 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Optimal Sampling Rate Selection and Unbiased Classification for Precise Animal Activity Recognition
Apr 01, 2026With the rapid advancements in deep learning techniques, wearable sensor-aided animal activity recognition (AAR) has demonstrated promising performance, thereby improving livestock management efficiency as well as animal health and welfare monitoring. However, existing research often prioritizes overall performance, overlooking the fact that classification accuracies for specific animal behavioral categories may remain unsatisfactory. This issue typically stems from suboptimal sampling rates or class imbalance problems. To address these challenges and achieve high classification accuracy across all individual behaviors in farm animals, we propose a novel Individual-Behavior-Aware Network (IBA-Net). This network enhances the recognition of each specific behavior by simultaneously customizing features and calibrating the classifier. Specifically, considering that different behaviors require varying sampling rates to achieve optimal performance, we design a Mixture-of-Experts (MoE)-based Feature Customization (MFC) module. This module adaptively fuses data from multiple sampling rates, capturing customized features tailored to various animal behaviors. Additionally, to mitigate classifier bias toward majority classes caused by class imbalance, we develop a Neural Collapse-driven Classifier Calibration (NC3) module. This module introduces a fixed equiangular tight frame (ETF) classifier during the classification stage, maximizing the angles between pair-wise classifier vectors and thereby improving the classification performance for minority classes. To validate the effectiveness of IBA-Net, we conducted experiments on three public datasets covering goat, cattle, and horse activity recognition. The results demonstrate that our method consistently outperforms existing approaches across all datasets.
Personalized Federated Learning with Residual Fisher Information for Medical Image Segmentation
Mar 16, 2026Federated learning enables multiple clients (institutions) to collaboratively train machine learning models without sharing their private data. To address the challenge of data heterogeneity across clients, personalized federated learning (pFL) aims to learn customized models for each client. In this work, we propose pFL-ResFIM, a novel pFL framework that achieves client-adaptive personalization at the parameter level. Specifically, we introduce a new metric, Residual Fisher Information Matrix (ResFIM), to quantify the sensitivity of model parameters to domain discrepancies. To estimate ResFIM for each client model under privacy constraints, we employ a spectral transfer strategy that generates simulated data reflecting the domain styles of different clients. Based on the estimated ResFIM, we partition model parameters into domain-sensitive and domain-invariant components. A personalized model for each client is then constructed by aggregating only the domain-invariant parameters on the server. Extensive experiments on public datasets demonstrate that pFL-ResFIM consistently outperforms state-of-the-art methods, validating its effectiveness.
Joint Segmentation and Grading with Iterative Optimization for Multimodal Glaucoma Diagnosis
Mar 15, 2026Accurate diagnosis of glaucoma is challenging, as early-stage changes are subtle and often lack clear structural or appearance cues. Most existing approaches rely on a single modality, such as fundus or optical coherence tomography (OCT), capturing only partial pathological information and often missing early disease progression. In this paper, we propose an iterative multimodal optimization model (IMO) for joint segmentation and grading. IMO integrates fundus and OCT features through a mid-level fusion strategy, enhanced by a cross-modal feature alignment (CMFA) module to reduce modality discrepancies. An iterative refinement decoder progressively optimizes the multimodal features through a denoising diffusion mechanism, enabling fine-grained segmentation of the optic disc and cup while supporting accurate glaucoma grading. Extensive experiments show that our method effectively integrates multimodal features, providing a comprehensive and clinically significant approach to glaucoma assessment. Source codes are available at https://github.com/warren-wzw/IMO.git.
FL-MedSegBench: A Comprehensive Benchmark for Federated Learning on Medical Image Segmentation
Mar 12, 2026Federated learning (FL) offers a privacy-preserving paradigm for collaborative medical image analysis without sharing raw data. However, the absence of standardized benchmarks for medical image segmentation hinders fair and comprehensive evaluation of FL methods. To address this gap, we introduce FL-MedSegBench, the first comprehensive benchmark for federated learning on medical image segmentation. Our benchmark encompasses nine segmentation tasks across ten imaging modalities, covering both 2D and 3D formats with realistic clinical heterogeneity. We systematically evaluate eight generic FL (gFL) and five personalized FL (pFL) methods across multiple dimensions: segmentation accuracy, fairness, communication efficiency, convergence behavior, and generalization to unseen domains. Extensive experiments reveal several key insights: (i) pFL methods, particularly those with client-specific batch normalization (\textit{e.g.}, FedBN), consistently outperform generic approaches; (ii) No single method universally dominates, with performance being dataset-dependent; (iii) Communication frequency analysis shows normalization-based personalization methods exhibit remarkable robustness to reduced communication frequency; (iv) Fairness evaluation identifies methods like Ditto and FedRDN that protect underperforming clients; (v) A method's generalization to unseen domains is strongly tied to its ability to perform well across participating clients. We will release an open-source toolkit to foster reproducible research and accelerate clinically applicable FL solutions, providing empirically grounded guidelines for real-world clinical deployment. The source code is available at https://github.com/meiluzhu/FL-MedSegBench.
