 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver-communicate no more: Situated RL agents learn concise communication protocols
Nov 02, 2022



While it is known that communication facilitates cooperation in multi-agent settings, it is unclear how to design artificial agents that can learn to effectively and efficiently communicate with each other. Much research on communication emergence uses reinforcement learning (RL) and explores unsituated communication in one-step referential tasks -- the tasks are not temporally interactive and lack time pressures typically present in natural communication. In these settings, agents may successfully learn to communicate, but they do not learn to exchange information concisely -- they tend towards over-communication and an inefficient encoding. Here, we explore situated communication in a multi-step task, where the acting agent has to forgo an environmental action to communicate. Thus, we impose an opportunity cost on communication and mimic the real-world pressure of passing time. We compare communication emergence under this pressure against learning to communicate with a cost on articulation effort, implemented as a per-message penalty (fixed and progressively increasing). We find that while all tested pressures can disincentivise over-communication, situated communication does it most effectively and, unlike the cost on effort, does not negatively impact emergence. Implementing an opportunity cost on communication in a temporally extended environment is a step towards embodiment, and might be a pre-condition for incentivising efficient, human-like communication.
Interpolating Between Softmax Policy Gradient and Neural Replicator Dynamics with Capped Implicit Exploration
Jun 04, 2022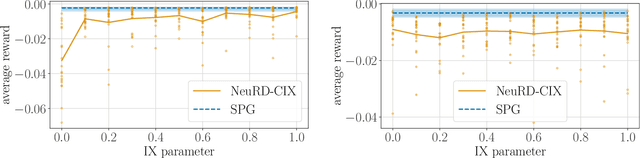
Neural replicator dynamics (NeuRD) is an alternative to the foundational softmax policy gradient (SPG) algorithm motivated by online learning and evolutionary game theory. The NeuRD expected update is designed to be nearly identical to that of SPG, however, we show that the Monte Carlo updates differ in a substantial way: the importance correction accounting for a sampled action is nullified in the SPG update, but not in the NeuRD update. Naturally, this causes the NeuRD update to have higher variance than its SPG counterpart. Building on implicit exploration algorithms in the adversarial bandit setting, we introduce capped implicit exploration (CIX) estimates that allow us to construct NeuRD-CIX, which interpolates between this aspect of NeuRD and SPG. We show how CIX estimates can be used in a black-box reduction to construct bandit algorithms with regret bounds that hold with high probability and the benefits this entails for NeuRD-CIX in sequential decision-making settings. Our analysis reveals a bias--variance tradeoff between SPG and NeuRD, and shows how theory predicts that NeuRD-CIX will perform well more consistently than NeuRD while retaining NeuRD's advantages over SPG in non-stationary environments.
