 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages
Mar 10, 2020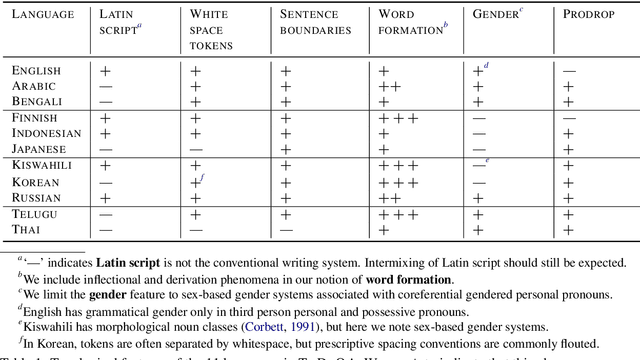

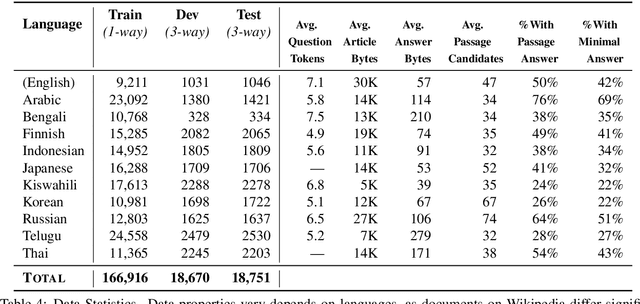
Confidently making progress on multilingual modeling requires challenging, trustworthy evaluations. We present TyDi QA---a question answering dataset covering 11 typologically diverse languages with 204K question-answer pairs. The languages of TyDi QA are diverse with regard to their typology---the set of linguistic features each language expresses---such that we expect models performing well on this set to generalize across a large number of the world's languages. We present a quantitative analysis of the data quality and example-level qualitative linguistic analyses of observed language phenomena that would not be found in English-only corpora. To provide a realistic information-seeking task and avoid priming effects, questions are written by people who want to know the answer, but don't know the answer yet, and the data is collected directly in each language without the use of translation.
Fusion of Detected Objects in Text for Visual Question Answering
Aug 14, 2019

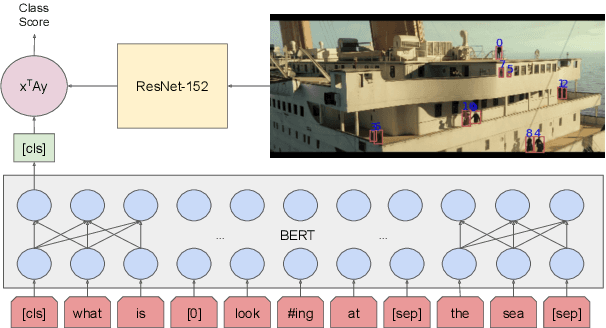
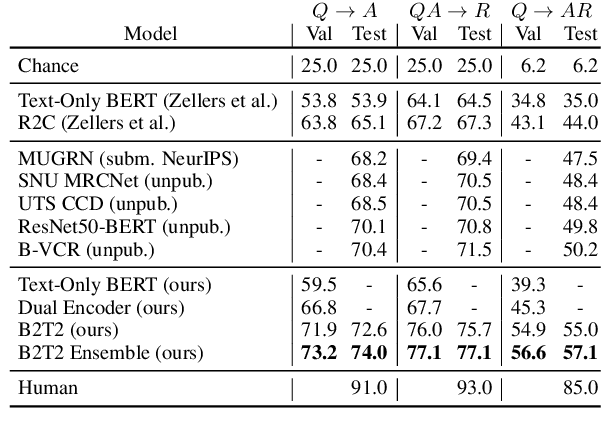
To advance models of multimodal context, we introduce a simple yet powerful neural architecture for data that combines vision and natural language. The "Bounding Boxes in Text Transformer" (B2T2) also leverages referential information binding words to portions of the image in a single unified architecture. B2T2 is highly effective on the Visual Commonsense Reasoning benchmark (visualcommonsense.com), achieving a new state-of-the-art with a 25% relative reduction in error rate compared to published baselines and obtaining the best performance to date on the public leaderboard (as of May 13, 2019). A detailed ablation analysis shows that the early integration of the visual features into the text analysis is key to the effectiveness of the new architecture.
