 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighly-Efficient Binary Neural Networks for Visual Place Recognition
Feb 24, 2022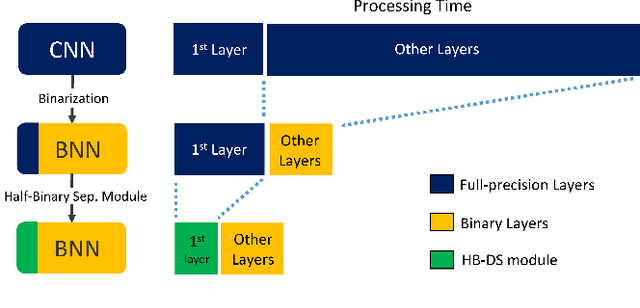
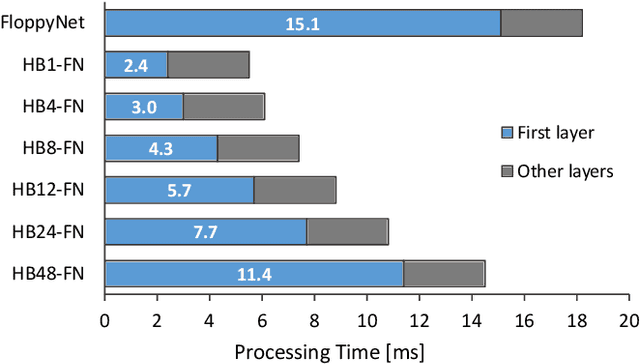

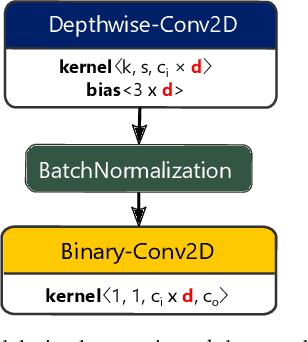
VPR is a fundamental task for autonomous navigation as it enables a robot to localize itself in the workspace when a known location is detected. Although accuracy is an essential requirement for a VPR technique, computational and energy efficiency are not less important for real-world applications. CNN-based techniques archive state-of-the-art VPR performance but are computationally intensive and energy demanding. Binary neural networks (BNN) have been recently proposed to address VPR efficiently. Although a typical BNN is an order of magnitude more efficient than a CNN, its processing time and energy usage can be further improved. In a typical BNN, the first convolution is not completely binarized for the sake of accuracy. Consequently, the first layer is the slowest network stage, requiring a large share of the entire computational effort. This paper presents a class of BNNs for VPR that combines depthwise separable factorization and binarization to replace the first convolutional layer to improve computational and energy efficiency. Our best model achieves state-of-the-art VPR performance while spending considerably less time and energy to process an image than a BNN using a non-binary convolution as a first stage.
MultiRes-NetVLAD: Augmenting Place Recognition Training with Low-Resolution Imagery
Feb 18, 2022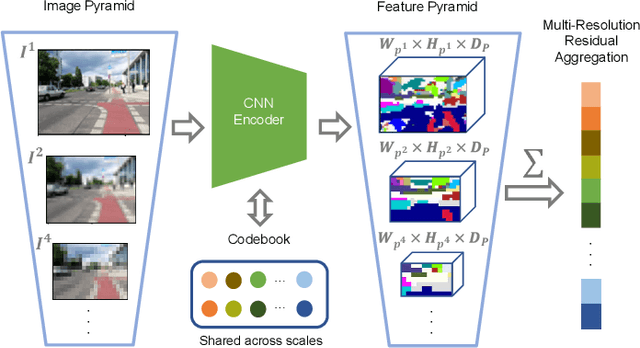
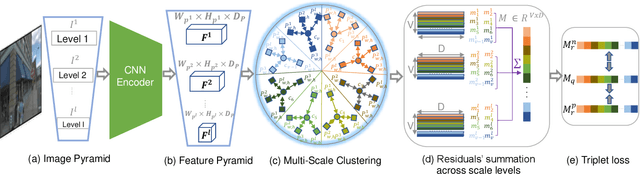
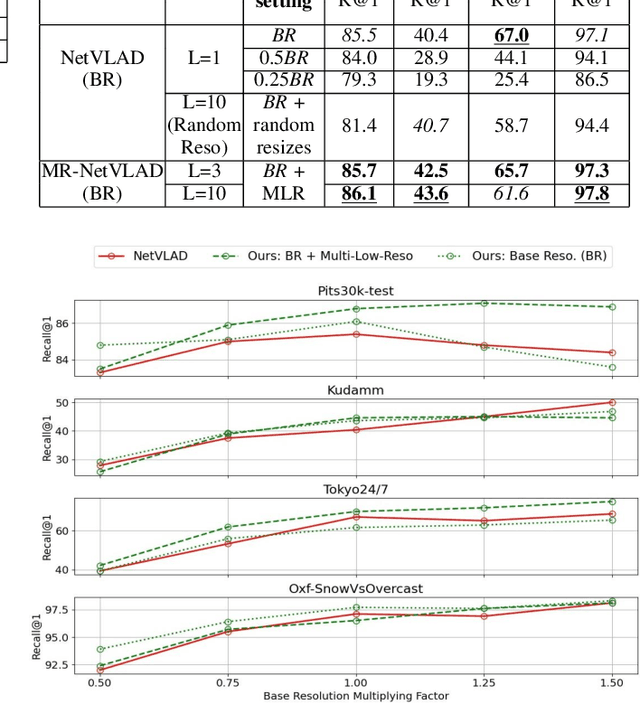

Visual Place Recognition (VPR) is a crucial component of 6-DoF localization, visual SLAM and structure-from-motion pipelines, tasked to generate an initial list of place match hypotheses by matching global place descriptors. However, commonly-used CNN-based methods either process multiple image resolutions after training or use a single resolution and limit multi-scale feature extraction to the last convolutional layer during training. In this paper, we