Efficient Deviation Types and Learning for Hindsight Rationality in Extensive-Form Games: Corrections
May 24, 2022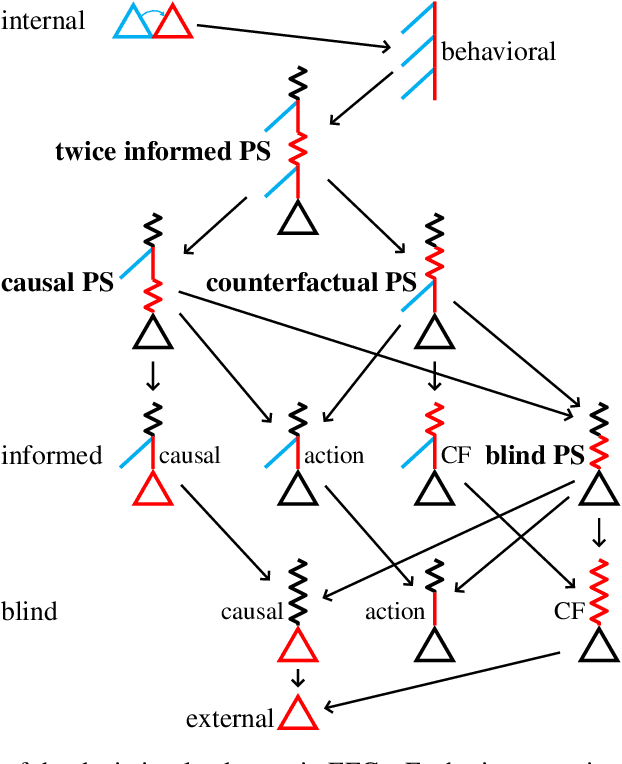
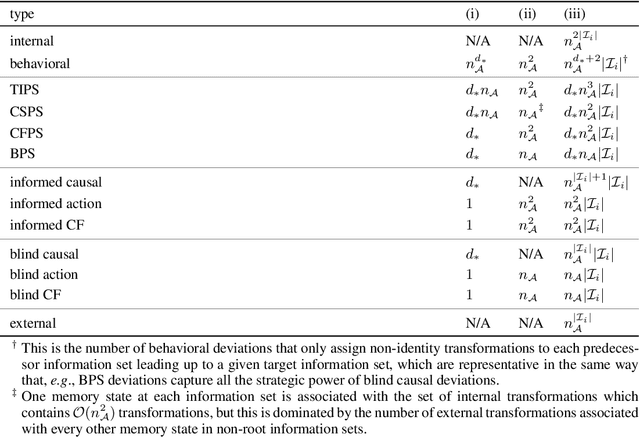
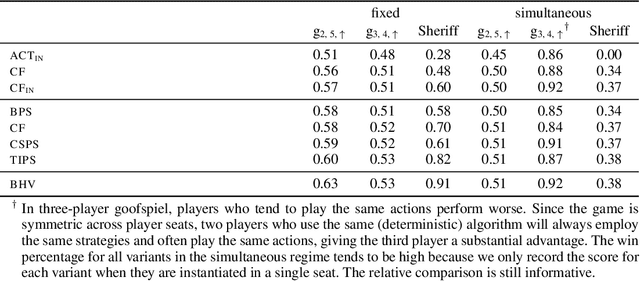

Hindsight rationality is an approach to playing general-sum games that prescribes no-regret learning dynamics for individual agents with respect to a set of deviations, and further describes jointly rational behavior among multiple agents with mediated equilibria. To develop hindsight rational learning in sequential decision-making settings, we formalize behavioral deviations as a general class of deviations that respect the structure of extensive-form games. Integrating the idea of time selection into counterfactual regret minimization (CFR), we introduce the extensive-form regret minimization (EFR) algorithm that achieves hindsight rationality for any given set of behavioral deviations with computation that scales closely with the complexity of the set. We identify behavioral deviation subsets, the partial sequence deviation types, that subsume previously studied types and lead to efficient EFR instances in games with moderate lengths. In addition, we present a thorough empirical analysis of EFR instantiated with different deviation types in benchmark games, where we find that stronger types typically induce better performance.
Should Models Be Accurate?
May 22, 2022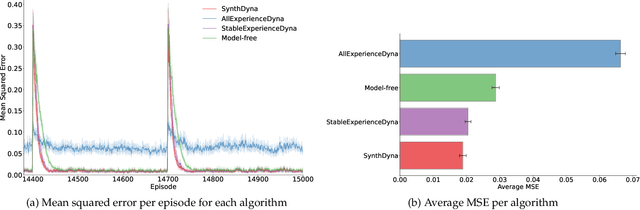
Model-based Reinforcement Learning (MBRL) holds promise for data-efficiency by planning with model-generated experience in addition to learning with experience from the environment. However, in complex or changing environments, models in MBRL will inevitably be imperfect, and their detrimental effects on learning can be difficult to mitigate. In this work, we question whether the objective of these models should be the accurate simulation of environment dynamics at all. We focus our investigations on Dyna-style planning in a prediction setting. First, we highlight and support three motivating points: a perfectly accurate model of environment dynamics is not practically achievable, is not necessary, and is not always the most useful anyways. Second, we introduce a meta-learning algorithm for training models with a focus on their usefulness to the learner instead of their accuracy in modelling the environment. Our experiments show that in a simple non-stationary environment, our algorithm enables faster learning than even using an accurate model built with domain-specific knowledge of the non-stationarity.
