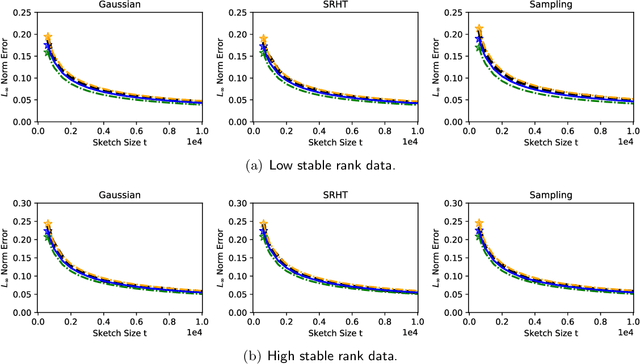
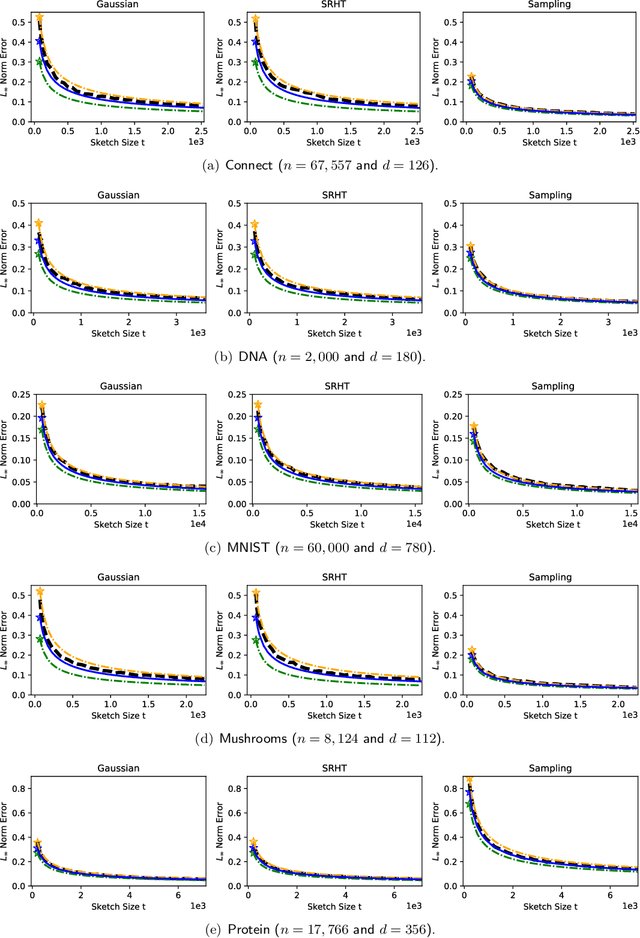
In recent years, randomized methods for numerical linear algebra have received growing interest as a general approach to large-scale problems. Typically, the essential ingredient of these methods is some form of randomized dimension reduction, which accelerates computations, but also creates random approximation error. In this way, the dimension reduction step encodes a tradeoff between cost and accuracy. However, the exact numerical relationship between cost and accuracy is typically unknown, and consequently, it may be difficult for the user to precisely know (1) how accurate a given solution is, or (2) how much computation is needed to achieve a given level of accuracy. In the current paper, we study randomized matrix multiplication (sketching) as a prototype setting for addressing these general problems. As a solution, we develop a bootstrap method for {directly estimating} the accuracy as a function of the reduced dimension (as opposed to deriving worst-case bounds on the accuracy in terms of the reduced dimension). From a computational standpoint, the proposed method does not substantially increase the cost of standard sketching methods, and this is made possible by an "extrapolation" technique. In addition, we provide both theoretical and empirical results to demonstrate the effectiveness of the proposed method.
