 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorralling Stochastic Bandit Algorithms
Jun 28, 2020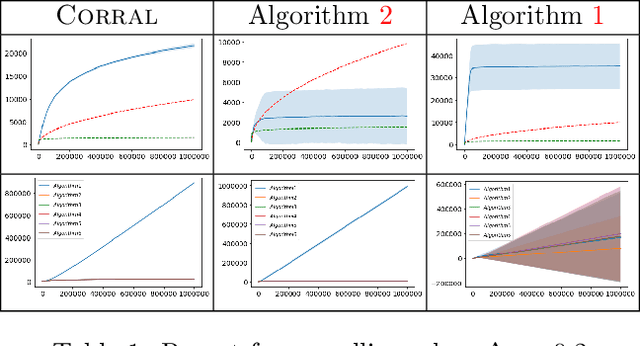
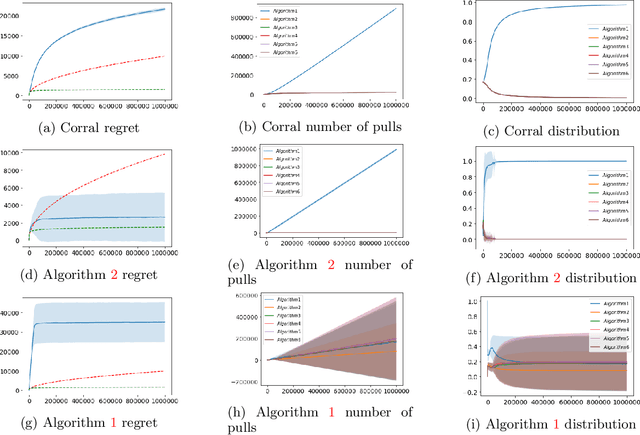
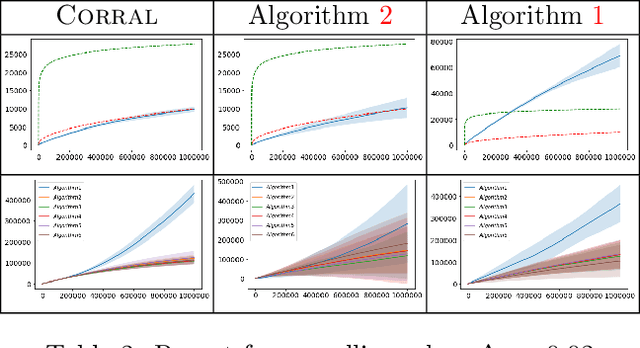
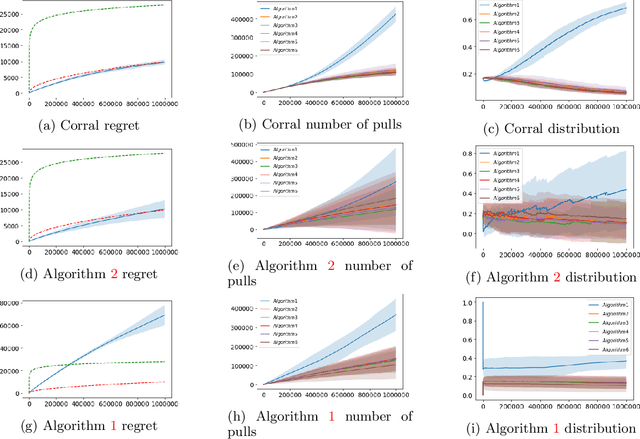
We study the problem of corralling stochastic bandit algorithms, that is combining multiple bandit algorithms designed for a stochastic environment, with the goal of devising a corralling algorithm that performs almost as well as the best base algorithm. We give two general algorithms for this setting, which we show benefit from favorable regret guarantees. We show that the regret of the corralling algorithms is no worse than that of the best algorithm containing the arm with the highest reward, and depends on the gap between the highest reward and other rewards. We also provide lower bounds for this problem that further justify our approach.