augment NetVLAD representation learning with low-resolution image pyramid encoding which leads to richer place representations. The resultant multi-resolution feature pyramid can be conveniently aggregated through VLAD into a single compact representation, avoiding the need for concatenation or summation of multiple patches in recent multi-scale approaches. Furthermore, we show that the underlying learnt feature tensor can be combined with existing multi-scale approaches to improve their baseline performance. Evaluation on 15 viewpoint-varying and viewpoint-consistent benchmarking datasets confirm that the proposed MultiRes-NetVLAD leads to state-of-the-art Recall@N performance for global descriptor based retrieval, compared against 11 existing techniques. Source code is publicly available at https://github.com/Ahmedest61/MultiRes-NetVLAD.
* 12 pages, 6 Figures, Accepted for publication in IEEE RA-L 2022 and ICRA 2022, includes supplementary material
Unsupervised Complementary-aware Multi-process Fusion for Visual Place Recognition
Dec 09, 2021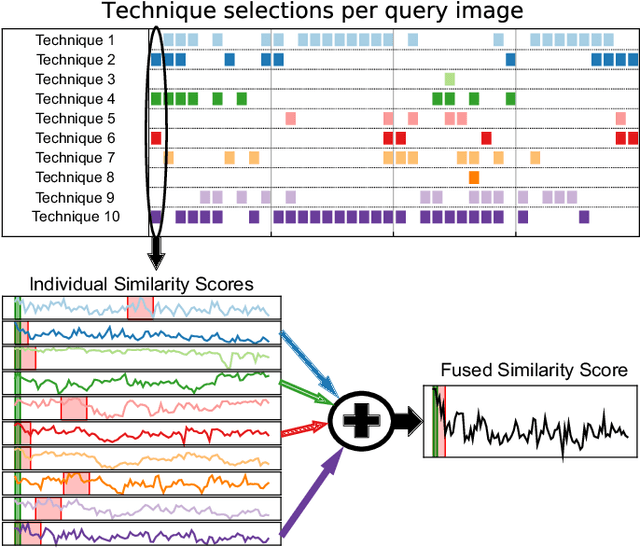
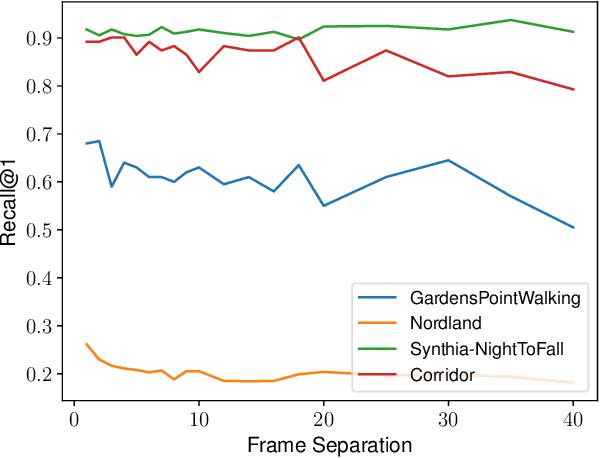
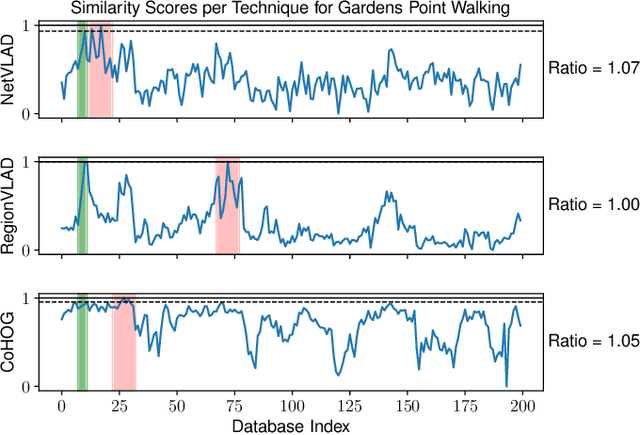
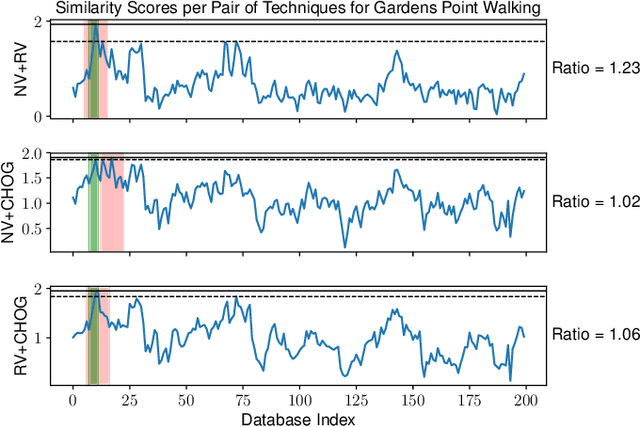
A recent approach to the Visual Place Recognition (VPR) problem has been to fuse the place recognition estimates of multiple complementary VPR techniques simultaneously. However, selecting the optimal set of techniques to use in a specific deployment environment a-priori is a difficult and unresolved challenge. Further, to the best of our knowledge, no method exists which can select a set of techniques on a frame-by-frame basis in response to image-to-image variations. In this work, we propose an unsupervised algorithm that finds the most robust set of VPR techniques to use in the current deployment environment, on a frame-by-frame basis. The selection of techniques is determined by an analysis of the similarity scores between the current query image and the collection of database images and does not require ground-truth information. We demonstrate our approach on a wide variety of datasets and VPR techniques and show that the proposed dynamic multi-process fusion (Dyn-MPF) has superior VPR performance compared to a variety of challenging competitive methods, some of which are given an unfair advantage through access to the ground-truth information.
