 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024



This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Occlusion-shared and Feature-separated Network for Occlusion Relationship Reasoning
Aug 16, 2019
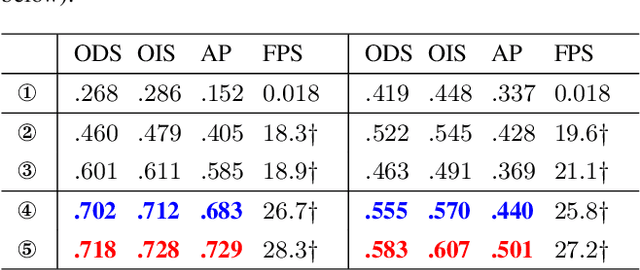
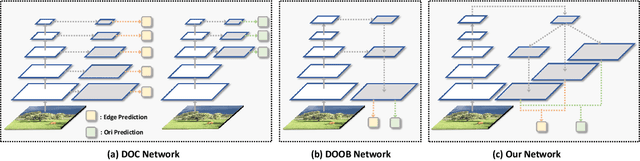
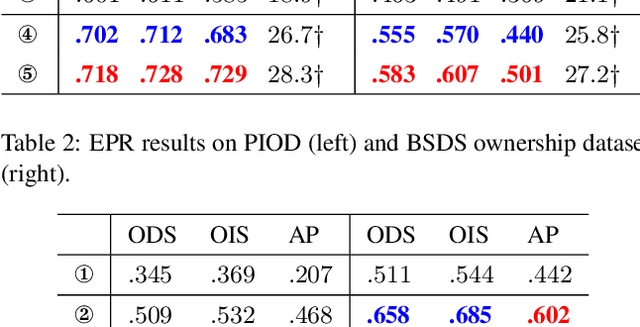
Occlusion relationship reasoning demands closed contour to express the object, and orientation of each contour pixel to describe the order relationship between objects. Current CNN-based methods neglect two critical issues of the task: (1) simultaneous existence of the relevance and distinction for the two elements, i.e, occlusion edge and occlusion orientation; and (2) inadequate exploration to the orientation features. For the reasons above, we propose the Occlusion-shared and Feature-separated Network (OFNet). On one hand, considering the relevance between edge and orientation, two sub-networks are designed to share the occlusion cue. On the other hand, the whole network is split into two paths to learn the high-level semantic features separately. Moreover, a contextual feature for orientation prediction is extracted, which represents the bilateral cue of the foreground and background areas. The bilateral cue is then fused with the occlusion cue to precisely locate the object regions. Finally, a stripe convolution is designed to further aggregate features from surrounding scenes of the occlusion edge. The proposed OFNet remarkably advances the state-of-the-art approaches on PIOD and BSDS ownership dataset. The source code is available at https://github.com/buptlr/OFNet.
A Novel Multi-layer Framework for Tiny Obstacle Discovery
May 06, 2019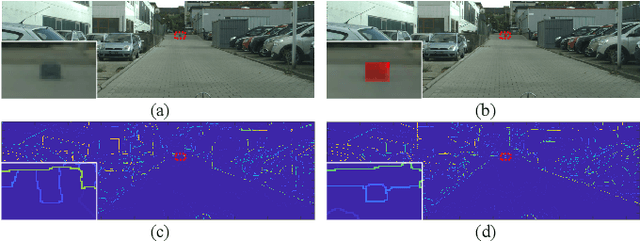
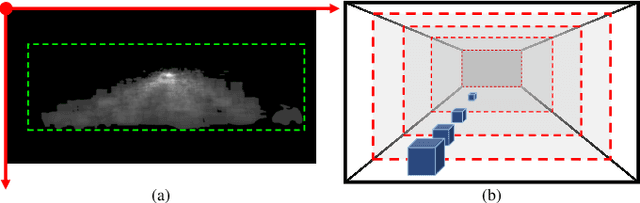
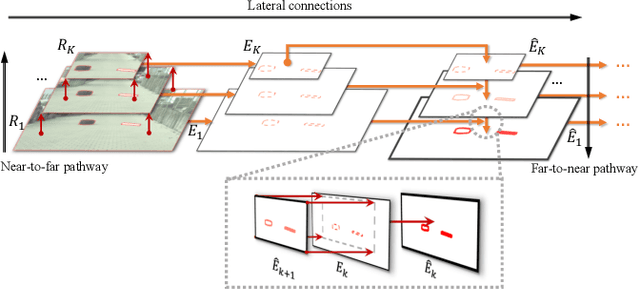
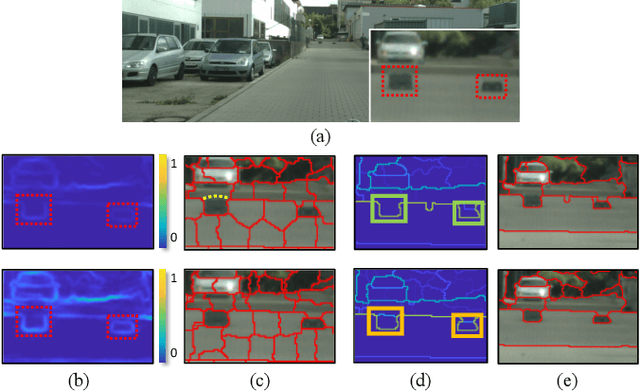
For tiny obstacle discovery in a monocular image, edge is a fundamental visual element. Nevertheless, because of various reasons, e.g., noise and similar color distribution with background, it is still difficult to detect the edges of tiny obstacles at long distance. In this paper, we propose an obstacle-aware discovery method to recover the missing