Synthetic QA Corpora Generation with Roundtrip Consistency
Jun 12, 2019
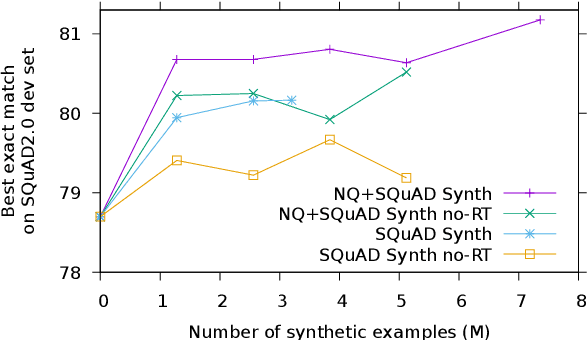
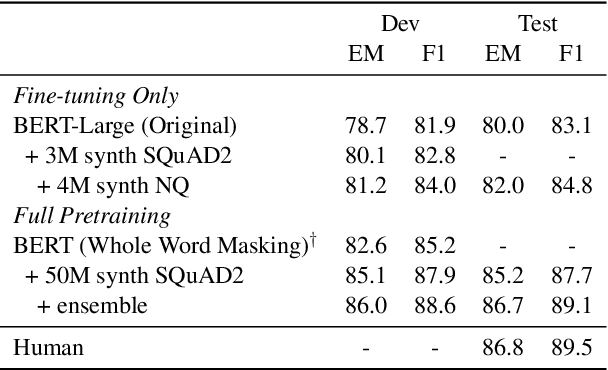
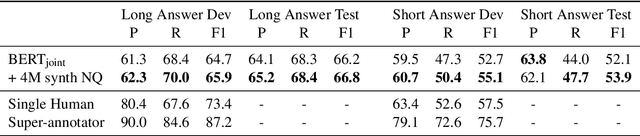
We introduce a novel method of generating synthetic question answering corpora by combining models of question generation and answer extraction, and by filtering the results to ensure roundtrip consistency. By pretraining on the resulting corpora we obtain significant improvements on SQuAD2 and NQ, establishing a new state-of-the-art on the latter. Our synthetic data generation models, for both question generation and answer extraction, can be fully reproduced by finetuning a publicly available BERT model on the extractive subsets of SQuAD2 and NQ. We also describe a more powerful variant that does full sequence-to-sequence pretraining for question generation, obtaining exact match and F1 at less than 0.1% and 0.4% from human performance on SQuAD2.
