 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Deep Learning Strategies For Automatic Speech Recognition
Apr 10, 2019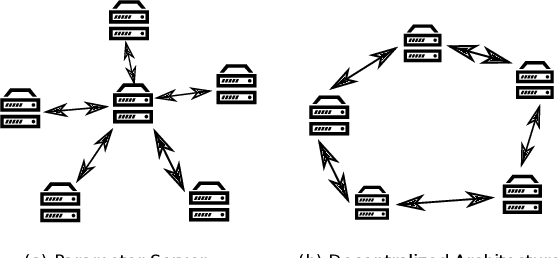
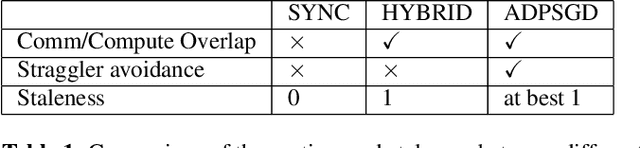
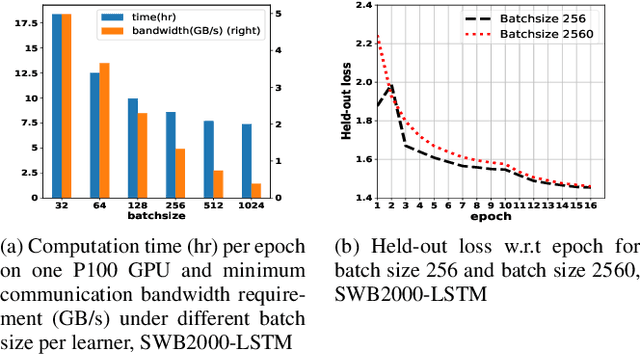
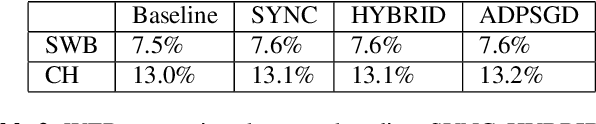
In this paper, we propose and investigate a variety of distributed deep learning strategies for automatic speech recognition (ASR) and evaluate them with a state-of-the-art Long short-term memory (LSTM) acoustic model on the 2000-hour Switchboard (SWB2000), which is one of the most widely used datasets for ASR performance benchmark. We first investigate what are the proper hyper-parameters (e.g., learning rate) to enable the training with sufficiently large batch size without impairing the model accuracy. We then implement various distributed strategies, including Synchronous (SYNC), Asynchronous Decentralized Parallel SGD (ADPSGD) and the hybrid of the two HYBRID, to study their runtime/accuracy trade-off. We show that we can train the LSTM model using ADPSGD in 14 hours with 16 NVIDIA P100 GPUs to reach a 7.6% WER on the Hub5- 2000 Switchboard (SWB) test set and a 13.1% WER on the CallHome (CH) test set. Furthermore, we can train the model using HYBRID in 11.5 hours with 32 NVIDIA V100 GPUs without loss in accuracy.
Acoustically Grounded Word Embeddings for Improved Acoustics-to-Word Speech Recognition
Mar 29, 2019



Direct acoustics-to-word (A2W) systems for end-to-end automatic speech recognition are simpler to train, and more efficient to decode with, than sub-word systems. However, A2W systems can have difficulties at training time when data is limited, and at decoding time when recognizing words outside the training vocabulary. To address these shortcomings, we investigate the use of recently proposed acoustic and acoustically grounded word embedding techniques in A2W systems. The idea is based on treating the final pre-softmax weight matrix of an AWE recognizer as a matrix of word embedding vectors, and using an externally trained set of word embeddings to improve the quality of this matrix. In particular we introduce two ideas: (1) Enforcing similarity at training time between the external embeddings and the recognizer weights, and (2) using the word embeddings at test time for predicting out-of-vocabulary words. Our word embedding model is acoustically grounded, that is it is learned jointly with acoustic embeddings so as to encode the words' acoustic-phonetic content; and it is parametric, so that it can embed any arbitrary (potentially out-of-vocabulary) sequence of characters. We find that both techniques improve the performance of an A2W recognizer on conversational telephone speech.
