 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUseful Policy Invariant Shaping from Arbitrary Advice
Nov 02, 2020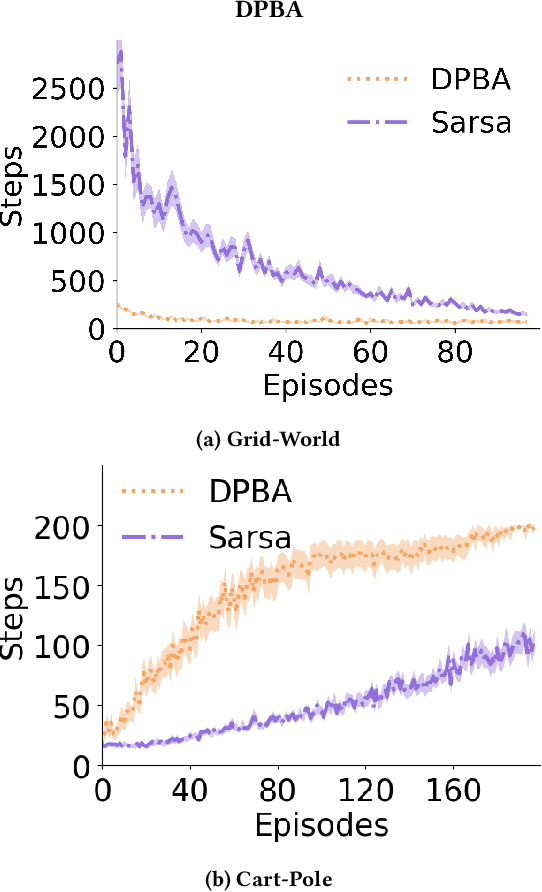

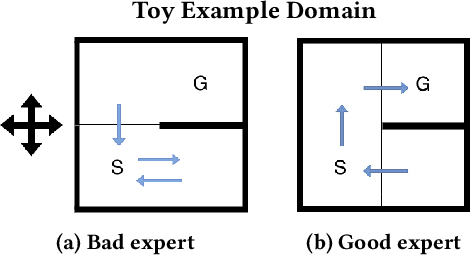

Reinforcement learning is a powerful learning paradigm in which agents can learn to maximize sparse and delayed reward signals. Although RL has had many impressive successes in complex domains, learning can take hours, days, or even years of training data. A major challenge of contemporary RL research is to discover how to learn with less data. Previous work has shown that domain information can be successfully used to shape the reward; by adding additional reward information, the agent can learn with much less data. Furthermore, if the reward is constructed from a potential function, the optimal policy is guaranteed to be unaltered. While such potential-based reward shaping (PBRS) holds promise, it is limited by the need for a well-defined potential function. Ideally, we would like to be able to take arbitrary advice from a human or other agent and improve performance without affecting the optimal policy. The recently introduced dynamic potential based advice (DPBA) method tackles this challenge by admitting arbitrary advice from a human or other agent and improves performance without affecting the optimal policy. The main contribution of this paper is to expose, theoretically and empirically, a flaw in DPBA. Alternatively, to achieve the ideal goals, we present a simple method called policy invariant explicit shaping (PIES) and show theoretically and empirically that PIES succeeds where DPBA fails.
