 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Automation Does a Data Scientist Want?
Jan 07, 2021

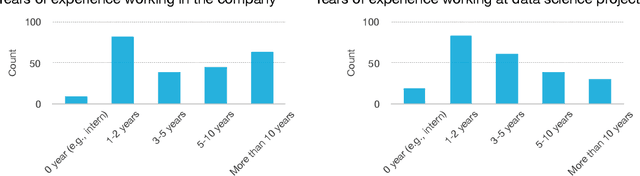
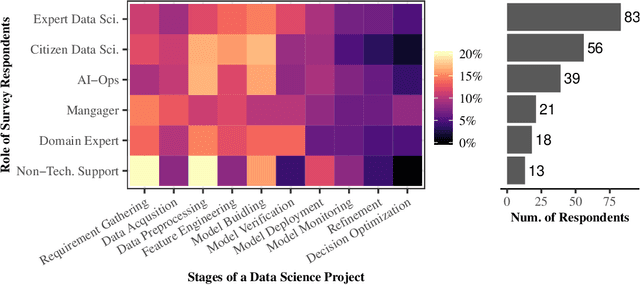
Data science and machine learning (DS/ML) are at the heart of the recent advancements of many Artificial Intelligence (AI) applications. There is an active research thread in AI, \autoai, that aims to develop systems for automating end-to-end the DS/ML Lifecycle. However, do DS and ML workers really want to automate their DS/ML workflow? To answer this question, we first synthesize a human-centered AutoML framework with 6 User Role/Personas, 10 Stages and 43 Sub-Tasks, 5 Levels of Automation, and 5 Types of Explanation, through reviewing research literature and marketing reports. Secondly, we use the framework to guide the design of an online survey study with 217 DS/ML workers who had varying degrees of experience, and different user roles "matching" to our 6 roles/personas. We found that different user personas participated in distinct stages of the lifecycle -- but not all stages. Their desired levels of automation and types of explanation for AutoML also varied significantly depending on the DS/ML stage and the user persona. Based on the survey results, we argue there is no rationale from user needs for complete automation of the end-to-end DS/ML lifecycle. We propose new next steps for user-controlled DS/ML automation.
How do Data Science Workers Collaborate? Roles, Workflows, and Tools
Jan 26, 2020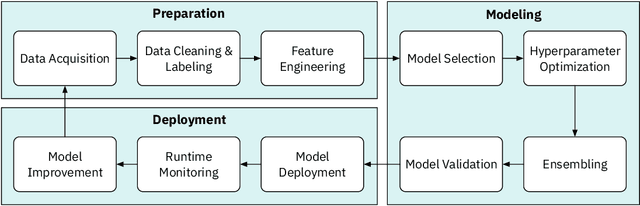

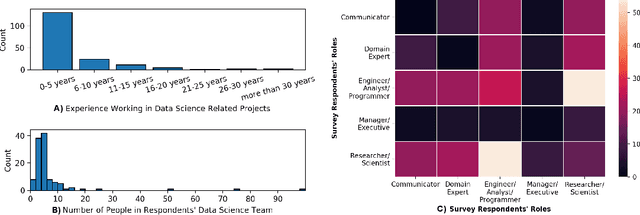
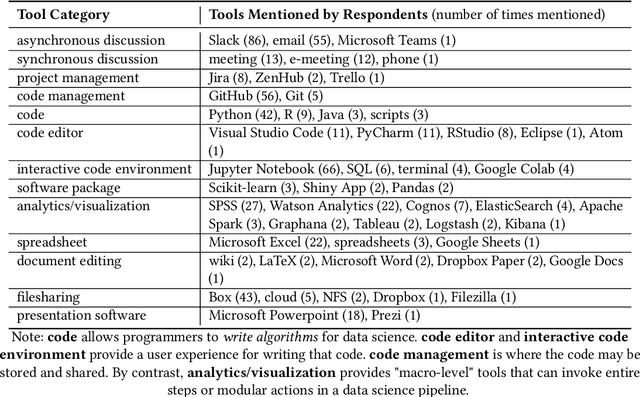
Today, the prominence of data science within organizations has given rise to teams of data science workers collaborating on extracting insights from data, as opposed to individual data scientists working alone. However, we still lack a deep understanding of how data science workers collaborate in practice. In this work, we conducted an online survey with 183 participants who work in various aspects of data science. We focused on their reported interactions with each other (e.g., managers with engineers) and with different tools (e.g., Jupyter Notebook). We found that data science teams are extremely collaborative and work with a variety of stakeholders and tools during the six common steps of a data science workflow (e.g., clean data and train model). We also found that the collaborative practices workers employ, such as documentation, vary according to the kinds of tools they use. Based on these findings, we discuss design implications for supporting data science team collaborations and future research directions.