Relative Deviation Margin Bounds
Jun 26, 2020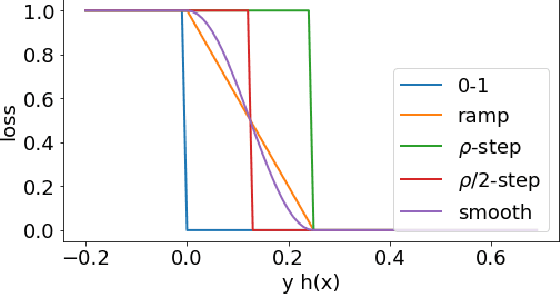
We present a series of new and more favorable margin-based learning guarantees that depend on the empirical margin loss of a predictor. We give two types of learning bounds, both data-dependent ones and bounds valid for general families, in terms of the Rademacher complexity or the empirical $\ell_\infty$ covering number of the hypothesis set used. We also briefly highlight several applications of these bounds and discuss their connection with existing results.
Reinforcement Learning with Feedback Graphs
May 07, 2020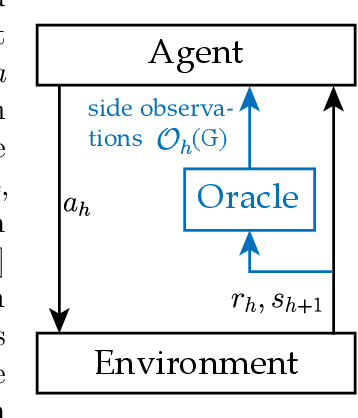


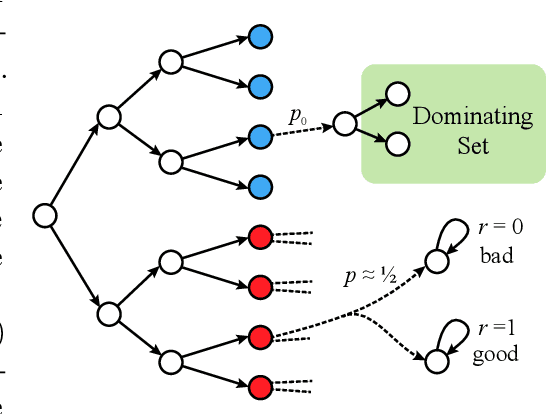
We study episodic reinforcement learning in Markov decision processes when the agent receives additional feedback per step in the form of several transition observations. Such additional observations are available in a range of tasks through extended sensors or prior knowledge about the environment (e.g., when certain actions yield similar outcome). We formalize this setting using a feedback graph over state-action pairs and show that model-based algorithms can leverage the additional feedback for more sample-efficient learning. We give a regret bound that, ignoring logarithmic factors and lower-order terms, depends only on the size of the maximum acyclic subgraph of the feedback graph, in contrast with a polynomial dependency on the number of states and actions in the absence of a feedback graph. Finally, we highlight challenges when leveraging a small dominating set of the feedback graph as compared to the bandit setting and propose a new algorithm that can use knowledge of such a dominating set for more sample-efficient learning of a near-optimal policy.
Adversarial Learning Guarantees for Linear Hypotheses and Neural Networks
Apr 28, 2020
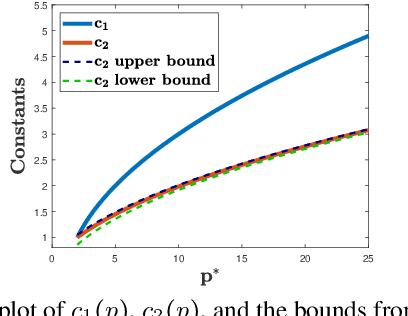
Adversarial or test time robustness measures the susceptibility of a classifier to perturbations to the test input. While there has been a flurry of recent work on designing defenses against such perturbations, the theory of adversarial robustness is not well understood. In order to make progress on this, we focus on the problem of understanding generalization in adversarial settings, via the lens of Rademacher complexity. We give upper and lower bounds for the adversarial empirical Rademacher complexity of linear hypotheses with adversarial perturbations measured in $l_r$-norm for an arbitrary $r \geq 1$. This generalizes the recent result of [Yin et al.'19] that studies the case of $r = \infty$, and provides a finer analysis of the dependence on the input dimensionality as compared to the recent work of [Khim and Loh'19] on linear hypothesis classes. We then extend our analysis to provide Rademacher complexity lower and upper bounds for a single ReLU unit. Finally, we give adversarial Rademacher complexity bounds for feed-forward neural networks with one hidden layer. Unlike previous works we directly provide bounds on the adversarial Rademacher complexity of the given network, as opposed to a bound on a surrogate. A by-product of our analysis also leads to tighter bounds for the Rademacher complexity of linear hypotheses, for which we give a detailed analysis and present a comparison with existing bounds.