The Advantage Regret-Matching Actor-Critic
Aug 27, 2020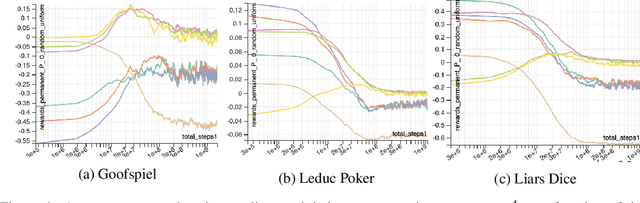
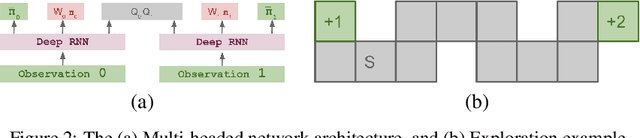
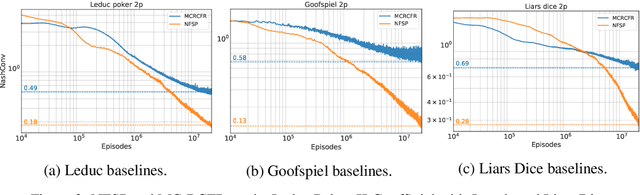
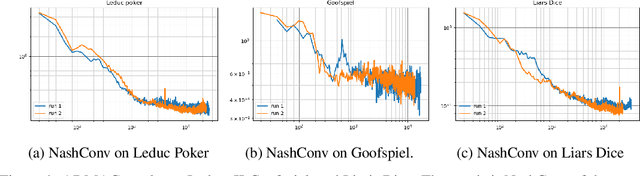
Regret minimization has played a key role in online learning, equilibrium computation in games, and reinforcement learning (RL). In this paper, we describe a general model-free RL method for no-regret learning based on repeated reconsideration of past behavior. We propose a model-free RL algorithm, the AdvantageRegret-Matching Actor-Critic (ARMAC): rather than saving past state-action data, ARMAC saves a buffer of past policies, replaying through them to reconstruct hindsight assessments of past behavior. These retrospective value estimates are used to predict conditional advantages which, combined with regret matching, produces a new policy. In particular, ARMAC learns from sampled trajectories in a centralized training setting, without requiring the application of importance sampling commonly used in Monte Carlo counterfactual regret (CFR) minimization; hence, it does not suffer from excessive variance in large environments. In the single-agent setting, ARMAC shows an interesting form of exploration by keeping past policies intact. In the multiagent setting, ARMAC in self-play approaches Nash equilibria on some partially-observable zero-sum benchmarks. We provide exploitability estimates in the significantly larger game of betting-abstracted no-limit Texas Hold'em.
Marginal Utility for Planning in Continuous or Large Discrete Action Spaces
Jun 17, 2020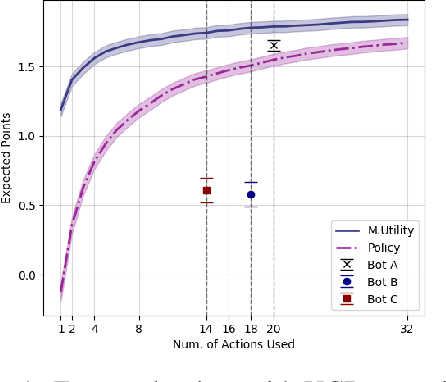
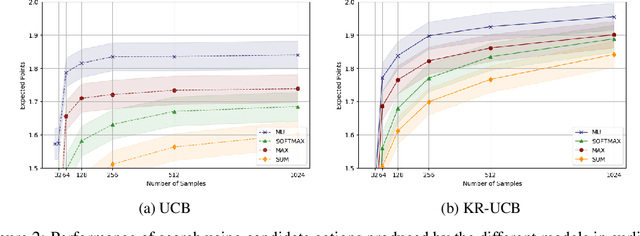
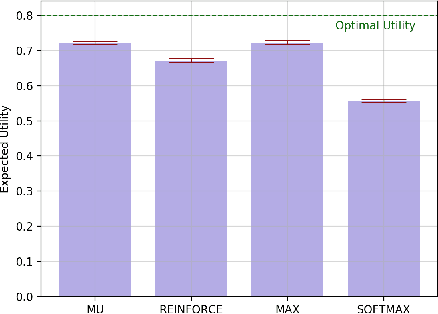
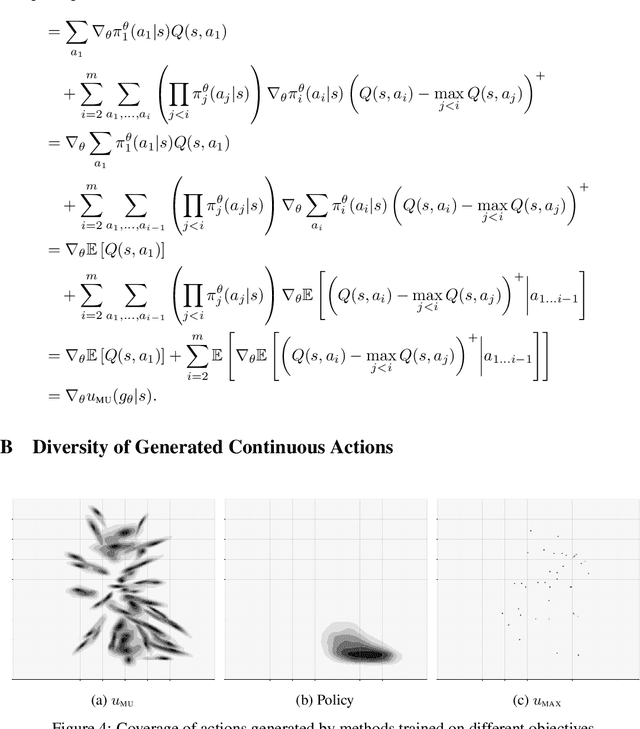
Sample-based planning is a powerful family of algorithms for generating intelligent behavior from a model of the environment. Generating good candidate actions is critical to the success of sample-based planners, particularly in continuous or large action spaces. Typically, candidate action generation exhausts the action space, uses domain knowledge, or more recently, involves learning a stochastic policy to provide such search guidance. In this paper we explore explicitly learning a candidate action generator by optimizing a novel objective, marginal utility. The marginal utility of an action generator measures the increase in value of an action over previously generated actions. We validate our approach in both curling, a challenging stochastic domain with continuous state and action spaces, and a location game with a discrete but large action space. We show that a generator trained with the marginal utility objective outperforms hand-coded schemes built on substantial domain knowledge, trained stochastic policies, and other natural objectives for generating actions for sampled-based planners.