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
May 24, 2019

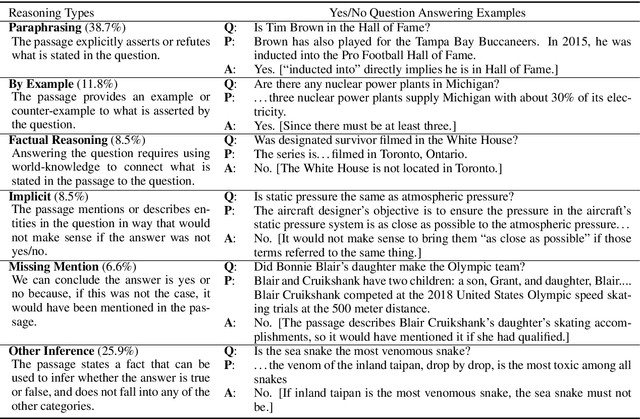
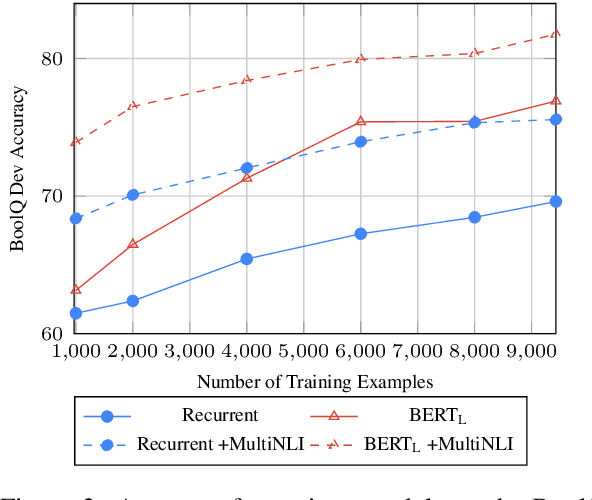
In this paper we study yes/no questions that are naturally occurring --- meaning that they are generated in unprompted and unconstrained settings. We build a reading comprehension dataset, BoolQ, of such questions, and show that they are unexpectedly challenging. They often query for complex, non-factoid information, and require difficult entailment-like inference to solve. We also explore the effectiveness of a range of transfer learning baselines. We find that transferring from entailment data is more effective than transferring from paraphrase or extractive QA data, and that it, surprisingly, continues to be very beneficial even when starting from massive pre-trained language models such as BERT. Our best method trains BERT on MultiNLI and then re-trains it on our train set. It achieves 80.4% accuracy compared to 90% accuracy of human annotators (and 62% majority-baseline), leaving a significant gap for future work.
Low-Resource Syntactic Transfer with Unsupervised Source Reordering
Mar 13, 2019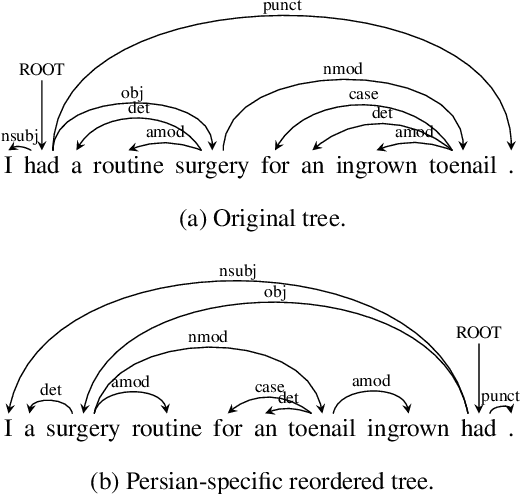
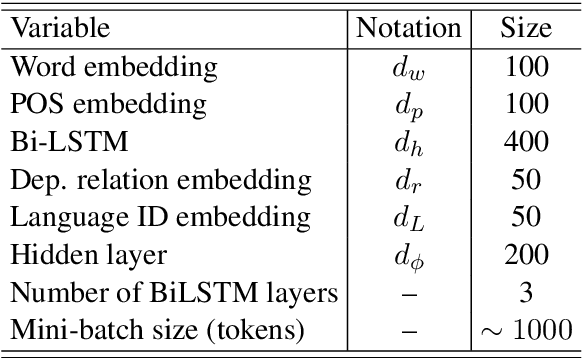
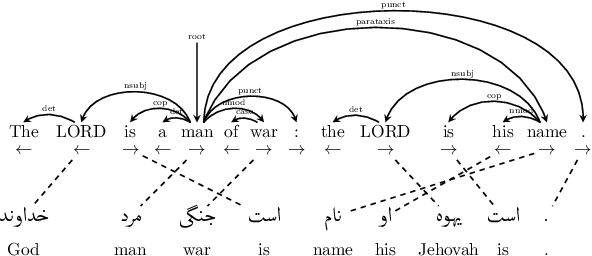
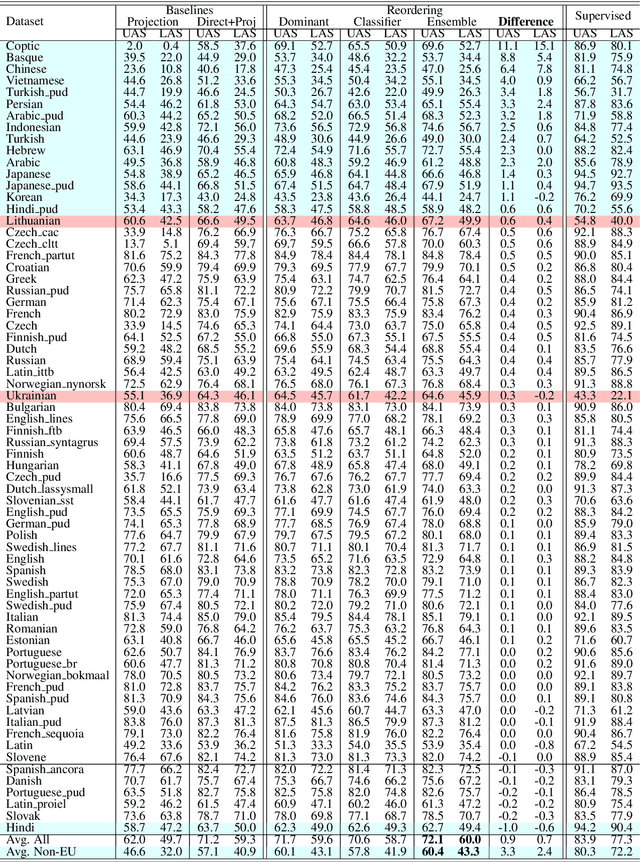
