 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelta Descriptors: Change-Based Place Representation for Robust Visual Localization
Jun 10, 2020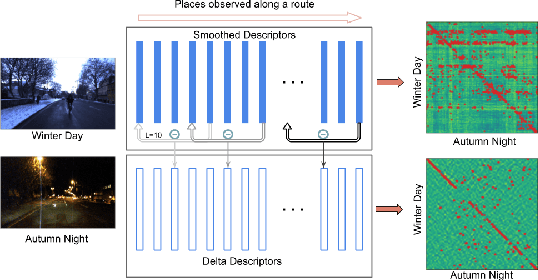
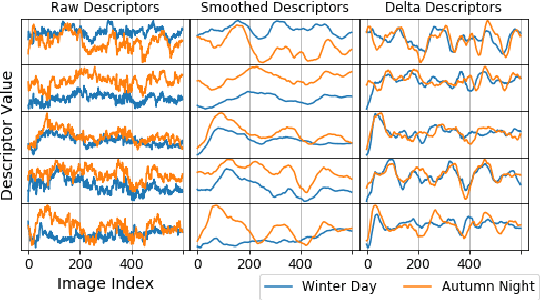

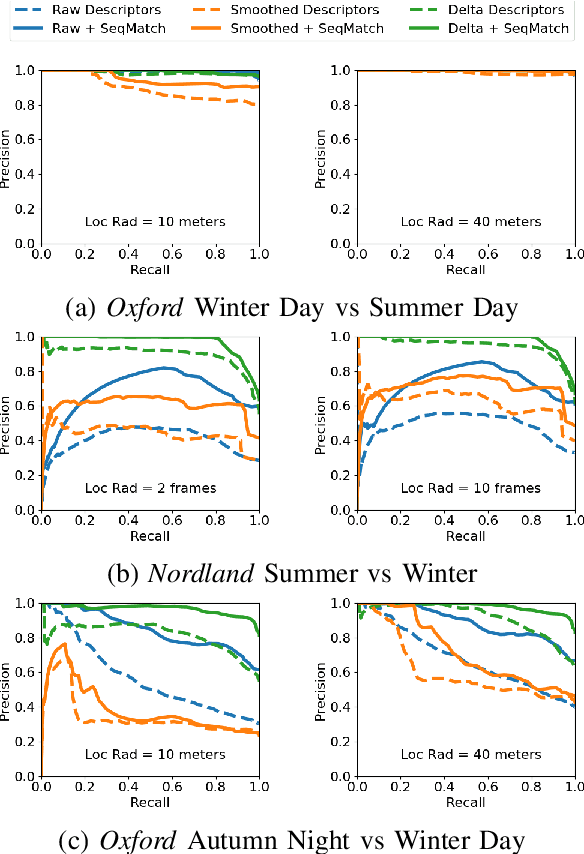
Visual place recognition is challenging because there are so many factors that can cause the appearance of a place to change, from day-night cycles to seasonal change to atmospheric conditions. In recent years a large range of approaches have been developed to address this challenge including deep-learnt image descriptors, domain translation, and sequential filtering, all with shortcomings including generality and velocity-sensitivity. In this paper we propose a novel descriptor derived from tracking changes in any learned global descriptor over time, dubbed Delta Descriptors. Delta Descriptors mitigate the offsets induced in the original descriptor matching space in an unsupervised manner by considering temporal differences across places observed along a route. Like all other approaches, Delta Descriptors have a shortcoming - volatility on a frame to frame basis - which can be overcome by combining them with sequential filtering methods. Using two benchmark datasets, we first demonstrate the high performance of Delta Descriptors in isolation, before showing new state-of-the-art performance when combined with sequence-based matching. We also present results demonstrating the approach working with a second different underlying descriptor type, and two other beneficial properties of Delta Descriptors in comparison to existing techniques: their increased inherent robustness to variations in camera motion and a reduced rate of performance degradation as dimensional reduction is applied. Source code will be released upon publication.