Sample-Efficient Model-based Actor-Critic for an Interactive Dialogue Task
Apr 28, 2020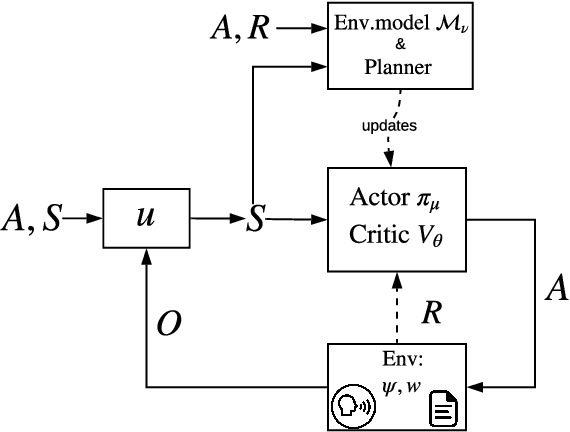
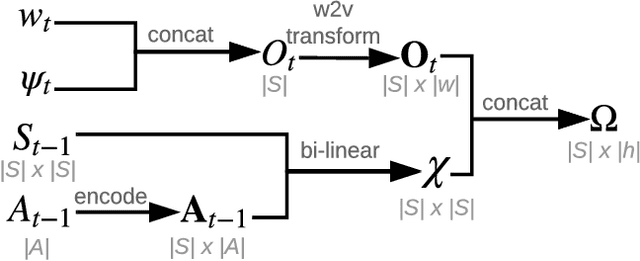
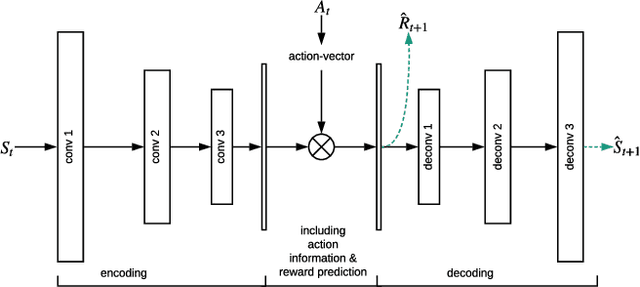
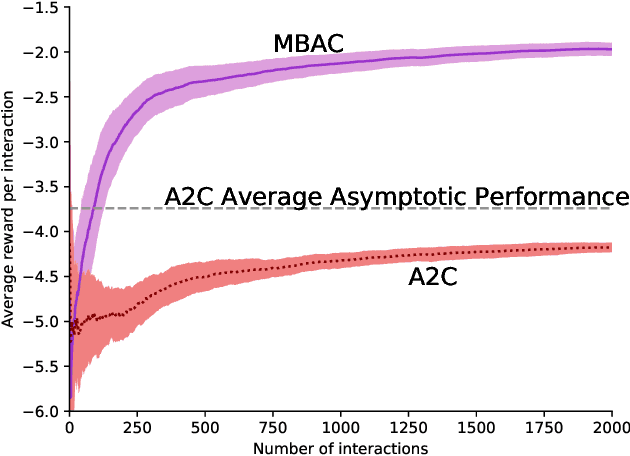
Human-computer interactive systems that rely on machine learning are becoming paramount to the lives of millions of people who use digital assistants on a daily basis. Yet, further advances are limited by the availability of data and the cost of acquiring new samples. One way to address this problem is by improving the sample efficiency of current approaches. As a solution path, we present a model-based reinforcement learning algorithm for an interactive dialogue task. We build on commonly used actor-critic methods, adding an environment model and planner that augments a learning agent to learn the model of the environment dynamics. Our results show that, on a simulation that mimics the interactive task, our algorithm requires 70 times fewer samples, compared to the baseline of commonly used model-free algorithm, and demonstrates 2~times better performance asymptotically. Moreover, we introduce a novel contribution of computing a soft planner policy and further updating a model-free policy yielding a less computationally expensive model-free agent as good as the model-based one. This model-based architecture serves as a foundation that can be extended to other human-computer interactive tasks allowing further advances in this direction.