Evolutionary Stochastic Gradient Descent for Optimization of Deep Neural Networks
Oct 16, 2018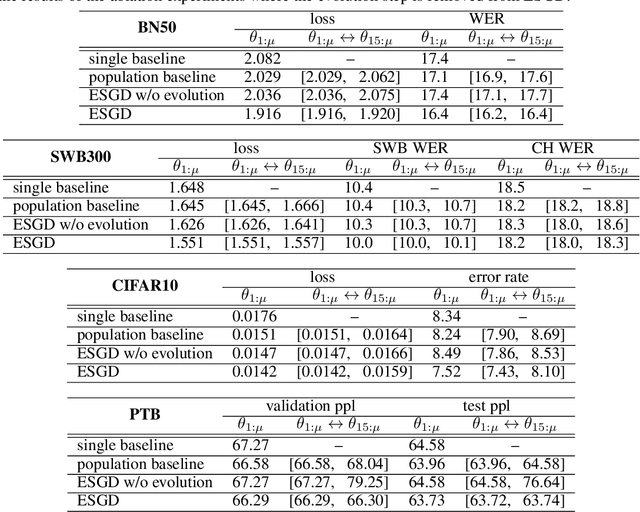
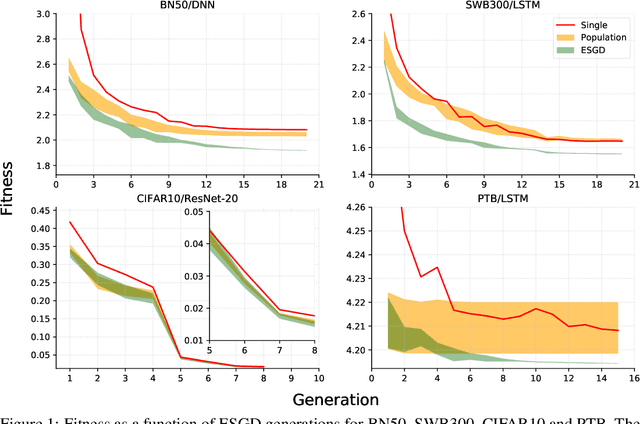
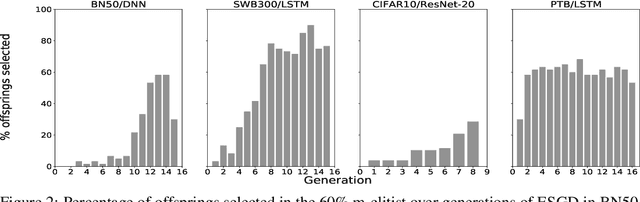
We propose a population-based Evolutionary Stochastic Gradient Descent (ESGD) framework for optimizing deep neural networks. ESGD combines SGD and gradient-free evolutionary algorithms as complementary algorithms in one framework in which the optimization alternates between the SGD step and evolution step to improve the average fitness of the population. With a back-off strategy in the SGD step and an elitist strategy in the evolution step, it guarantees that the best fitness in the population will never degrade. In addition, individuals in the population optimized with various SGD-based optimizers using distinct hyper-parameters in the SGD step are considered as competing species in a coevolution setting such that the complementarity of the optimizers is also taken into account. The effectiveness of ESGD is demonstrated across multiple applications including speech recognition, image recognition and language modeling, using networks with a variety of deep architectures.
