 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Unified Method for Detecting Text from Marathon Runners and Sports Players in Video
May 26, 2020
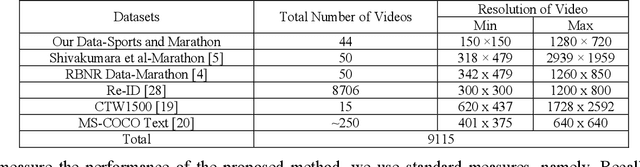


Detecting text located on the torsos of marathon runners and sports players in video is a challenging issue due to poor quality and adverse effects caused by flexible/colorful clothing, and different structures of human bodies or actions. This paper presents a new unified method for tackling the above challenges. The proposed method fuses gradient magnitude and direction coherence of text pixels in a new way for detecting candidate regions. Candidate regions are used for determining the number of temporal frame clusters obtained by K-means clustering on frame differences. This process in turn detects key frames. The proposed method explores Bayesian probability for skin portions using color values at both pixel and component levels of temporal frames, which provides fused images with skin components. Based on skin information, the proposed method then detects faces and torsos by finding structural and spatial coherences between them. We further propose adaptive pixels linking a deep learning model for text detection from torso regions. The proposed method is tested on our own dataset collected from marathon/sports video and three standard datasets, namely, RBNR, MMM and R-ID of marathon images, to evaluate the performance. In addition, the proposed method is also tested on the standard natural scene datasets, namely, CTW1500 and MS-COCO text datasets, to show the objectiveness of the proposed method. A comparative study with the state-of-the-art methods on bib number/text detection of different datasets shows that the proposed method outperforms the existing methods.
Robust Tensor Decomposition for Image Representation Based on Generalized Correntropy
May 10, 2020
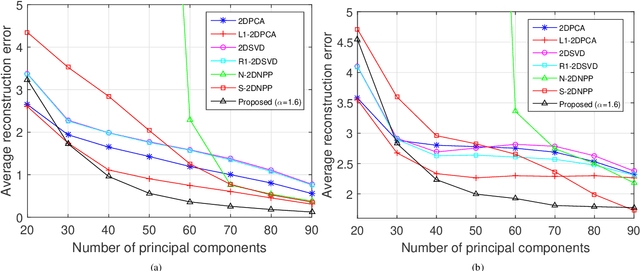