Event-based visual place recognition with ensembles of spatio-temporal windows
May 22, 2020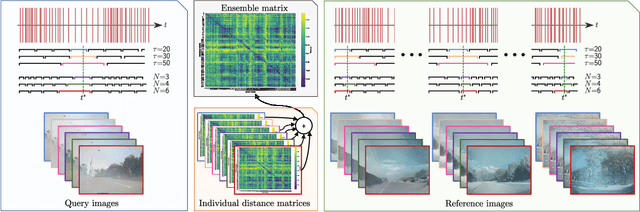


Event cameras are bio-inspired sensors capable of providing a continuous stream of events with low latency and high dynamic range. As a single event only carries limited information about the brightness change at a particular pixel, events are commonly accumulated into spatio-temporal windows for further processing. However, the optimal window length varies depending on the scene, camera motion, the task being performed, and other factors. In this research, we develop a novel ensemble-based scheme for combining spatio-temporal windows of varying lengths that are processed in parallel. For applications where the increased computational requirements of this approach are not practical, we also introduce a new "approximate" ensemble scheme that achieves significant computational efficiencies without unduly compromising the original performance gains provided by the ensemble approach. We demonstrate our ensemble scheme on the visual place recognition (VPR) task, introducing a new Brisbane-Event-VPR dataset with annotated recordings captured using a DAVIS346 color event camera. We show that our proposed ensemble scheme significantly outperforms all the single-window baselines and conventional model-based ensembles, irrespective of the image reconstruction and feature extraction methods used in the VPR pipeline, and evaluate which ensemble combination technique performs best. These results demonstrate the significant benefits of ensemble schemes for event camera processing in the VPR domain and may have relevance to other related processes, including feature tracking, visual-inertial odometry, and steering prediction in driving.
VPR-Bench: An Open-Source Visual Place Recognition Evaluation Framework with Quantifiable Viewpoint and Appearance Change
May 17, 2020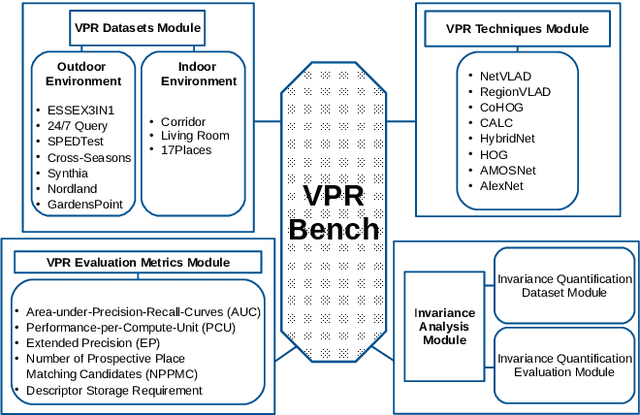
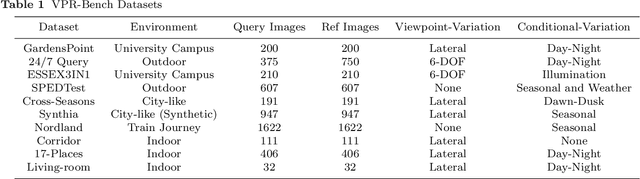
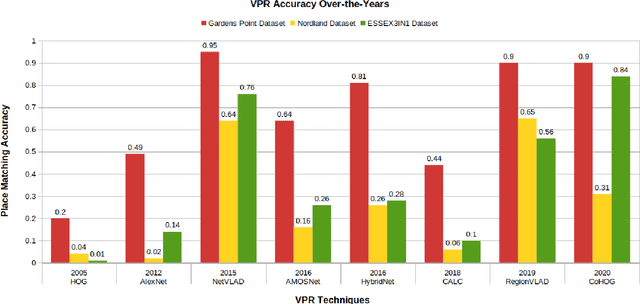
Visual Place Recognition (VPR) is the process of recognising a previously visited place using visual information, often under varying appearance conditions and viewpoint changes and with computational constraints. VPR is a critical component of many autonomous navigation systems ranging from autonomous vehicles to drones. While the concept of place recognition has been around for many years, VPR research has grown rapidly as a field over the past decade due to both improving camera hardware technologies and its suitability for application of deep learning-based techniques. With this growth however has come field fragmentation, lack of standardisation and a disconnect between current performance metrics and the actual utility of a VPR technique at application-deployment. In this paper we address these key challenges through a new comprehensive open-source evaluation framework, dubbed 'VPR-Bench'. VPR-Bench introduces two much-needed capabilities for researchers: firstly, quantification of viewpoint and illumination variation, replacing what has largely been assessed qualitatively in the past, and secondly, new metrics 'Extended precision' (EP), 'Performance-Per-Compute-Unit' (PCU) and 'Number of Prospective Place Matching Candidates' (NPPMC). These new metrics complement the limitations of traditional Precision-Recall curves, by providing measures that are more informative to the wide range of potential VPR applications. Mechanistically, we develop new unified templates that facilitate the implementation, deployment and evaluation of a wide range of VPR techniques and datasets. We incorporate the most comprehensive combination of state-of-the-art VPR techniques and datasets to date into VPR-Bench and demonstrate how it provides a rich range of previously inaccessible insights, such as the nuanced relationship between viewpoint invariance, different types of VPR techniques and datasets.