Weighted SGD for $\ell_p$ Regression with Randomized Preconditioning
Jul 10, 2017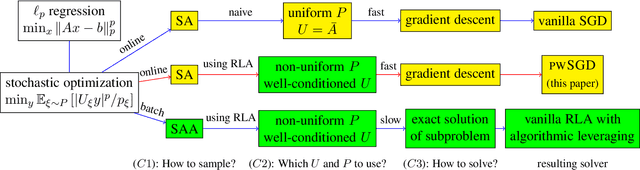

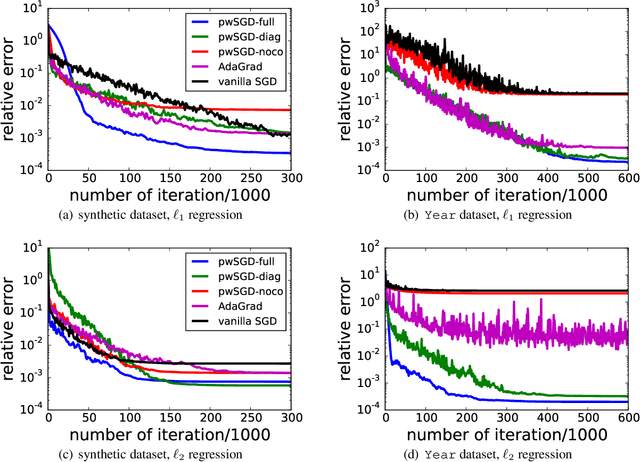
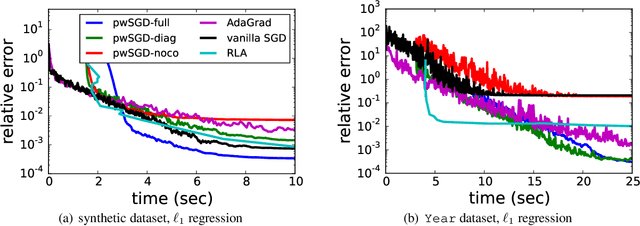
In recent years, stochastic gradient descent (SGD) methods and randomized linear algebra (RLA) algorithms have been applied to many large-scale problems in machine learning and data analysis. We aim to bridge the gap between these two methods in solving constrained overdetermined linear regression problems---e.g., $\ell_2$ and $\ell_1$ regression problems. We propose a hybrid algorithm named pwSGD that uses RLA techniques for preconditioning and constructing an importance sampling distribution, and then performs an SGD-like iterative process with weighted sampling on the preconditioned system. We prove that pwSGD inherits faster convergence rates that only depend on the lower dimension of the linear system, while maintaining low computation complexity. Particularly, when solving $\ell_1$ regression with size $n$ by $d$, pwSGD returns an approximate solution with $\epsilon$ relative error in the objective value in $\mathcal{O}(\log n \cdot \text{nnz}(A) + \text{poly}(d)/\epsilon^2)$ time. This complexity is uniformly better than that of RLA methods in terms of both $\epsilon$ and $d$ when the problem is unconstrained. For $\ell_2$ regression, pwSGD returns an approximate solution with $\epsilon$ relative error in the objective value and the solution vector measured in prediction norm in $\mathcal{O}(\log n \cdot \text{nnz}(A) + \text{poly}(d) \log(1/\epsilon) /\epsilon)$ time. We also provide lower bounds on the coreset complexity for more general regression problems, indicating that still new ideas will be needed to extend similar RLA preconditioning ideas to weighted SGD algorithms for more general regression problems. Finally, the effectiveness of such algorithms is illustrated numerically on both synthetic and real datasets.
Scalable Kernel K-Means Clustering with Nystrom Approximation: Relative-Error Bounds
Jun 24, 2017

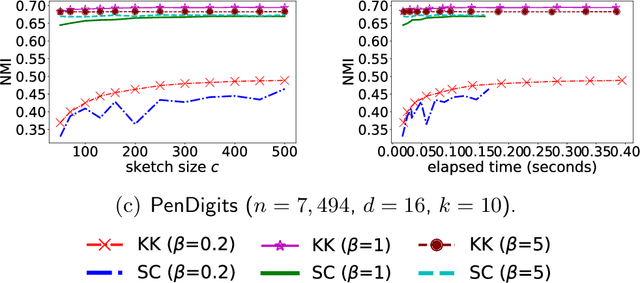
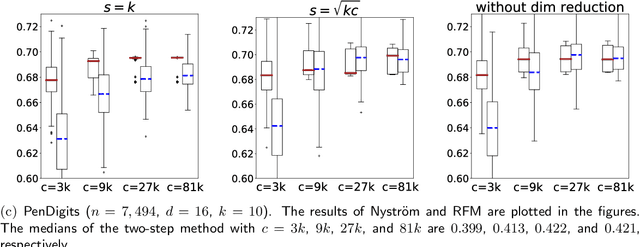
Kernel $k$-means clustering can correctly identify and extract a far more varied collection of cluster structures than the linear $k$-means clustering algorithm. However, kernel $k$-means clustering is computationally expensive when the non-linear feature map is high-dimensional and there are many input points. Kernel approximation, e.g., the Nystr\"om method, has been applied in previous works to approximately solve kernel learning problems when both of the above conditions are present. This work analyzes the application of this paradigm to kernel $k$-means clustering, and shows that applying the linear $k$-means clustering algorithm to $\frac{k}{\epsilon} (1 + o(1))$ features constructed using a so-called rank-restricted Nystr\"om approximation results in cluster assignments that satisfy a $1 + \epsilon$ approximation ratio in terms of the kernel $k$-means cost function, relative to the guarantee provided by the same algorithm without the use of the Nystr\"om method. As part of the analysis, this work establishes a novel $1 + \epsilon$ relative-error trace norm guarantee for low-rank approximation using the rank-restricted Nystr\"om approximation. Empirical evaluations on the $8.1$ million instance MNIST8M dataset demonstrate the scalability and usefulness of kernel $k$-means clustering with Nystr\"om approximation. This work argues that spectral clustering using Nystr\"om approximation---a popular and computationally efficient, but theoretically unsound approach to non-linear clustering---should be replaced with the efficient and theoretically sound combination of kernel $k$-means clustering with Nystr\"om approximation. The superior performance of the latter approach is empirically verified.