Traditional tensor decomposition methods, e.g., two dimensional principal component analysis and two dimensional singular value decomposition, that minimize mean square errors, are sensitive to outliers. To overcome this problem, in this paper we propose a new robust tensor decomposition method using generalized correntropy criterion (Corr-Tensor). A Lagrange multiplier method is used to effectively optimize the generalized correntropy objective function in an iterative manner. The Corr-Tensor can effectively improve the robustness of tensor decomposition with the existence of outliers without introducing any extra computational cost. Experimental results demonstrated that the proposed method significantly reduces the reconstruction error on face reconstruction and improves the accuracies on handwritten digit recognition and facial image clustering.
A Robust Matching Pursuit Algorithm Using Information Theoretic Learning
May 10, 2020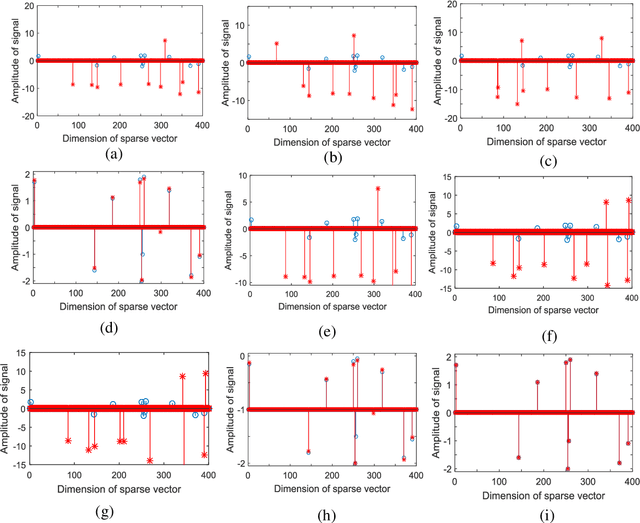
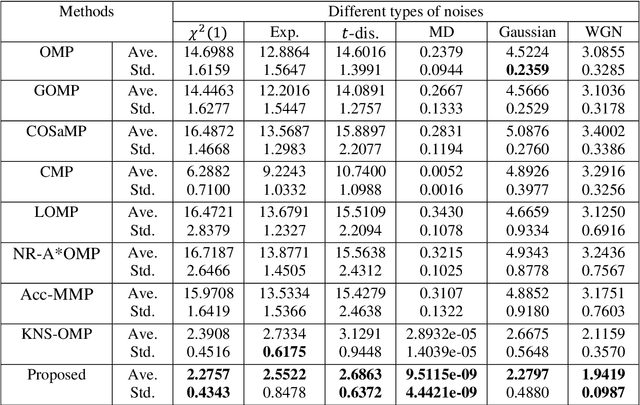
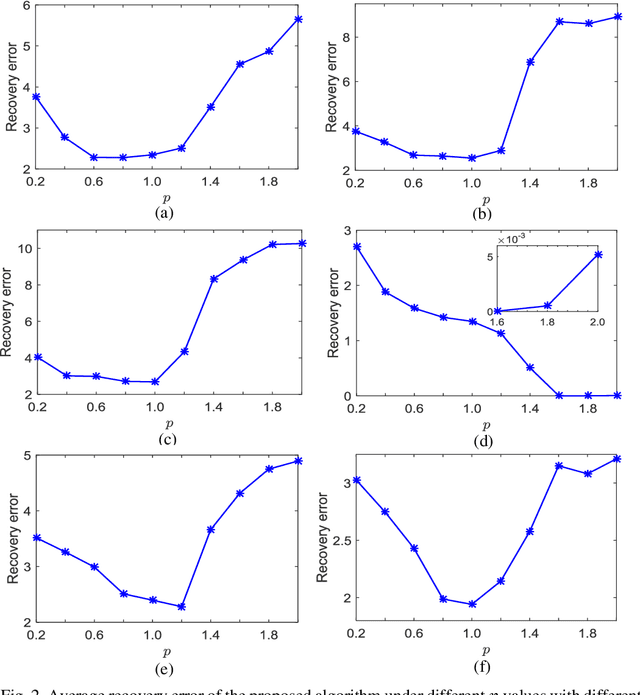
Current orthogonal matching pursuit (OMP) algorithms calculate the correlation between two vectors using the inner product operation and minimize the mean square error, which are both suboptimal when there are non-Gaussian noises or outliers in the observation data. To overcome these problems, a new OMP algorithm is developed based on the information theoretic learning (ITL), which is built on the following new techniques: (1) an ITL-based correlation (ITL-Correlation) is developed as a new similarity measure which can better exploit higher-order statistics of the data, and is robust against many different types of noise and outliers in a sparse representation framework; (2) a non-second order statistic measurement and minimization method is developed to improve the robustness of OMP by overcoming the limitation of Gaussianity inherent in cost function based on second-order moments. The experimental results on both simulated and real-world data consistently demonstrate the superiority of the proposed OMP algorithm in data recovery, image reconstruction, and classification.
Rethinking 1D-CNN for Time Series Classification: A Stronger Baseline
Feb 24, 2020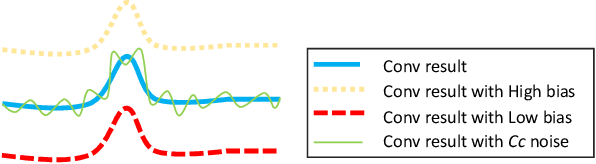
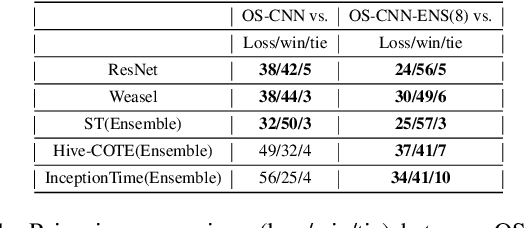
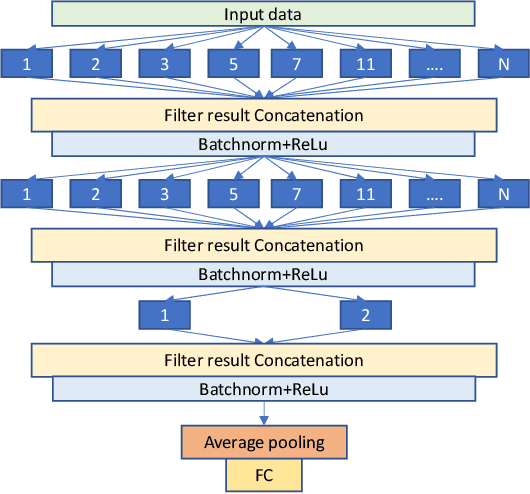
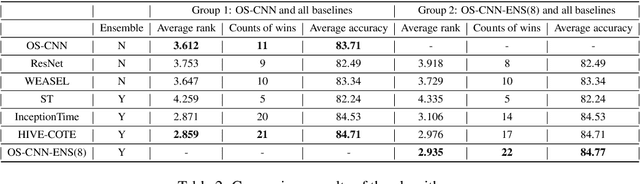