Player of Games
Dec 06, 2021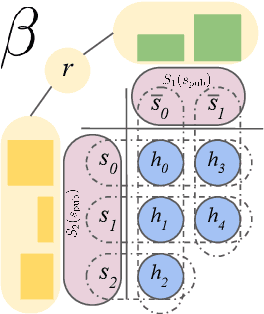

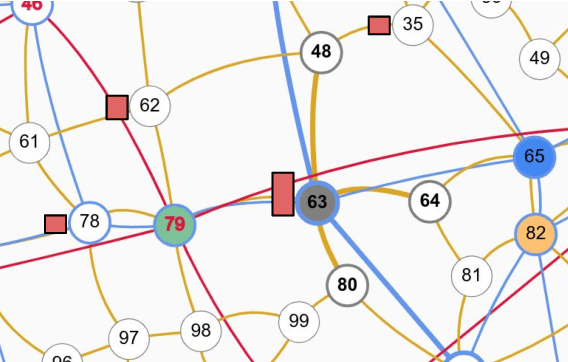
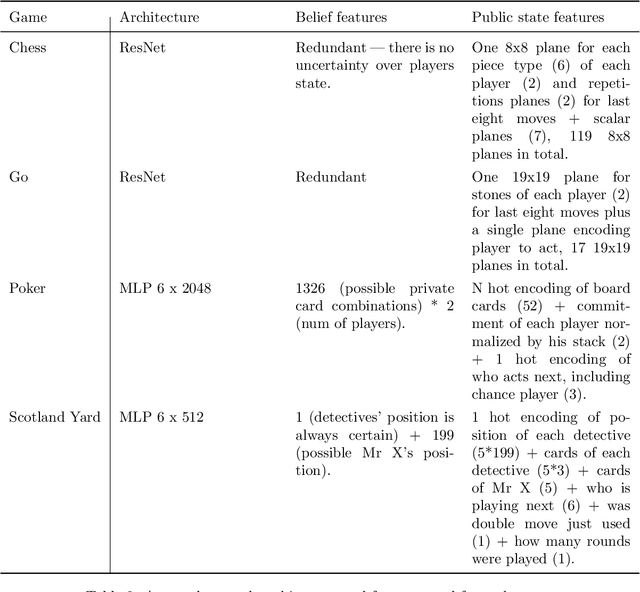
Games have a long history of serving as a benchmark for progress in artificial intelligence. Recently, approaches using search and learning have shown strong performance across a set of perfect information games, and approaches using game-theoretic reasoning and learning have shown strong performance for specific imperfect information poker variants. We introduce Player of Games, a general-purpose algorithm that unifies previous approaches, combining guided search, self-play learning, and game-theoretic reasoning. Player of Games is the first algorithm to achieve strong empirical performance in large perfect and imperfect information games -- an important step towards truly general algorithms for arbitrary environments. We prove that Player of Games is sound, converging to perfect play as available computation time and approximation capacity increases. Player of Games reaches strong performance in chess and Go, beats the strongest openly available agent in heads-up no-limit Texas hold'em poker (Slumbot), and defeats the state-of-the-art agent in Scotland Yard, an imperfect information game that illustrates the value of guided search, learning, and game-theoretic reasoning.