Trust in AutoML: Exploring Information Needs for Establishing Trust in Automated Machine Learning Systems
Jan 17, 2020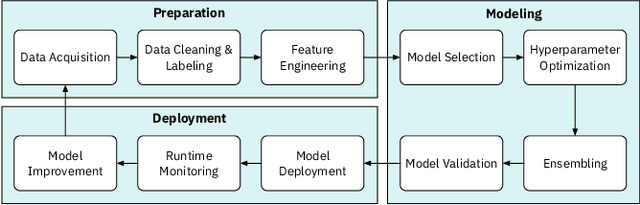

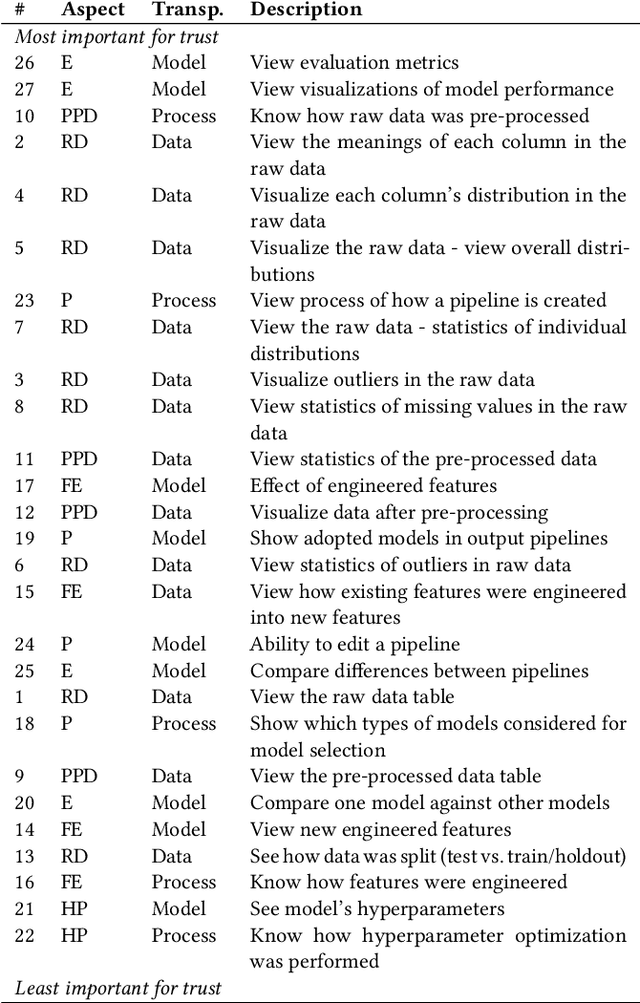
We explore trust in a relatively new area of data science: Automated Machine Learning (AutoML). In AutoML, AI methods are used to generate and optimize machine learning models by automatically engineering features, selecting models, and optimizing hyperparameters. In this paper, we seek to understand what kinds of information influence data scientists' trust in the models produced by AutoML? We operationalize trust as a willingness to deploy a model produced using automated methods. We report results from three studies -- qualitative interviews, a controlled experiment, and a card-sorting task -- to understand the information needs of data scientists for establishing trust in AutoML systems. We find that including transparency features in an AutoML tool increased user trust and understandability in the tool; and out of all proposed features, model performance metrics and visualizations are the most important information to data scientists when establishing their trust with an AutoML tool.
