 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoVAE: A Trustworthy Self-Explainable Prototypical Variational Model
Oct 15, 2022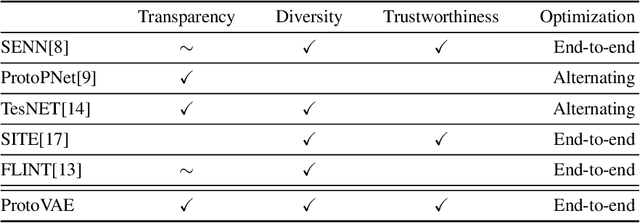
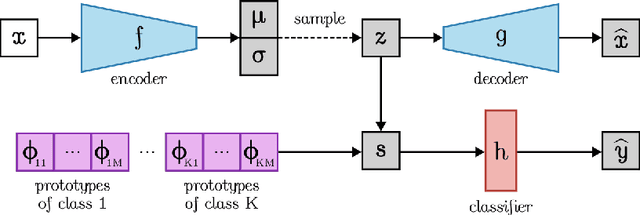
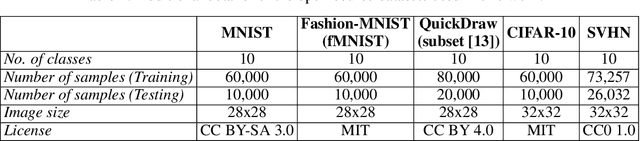
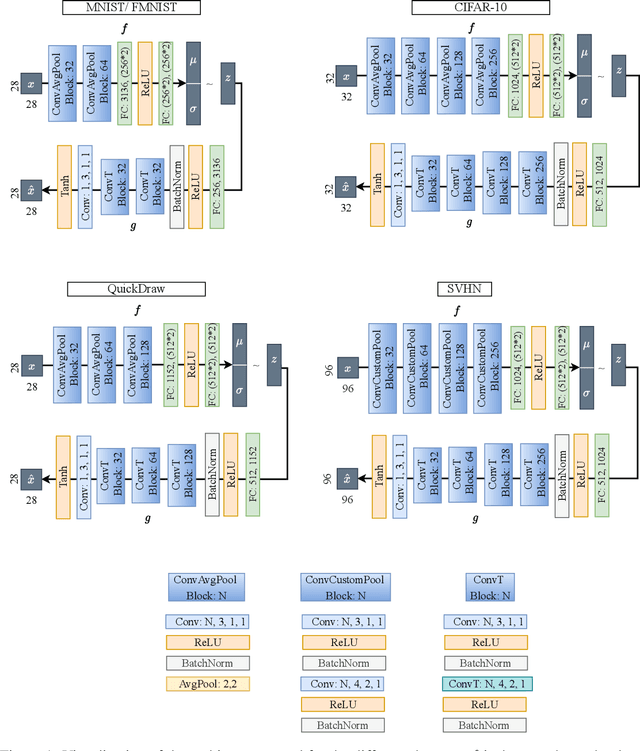
The need for interpretable models has fostered the development of self-explainable classifiers. Prior approaches are either based on multi-stage optimization schemes, impacting the predictive performance of the model, or produce explanations that are not transparent, trustworthy or do not capture the diversity of the data. To address these shortcomings, we propose ProtoVAE, a variational autoencoder-based framework that learns class-specific prototypes in an end-to-end manner and enforces trustworthiness and diversity by regularizing the representation space and introducing an orthonormality constraint. Finally, the model is designed to be transparent by directly incorporating the prototypes into the decision process. Extensive comparisons with previous self-explainable approaches demonstrate the superiority of ProtoVAE, highlighting its ability to generate trustworthy and diverse explanations, while not degrading predictive performance.