Mapping the Similarities of Spectra: Global and Locally-biased Approaches to SDSS Galaxy Data
Sep 13, 2016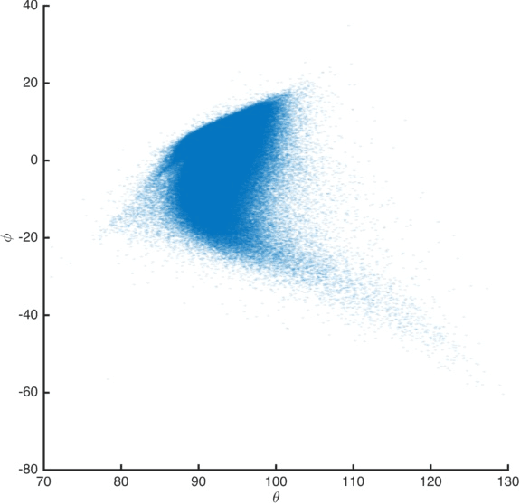
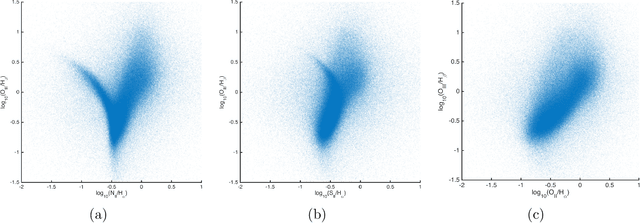
We apply a novel spectral graph technique, that of locally-biased semi-supervised eigenvectors, to study the diversity of galaxies. This technique permits us to characterize empirically the natural variations in observed spectra data, and we illustrate how this approach can be used in an exploratory manner to highlight both large-scale global as well as small-scale local structure in Sloan Digital Sky Survey (SDSS) data. We use this method in a way that simultaneously takes into account the measurements of spectral lines as well as the continuum shape. Unlike Principal Component Analysis, this method does not assume that the Euclidean distance between galaxy spectra is a good global measure of similarity between all spectra, but instead it only assumes that local difference information between similar spectra is reliable. Moreover, unlike other nonlinear dimensionality methods, this method can be used to characterize very finely both small-scale local as well as large-scale global properties of realistic noisy data. The power of the method is demonstrated on the SDSS Main Galaxy Sample by illustrating that the derived embeddings of spectra carry an unprecedented amount of information. By using a straightforward global or unsupervised variant, we observe that the main features correlate strongly with star formation rate and that they clearly separate active galactic nuclei. Computed parameters of the method can be used to describe line strengths and their interdependencies. By using a locally-biased or semi-supervised variant, we are able to focus on typical variations around specific objects of astronomical interest. We present several examples illustrating that this approach can enable new discoveries in the data as well as a detailed understanding of very fine local structure that would otherwise be overwhelmed by large-scale noise and global trends in the data.
Lecture Notes on Spectral Graph Methods
Aug 17, 2016These are lecture notes that are based on the lectures from a class I taught on the topic of Spectral Graph Methods at UC Berkeley during the Spring 2015 semester.
Lecture Notes on Randomized Linear Algebra
Aug 16, 2016These are lecture notes that are based on the lectures from a class I taught on the topic of Randomized Linear Algebra (RLA) at UC Berkeley during the Fall 2013 semester.