contours of these obstacles, which helps to obtain obstacle proposals as much as possible. First, by using visual cues in monocular images, several multi-layer regions are elaborately inferred to reveal the distances from the camera. Second, several novel obstacle-aware occlusion edge maps are constructed to well capture the contours of tiny obstacles, which combines cues from each layer. Third, to ensure the existence of the tiny obstacle proposals, the maps from all layers are used for proposals extraction. Finally, based on these proposals containing tiny obstacles, a novel obstacle-aware regressor is proposed to generate an obstacle occupied probability map with high confidence. The convincing experimental results with comparisons on the Lost and Found dataset demonstrate the effectiveness of our approach, achieving around 9.5% improvement on the accuracy than FPHT and PHT, it even gets comparable performance to MergeNet. Moreover, our method outperforms the state-of-the-art algorithms and significantly improves the discovery ability for tiny obstacles at long distance.
Context-Constrained Accurate Contour Extraction for Occlusion Edge Detection
Mar 21, 2019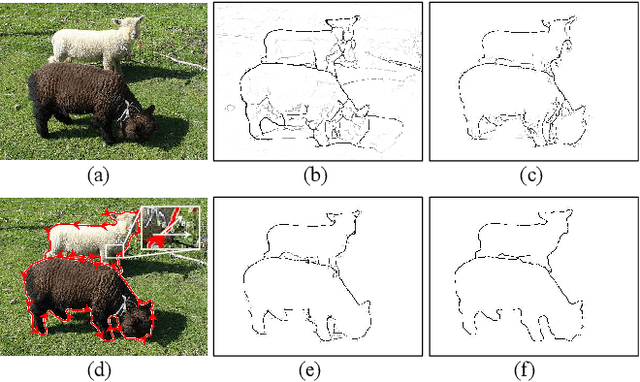
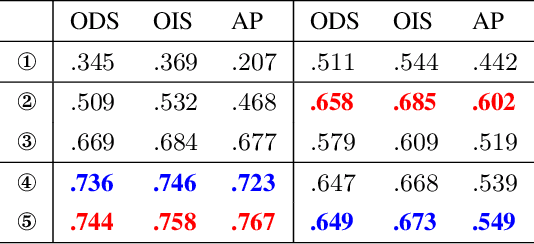
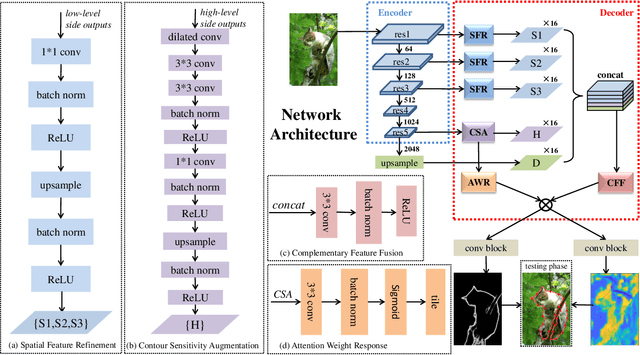
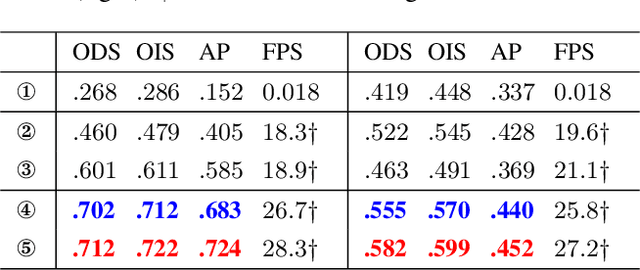
Occlusion edge detection requires both accurate locations and context constraints of the contour. Existing CNN-based pipeline does not utilize adaptive methods to filter the noise introduced by low-level features. To address this dilemma, we propose a novel Context-constrained accurate Contour Extraction Network (CCENet). Spatial details are retained and contour-sensitive context is augmented through two extraction blocks, respectively. Then, an elaborately designed fusion module is available to integrate features, which plays a complementary role to restore details and remove clutter. Weight response of attention mechanism is eventually utilized to enhance occluded contours and suppress noise. The proposed CCENet significantly surpasses state-of-the-art methods on PIOD and BSDS ownership dataset of object edge detection and occlusion orientation detection.