For time series classification task using 1D-CNN, the selection of kernel size is critically important to ensure the model can capture the right scale salient signal from a long time-series. Most of the existing work on 1D-CNN treats the kernel size as a hyper-parameter and tries to find the proper kernel size through a grid search which is time-consuming and is inefficient. This paper theoretically analyses how kernel size impacts the performance of 1D-CNN. Considering the importance of kernel size, we propose a novel Omni-Scale 1D-CNN (OS-CNN) architecture to capture the proper kernel size during the model learning period. A specific design for kernel size configuration is developed which enables us to assemble very few kernel-size options to represent more receptive fields. The proposed OS-CNN method is evaluated using the UCR archive with 85 datasets. The experiment results demonstrate that our method is a stronger baseline in multiple performance indicators, including the critical difference diagram, counts of wins, and average accuracy. We also published the experimental source codes at GitHub (https://github.com/Wensi-Tang/OS-CNN/).
Intra-Variable Handwriting Inspection Reinforced with Idiosyncrasy Analysis
Dec 19, 2019
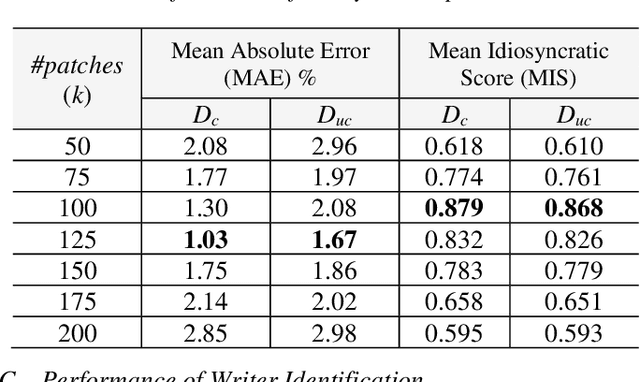
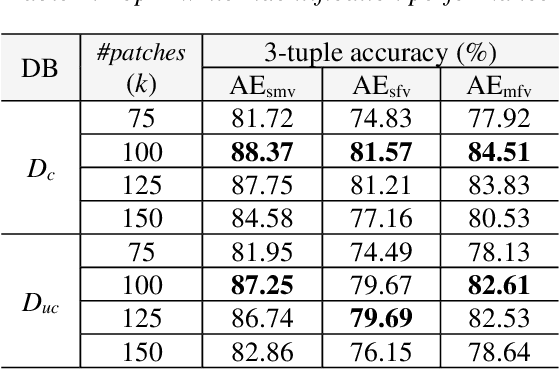
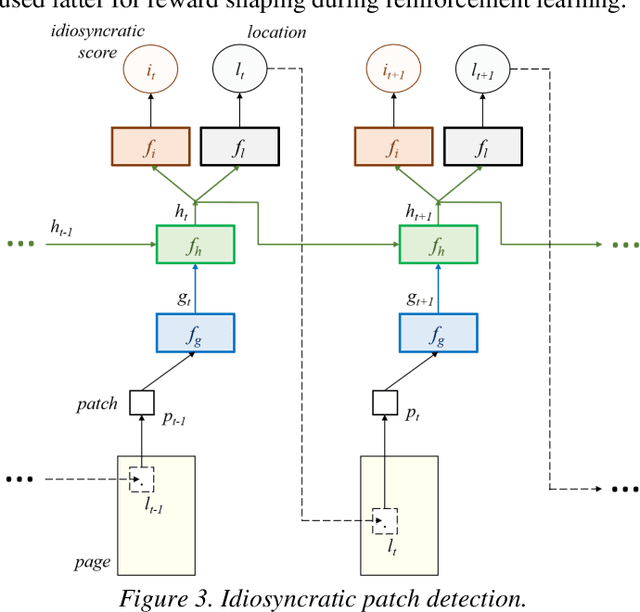
In this paper, we work on intra-variable handwriting, where the writing samples of an individual can vary significantly. Such within-writer variation throws a challenge for automatic writer inspection, where the state-of-the-art methods do not perform well. To deal with intra-variability, we analyze the idiosyncrasy in individual handwriting. We identify/verify the writer from highly idiosyncratic text-patches. Such patches are detected using a deep recurrent reinforcement learning-based architecture. An idiosyncratic score is assigned to every patch, which is predicted by employing deep regression analysis. For writer identification, we propose a deep neural architecture, which makes the final decision by the idiosyncratic score-induced weighted sum of patch-based decisions. For writer verification, we propose two algorithms for deep feature aggregation, which assist in authentication using a triplet network. The experiments were performed on two databases, where we obtained encouraging results.