Building competitive direct acoustics-to-word models for English conversational speech recognition
Dec 08, 2017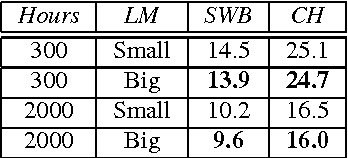
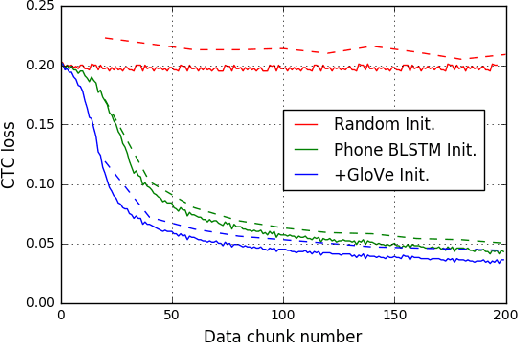
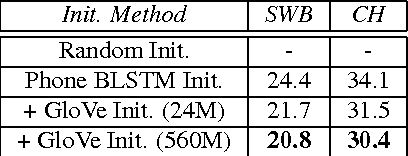
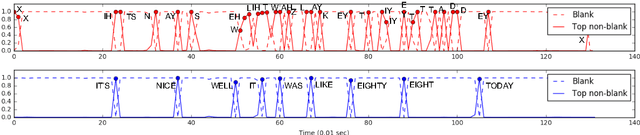
Direct acoustics-to-word (A2W) models in the end-to-end paradigm have received increasing attention compared to conventional sub-word based automatic speech recognition models using phones, characters, or context-dependent hidden Markov model states. This is because A2W models recognize words from speech without any decoder, pronunciation lexicon, or externally-trained language model, making training and decoding with such models simple. Prior work has shown that A2W models require orders of magnitude more training data in order to perform comparably to conventional models. Our work also showed this accuracy gap when using the English Switchboard-Fisher data set. This paper describes a recipe to train an A2W model that closes this gap and is at-par with state-of-the-art sub-word based models. We achieve a word error rate of 8.8%/13.9% on the Hub5-2000 Switchboard/CallHome test sets without any decoder or language model. We find that model initialization, training data order, and regularization have the most impact on the A2W model performance. Next, we present a joint word-character A2W model that learns to first spell the word and then recognize it. This model provides a rich output to the user instead of simple word hypotheses, making it especially useful in the case of words unseen or rarely-seen during training.
Direct Acoustics-to-Word Models for English Conversational Speech Recognition
Mar 22, 2017Recent work on end-to-end automatic speech recognition (ASR) has shown that the connectionist temporal classification (CTC) loss can be used to convert acoustics to phone or character sequences. Such systems are used with a dictionary and separately-trained Language Model (LM) to produce word sequences. However, they are not truly end-to-end in the sense of mapping acoustics directly to words without an intermediate phone representation. In this paper, we present the first results employing direct acoustics-to-word CTC models on two well-known public benchmark tasks: Switchboard and CallHome. These models do not require an LM or even a decoder at run-time and hence recognize speech with minimal complexity. However, due to the large number of word output units, CTC word models require orders of magnitude more data to train reliably compared to traditional systems. We present some techniques to mitigate this issue. Our CTC word model achieves a word error rate of 13.0%/18.8% on the Hub5-2000 Switchboard/CallHome test sets without any LM or decoder compared with 9.6%/16.0% for phone-based CTC with a 4-gram LM. We also present rescoring results on CTC word model lattices to quantify the performance benefits of a LM, and contrast the performance of word and phone CTC models.
English Conversational Telephone Speech Recognition by Humans and Machines
Mar 06, 2017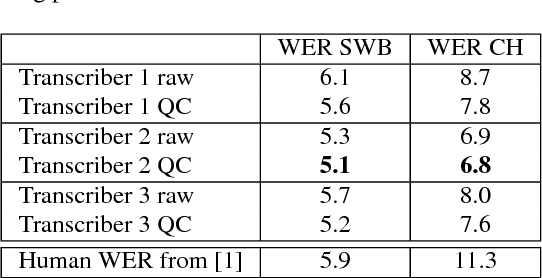
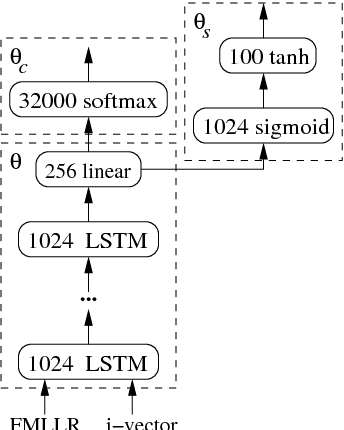
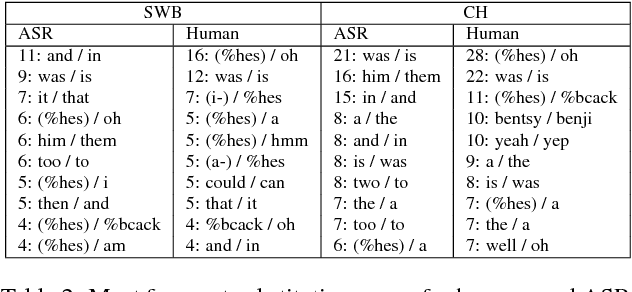
One of the most difficult speech recognition tasks is accurate recognition of human to human communication. Advances in deep learning over the last few years have produced major speech recognition improvements on the representative Switchboard conversational corpus. Word error rates that just a few years ago were 14% have dropped to 8.0%, then 6.6% and most recently 5.8%, and are now believed to be within striking range of human performance. This then raises two issues - what IS human performance, and how far down can we still drive speech recognition error rates? A recent paper by Microsoft suggests that we have already achieved human performance. In trying to verify this statement, we performed an independent set of human performance measurements on two conversational tasks and found that human performance may be considerably better than what was earlier reported, giving the community a significantly harder goal to achieve. We also report on our own efforts in this area, presenting a set of acoustic and language modeling techniques that lowered the word error rate of our own English conversational telephone LVCSR system to the level of 5.5%/10.3% on the Switchboard/CallHome subsets of the Hub5 2000 evaluation, which - at least at the writing of this paper - is a new performance milestone (albeit not at what we measure to be human performance!). On the acoustic side, we use a score fusion of three models: one LSTM with multiple feature inputs, a second LSTM trained with speaker-adversarial multi-task learning and a third residual net (ResNet) with 25 convolutional layers and time-dilated convolutions. On the language modeling side, we use word and character LSTMs and convolutional WaveNet-style language models.