Class Anchor Clustering: a Distance-based Loss for Training Open Set Classifiers
Apr 06, 2020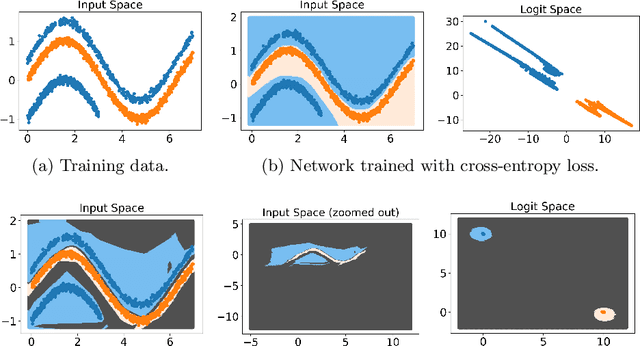
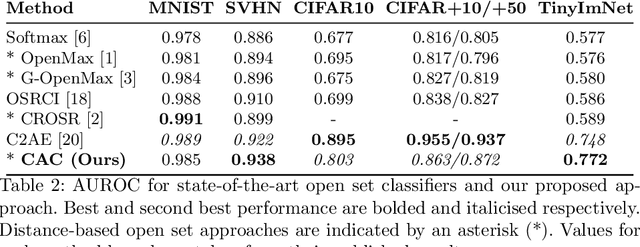
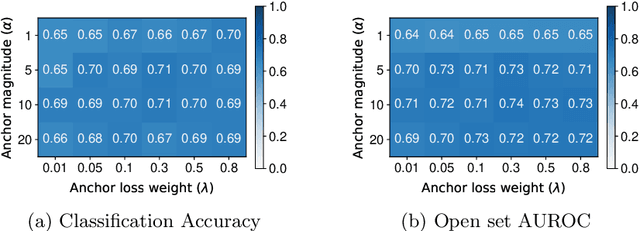
Existing open set classifiers distinguish between known and unknown inputs by measuring distance in a network's logit space, assuming that known inputs cluster closer to the training data than unknown inputs. However, this approach is typically applied post-hoc to networks trained with cross-entropy loss, which neither guarantees nor encourages the hoped-for clustering behaviour. To overcome this limitation, we introduce Class Anchor Clustering (CAC) loss. CAC is an entirely distance-based loss that explicitly encourages training data to form tight clusters around class-dependent anchor points in the logit space. We show that an open set classifier trained with CAC loss outperforms all state-of-the-art techniques on the challenging TinyImageNet dataset, achieving a 2.4% performance increase in AUROC. In addition, our approach outperforms other state-of-the-art distance-based approaches on a number of further relevant datasets. We will make the code for CAC publicly available.