PASTA-GAN++: A Versatile Framework for High-Resolution Unpaired Virtual Try-on
Jul 27, 2022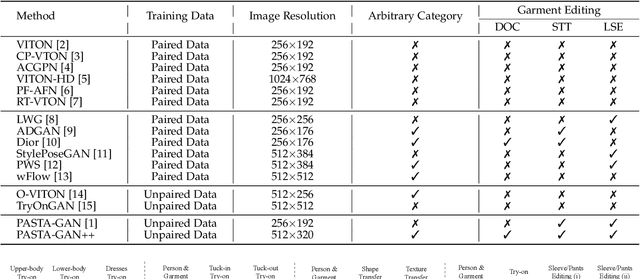

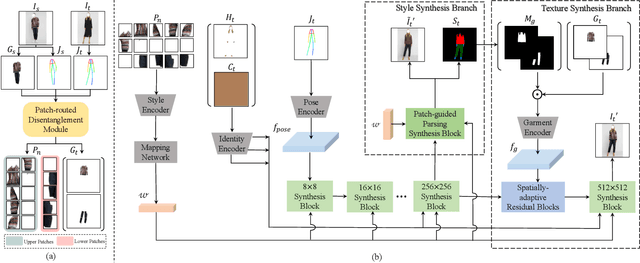

Image-based virtual try-on is one of the most promising applications of human-centric image generation due to its tremendous real-world potential. In this work, we take a step forwards to explore versatile virtual try-on solutions, which we argue should possess three main properties, namely, they should support unsupervised training, arbitrary garment categories, and controllable garment editing. To this end, we propose a characteristic-preserving end-to-end network, the PAtch-routed SpaTially-Adaptive GAN++ (PASTA-GAN++), to achieve a versatile system for high-resolution unpaired virtual try-on. Specifically, our PASTA-GAN++ consists of an innovative patch-routed disentanglement module to decouple the intact garment into normalized patches, which is capable of retaining garment style information while eliminating the garment spatial information, thus alleviating the overfitting issue during unsupervised training. Furthermore, PASTA-GAN++ introduces a patch-based garment representation and a patch-guided parsing synthesis block, allowing it to handle arbitrary garment categories and support local garment editing. Finally, to obtain try-on results with realistic texture details, PASTA-GAN++ incorporates a novel spatially-adaptive residual module to inject the coarse warped garment feature into the generator. Extensive experiments on our newly collected UnPaired virtual Try-on (UPT) dataset demonstrate the superiority of PASTA-GAN++ over existing SOTAs and its ability for controllable garment editing.
Learning Underrepresented Classes from Decentralized Partially Labeled Medical Images
Jun 30, 2022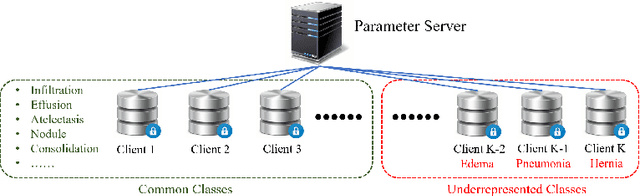
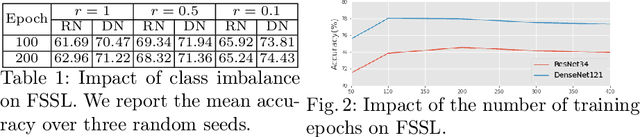
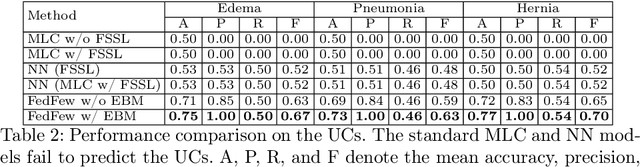

Using decentralized data for federated training is one promising emerging research direction for alleviating data scarcity in the medical domain. However, in contrast to large-scale fully labeled data commonly seen in general object recognition tasks, the local medical datasets are more likely to only have images annotated for a subset of classes of interest due to high annotation costs. In this paper, we consider a practical yet under-explored problem, where underrepresented classes only have few labeled instances available and only exist in a few clients of the federated system. We show that standard federated learning approaches fail to learn robust multi-label classifiers with extreme class imbalance and address it by proposing a novel federated learning framework, FedFew. FedFew consists of three stages, where the first stage leverages federated self-supervised learning to learn class-agnostic representations. In the second stage, the decentralized partially labeled data are exploited to learn an energy-based multi-label classifier for the common classes. Finally, the underrepresented classes are detected based on the energy and a prototype-based nearest-neighbor model is proposed for few-shot matching. We evaluate FedFew on multi-label thoracic disease classification tasks and demonstrate that it outperforms the federated baselines by a large margin.