PointCrack3D: Crack Detection in Unstructured Environments using a 3D-Point-Cloud-Based Deep Neural Network
Nov 23, 2021

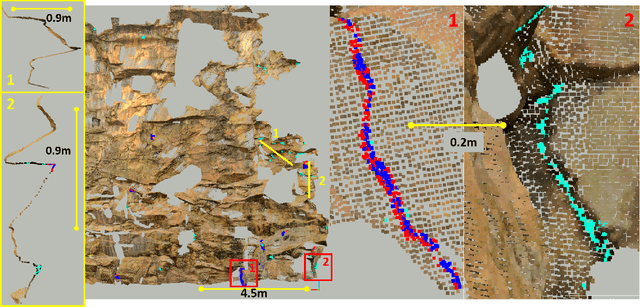
Surface cracks on buildings, natural walls and underground mine tunnels can indicate serious structural integrity issues that threaten the safety of the structure and people in the environment. Timely detection and monitoring of cracks are crucial to managing these risks, especially if the systems can be made highly automated through robots. Vision-based crack detection algorithms using deep neural networks have exhibited promise for structured surfaces such as walls or civil engineering tunnels, but little work has addressed highly unstructured environments such as rock cliffs and bare mining tunnels. To address this challenge, this paper presents PointCrack3D, a new 3D-point-cloud-based crack detection algorithm for unstructured surfaces. The method comprises three key components: an adaptive down-sampling method that maintains sufficient crack point density, a DNN that classifies each point as crack or non-crack, and a post-processing clustering method that groups crack points into crack instances. The method was validated experimentally on a new large natural rock dataset, comprising coloured LIDAR point clouds spanning more than 900 m^2 and 412 individual cracks. Results demonstrate a crack detection rate of 97% overall and 100% for cracks with a maximum width of more than 3 cm, significantly outperforming the state of the art. Furthermore, for cross-validation, PointCrack3D was applied to an entirely new dataset acquired in different locations and not used at all in training and shown to detect 100% of its crack instances. We also characterise the relationship between detection performance, crack width and number of points per crack, providing a foundation upon which to make decisions about both practical deployments and future research directions.