Multiplicative Controller Fusion: A Hybrid Navigation Strategy For Deployment in Unknown Environments
Mar 13, 2020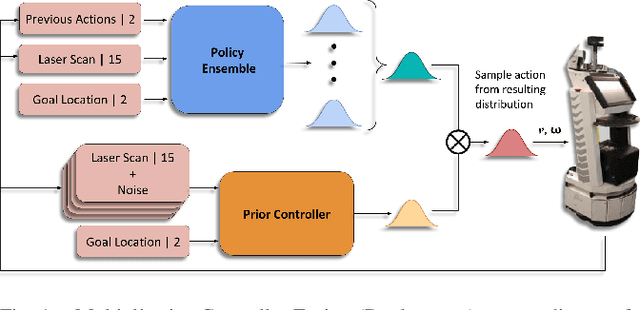
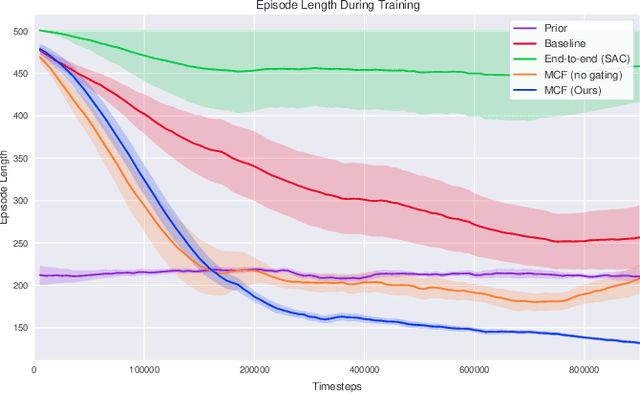
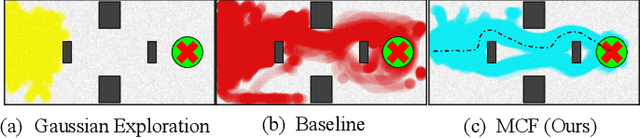
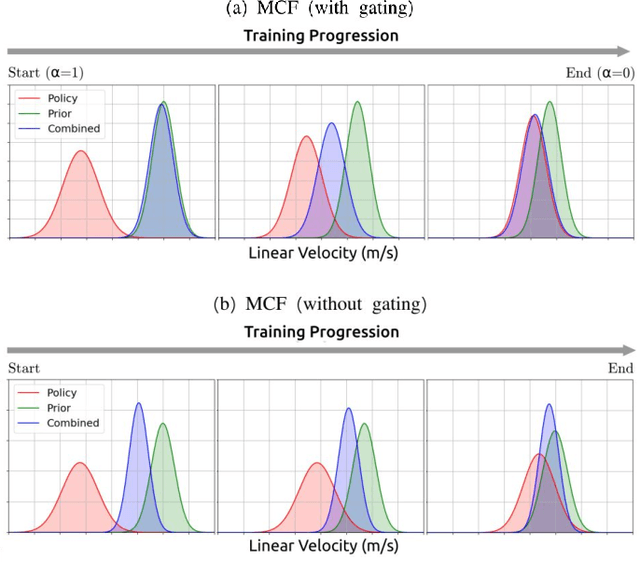
Learning-based approaches often outperform hand-coded algorithmic solutions for many problems in robotics. However, learning long-horizon tasks on real robot hardware can be intractable, and transferring a learned policy from simulation to reality is still extremely challenging. We present a novel approach to model-free reinforcement learning that can leverage existing sub-optimal solutions as an algorithmic prior during training and deployment. During training, our gated fusion approach enables the prior to guide the initial stages of exploration, increasing sample-efficiency and enabling learning from sparse long-horizon reward signals. Importantly, the policy can learn to improve beyond the performance of the sub-optimal prior since the prior's influence is annealed gradually. During deployment, the policy's uncertainty provides a reliable strategy for transferring a simulation-trained policy to the real world by falling back to the prior controller in uncertain states. We show the efficacy of our Multiplicative Controller Fusion approach on the task of robot navigation and demonstrate safe transfer from simulation to the real world without any fine tuning. The code for this project is made publicly available at https://sites.google.com/view/mcf-nav/home.