Approximate exploitability: Learning a best response in large games
Apr 20, 2020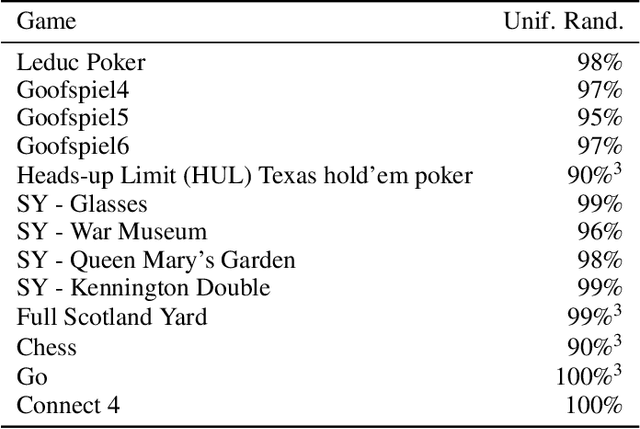
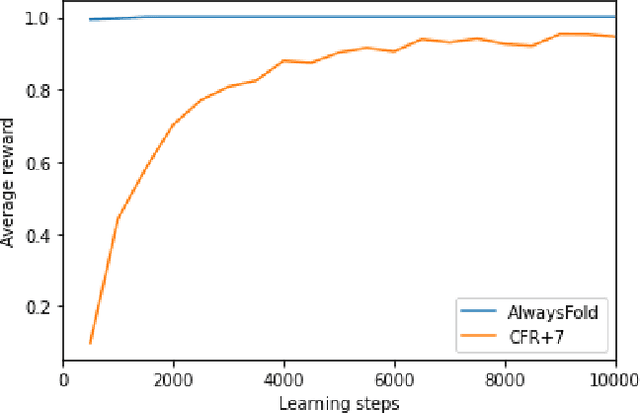

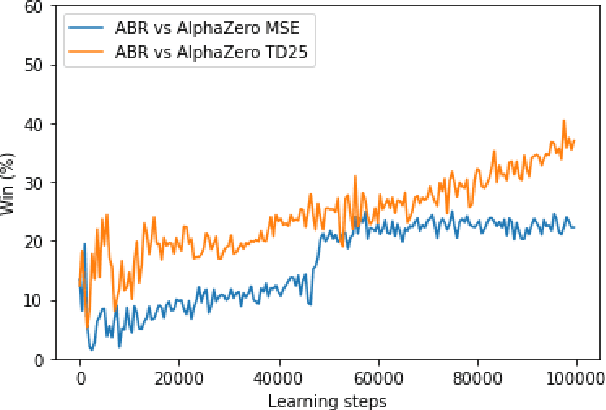
A common metric in games of imperfect information is exploitability, i.e. the performance of a policy against the worst-case opponent. This metric has many nice properties, but is intractable to compute in large games as it requires a full search of the game tree to calculate a best response to the given policy. We introduce a new metric, approximate exploitability, that calculates an analogous metric to exploitability using an approximate best response. This method scales to large games with tractable belief spaces. We focus only on the two-player, zero-sum case. Additionally, we provide empirical results for a specific instance of the method, demonstrating that it can effectively exploit agents in large games. We demonstrate that our method converges to exploitability in the tabular setting and the function approximation setting for small games, and demonstrate that it can consistently find exploits for weak policies in large games, showing results on Chess, Go, Heads-up No Limit Texas Hold'em, and other games.