Three Approaches for Personalization with Applications to Federated Learning
Feb 25, 2020


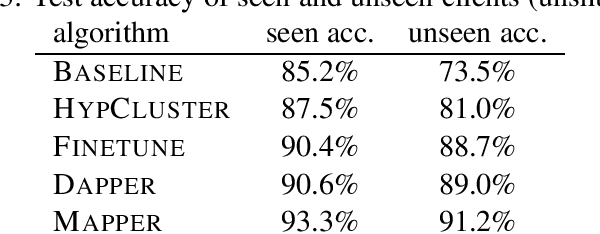
The standard objective in machine learning is to train a single model for all users. However, in many learning scenarios, such as cloud computing and federated learning, it is possible to learn one personalized model per user. In this work, we present a systematic learning-theoretic study of personalization. We propose and analyze three approaches: user clustering, data interpolation, and model interpolation. For all three approaches, we provide learning-theoretic guarantees and efficient algorithms for which we also demonstrate the performance empirically. All of our algorithms are model agnostic and work for any hypothesis class.
Adaptive Region-Based Active Learning
Feb 18, 2020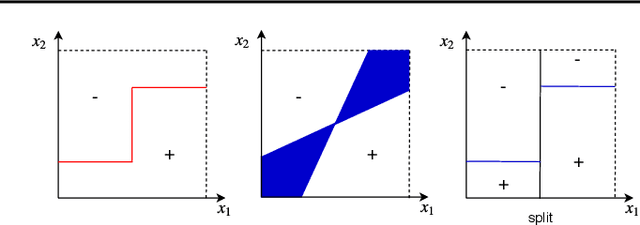
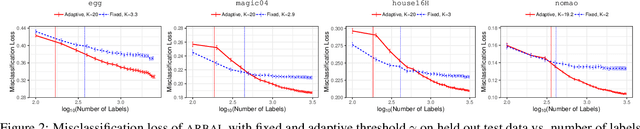
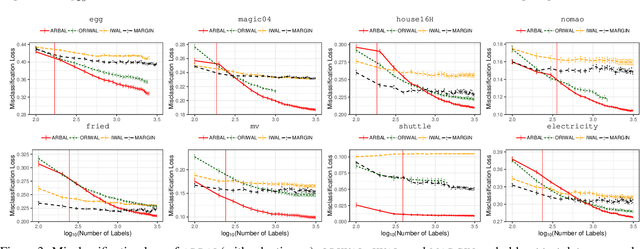
We present a new active learning algorithm that adaptively partitions the input space into a finite number of regions, and subsequently seeks a distinct predictor for each region, both phases actively requesting labels. We prove theoretical guarantees for both the generalization error and the label complexity of our algorithm, and analyze the number of regions defined by the algorithm under some mild assumptions. We also report the results of an extensive suite of experiments on several real-world datasets demonstrating substantial empirical benefits over existing single-region and non-adaptive region-based active learning baselines.