MVP: Unified Motion and Visual Self-Supervised Learning for Large-Scale Robotic Navigation
Mar 02, 2020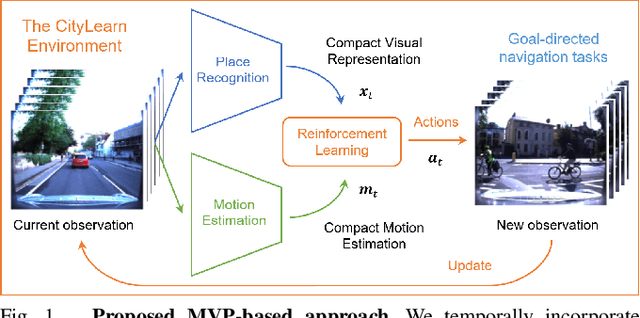
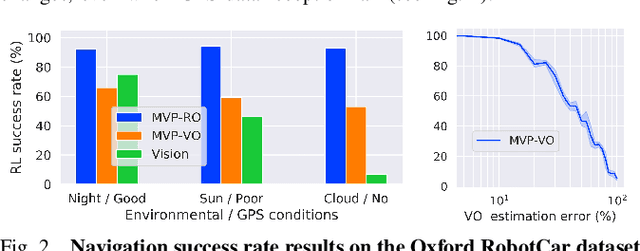

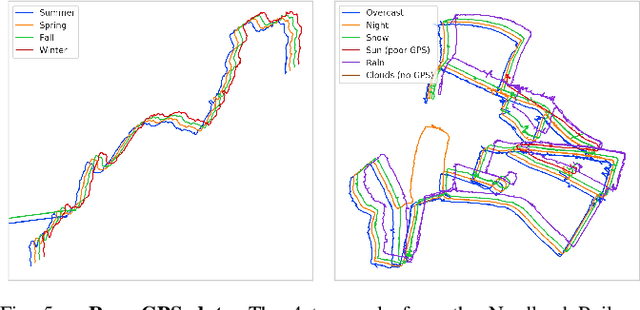
Autonomous navigation emerges from both motion and local visual perception in real-world environments. However, most successful robotic motion estimation methods (e.g. VO, SLAM, SfM) and vision systems (e.g. CNN, visual place recognition-VPR) are often separately used for mapping and localization tasks. Conversely, recent reinforcement learning (RL) based methods for visual navigation rely on the quality of GPS data reception, which may not be reliable when directly using it as ground truth across multiple, month-spaced traversals in large environments. In this paper, we propose a novel motion and visual perception approach, dubbed MVP, that unifies these two sensor modalities for large-scale, target-driven navigation tasks. Our MVP-based method can learn faster, and is more accurate and robust to both extreme environmental changes and poor GPS data than corresponding vision-only navigation methods. MVP temporally incorporates compact image representations, obtained using VPR, with optimized motion estimation data, including but not limited to those from VO or optimized radar odometry (RO), to efficiently learn self-supervised navigation policies via RL. We evaluate our method on two large real-world datasets, Oxford Robotcar and Nordland Railway, over a range of weather (e.g. overcast, night, snow, sun, rain, clouds) and seasonal (e.g. winter, spring, fall, summer) conditions using the new CityLearn framework; an interactive environment for efficiently training navigation agents. Our experimental results, on traversals of the Oxford RobotCar dataset with no GPS data, show that MVP can achieve 53% and 93% navigation success rate using VO and RO, respectively, compared to 7% for a vision-only method. We additionally report a trade-off between the RL success rate and the motion estimation precision.