AutoAIViz: Opening the Blackbox of Automated Artificial Intelligence with Conditional Parallel Coordinates
Jan 17, 2020
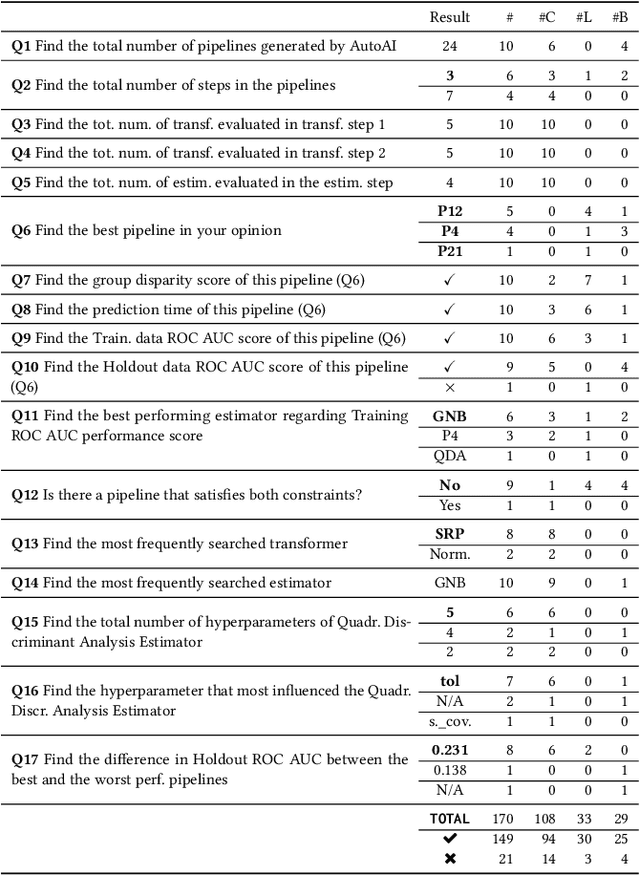
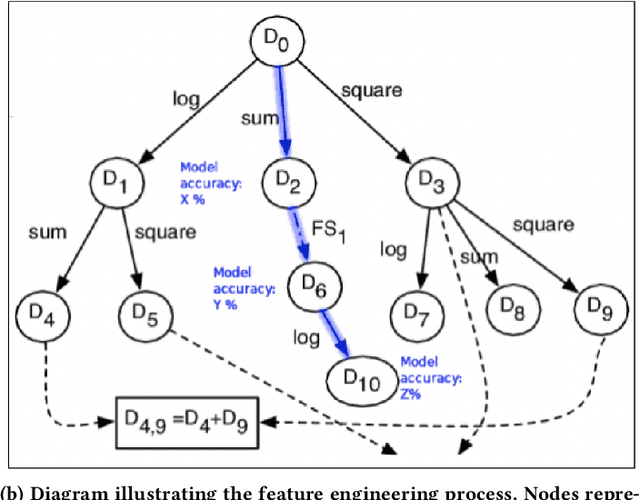
Artificial Intelligence (AI) can now automate the algorithm selection, feature engineering, and hyperparameter tuning steps in a machine learning workflow. Commonly known as AutoML or AutoAI, these technologies aim to relieve data scientists from the tedious manual work. However, today's AutoAI systems often present only limited to no information about the process of how they select and generate model results. Thus, users often do not understand the process, neither do they trust the outputs. In this short paper, we provide a first user evaluation by 10 data scientists of an experimental system, AutoAIViz, that aims to visualize AutoAI's model generation process. We find that the proposed system helps users to complete the data science tasks, and increases their understanding, toward the goal of increasing trust in the AutoAI system.
Enabling Value Sensitive AI Systems through Participatory Design Fictions
Dec 13, 2019Two general routes have been followed to develop artificial agents that are sensitive to human values---a top-down approach to encode values into the agents, and a bottom-up approach to learn from human actions, whether from real-world interactions or stories. Although both approaches have made exciting scientific progress, they may face challenges when applied to the current development practices of AI systems, which require the under-standing of the specific domains and specific stakeholders involved. In this work, we bring together perspectives from the human-computer interaction (HCI) community, where designing technologies sensitive to user values has been a longstanding focus. We highlight several well-established areas focusing on developing empirical methods for inquiring user values. Based on these methods, we propose participatory design fictions to study user values involved in AI systems and present preliminary results from a case study. With this paper, we invite the consideration of user-centered value inquiry and value learning.
How Data Scientists Work Together With Domain Experts in Scientific Collaborations: To Find The Right Answer Or To Ask The Right Question?