FedBM: Stealing Knowledge from Pre-trained Language Models for Heterogeneous Federated Learning
Feb 24, 2025



Federated learning (FL) has shown great potential in medical image computing since it provides a decentralized learning paradigm that allows multiple clients to train a model collaboratively without privacy leakage. However, current studies have shown that data heterogeneity incurs local learning bias in classifiers and feature extractors of client models during local training, leading to the performance degradation of a federation system. To address these issues, we propose a novel framework called Federated Bias eliMinating (FedBM) to get rid of local learning bias in heterogeneous federated learning (FL), which mainly consists of two modules, i.e., Linguistic Knowledge-based Classifier Construction (LKCC) and Concept-guided Global Distribution Estimation (CGDE). Specifically, LKCC exploits class concepts, prompts and pre-trained language models (PLMs) to obtain concept embeddings. These embeddings are used to estimate the latent concept distribution of each class in the linguistic space. Based on the theoretical derivation, we can rely on these distributions to pre-construct a high-quality classifier for clients to achieve classification optimization, which is frozen to avoid classifier bias during local training. CGDE samples probabilistic concept embeddings from the latent concept distributions to learn a conditional generator to capture the input space of the global model. Three regularization terms are introduced to improve the quality and utility of the generator. The generator is shared by all clients and produces pseudo data to calibrate updates of local feature extractors. Extensive comparison experiments and ablation studies on public datasets demonstrate the superior performance of FedBM over state-of-the-arts and confirm the effectiveness of each module, respectively. The code is available at https://github.com/CUHK-AIM-Group/FedBM.
CKSP: Cross-species Knowledge Sharing and Preserving for Universal Animal Activity Recognition
Oct 22, 2024Deep learning techniques are dominating automated animal activity recognition (AAR) tasks with wearable sensors due to their high performance on large-scale labelled data. However, current deep learning-based AAR models are trained solely on datasets of individual animal species, constraining their applicability in practice and performing poorly when training data are limited. In this study, we propose a one-for-many framework, dubbed Cross-species Knowledge Sharing and Preserving (CKSP), based on sensor data of diverse animal species. Given the coexistence of generic and species-specific behavioural patterns among different species, we design a Shared-Preserved Convolution (SPConv) module. This module assigns an individual low-rank convolutional layer to each species for extracting species-specific features and employs a shared full-rank convolutional layer to learn generic features, enabling the CKSP framework to learn inter-species complementarity and alleviating data limitations via increasing data diversity. Considering the training conflict arising from discrepancies in data distributions among species, we devise a Species-specific Batch Normalization (SBN) module, that involves multiple BN layers to separately fit the distributions of different species. To validate CKSP's effectiveness, experiments are performed on three public datasets from horses, sheep, and cattle, respectively. The results show that our approach remarkably boosts the classification performance compared to the baseline method (one-for-one framework) solely trained on individual-species data, with increments of 6.04%, 2.06%, and 3.66% in accuracy, and 10.33%, 3.67%, and 7.90% in F1-score for the horse, sheep, and cattle datasets, respectively. This proves the promising capabilities of our method in leveraging multi-species data to augment classification performance.