Hierarchical Multi-Process Fusion for Visual Place Recognition
Jan 28, 2020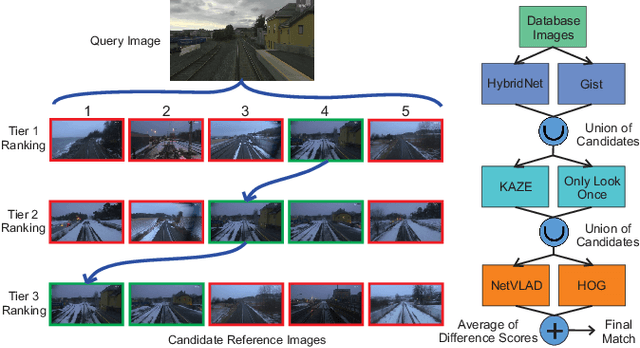
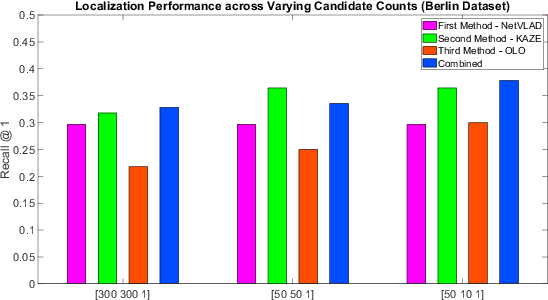
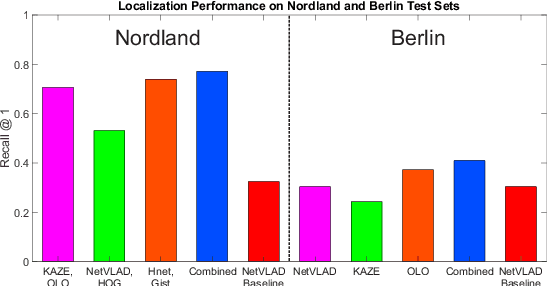
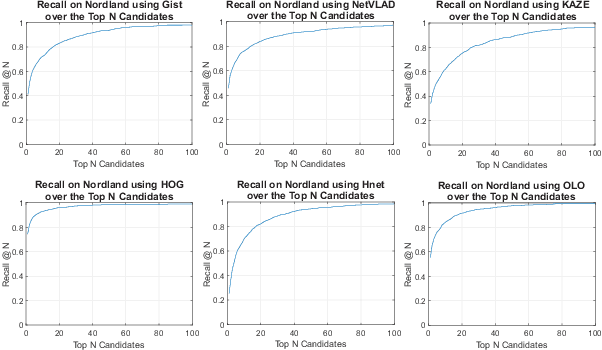
Combining multiple complementary techniques together has long been regarded as a way to improve performance. In visual localization, multi-sensor fusion, multi-process fusion of a single sensing modality, and even combinations of different localization techniques have been shown to result in improved performance. However, merely fusing together different localization techniques does not account for the varying performance characteristics of different localization techniques. In this paper we present a novel, hierarchical localization system that explicitly benefits from three varying characteristics of localization techniques: the distribution of their localization hypotheses, their appearance- and viewpoint-invariant properties, and the resulting differences in where in an environment each system works well and fails. We show how two techniques deployed hierarchically work better than in parallel fusion, how combining two different techniques works better than two levels of a single technique, even when the single technique has superior individual performance, and develop two and three-tier hierarchical structures that progressively improve localization performance. Finally, we develop a stacked hierarchical framework where localization hypotheses from techniques with complementary characteristics are concatenated at each layer, significantly improving retention of the correct hypothesis through to the final localization stage. Using two challenging datasets, we show the proposed system outperforming state-of-the-art techniques.