A Benchmark Comparison of Visual Place Recognition Techniques for Resource-Constrained Embedded Platforms
Sep 22, 2021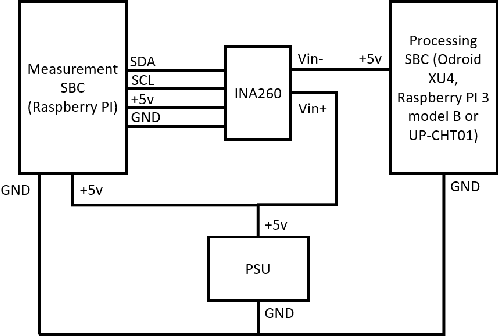
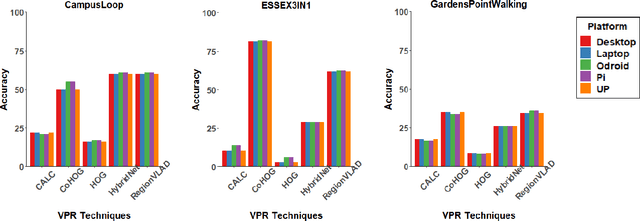
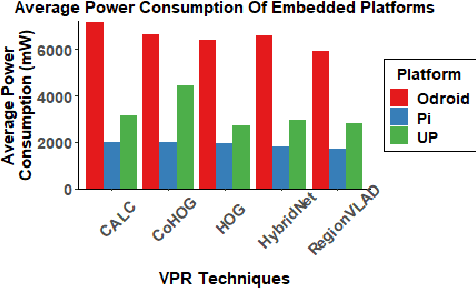
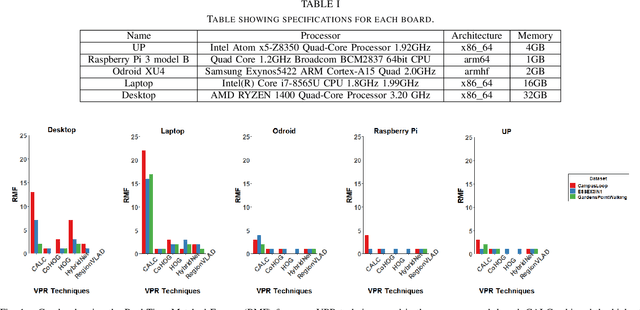
Visual Place Recognition (VPR) has been a subject of significant research over the last 15 to 20 years. VPR is a fundamental task for autonomous navigation as it enables self-localization within an environment. Although robots are often equipped with resource-constrained hardware, the computational requirements of and effects on VPR techniques have received little attention. In this work, we present a hardware-focused benchmark evaluation of a number of state-of-the-art VPR techniques on public datasets. We consider popular single board computers, including ODroid, UP and Raspberry Pi 3, in addition to a commodity desktop and laptop for reference. We present our analysis based on several key metrics, including place-matching accuracy, image encoding time, descriptor matching time and memory needs. Key questions addressed include: (1) How does the performance accuracy of a VPR technique change with processor architecture? (2) How does power consumption vary for different VPR techniques and embedded platforms? (3) How much does descriptor size matter in comparison to today's embedded platforms' storage? (4) How does the performance of a high-end platform relate to an on-board low-end embedded platform for VPR? The extensive analysis and results in this work serve not only as a benchmark for the VPR community, but also provide useful insights for real-world adoption of VPR applications.