Alternative Function Approximation Parameterizations for Solving Games: An Analysis of $f$-Regression Counterfactual Regret Minimization
Dec 06, 2019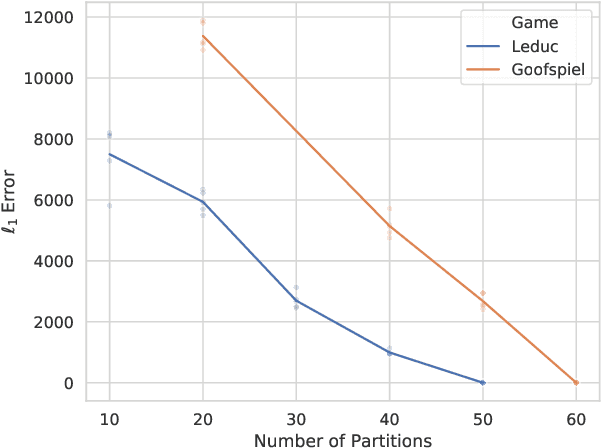
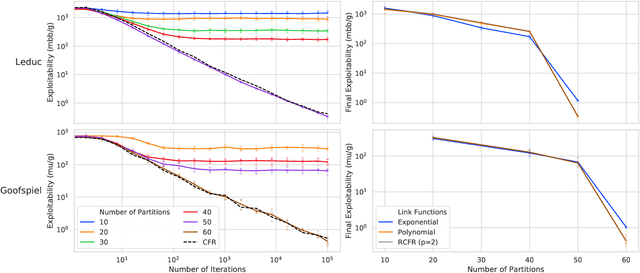
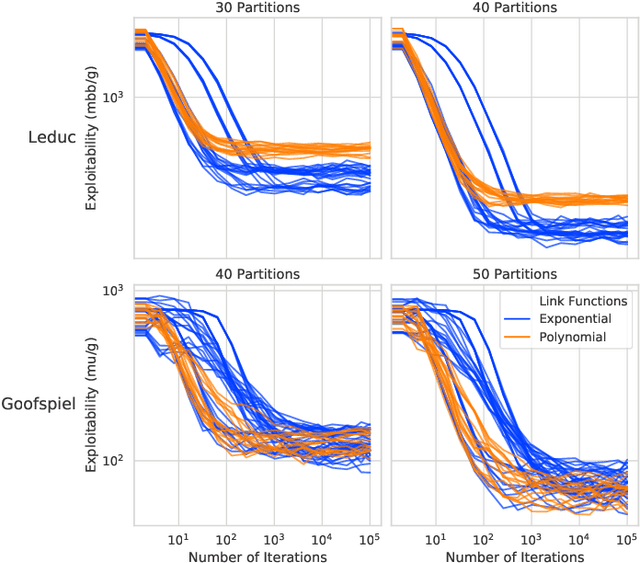
Function approximation is a powerful approach for structuring large decision problems that has facilitated great achievements in the areas of reinforcement learning and game playing. Regression counterfactual regret minimization (RCFR) is a flexible and simple algorithm for approximately solving imperfect information games with policies parameterized by a normalized rectified linear unit (ReLU). In contrast, the more conventional softmax parameterization is standard in the field of reinforcement learning and has a regret bound with a better dependence on the number of actions in the tabular case. We derive approximation error-aware regret bounds for $(\Phi, f)$-regret matching, which applies to a general class of link functions and regret objectives. These bounds recover a tighter bound for RCFR and provides a theoretical justification for RCFR implementations with alternative policy parameterizations ($f$-RCFR), including softmax. We provide exploitability bounds for $f$-RCFR with the polynomial and exponential link functions in zero-sum imperfect information games, and examine empirically how the link function interacts with the severity of the approximation to determine exploitability performance in practice. Although a ReLU parameterized policy is typically the best choice, a softmax parameterization can perform as well or better in settings that require aggressive approximation.