Fast, Compact and Highly Scalable Visual Place Recognition through Sequence-based Matching of Overloaded Representations
Jan 23, 2020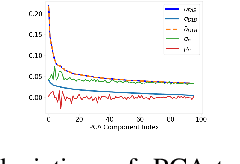
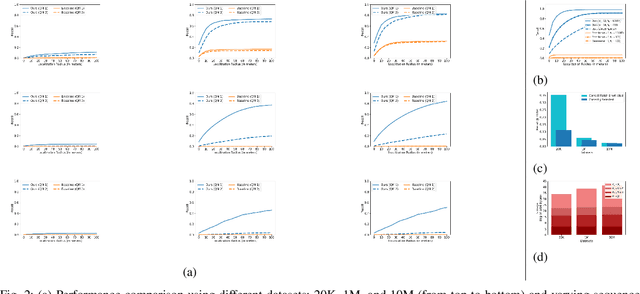
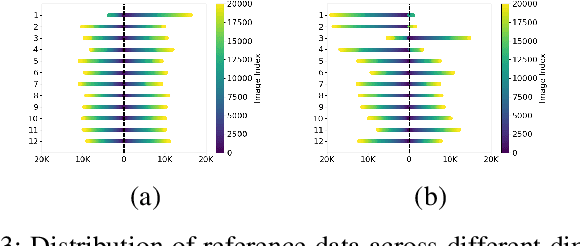
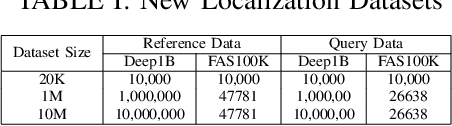
Visual place recognition algorithms trade off three key characteristics: their storage footprint, their computational requirements, and their resultant performance, often expressed in terms of recall rate. Significant prior work has investigated highly compact place representations, sub-linear computational scaling and sub-linear storage scaling techniques, but have always involved a significant compromise in one or more of these regards, and have only been demonstrated on relatively small datasets. In this paper we present a novel place recognition system which enables for the first time the combination of ultra-compact place representations, near sub-linear storage scaling and extremely lightweight compute requirements. Our approach exploits the inherently sequential nature of much spatial data in the robotics domain and inverts the typical target criteria, through intentionally coarse scalar quantization-based hashing that leads to more collisions but is resolved by sequence-based matching. For the first time, we show how effective place recognition rates can be achieved on a new very large 10 million place dataset, requiring only 8 bytes of storage per place and 37K unitary operations to achieve over 50% recall for matching a sequence of 100 frames, where a conventional state-of-the-art approach both consumes 1300 times more compute and fails catastrophically. We present analysis investigating the effectiveness of our hashing overload approach under varying sizes of quantized vector length, comparison of near miss matches with the actual match selections and characterise the effect of variance re-scaling of data on quantization.
A Compact Neural Architecture for Visual Place Recognition
Oct 15, 2019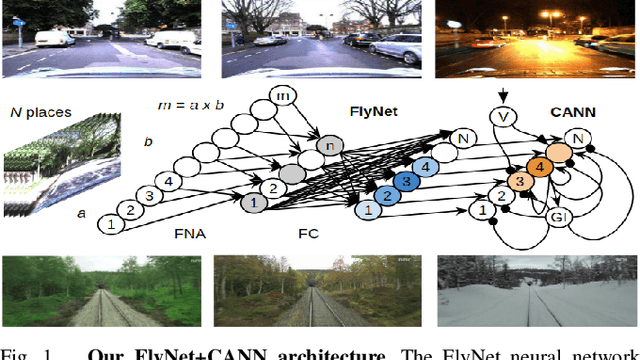
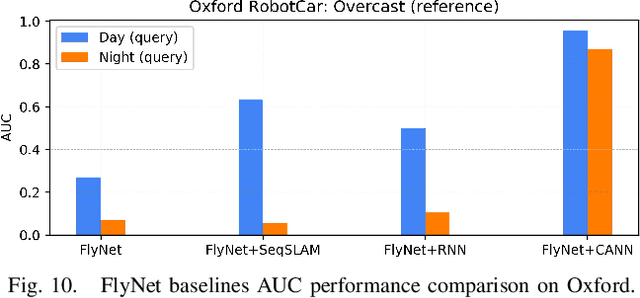
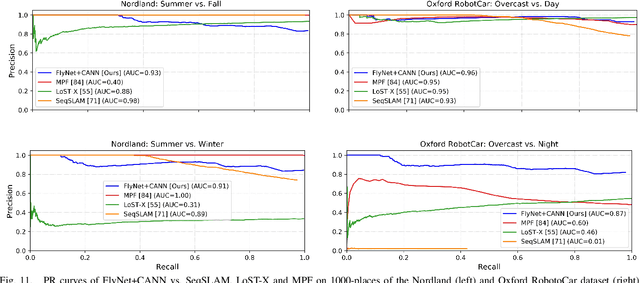
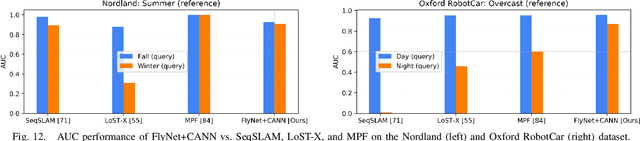
State-of-the-art algorithms for visual place recognition can be broadly split into two categories: computationally expensive deep-learning/image retrieval based techniques with minimal biological plausibility, and computationally cheap, biologically inspired models that yield poor performance in real-world environments. In this paper we present a new compact and high-performing system that bridges this divide for the first time. Our approach comprises