The Kernelized Taylor Diagram
May 18, 2022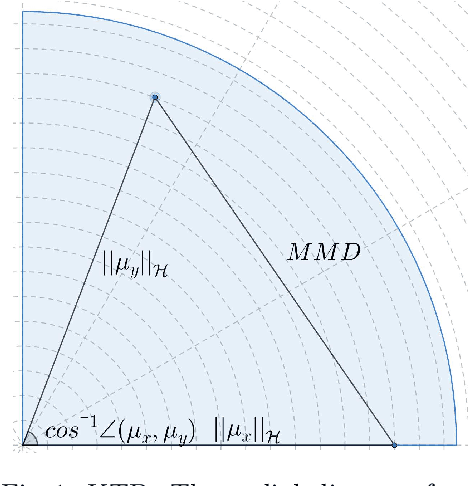
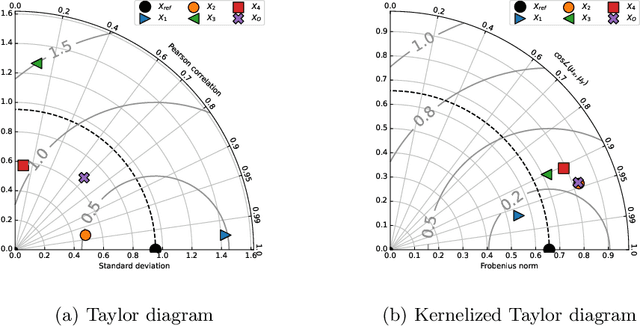
This paper presents the kernelized Taylor diagram, a graphical framework for visualizing similarities between data populations. The kernelized Taylor diagram builds on the widely used Taylor diagram, which is used to visualize similarities between populations. However, the Taylor diagram has several limitations such as not capturing non-linear relationships and sensitivity to outliers. To address such limitations, we propose the kernelized Taylor diagram. Our proposed kernelized Taylor diagram is capable of visualizing similarities between populations with minimal assumptions of the data distributions. The kernelized Taylor diagram relates the maximum mean discrepancy and the kernel mean embedding in a single diagram, a construction that, to the best of our knowledge, have not been devised prior to this work. We believe that the kernelized Taylor diagram can be a valuable tool in data visualization.
Automatic Identification of Chemical Moieties
Mar 30, 2022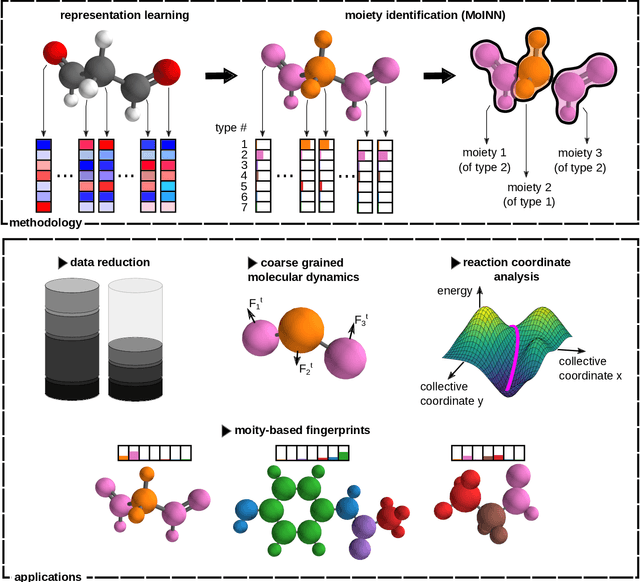
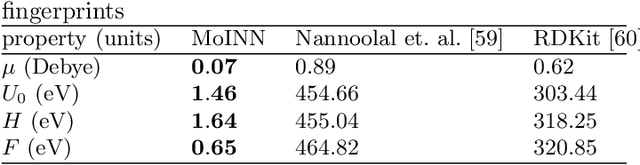
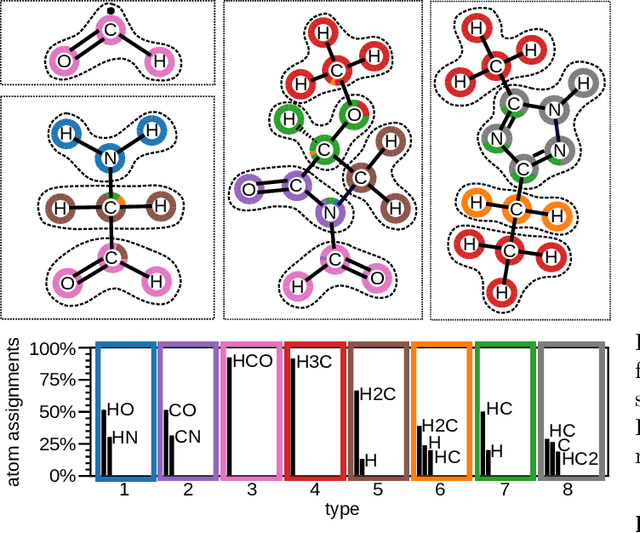
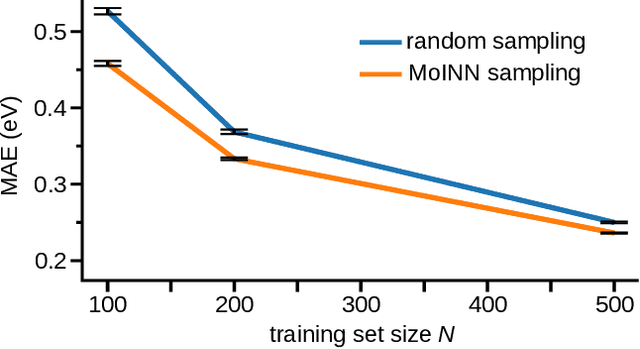
In recent years, the prediction of quantum mechanical observables with machine learning methods has become increasingly popular. Message-passing neural networks (MPNNs) solve this task by constructing atomic representations, from which the properties of interest are predicted. Here, we introduce a method to automatically identify chemical moieties (molecular building blocks) from such representations, enabling a variety of applications beyond property prediction, which otherwise rely on expert