Temporal Self-Attention Network for Medical Concept Embedding
Sep 15, 2019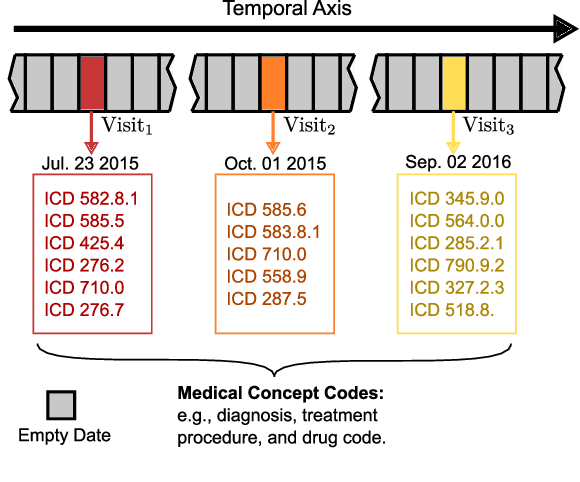
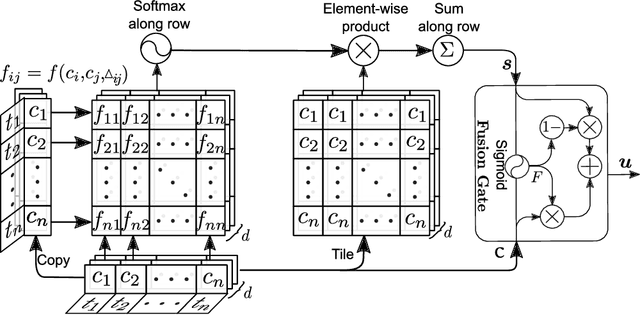
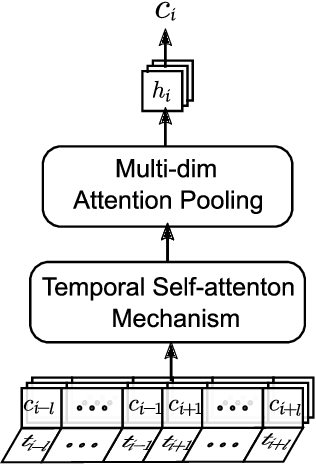

In longitudinal electronic health records (EHRs), the event records of a patient are distributed over a long period of time and the temporal relations between the events reflect sufficient domain knowledge to benefit prediction tasks such as the rate of inpatient mortality. Medical concept embedding as a feature extraction method that transforms a set of medical concepts with a specific time stamp into a vector, which will be fed into a supervised learning algorithm. The quality of the embedding significantly determines the learning performance over the medical data. In this paper, we propose a medical concept embedding method based on applying a self-attention mechanism to represent each medical concept. We propose a novel attention mechanism which captures the contextual information and temporal relationships between medical concepts. A light-weight neural net, "Temporal Self-Attention Network (TeSAN)", is then proposed to learn medical concept embedding based solely on the proposed attention mechanism. To test the effectiveness of our proposed methods, we have conducted clustering and prediction tasks on two public EHRs datasets comparing TeSAN against five state-of-the-art embedding methods. The experimental results demonstrate that the proposed TeSAN model is superior to all the compared methods. To the best of our knowledge, this work is the first to exploit temporal self-attentive relations between medical events.