Low-Variance and Zero-Variance Baselines for Extensive-Form Games
Jul 22, 2019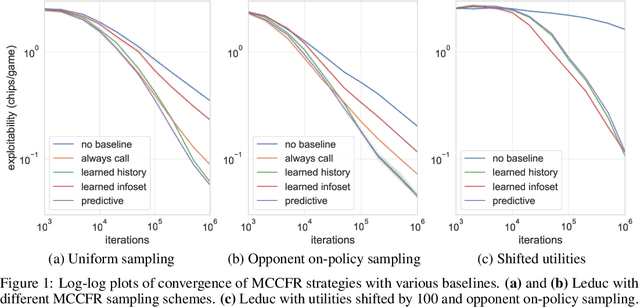
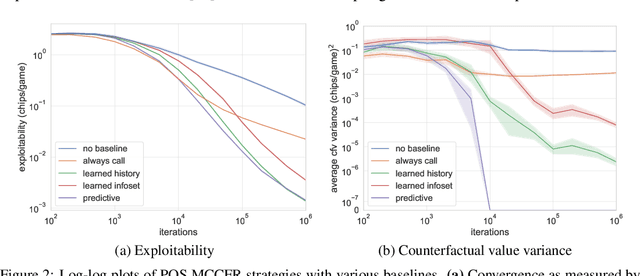
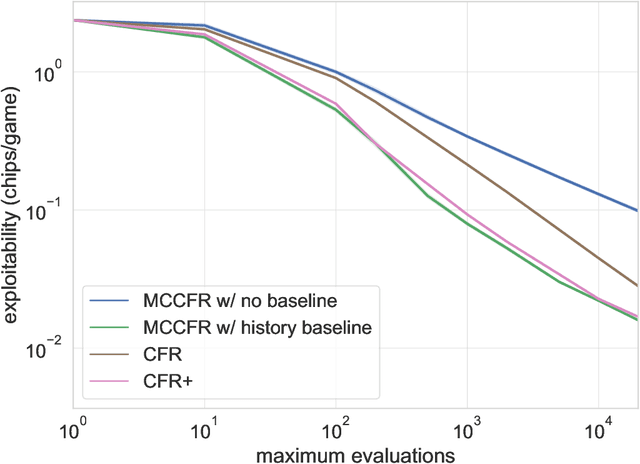
Extensive-form games (EFGs) are a common model of multi-agent interactions with imperfect information. State-of-the-art algorithms for solving these games typically perform full walks of the game tree that can prove prohibitively slow in large games. Alternatively, sampling-based methods such as Monte Carlo Counterfactual Regret Minimization walk one or more trajectories through the tree, touching only a fraction of the nodes on each iteration, at the expense of requiring more iterations to converge due to the variance of sampled values. In this paper, we extend recent work that uses baseline estimates to reduce this variance. We introduce a framework of baseline-corrected values in EFGs that generalizes the previous work. Within our framework, we propose new baseline functions that result in significantly reduced variance compared to existing techniques. We show that one particular choice of such a function --- predictive baseline --- is provably optimal under certain sampling schemes. This allows for efficient computation of zero-variance value estimates even along sampled trajectories.
Rethinking Formal Models of Partially Observable Multiagent Decision Making
Jun 26, 2019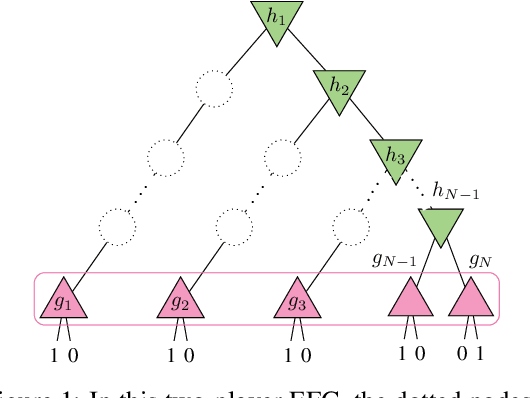
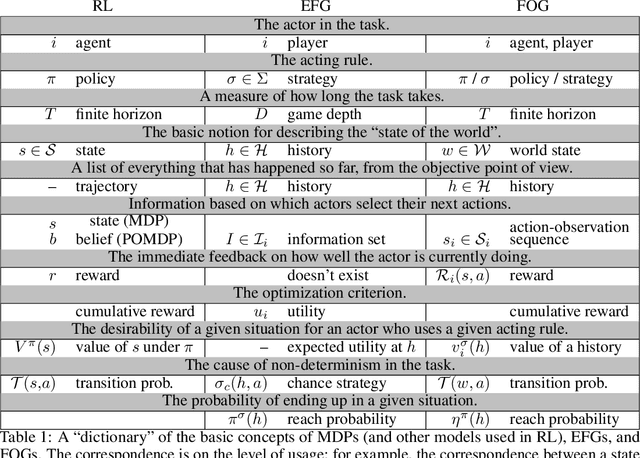
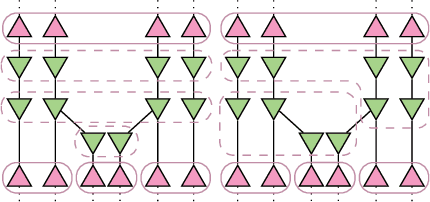
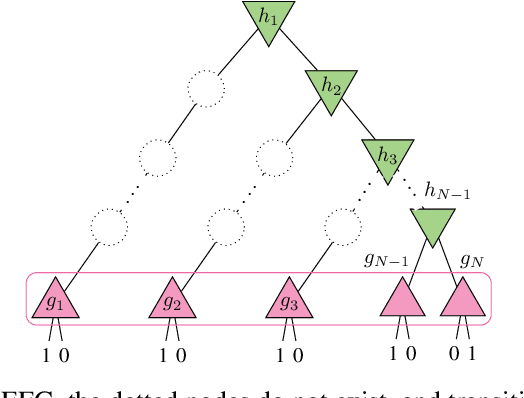
Multiagent decision-making problems in partially observable environments are usually modeled as either extensive-form games (EFGs) within the game theory community or partially observable stochastic games (POSGs) within the reinforcement learning community. While most practical problems can be modeled in both formalisms, the communities using these models are mostly distinct with little sharing of ideas or advances. The last decade has seen dramatic progress in algorithms for