An Efficient and Scalable Collection of Fly-inspired Voting Units for Visual Place Recognition in Changing Environments
Sep 22, 2021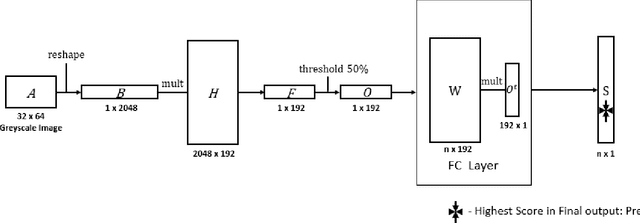
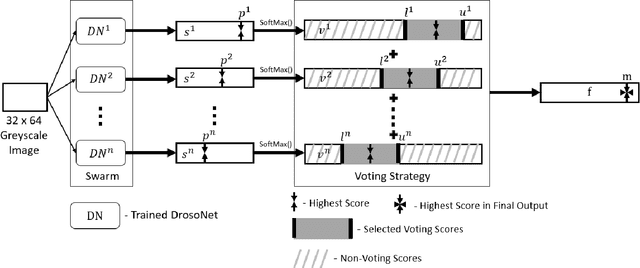
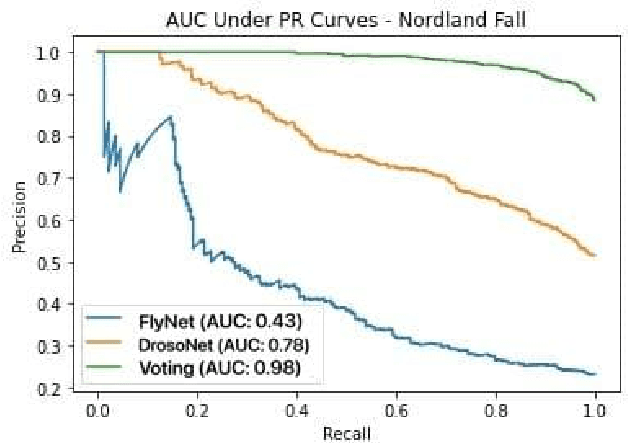
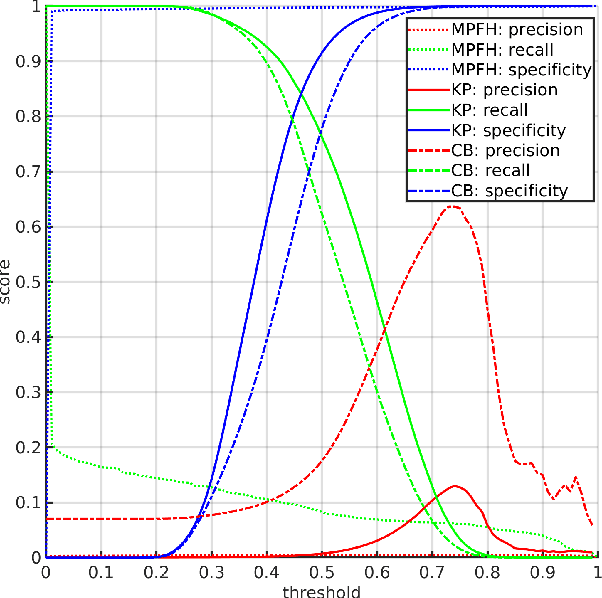
State-of-the-art visual place recognition performance is currently being achieved utilizing deep learning based approaches. Despite the recent efforts in designing lightweight convolutional neural network based models, these can still be too expensive for the most hardware restricted robot applications. Low-overhead VPR techniques would not only enable platforms equipped with low-end, cheap hardware but also reduce computation on more powerful systems, allowing these resources to be allocated for other navigation tasks. In this work, our goal is to provide an algorithm of extreme compactness and efficiency while achieving state-of-the-art robustness to appearance changes and small point-of-view variations. Our first contribution is DrosoNet, an exceptionally compact model inspired by the odor processing abilities of the fruit fly, Drosophyla melanogaster. Our second and main contribution is a voting mechanism that leverages multiple small and efficient classifiers to achieve more robust and consistent VPR compared to a single one. We use DrosoNet as the baseline classifier for the voting mechanism and evaluate our models on five benchmark datasets, assessing moderate to extreme appearance changes and small to moderate viewpoint variations. We then compare the proposed algorithms to state-of-the-art methods, both in terms of precision-recall AUC results and computational efficiency.