knowledge. The required representation can either be provided by a pretrained MPNN, or learned from scratch using only structural information. Beyond the data-driven design of molecular fingerprints, the versatility of our approach is demonstrated by enabling the selection of representative entries in chemical databases, the automatic construction of coarse-grained force fields, as well as the identification of reaction coordinates.
Mixing Up Contrastive Learning: Self-Supervised Representation Learning for Time Series
Mar 17, 2022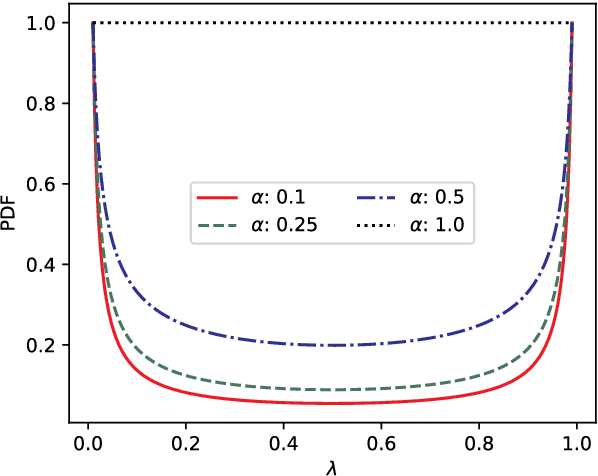
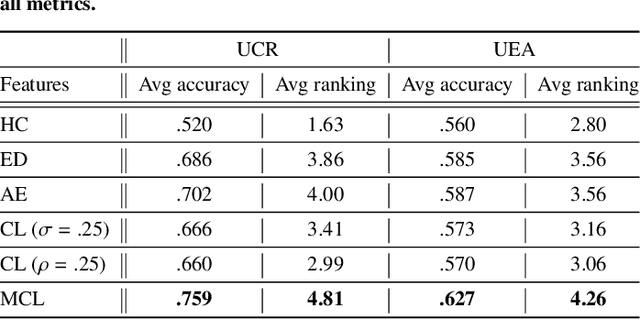
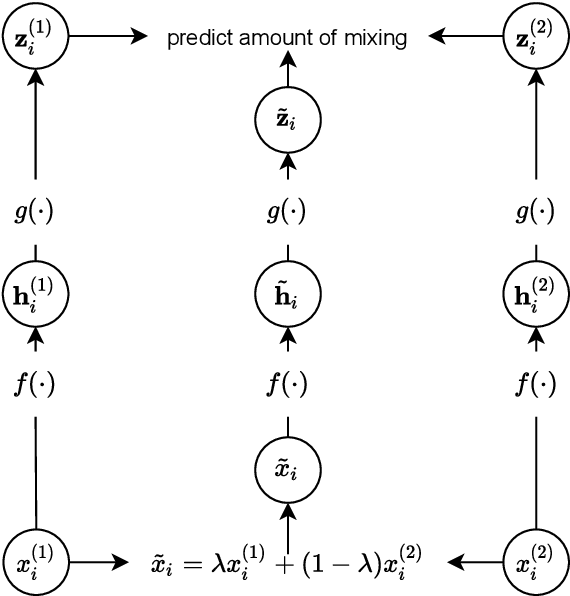
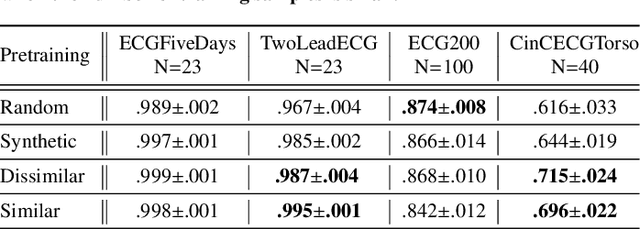
The lack of labeled data is a key challenge for learning useful representation from time series data. However, an unsupervised representation framework that is capable of producing high quality representations could be of great value. It is key to enabling transfer learning, which is especially beneficial for medical applications, where there is an abundance of data but labeling is costly and time consuming. We propose an unsupervised contrastive learning framework that is motivated from the perspective of label smoothing. The proposed approach uses a novel contrastive loss that naturally exploits a data augmentation scheme in which new samples are generated by mixing two data samples with a mixing component. The task in the proposed framework is to predict the mixing component, which is utilized as soft targets in the loss function. Experiments demonstrate the framework's superior performance compared to other representation learning approaches on both univariate and multivariate time series and illustrate its benefits for transfer learning for clinical time series.