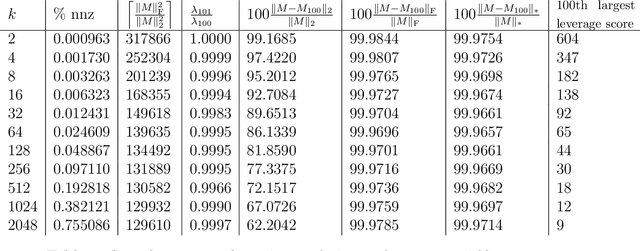
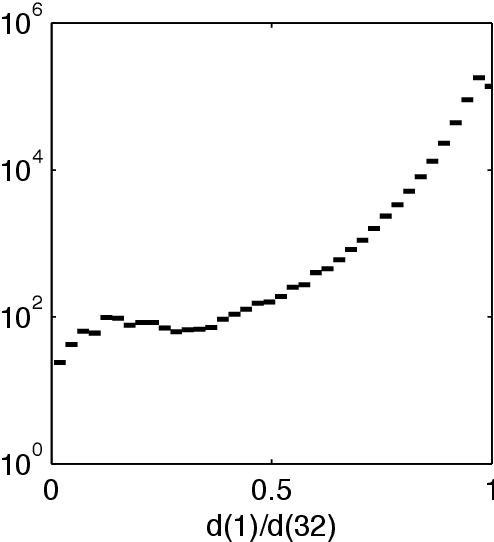
Sub-sampled Newton Methods with Non-uniform Sampling
Jul 05, 2016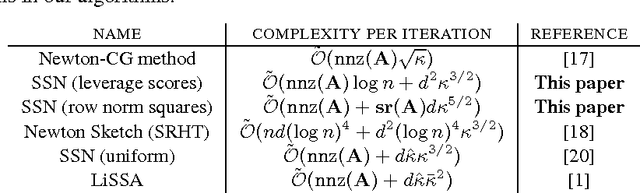
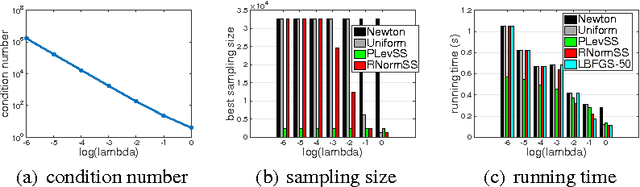
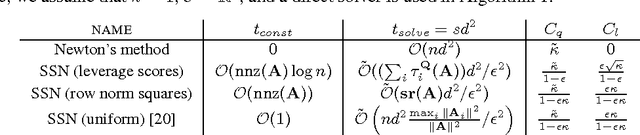
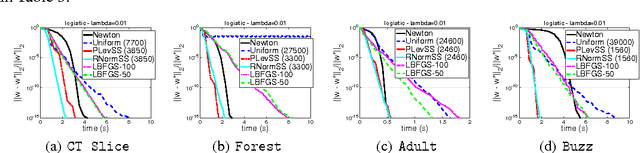
We consider the problem of finding the minimizer of a convex function $F: \mathbb R^d \rightarrow \mathbb R$ of the form $F(w) := \sum_{i=1}^n f_i(w) + R(w)$ where a low-rank factorization of $\nabla^2 f_i(w)$ is readily available. We consider the regime where $n \gg d$. As second-order methods prove to be effective in finding the minimizer to a high-precision, in this work, we propose randomized Newton-type algorithms that exploit \textit{non-uniform} sub-sampling of $\{\nabla^2 f_i(w)\}_{i=1}^{n}$, as well as inexact updates, as means to reduce the computational complexity. Two non-uniform sampling distributions based on {\it block norm squares} and {\it block partial leverage scores} are considered in order to capture important terms among $\{\nabla^2 f_i(w)\}_{i=1}^{n}$. We show that at each iteration non-uniformly sampling at most $\mathcal O(d \log d)$ terms from $\{\nabla^2 f_i(w)\}_{i=1}^{n}$ is sufficient to achieve a linear-quadratic convergence rate in $w$ when a suitable initial point is provided. In addition, we show that our algorithms achieve a lower computational complexity and exhibit more robustness and better dependence on problem specific quantities, such as the condition number, compared to similar existing methods, especially the ones based on uniform sampling. Finally, we empirically demonstrate that our methods are at least twice as fast as Newton's methods with ridge logistic regression on several real datasets.