DEeR: Deviation Eliminating and Noise Regulating for Privacy-preserving Federated Low-rank Adaptation
Oct 16, 2024



Integrating low-rank adaptation (LoRA) with federated learning (FL) has received widespread attention recently, aiming to adapt pretrained foundation models (FMs) to downstream medical tasks via privacy-preserving decentralized training. However, owing to the direct combination of LoRA and FL, current methods generally undergo two problems, i.e., aggregation deviation, and differential privacy (DP) noise amplification effect. To address these problems, we propose a novel privacy-preserving federated finetuning framework called \underline{D}eviation \underline{E}liminating and Nois\underline{e} \underline{R}egulating (DEeR). Specifically, we firstly theoretically prove that the necessary condition to eliminate aggregation deviation is guaranteing the equivalence between LoRA parameters of clients. Based on the theoretical insight, a deviation eliminator is designed to utilize alternating minimization algorithm to iteratively optimize the zero-initialized and non-zero-initialized parameter matrices of LoRA, ensuring that aggregation deviation always be zeros during training. Furthermore, we also conduct an in-depth analysis of the noise amplification effect and find that this problem is mainly caused by the ``linear relationship'' between DP noise and LoRA parameters. To suppress the noise amplification effect, we propose a noise regulator that exploits two regulator factors to decouple relationship between DP and LoRA, thereby achieving robust privacy protection and excellent finetuning performance. Additionally, we perform comprehensive ablated experiments to verify the effectiveness of the deviation eliminator and noise regulator. DEeR shows better performance on public medical datasets in comparison with state-of-the-art approaches. The code is available at https://github.com/CUHK-AIM-Group/DEeR.
Personalized Retrogress-Resilient Framework for Real-World Medical Federated Learning
Oct 01, 2021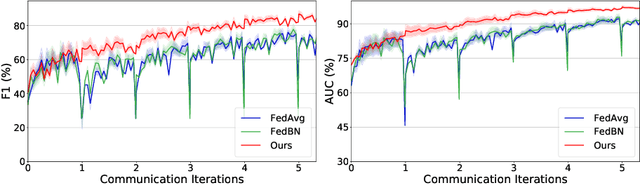
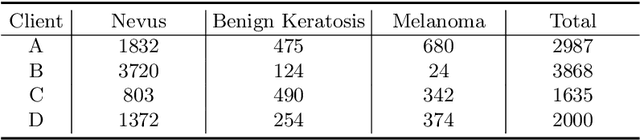
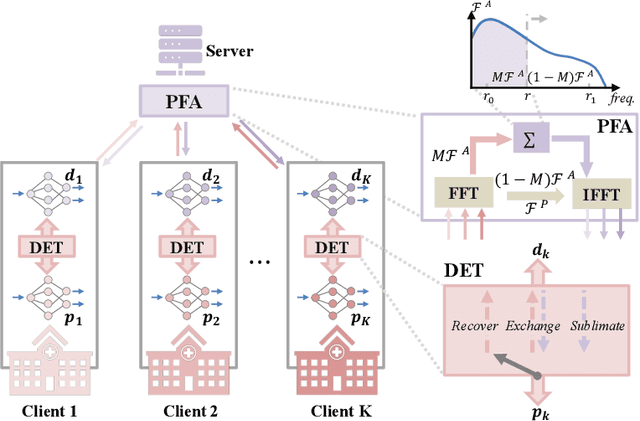
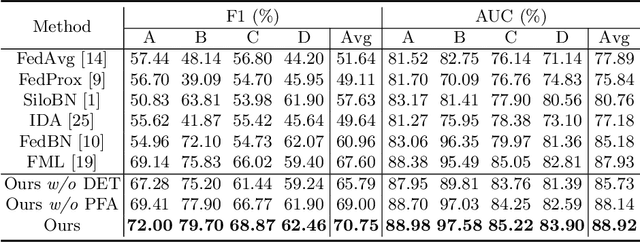
Nowadays, deep learning methods with large-scale datasets can produce clinically useful models for computer-aided diagnosis. However, the privacy and ethical concerns are increasingly critical, which make it difficult to collect large quantities of data from multiple institutions. Federated Learning (FL) provides a promising decentralized solution to train model collaboratively by exchanging client models instead of private data. However, the server aggregation of existing FL methods is observed to degrade the model performance in real-world medical FL setting, which is termed as retrogress. To address this problem, we propose a personalized retrogress-resilient framework to produce a superior personalized model for each client. Specifically, we devise a Progressive Fourier Aggregation (PFA) at the server to achieve more stable and effective global knowledge gathering by integrating client models from low-frequency to high-frequency gradually. Moreover, with an introduced deputy model to receive the aggregated server model, we design a Deputy-Enhanced Transfer (DET) strategy at the client and conduct three steps of Recover-Exchange-Sublimate to ameliorate the personalized local model by transferring the global knowledge smoothly. Extensive experiments on real-world dermoscopic FL dataset prove that our personalized retrogress-resilient framework outperforms state-of-the-art FL methods, as well as the generalization on an out-of-distribution cohort. The code and dataset are available at https://github.com/CityU-AIM-Group/PRR-FL.