Spiking Neural Networks for Visual Place Recognition via Weighted Neuronal Assignments
Sep 14, 2021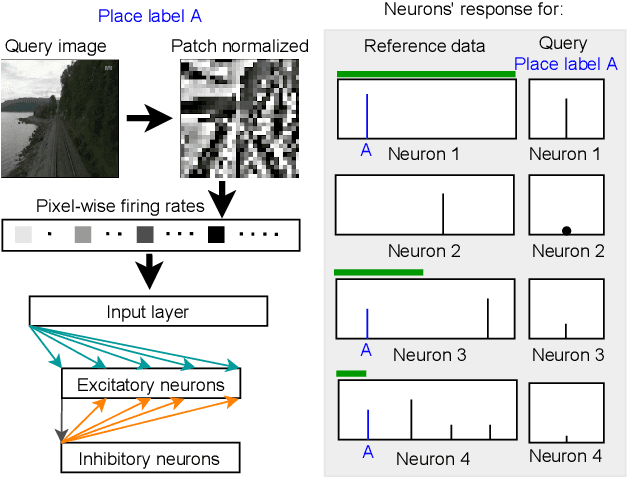
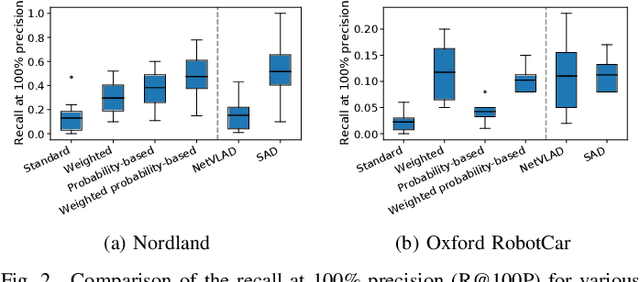
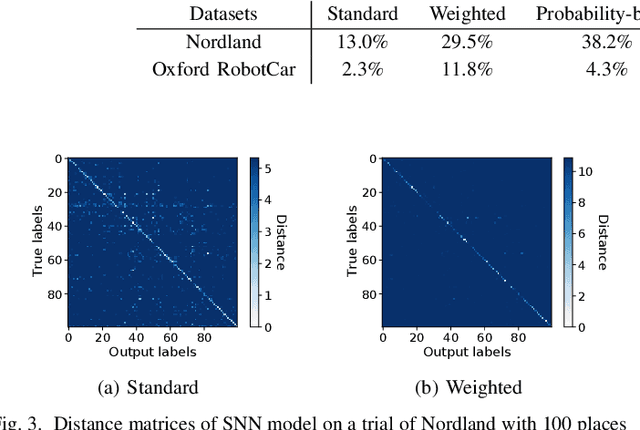
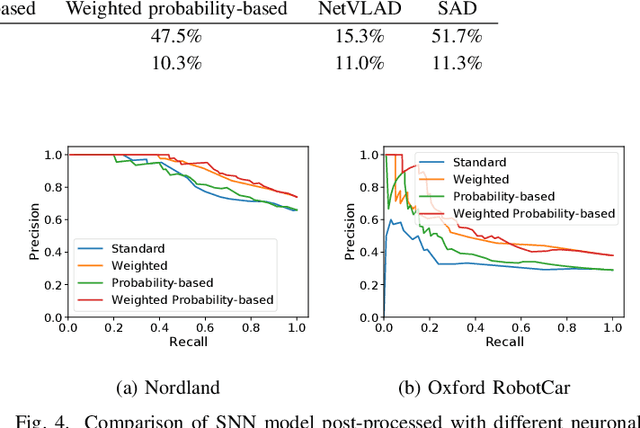
Spiking neural networks (SNNs) offer both compelling potential advantages, including energy efficiency and low latencies, and challenges including the non-differentiable nature of event spikes. Much of the initial research in this area has converted deep neural networks to equivalent SNNs, but this conversion approach potentially negates some of the potential advantages of SNN-based approaches developed from scratch. One promising area for high performance SNNs is template matching and image recognition. This research introduces the first high performance SNN for the Visual Place Recognition (VPR) task: given a query image, the SNN has to find the closest match out of a list of reference images. At the core of this new system is a novel assignment scheme that implements a form of ambiguity-informed salience, by up-weighting single-place-encoding neurons and down-weighting "ambiguous" neurons that respond to multiple different reference places. In a range of experiments on the challenging Oxford RobotCar and Nordland datasets, we show that our SNN achieves comparable VPR performance to state-of-the-art and classical techniques, and degrades gracefully in performance with an increasing number of reference places. Our results provide a significant milestone towards SNNs that can provide robust, energy-efficient and low latency robot localization.