Advances and Open Problems in Federated Learning
Dec 10, 2019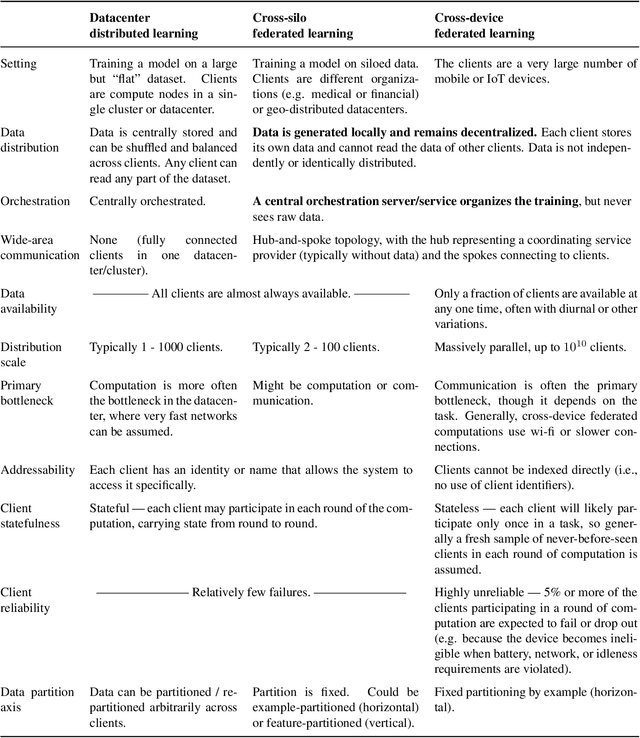
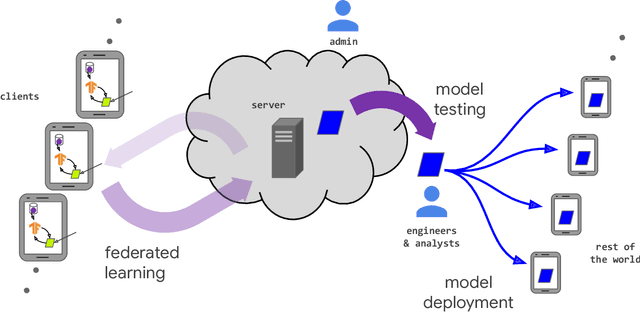
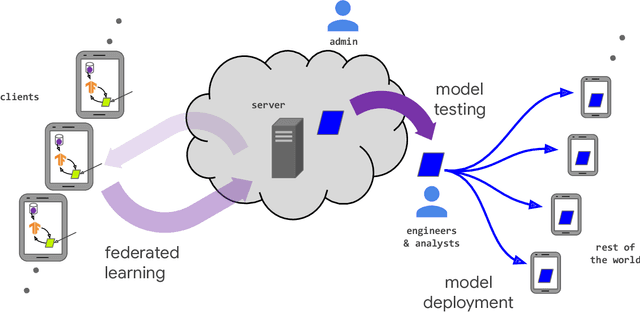

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
Learning GANs and Ensembles Using Discrepancy
Nov 06, 2019
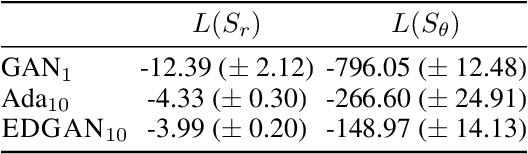

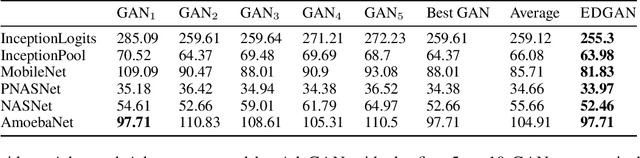
Generative adversarial networks (GANs) generate data based on minimizing a divergence between two distributions. The choice of that divergence is therefore critical. We argue that the divergence must take into account the hypothesis set and the loss function used in a subsequent learning task, where the data generated by a GAN serves for training. Taking that structural information into account is also important to derive generalization guarantees. Thus, we propose to use the discrepancy measure, which was originally introduced for the closely related problem of domain adaptation and which precisely takes into account the hypothesis set and the loss function. We show that discrepancy admits favorable properties for training GANs and prove explicit generalization guarantees. We present efficient algorithms using discrepancy for two tasks: training a GAN directly, namely DGAN, and mixing previously trained generative models, namely EDGAN. Our experiments on toy examples and several benchmark datasets show that DGAN is competitive with other GANs and that EDGAN outperforms existing GAN ensembles, such as AdaGAN.