EFGs, mainly driven by the challenge problem of poker. We have seen computational techniques achieving super-human performance, some variants of poker are essentially solved, and there are now sound local search algorithms which were previously thought impossible. While the advances have garnered attention, the fundamental advances are not yet understood outside the EFG community. This can be largely explained by the starkly different formalisms between the game theory and reinforcement learning communities and, further, by the unsuitability of the original EFG formalism to make the ideas simple and clear. This paper aims to address these hindrances, by advocating a new unifying formalism, a variant of POSGs, which we call Factored-Observation Games (FOGs). We prove that any timeable perfect-recall EFG can be efficiently modeled as a FOG as well as relating FOGs to other existing formalisms. Additionally, a FOG explicitly identifies the public and private components of observations, which is fundamental to the recent EFG breakthroughs. We conclude by presenting the two building-blocks of these breakthroughs --- counterfactual regret minimization and public state decomposition --- in the new formalism, illustrating our goal of a simpler path for sharing recent advances between game theory and reinforcement learning community.
Ease-of-Teaching and Language Structure from Emergent Communication
Jun 06, 2019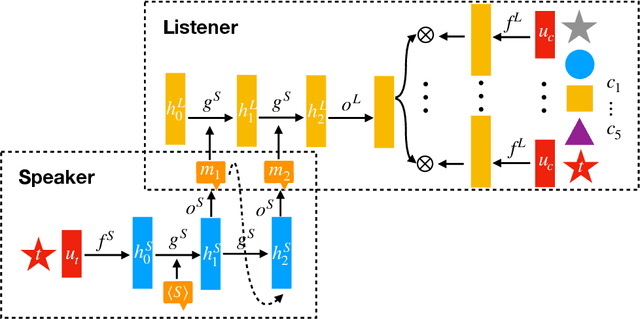

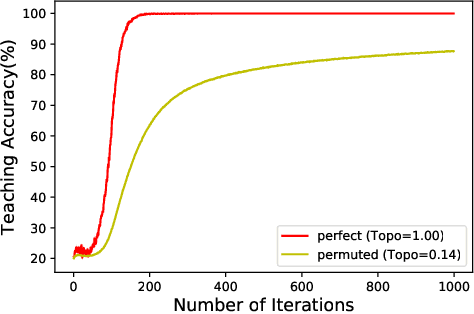

Artificial agents have been shown to learn to communicate when needed to complete a cooperative task. Some level of language structure (e.g., compositionality) has been found in the learned communication protocols. This observed structure is often the result of specific environmental pressures during training. By introducing new agents periodically to replace old ones, sequentially and within a population, we explore such a new pressure -- ease of teaching -- and show its impact on the structure of the resulting language.