Sep 08, 2019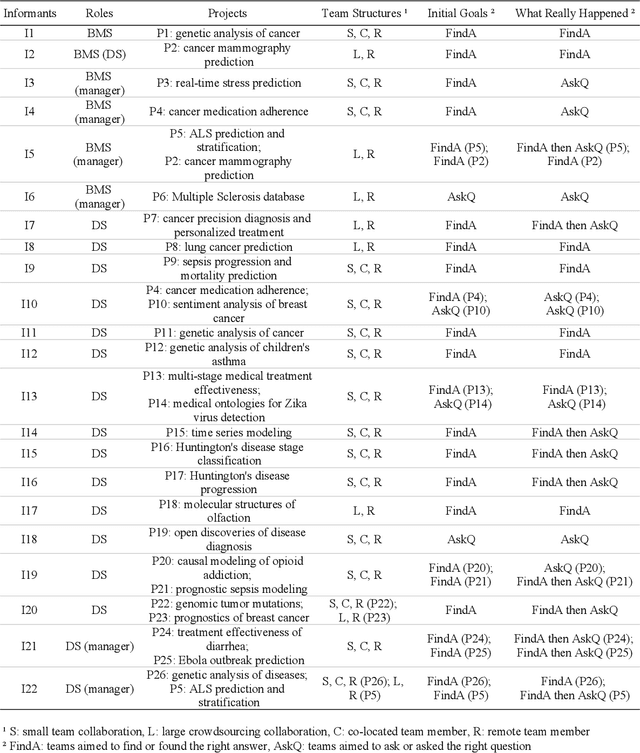

In recent years there has been an increasing trend in which data scientists and domain experts work together to tackle complex scientific questions. However, such collaborations often face challenges. In this paper, we aim to decipher this collaboration complexity through a semi-structured interview study with 22 interviewees from teams of bio-medical scientists collaborating with data scientists. In the analysis, we adopt the Olsons' four-dimensions framework proposed in Distance Matters to code interview transcripts. Our findings suggest that besides the glitches in the collaboration readiness, technology readiness, and coupling of work dimensions, the tensions that exist in the common ground building process influence the collaboration outcomes, and then persist in the actual collaboration process. In contrast to prior works' general account of building a high level of common ground, the breakdowns of content common ground together with the strengthen of process common ground in this process is more beneficial for scientific discovery. We discuss why that is and what the design suggestions are, and conclude the paper with future directions and limitations.
Human-AI Collaboration in Data Science: Exploring Data Scientists' Perceptions of Automated AI
Sep 05, 2019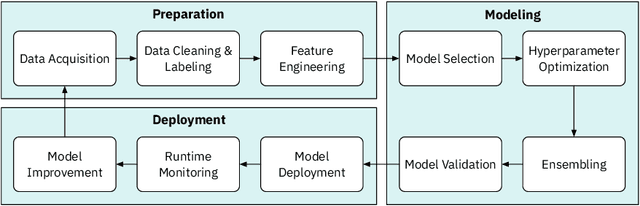
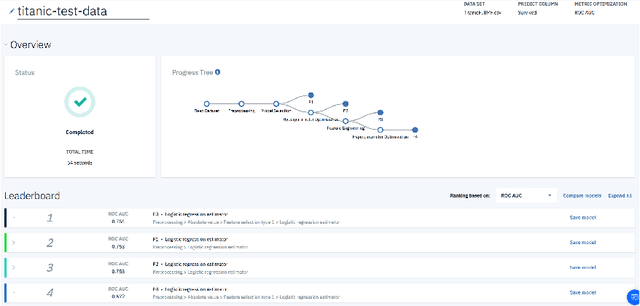
The rapid advancement of artificial intelligence (AI) is changing our lives in many ways. One application domain is data science. New techniques in automating the creation of AI, known as AutoAI or AutoML, aim to automate the work practices of data scientists. AutoAI systems are capable of autonomously ingesting and pre-processing data, engineering new features, and creating and scoring models based on a target objectives (e.g. accuracy or run-time efficiency). Though not yet widely adopted, we are interested in understanding how AutoAI will impact the practice of data science. We conducted interviews with 20 data scientists who work at a large, multinational technology company and practice data science in various business settings. Our goal is to understand their current work practices and how these practices might change with AutoAI. Reactions were mixed: while informants expressed concerns about the trend of automating their jobs, they also strongly felt it was inevitable. Despite these concerns, they remained optimistic about their future job security due to a view that the future of data science work will be a collaboration between humans and AI systems, in which both automation and human expertise are indispensable.