Zero-Shot Domain Adaptation with a Physics Prior
Aug 11, 2021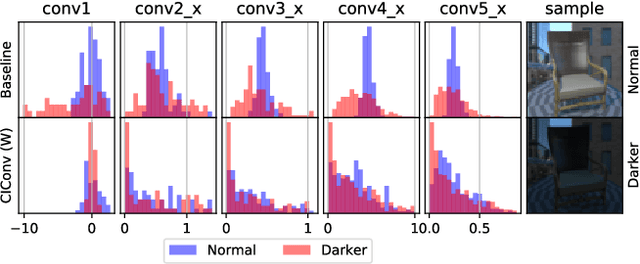


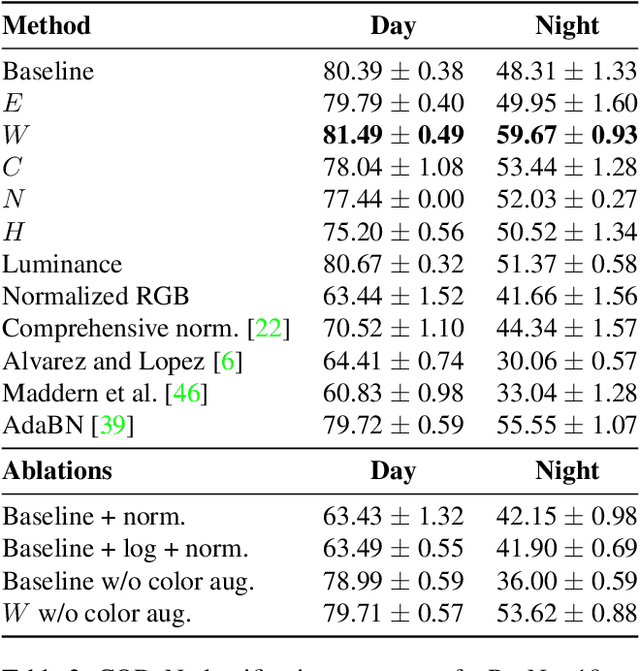
We explore the zero-shot setting for day-night domain adaptation. The traditional domain adaptation setting is to train on one domain and adapt to the target domain by exploiting unlabeled data samples from the test set. As gathering relevant test data is expensive and sometimes even impossible, we remove any reliance on test data imagery and instead exploit a visual inductive prior derived from physics-based reflection models for domain adaptation. We cast a number of color invariant edge detectors as trainable layers in a convolutional neural network and evaluate their robustness to illumination changes. We show that the color invariant layer reduces the day-night distribution shift in feature map activations throughout the network. We demonstrate improved performance for zero-shot day to night domain adaptation on both synthetic as well as natural datasets in various tasks, including classification, segmentation and place recognition.
Bayesian Controller Fusion: Leveraging Control Priors in Deep Reinforcement Learning for Robotics
Jul 22, 2021
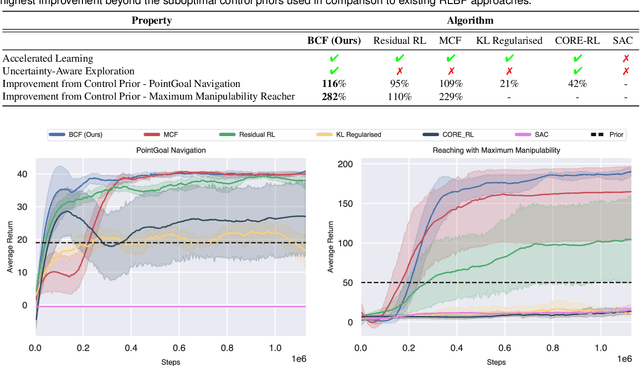
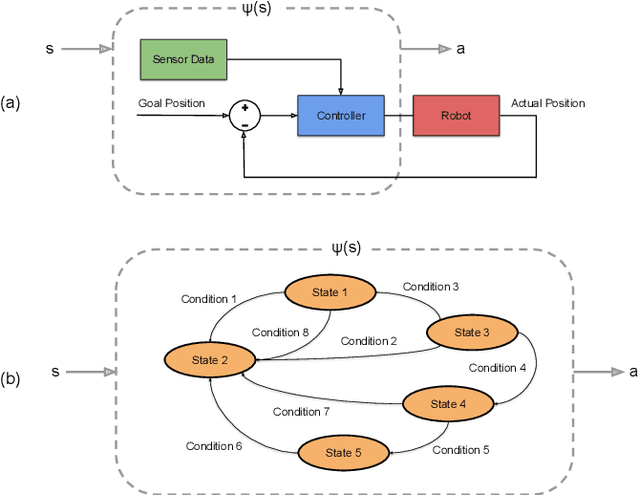
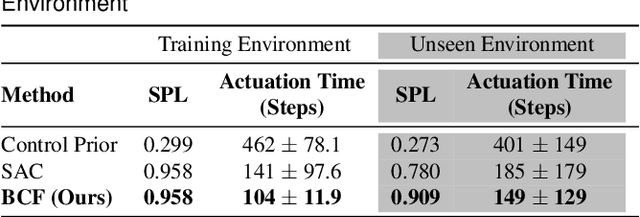
We present Bayesian Controller Fusion (BCF): a hybrid control strategy that combines the strengths of traditional hand-crafted controllers and model-free deep reinforcement learning (RL). BCF thrives in the robotics domain, where reliable but suboptimal control priors exist for many tasks, but RL from scratch remains unsafe and data-inefficient. By fusing uncertainty-aware distributional outputs from each system, BCF arbitrates control between them, exploiting their respective strengths. We study BCF on two real-world robotics tasks involving navigation in a vast and long-horizon environment, and a complex reaching task that involves manipulability maximisation. For both these domains, there exist simple handcrafted controllers that can solve the task at hand in a risk-averse manner but do not necessarily exhibit the optimal solution given limitations in analytical modelling, controller miscalibration and task variation. As exploration is naturally guided by the prior in the early stages of training, BCF accelerates learning, while substantially improving beyond the performance of the control prior, as the policy gains more experience. More importantly, given the risk-aversity of the control prior, BCF ensures safe exploration and deployment, where the control prior naturally dominates the action distribution in states unknown to the policy. We additionally show BCF's applicability to the zero-shot sim-to-real setting and its ability to deal with out-of-distribution states in the real-world. BCF is a promising approach for combining the complementary strengths of deep RL and traditional robotic control, surpassing what either can achieve independently. The code and supplementary video material are made publicly available at https://krishanrana.github.io/bcf.