The Partially Observable History Process
Nov 15, 2021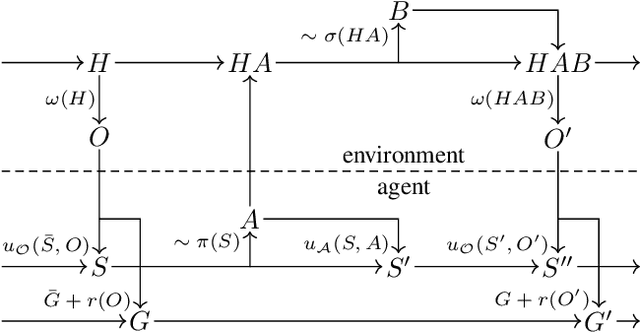
We introduce the partially observable history process (POHP) formalism for reinforcement learning. POHP centers around the actions and observations of a single agent and abstracts away the presence of other players without reducing them to stochastic processes. Our formalism provides a streamlined interface for designing algorithms that defy categorization as exclusively single or multi-agent, and for developing theory that applies across these domains. We show how the POHP formalism unifies traditional models including the Markov decision process, the Markov game, the extensive-form game, and their partially observable extensions, without introducing burdensome technical machinery or violating the philosophical underpinnings of reinforcement learning. We illustrate the utility of our formalism by concisely exploring observable sequential rationality, re-deriving the extensive-form regret minimization (EFR) algorithm, and examining EFR's theoretical properties in greater generality.
Learning to Be Cautious
Oct 29, 2021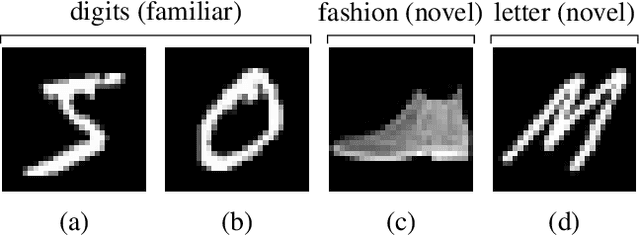


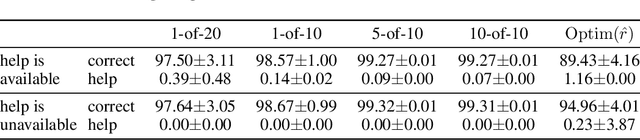
A key challenge in the field of reinforcement learning is to develop agents that behave cautiously in novel situations. It is generally impossible to anticipate all situations that an autonomous system may face or what behavior would best avoid bad outcomes. An agent that could learn to be cautious would overcome this challenge by discovering for itself when and how to behave cautiously. In contrast, current approaches typically embed task-specific safety information or explicit cautious behaviors into the system, which is error-prone and imposes extra burdens on practitioners. In this paper, we present both a sequence of tasks where cautious behavior becomes increasingly non-obvious, as well as an algorithm to demonstrate that it is possible for a system to \emph{learn} to be cautious. The essential features of our algorithm are that it characterizes reward function uncertainty without task-specific safety information and uses this uncertainty to construct a robust policy. Specifically, we construct robust policies with a $k$-of-$N$ counterfactual regret minimization (CFR) subroutine given a learned reward function uncertainty represented by a neural network ensemble belief. These policies exhibit caution in each of our tasks without any task-specific safety tuning.