The Hanabi Challenge: A New Frontier for AI Research
Feb 01, 2019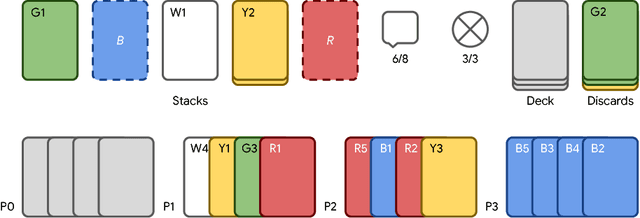
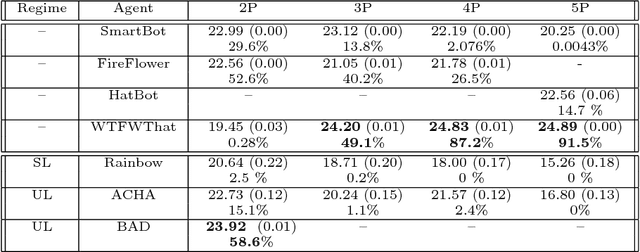
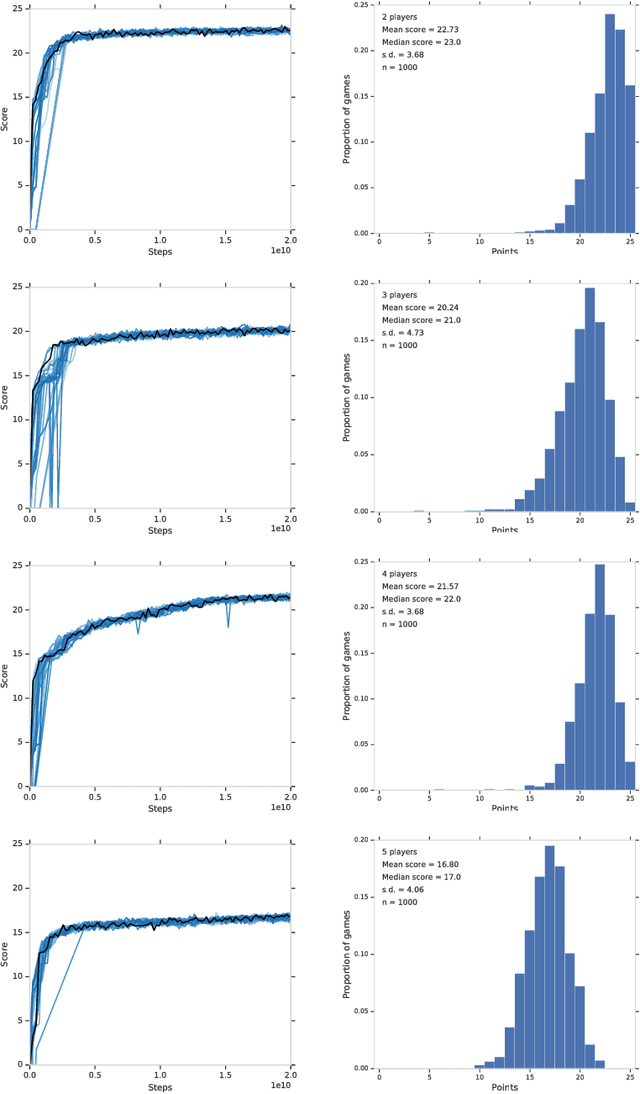
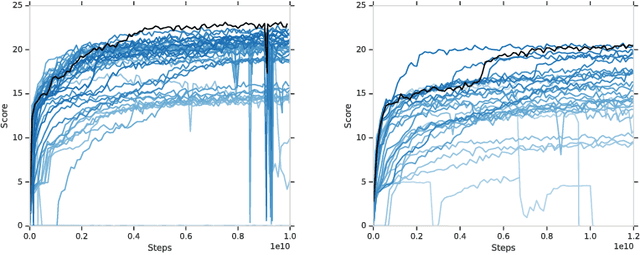
From the early days of computing, games have been important testbeds for studying how well machines can do sophisticated decision making. In recent years, machine learning has made dramatic advances with artificial agents reaching superhuman performance in challenge domains like Go, Atari, and some variants of poker. As with their predecessors of chess, checkers, and backgammon, these game domains have driven research by providing sophisticated yet well-defined challenges for artificial intelligence practitioners. We continue this tradition by proposing the game of Hanabi as a new challenge domain with novel problems that arise from its combination of purely cooperative gameplay and imperfect information in a two to five player setting. In particular, we argue that Hanabi elevates reasoning about the beliefs and intentions of other agents to the foreground. We believe developing novel techniques capable of imbuing artificial agents with such theory of mind will not only be crucial for their success in Hanabi, but also in broader collaborative efforts, and especially those with human partners. To facilitate future research, we introduce the open-source Hanabi Learning Environment, propose an experimental framework for the research community to evaluate algorithmic advances, and assess the performance of current state-of-the-art techniques.