Probabilistic Appearance-Invariant Topometric Localization with New Place Awareness
Jul 16, 2021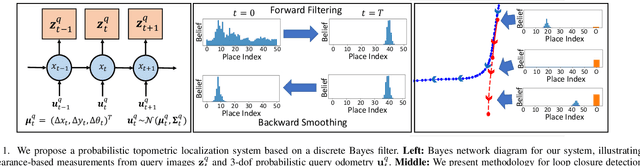
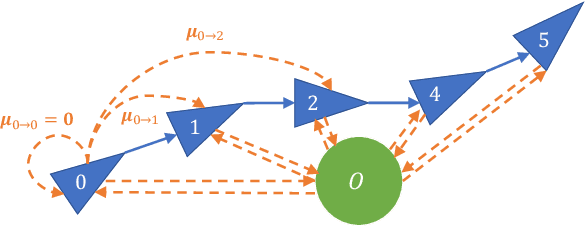
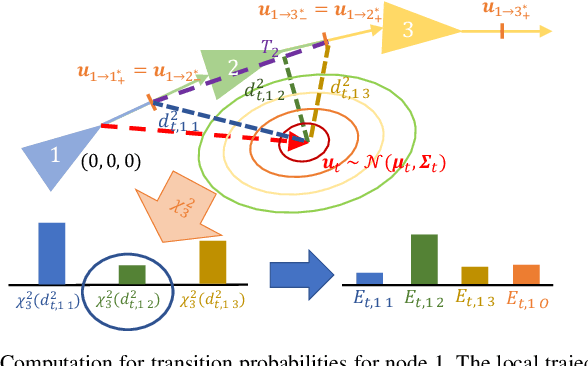
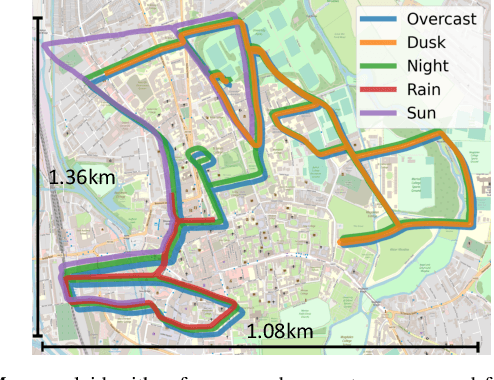
Probabilistic state-estimation approaches offer a principled foundation for designing localization systems, because they naturally integrate sequences of imperfect motion and exteroceptive sensor data. Recently, probabilistic localization systems utilizing appearance-invariant visual place recognition (VPR) methods as the primary exteroceptive sensor have demonstrated state-of-the-art performance in the presence of substantial appearance change. However, existing systems 1) do not fully utilize odometry data within the motion models, and 2) are unable to handle route deviations, due to the assumption that query traverses exactly repeat the mapping traverse. To address these shortcomings, we present a new probabilistic topometric localization system which incorporates full 3-dof odometry into the motion model and furthermore, adds an "off-map" state within the state-estimation framework, allowing query traverses which feature significant route detours from the reference map to be successfully localized. We perform extensive evaluation on multiple query traverses from the Oxford RobotCar dataset exhibiting both significant appearance change and deviations from routes previously traversed. In particular, we evaluate performance on two practically relevant localization tasks: loop closure detection and global localization. Our approach achieves major performance improvements over both existing and improved state-of-the-art systems.
* 8 pages