Kernel Approximation Methods for Speech Recognition
Jan 13, 2017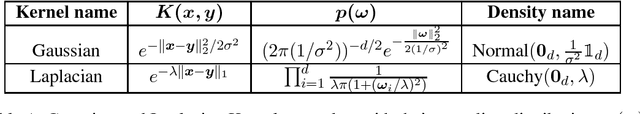
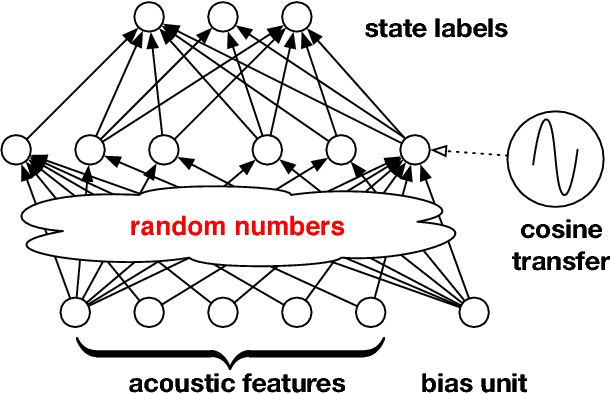
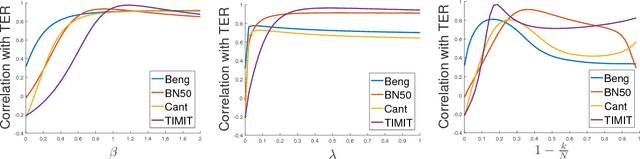

We study large-scale kernel methods for acoustic modeling in speech recognition and compare their performance to deep neural networks (DNNs). We perform experiments on four speech recognition datasets, including the TIMIT and Broadcast News benchmark tasks, and compare these two types of models on frame-level performance metrics (accuracy, cross-entropy), as well as on recognition metrics (word/character error rate). In order to scale kernel methods to these large datasets, we use the random Fourier feature method of Rahimi and Recht (2007). We propose two novel techniques for improving the performance of kernel acoustic models. First, in order to reduce the number of random features required by kernel models, we propose a simple but effective method for feature selection. The method is able to explore a large number of non-linear features while maintaining a compact model more efficiently than existing approaches. Second, we present a number of frame-level metrics which correlate very strongly with recognition performance when computed on the heldout set; we take advantage of these correlations by monitoring these metrics during training in order to decide when to stop learning. This technique can noticeably improve the recognition performance of both DNN and kernel models, while narrowing the gap between them. Additionally, we show that the linear bottleneck method of Sainath et al. (2013) improves the performance of our kernel models significantly, in addition to speeding up training and making the models more compact. Together, these three methods dramatically improve the performance of kernel acoustic models, making their performance comparable to DNNs on the tasks we explored.