Anomaly Detection-Inspired Few-Shot Medical Image Segmentation Through Self-Supervision With Supervoxels
Mar 03, 2022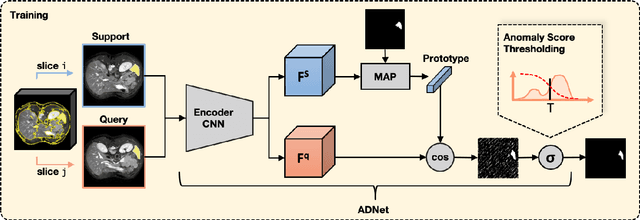

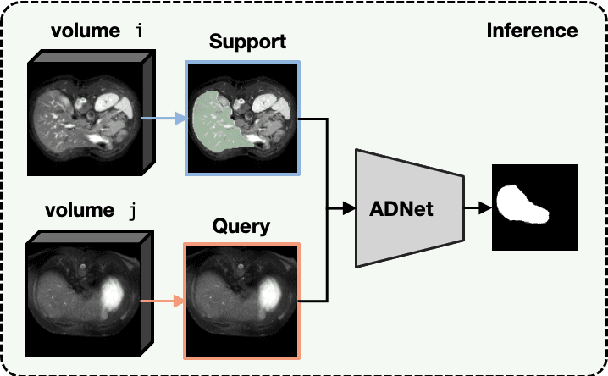

Recent work has shown that label-efficient few-shot learning through self-supervision can achieve promising medical image segmentation results. However, few-shot segmentation models typically rely on prototype representations of the semantic classes, resulting in a loss of local information that can degrade performance. This is particularly problematic for the typically large and highly heterogeneous background class in medical image segmentation problems. Previous works have attempted to address this issue by learning additional prototypes for each class, but since the prototypes are based on a limited number of slices, we argue that this ad-hoc solution is insufficient to capture the background properties. Motivated by this, and the observation that the foreground class (e.g., one organ) is relatively homogeneous, we propose a novel anomaly detection-inspired approach to few-shot medical image segmentation in which we refrain from modeling the background explicitly. Instead, we rely solely on a single foreground prototype to compute anomaly scores for all query pixels. The segmentation is then performed by thresholding these anomaly scores using a learned threshold. Assisted by a novel self-supervision task that exploits the 3D structure of medical images through supervoxels, our proposed anomaly detection-inspired few-shot medical image segmentation model outperforms previous state-of-the-art approaches on two representative MRI datasets for the tasks of abdominal organ segmentation and cardiac segmentation.