We describe a cross-lingual transfer method for dependency parsing that takes into account the problem of word order differences between source and target languages. Our model only relies on the Bible, a considerably smaller parallel data than the commonly used parallel data in transfer methods. We use the concatenation of projected trees from the Bible corpus, and the gold-standard treebanks in multiple source languages along with cross-lingual word representations. We demonstrate that reordering the source treebanks before training on them for a target language improves the accuracy of languages outside the European language family. Our experiments on 68 treebanks (38 languages) in the Universal Dependencies corpus achieve a high accuracy for all languages. Among them, our experiments on 16 treebanks of 12 non-European languages achieve an average UAS absolute improvement of 3.3% over a state-of-the-art method.
A BERT Baseline for the Natural Questions
Jan 24, 2019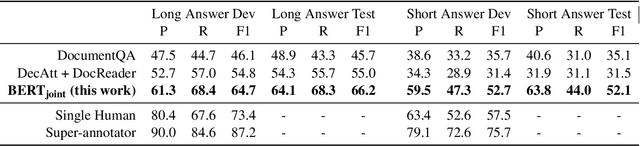
This technical note describes a new baseline for the Natural Questions. Our model is based on BERT and reduces the gap between the model F1 scores reported in the original dataset paper and the human upper bound by 30% and 50% relative for the long and short answer tasks respectively. This baseline has been submitted to the official NQ leaderboard at ai.google.com/research/NaturalQuestions and we plan to opensource the code for it in the near future.