Efficient Deviation Types and Learning for Hindsight Rationality in Extensive-Form Games
Feb 13, 2021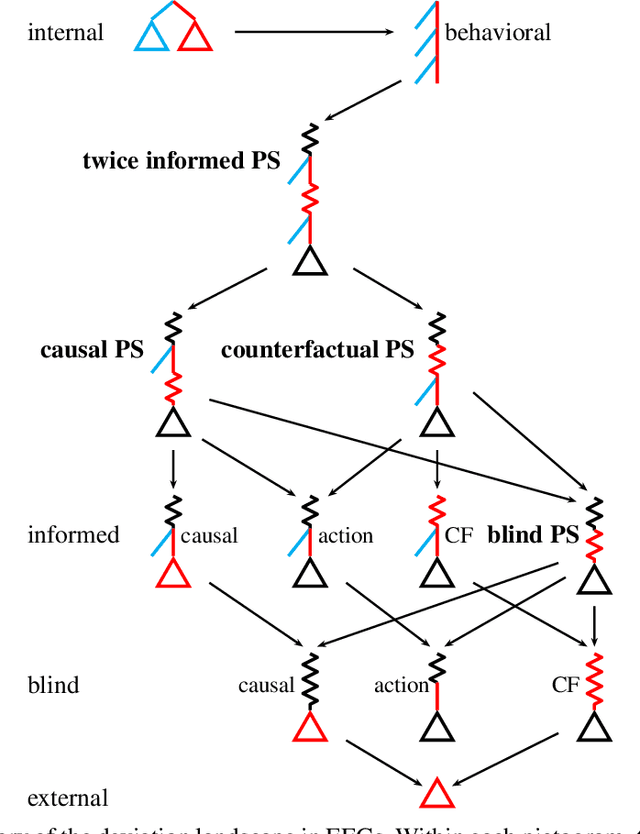

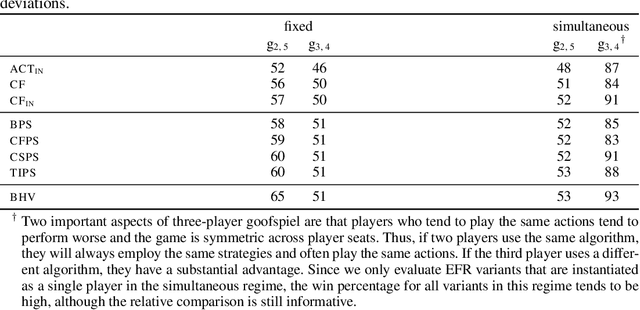
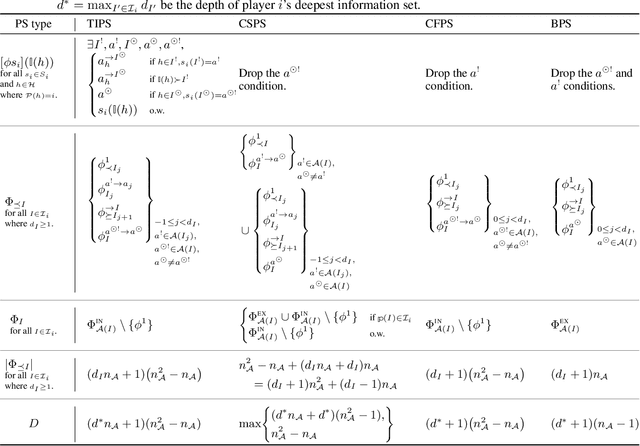
Hindsight rationality is an approach to playing multi-agent, general-sum games that prescribes no-regret learning dynamics and describes jointly rational behavior with mediated equilibria. We explore the space of deviation types in extensive-form games (EFGs) and discover powerful types that are efficient to compute in games with moderate lengths. Specifically, we identify four new types of deviations that subsume previously studied types within a broader class we call partial sequence deviations. Integrating the idea of time selection regret minimization into counterfactual regret minimization (CFR), we introduce the extensive-form regret minimization (EFR) algorithm that is hindsight rational for a general and natural class of deviations in EFGs. We provide instantiations and regret bounds for EFR that correspond to each partial sequence deviation type. In addition, we present a thorough empirical analysis of EFR's performance with different deviation types in common benchmark games. As theory suggests, instantiating EFR with stronger deviations leads to behavior that tends to outperform that of weaker deviations.