two key components: FlyNet, a compact, sparse two-layer neural network inspired by fruit fly brain architectures, and a one-dimensional continuous attractor neural network (CANN). Our FlyNet+CANN network combines the compact pattern recognition capabilities of the FlyNet model with the powerful temporal filtering capabilities of an equally compact CANN, replicating entirely in a neural network implementation the functionality that yields high performance in algorithmic localization approaches like SeqSLAM. We evaluate our approach and compare it to three state-of-the-art methods on two benchmark real-world datasets with small viewpoint changes and extreme appearance variations including different times of day (afternoon to night) where it achieves an AUC performance of 87%, compared to 60% for Multi-Process Fusion, 46% for LoST-X and 1% for SeqSLAM, while being 6.5, 310, and 1.5 times faster respectively.
From Visual Place Recognition to Navigation: Learning Sample-Efficient Control Policies across Diverse Real World Environments
Oct 10, 2019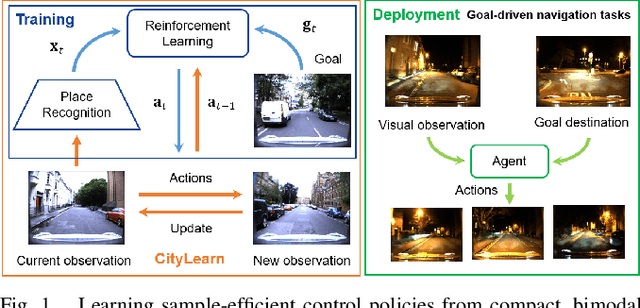

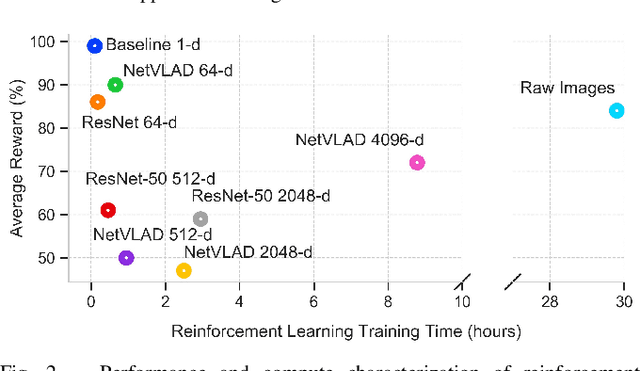

Visual navigation tasks in real world environments often require both self-motion and place recognition feedback. While deep reinforcement learning has shown success in solving these perception and decision-making problems in an end-to-end manner, these algorithms require large amounts of experience to learn navigation policies from high-dimensional inputs, which is generally impractical for real robots due to sample complexity. In this paper, we address these problems with two main contributions. We first leverage place recognition and deep learning techniques combined with goal destination feedback to generate compact, bimodal images representations that can then be used to effectively learn control policies at kilometer scale from a small amount of experience. Second, we present an interactive and realistic framework, called CityLearn, that enables for the first time the training of navigation algorithms across city-sized, real-world environments with extreme environmental changes. CityLearn features over 10 benchmark real-world datasets often used in place recognition research with more than 100 recorded traversals and across 60 cities around the world. We evaluate our approach in two CityLearn environments where our navigation policy is trained using a single traversal. Results show our method can be over 2 orders of magnitude faster than when using raw images and can also generalize across extreme visual changes including day to night and summer to winter transitions.