Improving Span-based Question Answering Systems with Coarsely Labeled Data
Nov 05, 2018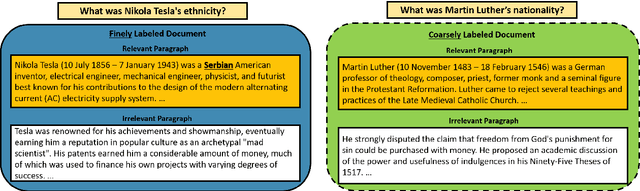
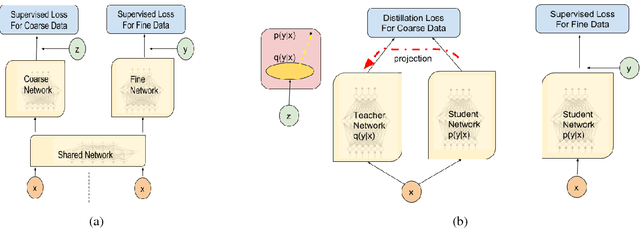
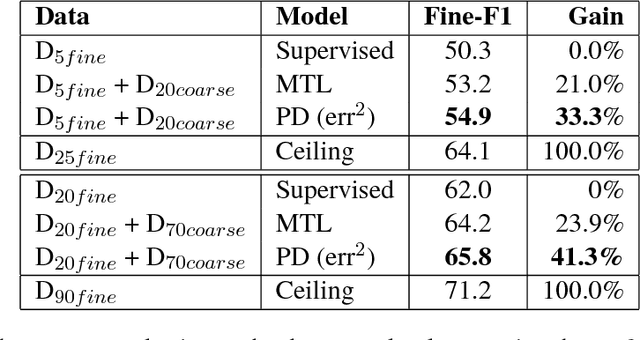
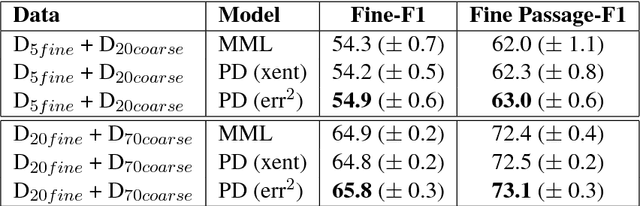
We study approaches to improve fine-grained short answer Question Answering models by integrating coarse-grained data annotated for paragraph-level relevance and show that coarsely annotated data can bring significant performance gains. Experiments demonstrate that the standard multi-task learning approach of sharing representations is not the most effective way to leverage coarse-grained annotations. Instead, we can explicitly model the latent fine-grained short answer variables and optimize the marginal log-likelihood directly or use a newly proposed \emph{posterior distillation} learning objective. Since these latent-variable methods have explicit access to the relationship between the fine and coarse tasks, they result in significantly larger improvements from coarse supervision.
Noise Contrastive Estimation and Negative Sampling for Conditional Models: Consistency and Statistical Efficiency
Sep 06, 2018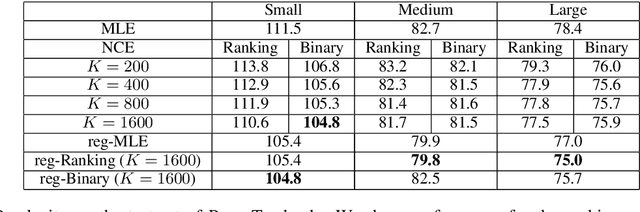
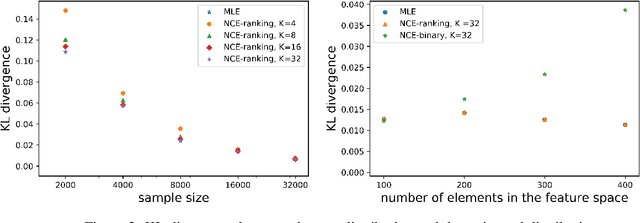
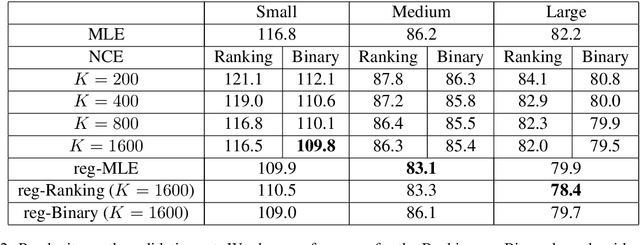
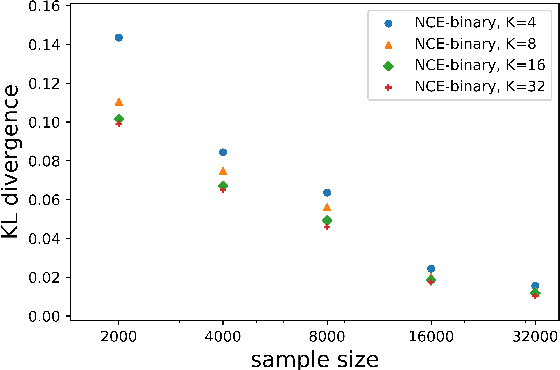
Noise Contrastive Estimation (NCE) is a powerful parameter estimation method for log-linear models, which avoids calculation of the partition function or its derivatives at each training step, a computationally demanding step in many cases. It is closely related to negative sampling methods, now widely used in NLP. This paper considers NCE-based estimation of conditional models. Conditional models are frequently encountered in practice; however there has not been a rigorous theoretical analysis of NCE in this setting, and we will argue there are subtle but important questions when generalizing NCE to the conditional case. In particular, we analyze two variants of NCE for conditional models: one based on a classification objective, the