Demonstrating The Risk of Imbalanced Datasets in Chest X-ray Image-based Diagnostics by Prototypical Relevance Propagation
Jan 10, 2022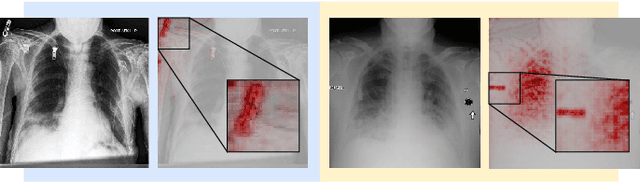

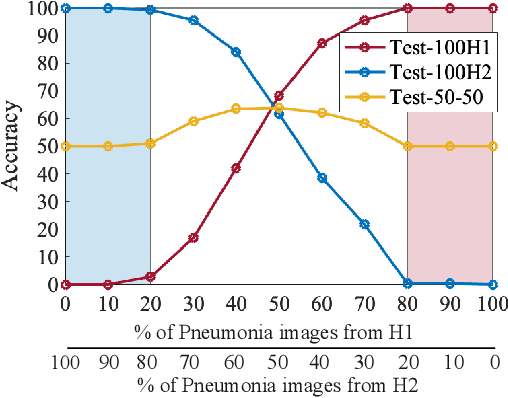
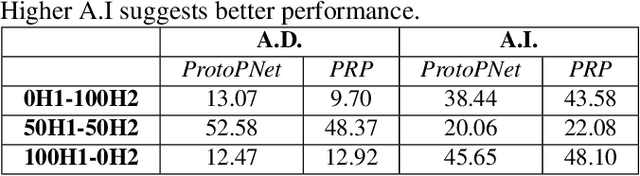
The recent trend of integrating multi-source Chest X-Ray datasets to improve automated diagnostics raises concerns that models learn to exploit source-specific correlations to improve performance by recognizing the source domain of an image rather than the medical pathology. We hypothesize that this effect is enforced by and leverages label-imbalance across the source domains, i.e, prevalence of a disease corresponding to a source. Therefore, in this work, we perform a thorough study of the effect of label-imbalance in multi-source training for the task of pneumonia detection on the widely used ChestX-ray14 and CheXpert datasets. The results highlight and stress the importance of using more faithful and transparent self-explaining models for automated diagnosis, thus enabling the inherent detection of spurious learning. They further illustrate that this undesirable effect of learning spurious correlations can be reduced considerably when ensuring label-balanced source domain datasets.