Solving Common-Payoff Games with Approximate Policy Iteration
Jan 11, 2021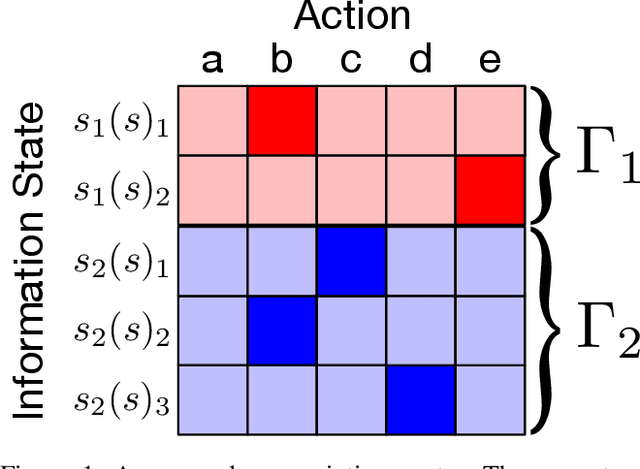
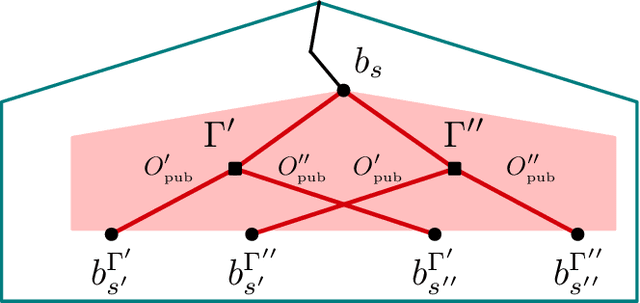
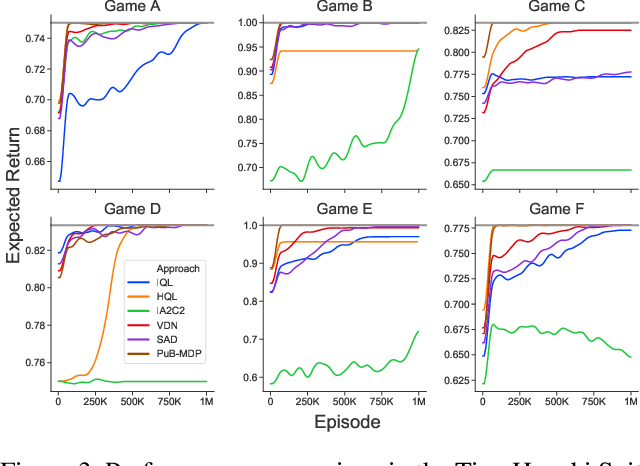
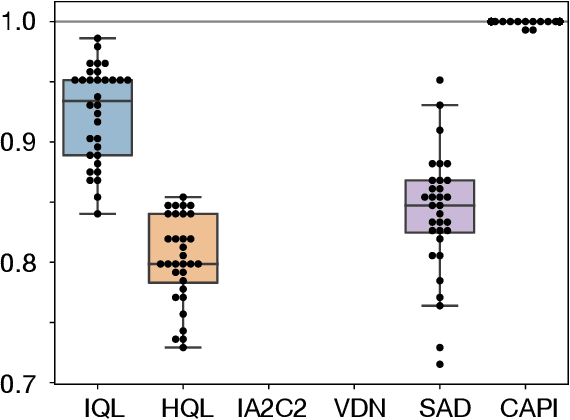
For artificially intelligent learning systems to have widespread applicability in real-world settings, it is important that they be able to operate decentrally. Unfortunately, decentralized control is difficult -- computing even an epsilon-optimal joint policy is a NEXP complete problem. Nevertheless, a recently rediscovered insight -- that a team of agents can coordinate via common knowledge -- has given rise to algorithms capable of finding optimal joint policies in small common-payoff games. The Bayesian action decoder (BAD) leverages this insight and deep reinforcement learning to scale to games as large as two-player Hanabi. However, the approximations it uses to do so prevent it from discovering optimal joint policies even in games small enough to brute force optimal solutions. This work proposes CAPI, a novel algorithm which, like BAD, combines common knowledge with deep reinforcement learning. However, unlike BAD, CAPI prioritizes the propensity to discover optimal joint policies over scalability. While this choice precludes CAPI from scaling to games as large as Hanabi, empirical results demonstrate that, on the games to which CAPI does scale, it is capable of discovering optimal joint policies even when other modern multi-agent reinforcement learning algorithms are unable to do so. Code is available at https://github.com/ssokota/capi .