Training variance and performance evaluation of neural networks in speech
Jun 14, 2016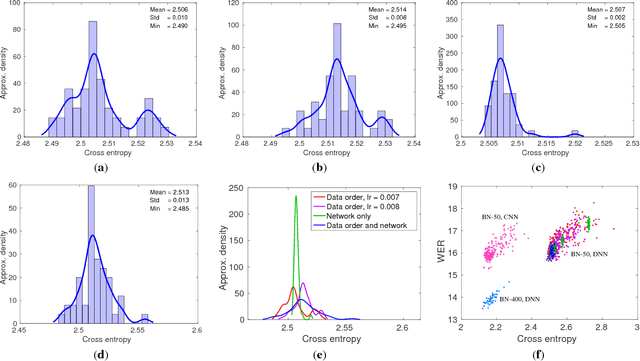
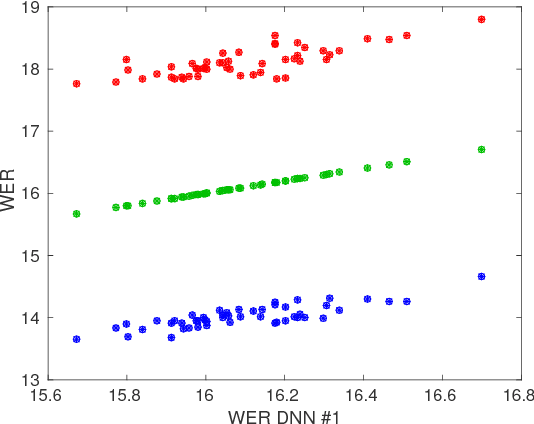
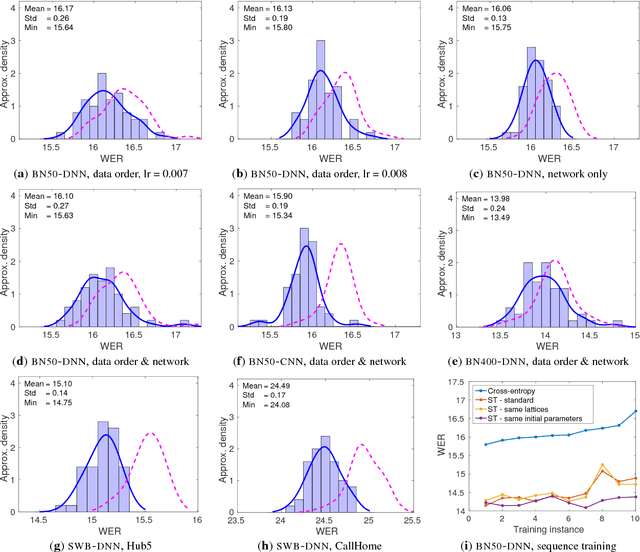
In this work we study variance in the results of neural network training on a wide variety of configurations in automatic speech recognition. Although this variance itself is well known, this is, to the best of our knowledge, the first paper that performs an extensive empirical study on its effects in speech recognition. We view training as sampling from a distribution and show that these distributions can have a substantial variance. These results show the urgent need to rethink the way in which results in the literature are reported and interpreted.
A Comparison between Deep Neural Nets and Kernel Acoustic Models for Speech Recognition
Mar 18, 2016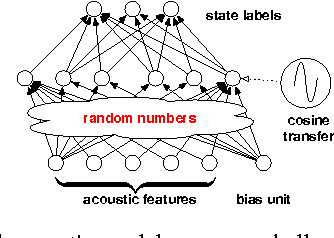


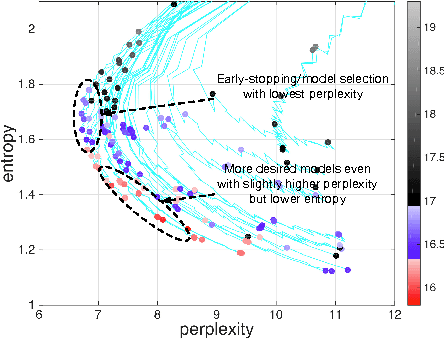
We study large-scale kernel methods for acoustic modeling and compare to DNNs on performance metrics related to both acoustic modeling and recognition. Measuring perplexity and frame-level classification accuracy, kernel-based acoustic models are as effective as their DNN counterparts. However, on token-error-rates DNN models can be significantly better. We have discovered that this might be attributed to DNN's unique strength in reducing both the perplexity and the entropy of the predicted posterior probabilities. Motivated by our findings, we propose a new technique, entropy regularized perplexity, for model selection. This technique can noticeably improve the recognition performance of both types of models, and reduces the gap between them. While effective on Broadcast News, this technique could be also applicable to other tasks.