Towards Scalable Unpaired Virtual Try-On via Patch-Routed Spatially-Adaptive GAN
Nov 20, 2021
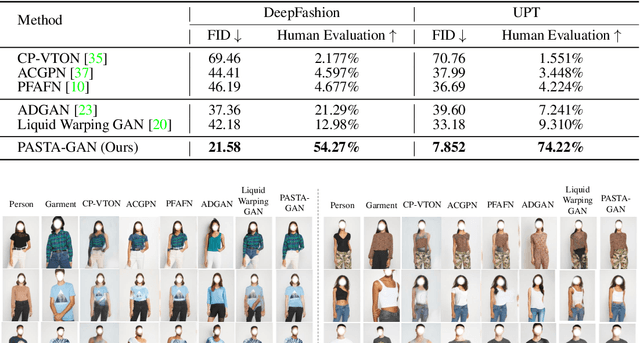
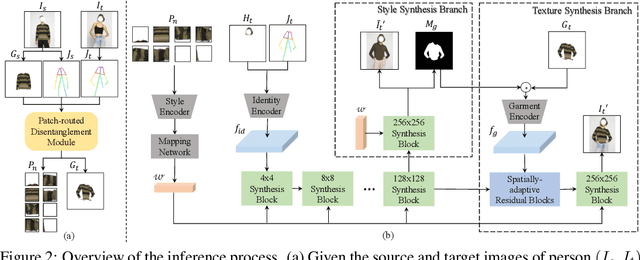

Image-based virtual try-on is one of the most promising applications of human-centric image generation due to its tremendous real-world potential. Yet, as most try-on approaches fit in-shop garments onto a target person, they require the laborious and restrictive construction of a paired training dataset, severely limiting their scalability. While a few recent works attempt to transfer garments directly from one person to another, alleviating the need to collect paired datasets, their performance is impacted by the lack of paired (supervised) information. In particular, disentangling style and spatial information of the garment becomes a challenge, which existing methods either address by requiring auxiliary data or extensive online optimization procedures, thereby still inhibiting their scalability. To achieve a \emph{scalable} virtual try-on system that can transfer arbitrary garments between a source and a target person in an unsupervised manner, we thus propose a texture-preserving end-to-end network, the PAtch-routed SpaTially-Adaptive GAN (PASTA-GAN), that facilitates real-world unpaired virtual try-on. Specifically, to disentangle the style and spatial information of each garment, PASTA-GAN consists of an innovative patch-routed disentanglement module for successfully retaining garment texture and shape characteristics. Guided by the source person keypoints, the patch-routed disentanglement module first decouples garments into normalized patches, thus eliminating the inherent spatial information of the garment, and then reconstructs the normalized patches to the warped garment complying with the target person pose. Given the warped garment, PASTA-GAN further introduces novel spatially-adaptive residual blocks that guide the generator to synthesize more realistic garment details.
Multi-modal land cover mapping of remote sensing images using pyramid attention and gated fusion networks
Nov 06, 2021

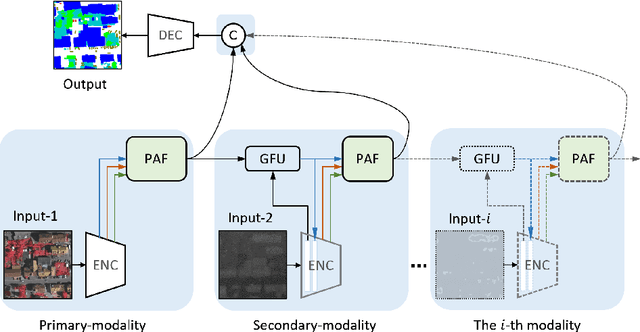
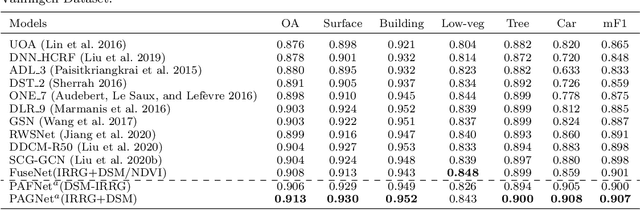
Multi-modality data is becoming readily available in remote sensing (RS) and can provide complementary information about the Earth's surface. Effective fusion of multi-modal information is thus important for various applications in RS, but also very challenging due to large domain differences, noise, and redundancies. There is a lack of effective and scalable fusion techniques for bridging multiple modality encoders and fully exploiting complementary information. To this end, we propose a new multi-modality network (MultiModNet) for land cover mapping of multi-modal remote sensing data based on a novel pyramid attention fusion (PAF) module and a gated fusion unit (GFU). The PAF module is designed to efficiently obtain rich fine-grained contextual representations from each modality with a built-in cross-level and cross-view attention fusion mechanism, and the GFU module utilizes a novel gating mechanism for early merging of features, thereby diminishing hidden redundancies and noise. This enables supplementary modalities to effectively extract the most valuable and complementary information for late feature fusion. Extensive experiments on two representative RS benchmark datasets demonstrate the effectiveness, robustness, and superiority of the MultiModNet for multi-modal land cover classification.