SCAFFOLD: Stochastic Controlled Averaging for On-Device Federated Learning
Oct 14, 2019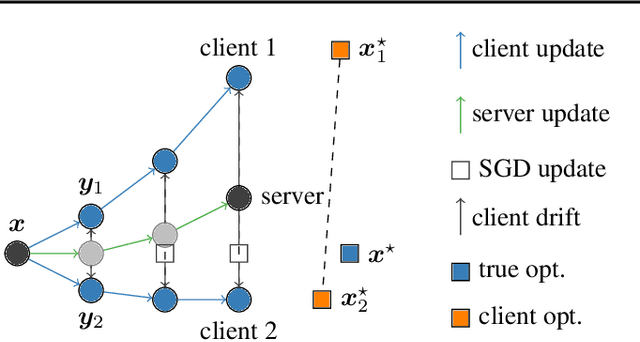
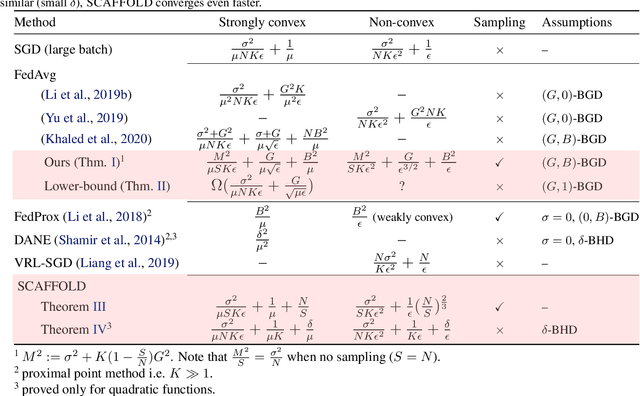
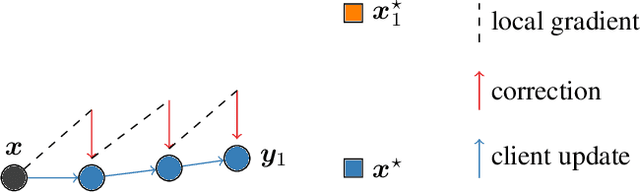
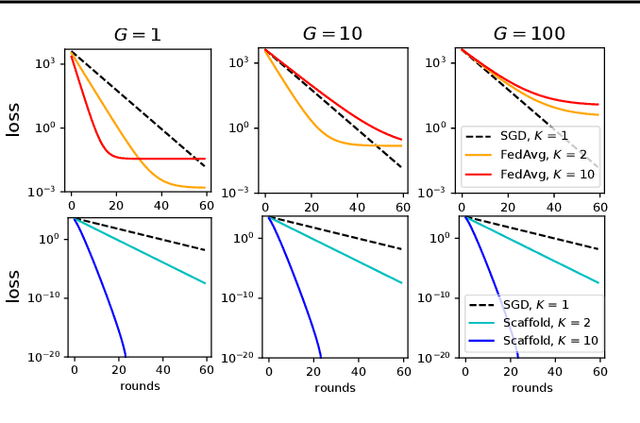
Federated learning is a key scenario in modern large-scale machine learning. In that scenario, the training data remains distributed over a large number of clients, which may be phones, other mobile devices, or network sensors and a centralized model is learned without ever transmitting client data over the network. The standard optimization algorithm used in this scenario is Federated Averaging (FedAvg). However, when client data is heterogeneous, which is typical in applications, FedAvg does not admit a favorable convergence guarantee. This is because local updates on clients can drift apart, which also explains the slow convergence and hard-to-tune nature of FedAvg in practice. This paper presents a new Stochastic Controlled Averaging algorithm (SCAFFOLD) which uses control variates to reduce the drift between different clients. We prove that the algorithm requires significantly fewer rounds of communication and benefits from favorable convergence guarantees.
Bandits with Feedback Graphs and Switching Costs
Jul 29, 2019

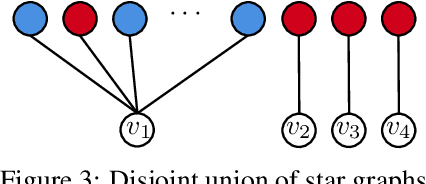
We study the adversarial multi-armed bandit problem where partial observations are available and where, in addition to the loss incurred for each action, a \emph{switching cost} is incurred for shifting to a new action. All previously known results incur a factor proportional to the independence number of the feedback graph. We give a new algorithm whose regret guarantee depends only on the domination number of the graph. We further supplement that result with a lower bound. Finally, we also give a new algorithm with improved policy regret bounds when partial counterfactual feedback is available.