Hindsight and Sequential Rationality of Correlated Play
Dec 17, 2020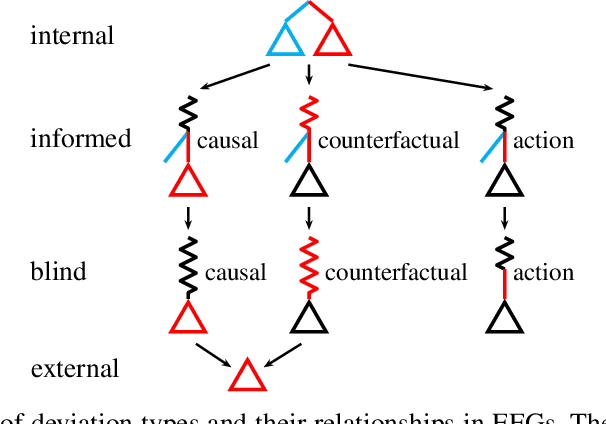
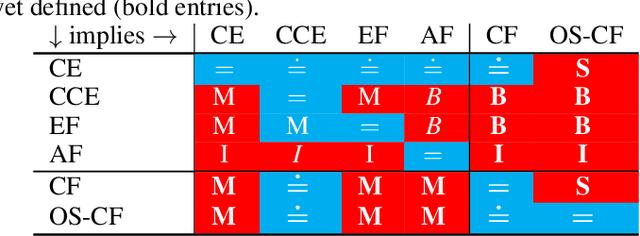
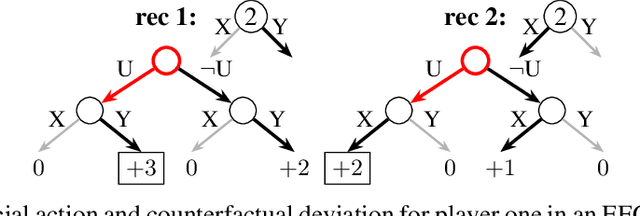
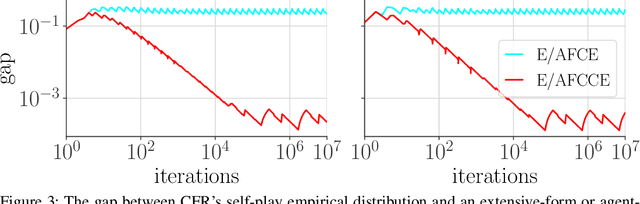
Driven by recent successes in two-player, zero-sum game solving and playing, artificial intelligence work on games has increasingly focused on algorithms that produce equilibrium-based strategies. However, this approach has been less effective at producing competent players in general-sum games or those with more than two players than in two-player, zero-sum games. An appealing alternative is to consider adaptive algorithms that ensure strong performance in hindsight relative to what could have been achieved with modified behavior. This approach also leads to a game-theoretic analysis, but in the correlated play that arises from joint learning dynamics rather than factored agent behavior at equilibrium. We develop and advocate for this hindsight rationality framing of learning in general sequential decision-making settings. To this end, we re-examine mediated equilibrium and deviation types in extensive-form games, thereby gaining a more complete understanding and resolving past misconceptions. We present a set of examples illustrating the distinct strengths and weaknesses of each type of equilibrium in the literature, and prove that no tractable concept subsumes all others. This line of inquiry culminates in the definition of the deviation and equilibrium classes that correspond to algorithms in the counterfactual regret minimization (CFR) family, relating them to all others in the literature. Examining CFR in greater detail further leads to a new recursive definition of rationality in correlated play that extends sequential rationality in a way that naturally applies to hindsight evaluation.