other based on a ranking objective. We show that the ranking-based variant of NCE gives consistent parameter estimates under weaker assumptions than the classification-based method; we analyze the statistical efficiency of the ranking-based and classification-based variants of NCE; finally we describe experiments on synthetic data and language modeling showing the effectiveness and trade-offs of both methods.
SyntaxNet Models for the CoNLL 2017 Shared Task
Mar 15, 2017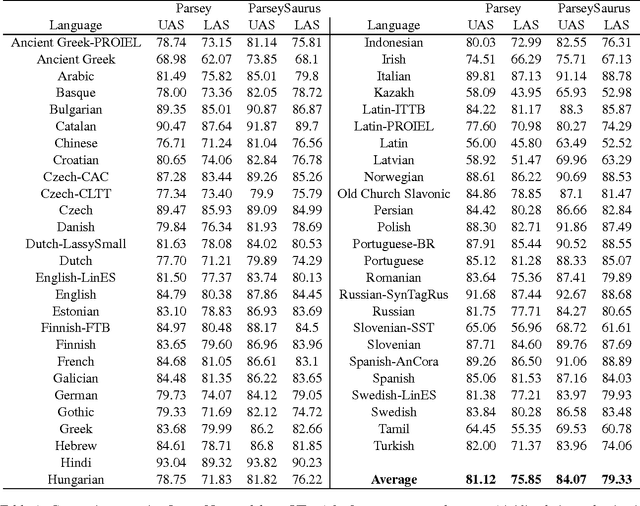
We describe a baseline dependency parsing system for the CoNLL2017 Shared Task. This system, which we call "ParseySaurus," uses the DRAGNN framework [Kong et al, 2017] to combine transition-based recurrent parsing and tagging with character-based word representations. On the v1.3 Universal Dependencies Treebanks, the new system outpeforms the publicly available, state-of-the-art "Parsey's Cousins" models by 3.47% absolute Labeled Accuracy Score (LAS) across 52 treebanks.
Cross-Lingual Syntactic Transfer with Limited Resources
Feb 04, 2017We describe a simple but effective method for cross-lingual syntactic transfer of dependency parsers, in the scenario where a large amount of translation data is not available. The method makes use of three steps: 1) a method for deriving cross-lingual word clusters, which can then be used in a multilingual parser; 2) a method for transferring lexical information from a target language to source language treebanks; 3) a method for integrating these steps with the density-driven annotation projection method of Rasooli and Collins (2015). Experiments show improvements over the state-of-the-art in several languages used in previous work, in a setting where the only source of translation data is the Bible, a considerably smaller corpus than the Europarl corpus used in previous work. Results using the Europarl corpus as a source of translation data show additional improvements over the results of Rasooli and Collins (2015). We conclude with results on 38 datasets from the Universal Dependencies corpora.