How to Scale Up Kernel Methods to Be As Good As Deep Neural Nets
Jun 17, 2015
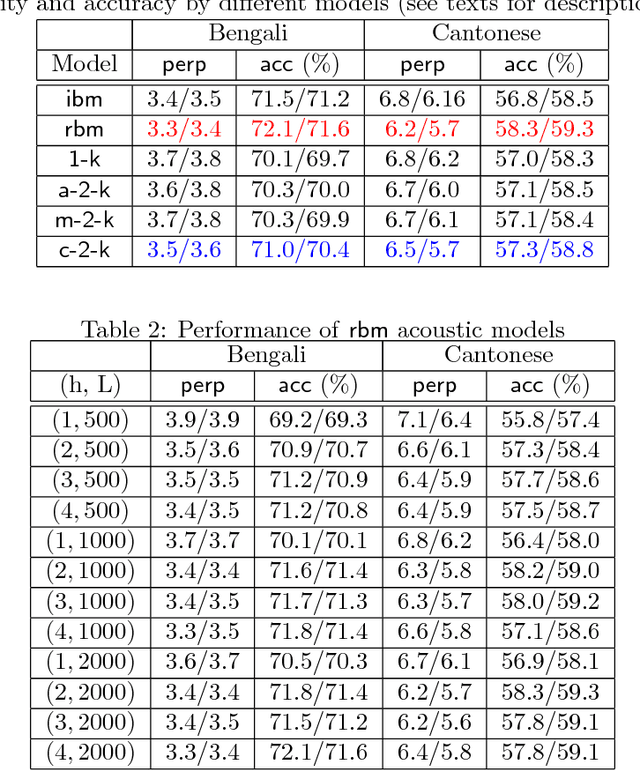
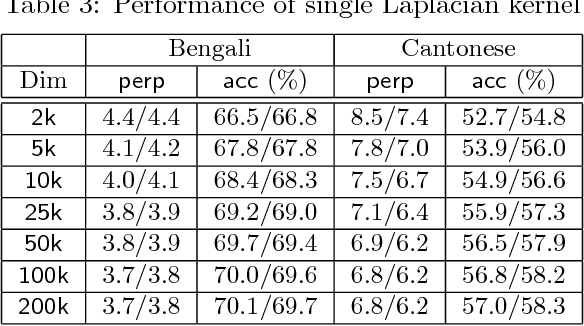
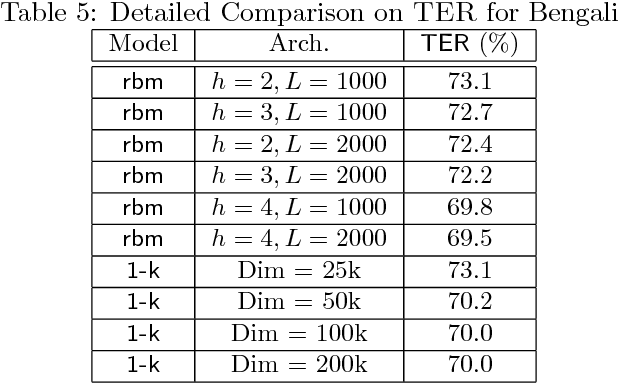
The computational complexity of kernel methods has often been a major barrier for applying them to large-scale learning problems. We argue that this barrier can be effectively overcome. In particular, we develop methods to scale up kernel models to successfully tackle large-scale learning problems that are so far only approachable by deep learning architectures. Based on the seminal work by Rahimi and Recht on approximating kernel functions with features derived from random projections, we advance the state-of-the-art by proposing methods that can efficiently train models with hundreds of millions of parameters, and learn optimal representations from multiple kernels. We conduct extensive empirical studies on problems from image recognition and automatic speech recognition, and show that the performance of our kernel models matches that of well-engineered deep neural nets (DNNs). To the best of our knowledge, this is the first time that a direct comparison between these two methods on large-scale problems is reported. Our kernel methods have several appealing properties: training with convex optimization, cost for training a single model comparable to DNNs, and significantly reduced total cost due to fewer hyperparameters to tune for model selection. Our contrastive study between these two very different but equally competitive models sheds light on fundamental questions such as how to learn good representations.