FACLSTM: ConvLSTM with Focused Attention for Scene Text Recognition
Apr 20, 2019

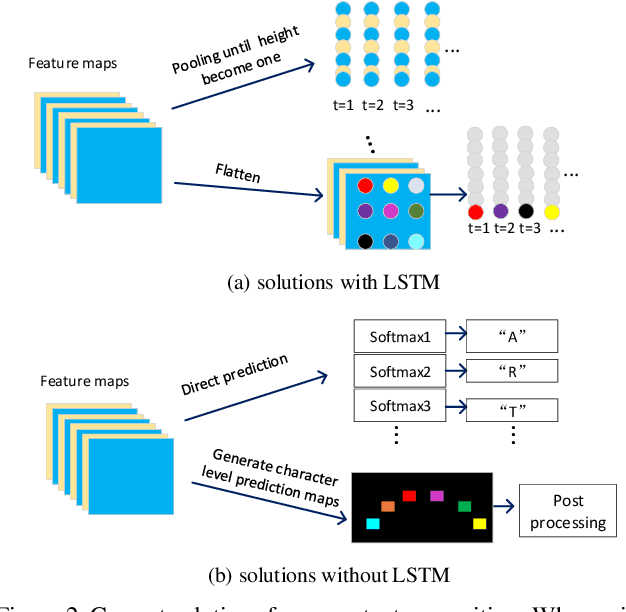
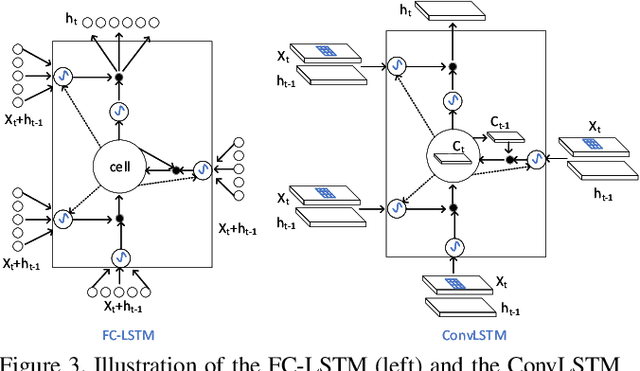
Scene text recognition has recently been widely treated as a sequence-to-sequence prediction problem, where traditional fully-connected-LSTM (FC-LSTM) has played a critical role. Due to the limitation of FC-LSTM, existing methods have to convert 2-D feature maps into 1-D sequential feature vectors, resulting in severe damages of the valuable spatial and structural information of text images. In this paper, we argue that scene text recognition is essentially a spatiotemporal prediction problem for its 2-D image inputs, and propose a convolution LSTM (ConvLSTM)-based scene text recognizer, namely, FACLSTM, i.e., Focused Attention ConvLSTM, where the spatial correlation of pixels is fully leveraged when performing sequential prediction with LSTM. Particularly, the attention mechanism is properly incorporated into an efficient ConvLSTM structure via the convolutional operations and additional character center masks are generated to help focus attention on right feature areas. The experimental results on benchmark datasets IIIT5K, SVT and CUTE demonstrate that our proposed FACLSTM performs competitively on the regular, low-resolution and noisy text images, and outperforms the state-of-the-art approaches on the curved text with large margins.
A Study on Writer Identification and Verification from Intra-variable Individual Handwriting
Sep 06, 2018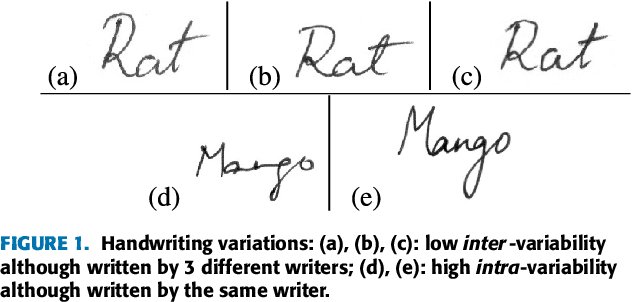
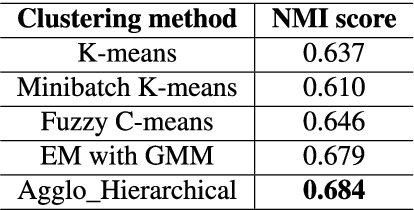
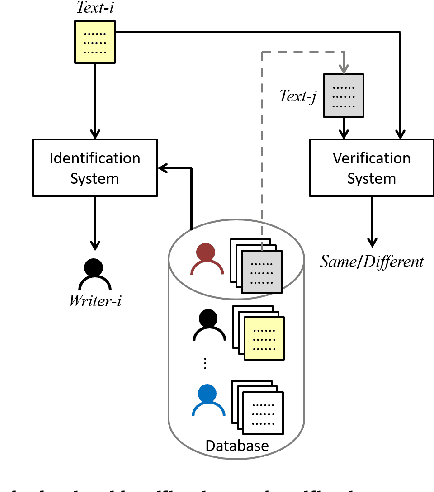
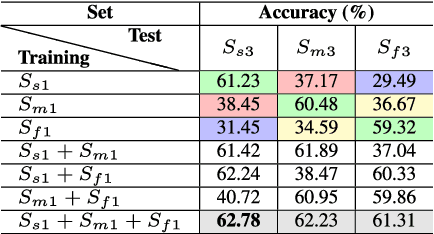
The handwriting of an individual may vary substantially with factors such as mood, time, space, writing speed, writing medium and tool, writing topic, etc. It becomes challenging to perform automated writer verification/identification on a particular set of handwritten patterns (e.g., speedy handwriting) of a person, especially when the system is trained using a different set of writing patterns (e.g., normal speed) of that same person. However, it would be interesting to experimentally analyze if there