 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Thematic Analysis for Clinical Qualitative Data: Iterative Codebook Refinement with Full Provenance
Mar 09, 2026Thematic analysis (TA) is widely used in health research to extract patterns from patient interviews, yet manual TA faces challenges in scalability and reproducibility. LLM-based automation can help, but existing approaches produce codebooks with limited generalizability and lack analytic auditability. We present an automated TA framework combining iterative codebook refinement with full provenance tracking. Evaluated on five corpora spanning clinical interviews, social media, and public transcripts, the framework achieves the highest composite quality score on four of five datasets compared to six baselines. Iterative refinement yields statistically significant improvements on four datasets with large effect sizes, driven by gains in code reusability and distributional consistency while preserving descriptive quality. On two clinical corpora (pediatric cardiology), generated themes align with expert-annotated themes.
Single color virtual H&E staining with In-and-Out Net
May 22, 2024



Virtual staining streamlines traditional staining procedures by digitally generating stained images from unstained or differently stained images. While conventional staining methods involve time-consuming chemical processes, virtual staining offers an efficient and low infrastructure alternative. Leveraging microscopy-based techniques, such as confocal microscopy, researchers can expedite tissue analysis without the need for physical sectioning. However, interpreting grayscale or pseudo-color microscopic images remains a challenge for pathologists and surgeons accustomed to traditional histologically stained images. To fill this gap, various studies explore digitally simulating staining to mimic targeted histological stains. This paper introduces a novel network, In-and-Out Net, specifically designed for virtual staining tasks. Based on Generative Adversarial Networks (GAN), our model efficiently transforms Reflectance Confocal Microscopy (RCM) images into Hematoxylin and Eosin (H&E) stained images. We enhance nuclei contrast in RCM images using aluminum chloride preprocessing for skin tissues. Training the model with virtual H\&E labels featuring two fluorescence channels eliminates the need for image registration and provides pixel-level ground truth. Our contributions include proposing an optimal training strategy, conducting a comparative analysis demonstrating state-of-the-art performance, validating the model through an ablation study, and collecting perfectly matched input and ground truth images without registration. In-and-Out Net showcases promising results, offering a valuable tool for virtual staining tasks and advancing the field of histological image analysis.
Adversarial Video Compression Guided by Soft Edge Detection
Nov 26, 2018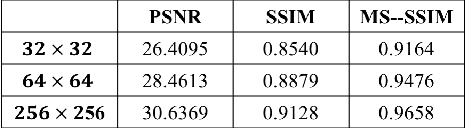
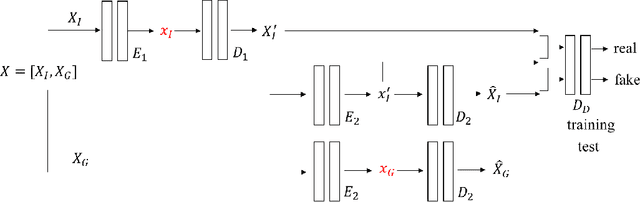
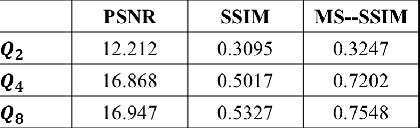
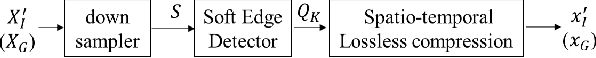
We propose a video compression framework using conditional Generative Adversarial Networks (GANs). We rely on two encoders: one that deploys a standard video codec and another which generates low-level maps via a pipeline of down-sampling, a newly devised soft edge detector, and a novel lossless compression scheme. For decoding, we use a standard video decoder as well as a neural network based one, which is trained using a conditional GAN. Recent "deep" approaches to video compression require multiple videos to pre-train generative networks to conduct interpolation. In contrast to this prior work, our scheme trains a generative decoder on pairs of a very limited number of key frames taken from a single video and corresponding low-level maps. The trained decoder produces reconstructed frames relying on a guidance of low-level maps, without any interpolation. Experiments on a diverse set of 131 videos demonstrate that our proposed GAN-based compression engine achieves much higher quality reconstructions at very low bitrates than prevailing standard codecs such as H.264 or HEVC.