exists any implicit characteristic of individuality which is insensitive to high intra-variable handwriting. In this paper, we study some handcrafted features and auto-derived features extracted from intra-variable writing. Here, we work on writer identification/verification from offline Bengali handwriting of high intra-variability. To this end, we use various models mainly based on handcrafted features with SVM (Support Vector Machine) and features auto-derived by the convolutional network. For experimentation, we have generated two handwritten databases from two different sets of 100 writers and enlarged the dataset by a data-augmentation technique. We have obtained some interesting results.
Bag-of-Visual-Words for Signature-Based Multi-Script Document Retrieval
Jul 18, 2018
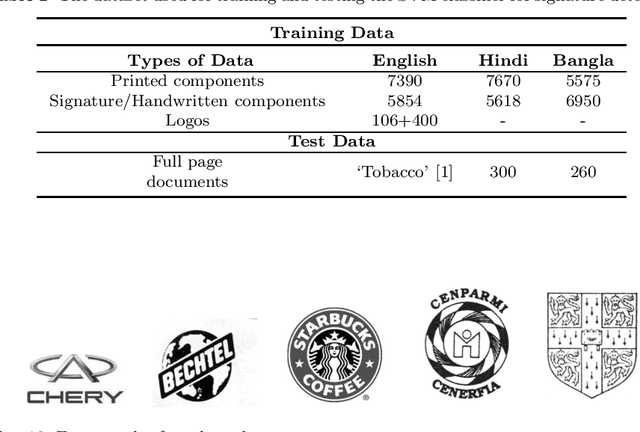

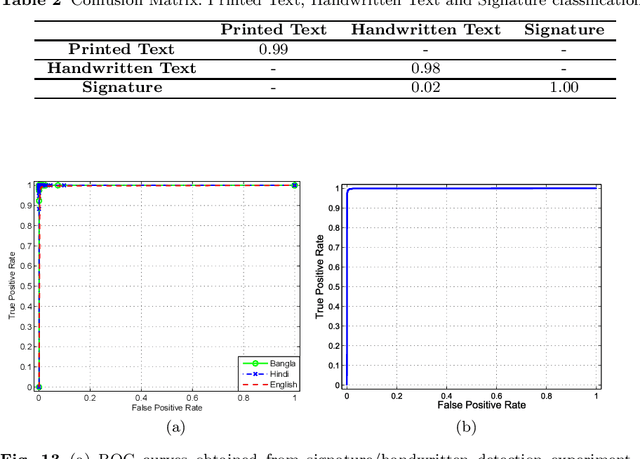
An end-to-end architecture for multi-script document retrieval using handwritten signatures is proposed in this paper. The user supplies a query signature sample and the system exclusively returns a set of documents that contain the query signature. In the first stage, a component-wise classification technique separates the potential signature components from all other components. A bag-of-visual-words powered by SIFT descriptors in a patch-based framework is proposed to compute the features and a Support Vector Machine (SVM)-based classifier was used to separate signatures from the documents. In the second stage, features from the foreground (i.e. signature strokes) and the background spatial information (i.e. background loops, reservoirs etc.) were combined to characterize the signature object to match with the query signature. Finally, three distance measures were used to match a query signature with the signature present in target documents for retrieval. The `Tobacco' document database and an Indian script database containing 560 documents of Devanagari (Hindi) and Bangla scripts were used for the performance evaluation. The proposed system was also tested on noisy documents and promising results were obtained. A comparative study shows that the proposed method outperforms the state-of-the-art approaches.